DuckDB vs ClickHouse performance comparison for structured data serialization and in-memory TPC-DS queries execution
January 6th, 2024 / 10 Comments » / by admin
Introduction
As the hype around DuckDB database engine was gaining momentum and popular OLAP computing platforms started to get more difficult to develop on and integrate into small to medium workloads (laptop/desktop-size compute), I also decided to take it for a spin to see for myself what all the fuss was all about. After kicking the tires on it for a few days I walked away equally pleased and surprised with what I saw and even decided to write a post on DuckDB’s performance running a series on TPC-DS benchmark queries – link to old blog post can be found HERE.
Well, here we are again, a few years later and it looks like the team behind DuckDB has made a lot of inroads into improving the product. DuckDB exploded in popularity, well-funded companies have started to pop up, further capitalizing on its success and extending its capabilities and many data science folks (from what I’m hearing) are busy replacing the venerable Pandas API for DuckDB SQL equivalent. This certainly does not feel like a science experiment anymore and commercial projects are built using it as the linchpin for data processing and storage.
However, while in-process OLAP database was a new concept a few years ago, there are new tools and frameworks popping up from other vendors and talented hackers alike. ClickHouse, another RDBMS which has been gaining momentum in the last few years has also taken a lot of stalwarts of this industry by surprise. ClickHouse boasts some impressive list of clients and adopters on its website, and I was even surprised to see internal Microsoft team building their self-service Analytics Tool (Titan) on this platform. ClickHouse popularity also contributed to project such as chDB – an in-process SQL OLAP Engine, powered by ClickHouse. Thanks to chDB, developers, just like with DuckDB, don’t need to install server-side software and can take advantage of a fully-fledged SQL engine inside a Python module.

While ClickHouse and DuckDB are two fundamentally different tools in terms of their primary use cases – the former is geared toward multi-node, distributed deployments and PB-scale data volumes whereas the latter is more of a SQLite for OLAP – they can still be used for a wide range of data processing tasks, more as a Swiss Army knife utility and less as a heavy-hitting big data hammer. They can both query data stored in object storage, do cross-database queries, parse compressed columnar files or semi-structured data e.g. JSON with ease and have rich SQL API support. All these additional bells and whistles can be indispensable in today’s data engineering workflows and in this post, I’d like to put some of this capability to the test. Let’s see how both of these engines perform on a couple of tasks which do not require handling terabytes of data and could instead be used to serialize different file formats and perform in-memory queries, without the need for durable and persistent data storage.
Anecdotal Performance Comparison
One of the most common tasks when dealing with flat files coming out of legacy systems is to convert those into more storage-friendly format and optimize them for query performance. Compression algorithms implemented in columnar file types such as ORC, Avro and Parquet typically reduce data set size by 75-95% in addition to significantly improving query performance as less data has to be read from disk or over a network connection. Both, DuckDB and ClickHouse documentation provides a very good overview of all the benefits formats such Apache Parquet provide out of the box.
For this purpose, I generated a widely used TPC-DS data set for five separate scale factors (roughly correlating to the volume of data in GBs produced by the tool) i.e. 10, 20, 30,40 and 50. As DSDGEN – a tool used for dataset generation – does not output to any of the modern file formats used in analytics e.g. Parquet or Avro, what better way to put these two engines through their paces and see which one can convert between the good old CSV and Apache Parquet the fastest. And since we’re at it, why not run a few TPC-DS benchmark queries against it to compare execution times as well.

Quick note though, both databases provide different Parquet codec or compression algorithm selection by default – DuckDB uses Snappy by default whereas ClickHouse chose to go with LZ4. For this test, to make this comparison as fair as possible, I standardized both outputs on Snappy. I also run the following snippet of code to provide all CSV files with headers (also stored in single line CSV files) – something that TPC-DS utility unfortunately does not do by default.
#!/usr/bin/python
import os
import csv
_CSV_FILES_DIR = r"/Users/user_name/user_files/TPCDS/50GB/csv/"
_CSV_FILES_HEADERS_DIR = r"/Users/user_name/user_files/TPCDS/headers/"
header_files = [f for f in os.listdir(_CSV_FILES_HEADERS_DIR) if f.endswith(".csv")]
csv_files = [f for f in os.listdir(_CSV_FILES_DIR) if f.endswith(".csv")]
for csv_file in csv_files:
with open(
os.path.join(_CSV_FILES_HEADERS_DIR, "h_" + csv_file), newline=""
) as fh, open(os.path.join(_CSV_FILES_DIR, csv_file), newline="") as f:
headers = {}
file_reader = csv.reader(f)
first_line = next(file_reader)
headers.update({csv_file: "".join(first_line)})
og_headers = {}
header_reader = csv.reader(fh)
first_line = next(header_reader)
og_headers.update({csv_file: "".join(first_line)})
shared_items = {
k: headers[k]
for k in headers
if k in og_headers and headers[k] == og_headers[k]
}
if shared_items:
print(
"File '{file_name}' already contains required header. Moving on...".format(
file_name=csv_file
)
)
else:
print(
"Appending header to '{file_name}' file...".format(file_name=csv_file)
)
cmd = "echo '{header}' | cat - {file_path} > temp && mv temp {file_path}".format(
header="".join(first_line),
file_path=os.path.join(_CSV_FILES_DIR, csv_file),
)
os.system(cmd)
With that out of the way, let’s look into how both of these database fair in converting the ubiquitous CSV format into the more modern Parquet variant. For ClickHouse, the following code uses clickhouse-local – a tool which allows you to use the ClickHouse database engine isolated in a command-line utility for fast SQL data processing, without having to configure and start a ClickHouse server. For DuckDB, on the other hand, I used their Python package API. Both worked well on my geriatric but trusty Mac Pro 5,1 with speedy local SSD, 112GB of memory and 2 x Intel Xeon X5690 CPUs.
For reference, DuckDB version 0.9.0 and ClickHouse 23.10.1.1290 were used in this comparison.
#!/usr/bin/python
import duckdb
import sys
from os import system, path, listdir, remove
import csv
from humanfriendly import format_timespan
from time import perf_counter
from random import choice
_CSV_FILES_DIR = r"/Users/user_name/user_files/TPCDS/50GB/csv/"
_PARQUET_FILES_DIR = r"/Users/user_name/user_files/TPCDS/50GB/parquet/"
_WRITE_RESULTS_TO_FILE = 1
_FILE_DELIMITER = "|"
_PARQUET_COMPRESSION_METHOD = "SNAPPY"
def write_time_to_file(_PARQUET_FILES_DIR, results_file_name, processed_file_stats):
try:
with open(
path.join(_PARQUET_FILES_DIR, results_file_name), "w", newline=""
) as csv_file:
w = csv.writer(csv_file)
header = ["File_Name", "Processing_Time"]
w.writerow(header)
for key, value in processed_file_stats.items():
w.writerow([key, value])
except csv.Error as e:
print(e)
def main(param):
results_file_name = "_format_conversion_perf_results.csv"
processed_file_stats = {}
csv_files = [file for file in listdir(_CSV_FILES_DIR) if file.endswith(".csv")]
for file in csv_files:
print("Converting {file} file...".format(file=file), end="", flush=True)
start_time = perf_counter()
parquet_exists = path.join(_PARQUET_FILES_DIR, file.replace(".csv", ".parquet"))
if path.exists(parquet_exists):
try:
remove(parquet_exists)
except OSError as e:
print(e)
if param == "duckdb":
duckdb.sql(
"COPY (SELECT * FROM read_csv_auto('{csv}', delim='{delimiter}', header=True, parallel=True)) \
TO '{parquet}' (FORMAT 'PARQUET', ROW_GROUP_SIZE 100000, CODEC '{compress}')".format(
csv=path.join(_CSV_FILES_DIR, file),
compress=_PARQUET_COMPRESSION_METHOD,
delimiter=_FILE_DELIMITER,
parquet=path.join(
_PARQUET_FILES_DIR, file.replace("csv", "parquet")
),
)
)
if param == "clickhouse":
cmd = 'cd ~ && ./clickhouse local \
--output_format_parquet_compression_method="{compress}" \
--format_csv_delimiter="{delimiter}" -q "SELECT * FROM file({csv}, CSVWithNames) \
INTO OUTFILE {parquet} FORMAT Parquet"'.format(
csv="'" + _CSV_FILES_DIR + "/" + file + "'",
compress=_PARQUET_COMPRESSION_METHOD.lower(),
parquet="'"
+ _PARQUET_FILES_DIR
+ "/"
+ file.replace("csv", "parquet")
+ "'",
delimiter=_FILE_DELIMITER,
)
system(cmd)
end_time = perf_counter()
duration = end_time - start_time
processed_file_stats.update({file: duration})
print("finished in {duration}.".format(duration=format_timespan(duration)))
if _WRITE_RESULTS_TO_FILE == 1:
write_time_to_file(
_PARQUET_FILES_DIR, "_" + param + results_file_name, processed_file_stats
)
if __name__ == "__main__":
params_scope = ["clickhouse", "duckdb"]
if len(sys.argv[1:]) == 1:
param = sys.argv[1]
if param not in params_scope:
raise ValueError(
"Incorrect argument given. Please choose from the following values: {q}".format(
q=", ".join(params_scope[:])
)
)
else:
main(param)
else:
raise ValueError(
"Too many arguments given. Looking for a single parameter value e.g. {param}.".format(
param=choice(params_scope)
)
)
When executed, ClickHouse performed a bit better than DuckDB across all data samples. This is especially evident for larger, multi-million row objects where its performance was sometimes double that of DuckDB. Also, looking at the CPU utilization I noticed that with ClickHouse, multiple processes were always instantiated for each table (the number fluctuated between a couple all the way up to equal the number of cores on my machine), possibly leading to a better parallelization and I/O utilization. DuckDB workload, on the other hand, was mostly tied to a single core, even though “parallel = True” file reader parameter was specified.
All in all, both tools provide a really easy way for fast and hassle-free data serialization and can even be used in serverless pipelines as demonstrated in the next section.
Next, let’s look at how both databases handle typical OLAP queries. Given I already had a parquet file generated for each table and five distinct scaling factors, it would be a shame to waste the opportunity to test how TPC-DS queries run against each database.
I already tested DuckDB a few years ago (link HERE) and found it to be a great little tool for small to medium OLAP workloads so for this comparison I decided to do something a bit different and load individual TPC-DS data set into memory instead of creating it on disk. For DuckDB, the special value :memory: (the default) can be used to create an in-memory database with no disk persistence. ClickHouse also offers in-memory capability through one of its many storage engines. The Memory engine used in this demo stores data in RAM, in uncompressed format so it looked like the perfect fit for performance-first implementation. For this exercise, I repurposed my previous Python script and added ClickHouse functionality as well as loading data into RAM and creating implicit database schema from each file. This meant that each parquet file was loaded “as-is” and neither of the two databases strictly conformed to the TPC-DS schema specifications. This pattern is known as CTAS (Create Table As Select) as it creates a new table based on the output of a SELECT statement.
The following script was used to implicitly create TPC-DS database tables, load the previously generated parquet files into memory and run SQL queries against the schema. All specified SQL queries are run three times with a mean time selected as the final query execution result.
#!/usr/bin/python
import duckdb
import sys
from random import choice
from time import perf_counter
from humanfriendly import format_timespan
import pandas as pd
from os import listdir, path, system
import clickhouse_connect
import psutil
import csv
_SQL_QUERIES = r"/Users/user_name/user_files/TPCDS/Code/sql/tpcds_sql_queries.sql"
_CSV_FILES_DIR = r"/Users/user_name/user_files/TPCDS/50GB/csv/"
_PARQUET_FILES_DIR = r"/Users/user_name/user_files/TPCDS/50GB/parquet/"
_EXEC_RESULTS = r"/Users/user_name/user_files/TPCDS/exec_results.xlsx"
_QUERIES_SKIPPED = [
"Query1","Query5","Query6","Query8","Query10","Query13","Query14","Query15","Query17",
"Query19","Query20","Query24","Query25","Query26","Query27","Query33","Query35","Query38",
"Query39","Query45","Query51","Query52","Query53","Query61","Query66","Query68","Query69",
"Query70","Query73","Query74","Query76","Query79","Query81","Query83","Query84","Query85",
"Query86","Query87","Query88","Query89","Query90","Query95","Query96","Query98","Query103"]
_EXECUTION_ROUNDS = 3
_WRITE_RESULTS_TO_FILE = 1
def write_time_to_file(_PARQUET_FILES_DIR, results_file_name, processed_file_stats):
try:
with open(
path.join(_PARQUET_FILES_DIR, results_file_name), "w", newline=""
) as csv_file:
w = csv.writer(csv_file)
header = ["File_Name", "Processing_Time"]
w.writerow(header)
for key, value in processed_file_stats.items():
w.writerow([key, value])
except csv.Error as e:
print(e)
def get_sql(sql_queries):
query_number = []
query_sql = []
with open(sql_queries, "r") as f:
for i in f:
if i.startswith("----"):
i = i.replace("----", "")
query_number.append(i.rstrip("\n"))
temp_query_sql = []
with open(sql_queries, "r") as f:
for i in f:
temp_query_sql.append(i)
l = [i for i, s in enumerate(temp_query_sql) if "----" in s]
l.append((len(temp_query_sql)))
for first, second in zip(l, l[1:]):
query_sql.append("".join(temp_query_sql[first:second]))
sql = dict(zip(query_number, query_sql))
return sql
def load_db_schema(param, tables, _PARQUET_FILES_DIR, _CSV_FILES_DIR, conn):
stats = {}
results_file_name = "_db_load_perf_results.csv"
print(
"\n--------------------------- Loading TPC-DS data into memory ----------------------------"
)
try:
if param == "duckdb":
for table in tables:
cursor = conn.cursor()
copysql = "CREATE TABLE {table} AS SELECT * FROM read_parquet ('{path}{table}.parquet');".format(
table=table, path=_PARQUET_FILES_DIR
)
print(
"Loading table {table}...".format(table=table), end="", flush=True
)
start_time = perf_counter()
cursor.execute(copysql)
end_time = perf_counter()
stats.update({table: end_time - start_time})
cursor.execute("SELECT COUNT(1) FROM {table}".format(table=table))
records = cursor.fetchone()
db_row_counts = records[0]
file_row_counts = (
sum(
1
for line in open(
_CSV_FILES_DIR + table + ".csv",
newline="",
)
)
- 1
)
if file_row_counts != db_row_counts:
raise Exception(
"Table {table} failed to load correctly as record counts do not match: flat file: {ff_ct} vs database: {db_ct}.\
Please troubleshoot!".format(
table=table,
ff_ct=file_row_counts,
db_ct=db_row_counts,
)
)
else:
print(
"{records} records loaded successfully in {time}.".format(
records=db_row_counts,
time=format_timespan(end_time - start_time),
)
)
cursor.close()
if param == "clickhouse":
for table in tables:
cursor = "DROP TABLE IF EXISTS {table};".format(table=table)
conn.command(cursor)
cursor = "CREATE TABLE {table} ENGINE = Memory AS \
SELECT * FROM file({parquet}, Parquet)".format(
table=table,
parquet="'" + _PARQUET_FILES_DIR + table + ".parquet" + "'",
)
start_time = perf_counter()
print(
"Loading table {table}...".format(table=table), end="", flush=True
)
conn.command(cursor)
end_time = perf_counter()
stats.update({table: end_time - start_time})
db_row_counts = conn.command(
"SELECT COUNT(1) FROM {table}".format(table=table)
)
file_row_counts = (
sum(
1
for line in open(
_CSV_FILES_DIR + table + ".csv",
newline="",
)
)
- 1
)
if file_row_counts != db_row_counts:
raise Exception(
"Table {table} failed to load correctly as record counts do not match: flat file: {ff_ct} vs database: {db_ct}.\
Please troubleshoot!".format(
table=table,
ff_ct=file_row_counts,
db_ct=db_row_counts,
)
)
else:
print(
"{records} records loaded successfully in {time}.".format(
records=db_row_counts,
time=format_timespan(end_time - start_time),
)
)
if _WRITE_RESULTS_TO_FILE == 1:
write_time_to_file(
_PARQUET_FILES_DIR, "_" + param + results_file_name, stats
)
except Exception as e:
print(e)
sys.exit(1)
def time_sql_execution(pd_index, exec_round, conn, sql_queries):
exec_results = {}
print(
"\n---------------------- Executing TPC-DS queries (round {round} of {total}) ----------------------".format(
round=exec_round + 1, total=_EXECUTION_ROUNDS
)
)
for key, val in sql_queries.items():
query_sql = val
query_number = key.replace("Query", "")
try:
query_start_time = perf_counter()
if param == "duckdb":
cursor = conn.cursor()
cursor.execute(query_sql)
records = cursor.fetchall()
cursor.close()
if param == "clickhouse":
result = conn.query(query_sql.replace(";", ""))
records = result.result_rows
query_end_time = perf_counter()
rows_count = sum(1 for row in records)
query_duration = query_end_time - query_start_time
exec_results.update({key: query_end_time - query_start_time})
print(
"Query {q_number} executed successfully and returned {ct} rows. Execution time was {time}.".format(
q_number=query_number,
time=format_timespan(query_duration),
ct=rows_count,
)
)
except Exception as e:
print(e)
df = pd.DataFrame(
list(exec_results.items()),
index=pd_index,
columns=["Query_Number", "Execution_Time_" + str(exec_round)],
)
return df
def main(param):
tables = [
path.splitext(file)[0]
for file in listdir(_PARQUET_FILES_DIR)
if file.endswith(".parquet")
]
sql_file = _SQL_QUERIES
if param == "duckdb":
conn = duckdb.connect(database=":memory:")
ver = conn.execute("PRAGMA version;").fetchone()
print("DuckDB version (git short hash) =", ver[1])
load_db_schema(param, tables, _PARQUET_FILES_DIR, _CSV_FILES_DIR, conn)
if param == "clickhouse":
clickhouse = [p for p in psutil.process_iter() if p.name() == "clickhouse"]
if clickhouse:
conn = clickhouse_connect.get_client(host="localhost", username="default")
ver = conn.server_version
print("ClickHouse version =", ver)
load_db_schema(param, tables, _PARQUET_FILES_DIR, _CSV_FILES_DIR, conn)
else:
cmd = "cd ~ && ./clickhouse server"
raise Exception(
'ClickHouse is currently NOT running, please initialize it by running the following: "'
"{cmd}"
'"'.format(cmd=cmd)
)
sql_queries = get_sql(sql_file)
if _QUERIES_SKIPPED:
sql_queries = {
k: v for k, v in sql_queries.items() if k not in _QUERIES_SKIPPED
}
index_count = len(sql_queries.keys())
pd_index = range(0, index_count)
dfs = pd.DataFrame()
for exec_round in range(0, _EXECUTION_ROUNDS):
df = time_sql_execution(pd_index, exec_round, conn, sql_queries)
dfs = pd.concat([dfs, df], axis=1, sort=False)
dfs = dfs.loc[:, ~dfs.columns.duplicated()]
dfs["Mean_Execution_Time"] = round(dfs.mean(axis=1), 2)
dfs.to_excel(_EXEC_RESULTS, sheet_name="TPC-DS_Exec_Times", index=False)
conn.close()
if __name__ == "__main__":
params_scope = ["clickhouse", "duckdb"]
if len(sys.argv[1:]) == 1:
param = sys.argv[1]
if param not in params_scope:
raise ValueError(
"Incorrect argument given. Please choose from the following values: {q}".format(
q=", ".join(params_scope[:])
)
)
else:
main(param)
else:
raise ValueError(
"Too many arguments given. Looking for a single parameter value e.g. {param}.".format(
param=choice(params_scope)
)
)
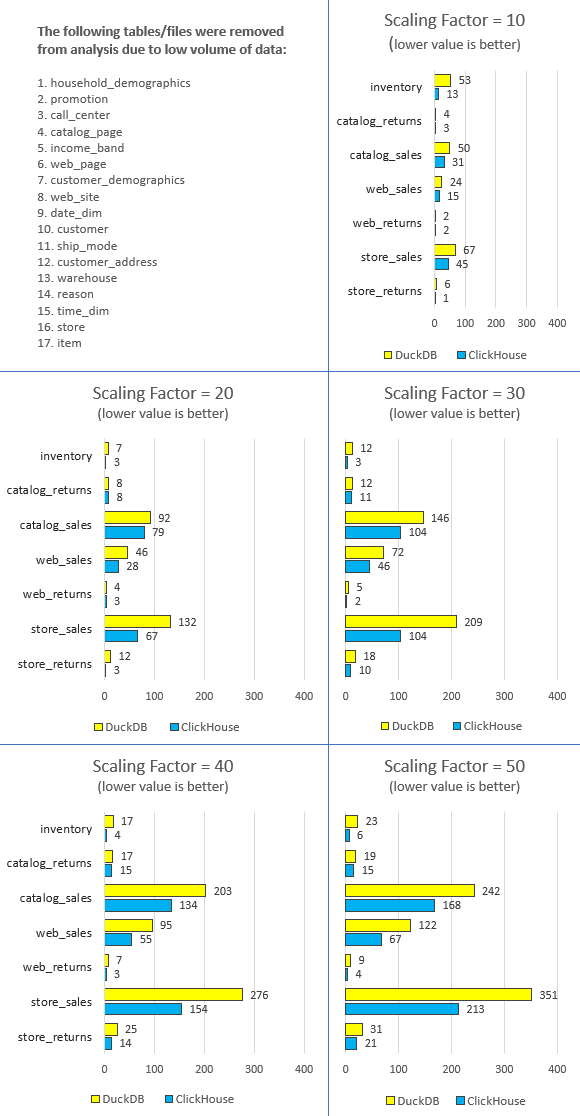
This is pretty much the same code I used a few years ago when benchmarking DuckDB but it creates an in-memory dataset instead of relying on disk persistence and it’s been extended to run for ClickHouse as well. I also excludes a bunch of queries which were failing due to slight SQL syntax incompatibilities across the two engines. Both, DuckDB and ClickHouse have idiosyncrasies in the dialect of SQL they’ve adopted, so the only way to have a common and standard set was to cull some of them. I run this script across all scaling factors but for the sake of brevity I only charted two of them i.e. 40 and 50 (you can download all results across all scaling factors from HERE).
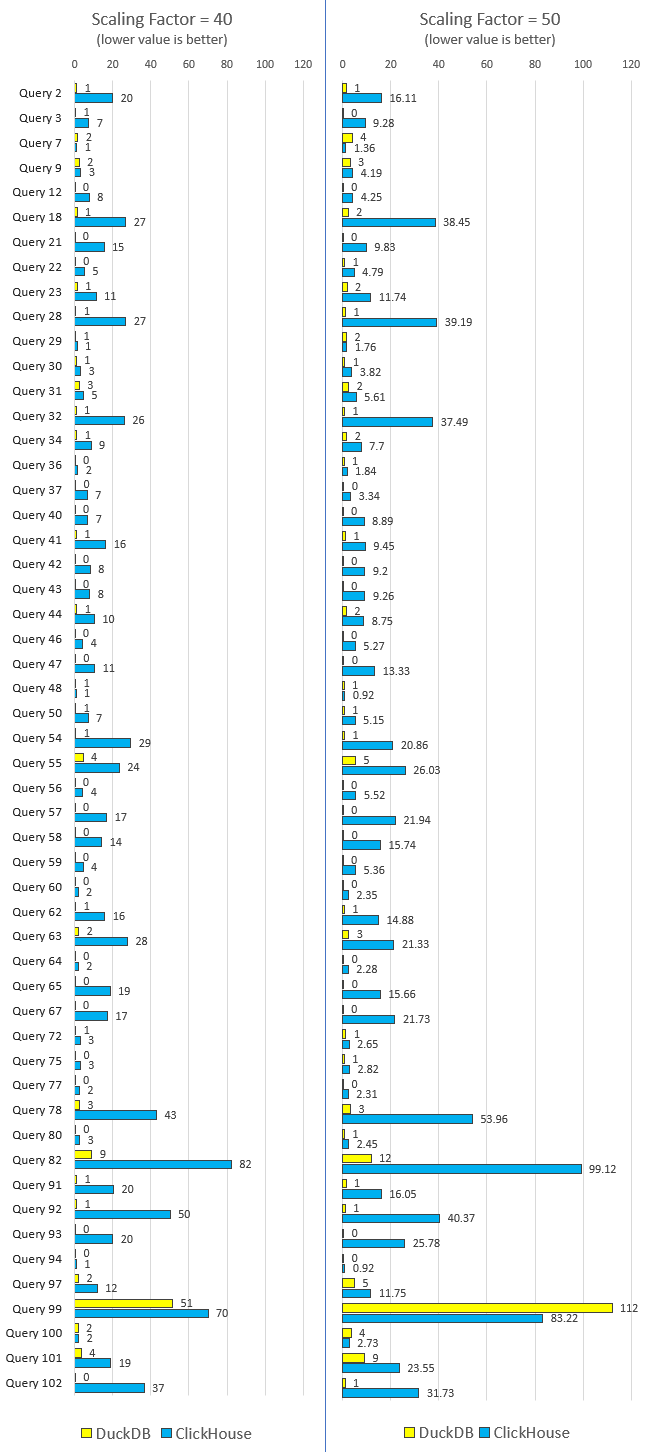
When I first run this benchmark, I was surprised to learn how much better DuckDB performed across the board. In fact, it was so much better that I decided to rewrite a portion of the script to ensure data was loaded into an explicitly defined schema, instead of using the CTAS pattern, believing that was the reason for ClickHouse much slower performance. It, however, did not make a material difference to the execution times so I reverted back to the CTAS model and run the queries multiple times to confirm the findings. As you can see, it looks like with the exception of one query in the 50GB category, DuckDB turned out to be a much better engine for querying in-memory data and hearing all the great stories about ClickHouse performance left me surprised how much slower is was in this comparison. I’m sure there are a number of tweaks I could implement to improve its performance but this was about a very specific use case – in-memory data storage and queries execution – so I was a bit stunned to find out DuckDB blew it out of the water. In their on-line documentation ClickHouse indicates that with memory table engine “maximal productivity (over 10 GB/sec) is reached on simple queries, because there is no reading from the disk, decompressing, or deserializing data” so unless Mac OS platform is not optimized for running ClickHouse instance, the only thing I could attribute this to is the complex nature of TPC-DS queries and the fact ClickHouse does not perform nominally unless data is mostly denormalized.
This exercise also goes to show that for each use case, a thorough testing is a required precursor to fully ascertain software performance characteristics – DuckDB was slower when serializing flat files data but took the crown when running complex computations on relational schema.
In-process SQL Database for Serverless Compute
Benchmarks’ results notwithstanding, in-process database like DuckDB can be used to “stitch together” serverless pipelines without the need for a dedicated server deployment. Words like “serverless” and “database” hardly go together in the same sentence – most of the time, latency and availability trade-offs or simply variable compute needs have a big impact on providing a consistent experience for end-users. As Marc Brooker put it in one of his memorable tweets, “The declarative nature of SQL is a major strength, but also a common source of operational problems. This is because SQL obscures one of the most important practical questions about running a program: how much work are we asking the computer to do?”
However, database engines like DuckDB can be used with great success for serverless pipelines to do things like, data serialization, remote object store files integration, semi-structured or spatial data manipulation and many more.
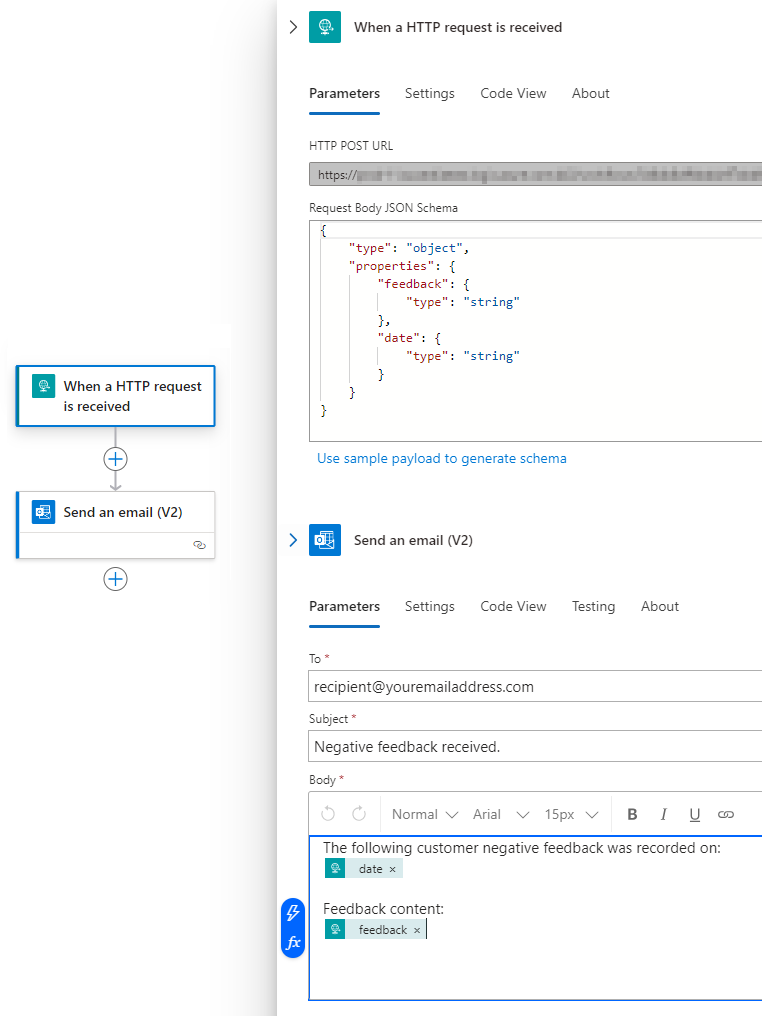
The following is a small example of using DuckDB in Azure function in order to convert a CSV file into a Parquet file. Using serverless model with an in-process database engine works well when data volumes are small and workloads predictable. Deploying a client-server RDBMS for small, infrequent workloads like these would be an overkill and tools like DuckDB allow for a lot of flexibility and creativity.
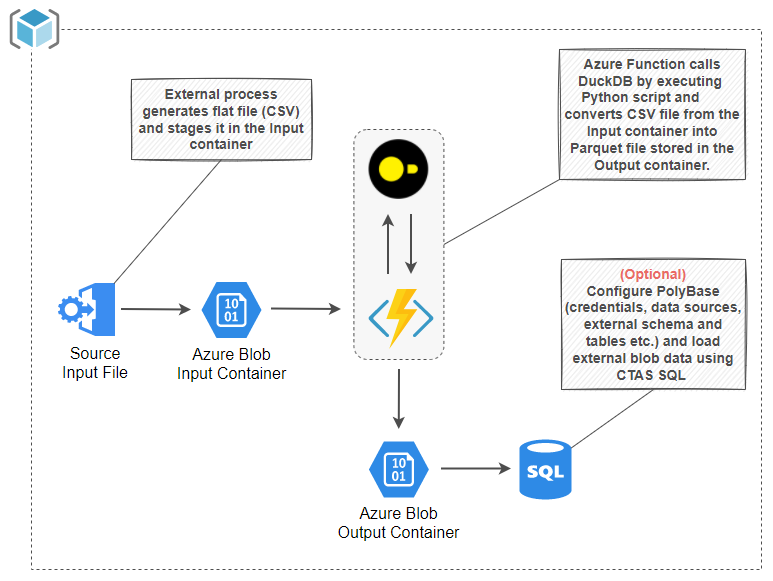
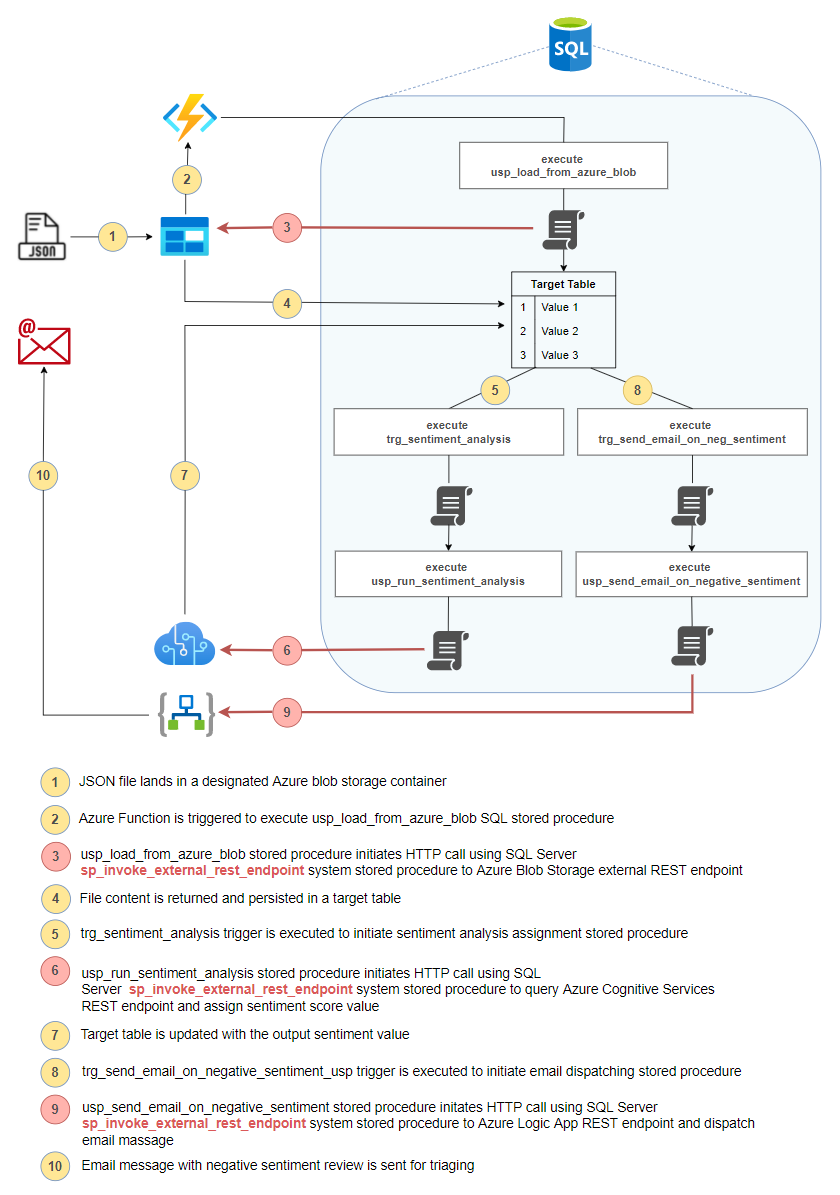
This architecture assumes a very simple Azure blob storage trigger which fires when a new CSV file is uploaded into a container. A small Python script is then executed to convert an input CSV file into a Parquet file and persist it into an output container. Although DuckDB recently released extension support for a native filesystem abstraction for the Azure Blob storage, I was unable to write Parquet file into the output container as this feature is not yet supported. However, fsspec (Filesystem Spec) library comes with Azure Blob File Storage support and integrating it into DuckDB was not difficult. Also, if you’re using the below script, please make sure you have all the required Python modules listed in the requirements.txt file e.g. azure-functions, duckdb, fsspec and azure-storage-blob.
import logging
import duckdb
import azure.functions as func
from fsspec import filesystem
from os import path
from azure.storage.blob import BlobClient
# For demo only - any cryptographic keys should be stored in Azure Key Vault!
ACCOUNT_NAME = "az_duckdb"
# For demo only - any cryptographic keys should be stored in Azure Key Vault!
ACCOUNT_KEY = "your_personal_account_key"
BLOB_CONN_STRING = "DefaultEndpointsProtocol=https;AccountName={acct_name};AccountKey={acct_key};EndpointSuffix=core.windows.net".format(
acct_name=ACCOUNT_NAME, acct_key=ACCOUNT_KEY
)
def main(inputblob: func.InputStream, outputblob):
logging.basicConfig(
level=logging.INFO, format="%(asctime)s:%(levelname)s:%(message)s"
)
logging.info(f"Python function triggered for blob: {inputblob.name}")
try:
output_blob_name = inputblob.name.replace("csv", "parquet").replace(
"input", "output"
)
conn = duckdb.connect()
conn.register_filesystem(
filesystem("abfs", account_name=ACCOUNT_NAME, account_key=ACCOUNT_KEY)
)
cursor = conn.cursor()
cursor.execute(
"SELECT COUNT(1) \
FROM read_csv_auto('abfs://{input}', delim = '|', header=True)".format(
input=inputblob.name
)
)
csv_count = cursor.fetchone()
csv_row_counts = csv_count[0]
cursor.execute(
"COPY (SELECT * \
FROM read_csv_auto('abfs://{input}', delim = '|', header=True)) \
TO 'abfs://{output}' (FORMAT 'parquet', CODEC 'SNAPPY')".format(
input=inputblob.name, output=output_blob_name
)
)
cursor.execute(
"SELECT COUNT(1) \
FROM read_parquet('abfs://{output}')".format(
output=output_blob_name
)
)
parquet_count = cursor.fetchone()
parquet_row_counts = parquet_count[0]
blob = BlobClient.from_connection_string(
conn_str=BLOB_CONN_STRING,
container_name="output",
blob_name=path.basename(output_blob_name),
)
exists = blob.exists()
if exists and csv_row_counts == parquet_row_counts:
logging.info("CSV to Parquet file serialization executed successfully!")
except Exception as e:
logging.critical(e, exc_info=True)
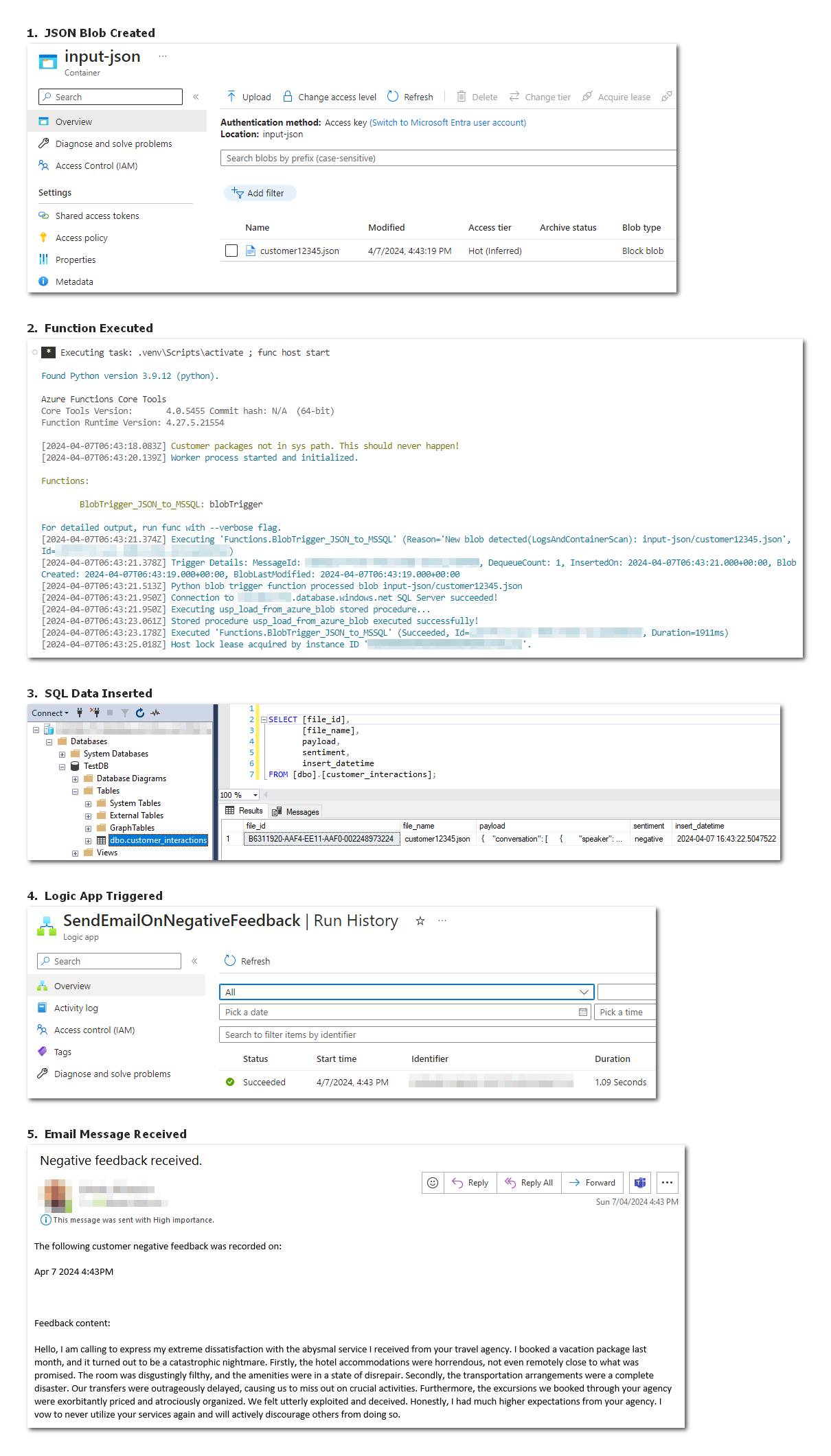
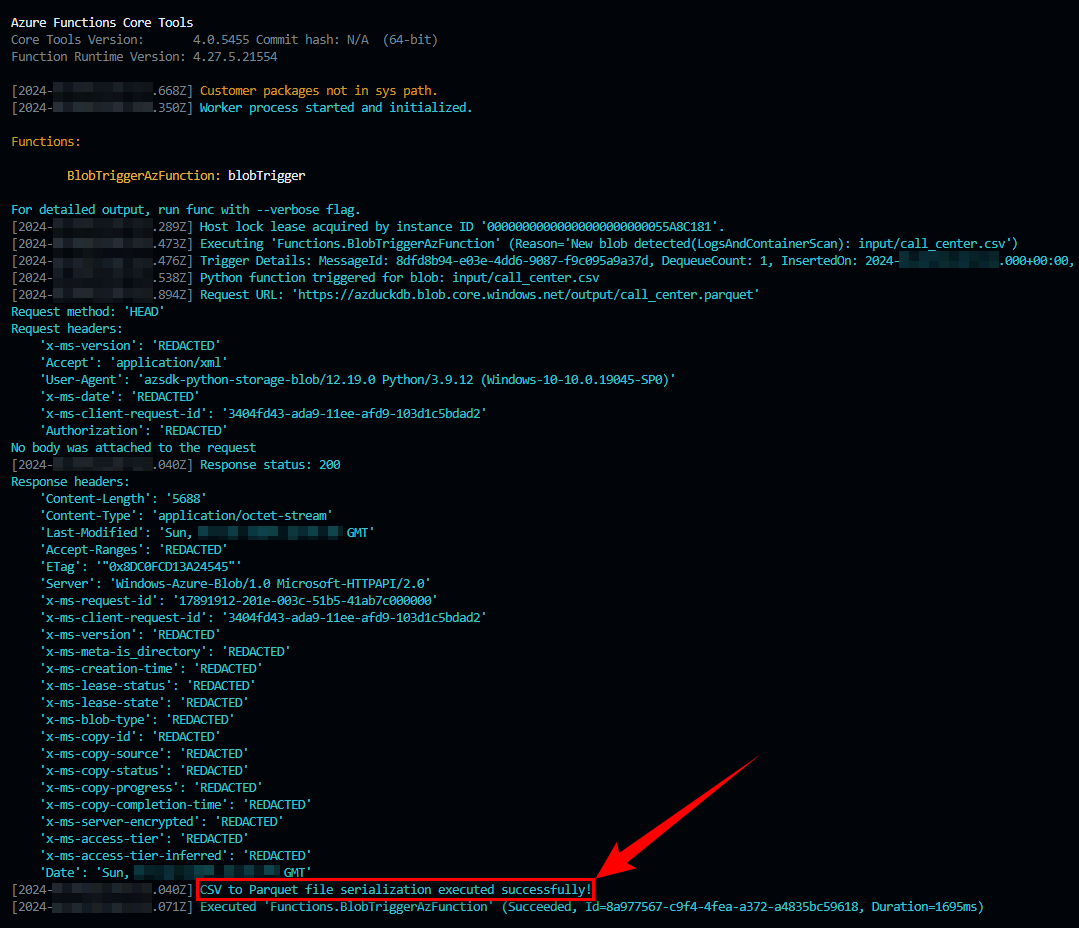
Here’s an output of running this function on my local machine via the Azure Functions Core Tools extension for VS Code (please click on image to expand). When call_center.csv file is placed in the Input container, the function is triggered and DuckDB module invoked via a Python API. When finished executing, a newly created Parquet file is placed in an Output container.
Architecture like this can be further extended to support more complex scenarios e.g. event-driven workflow from a series of chained (durable) functions, executing in a specific order or in a fan out/fan in patter where multiple functions run in parallel. These patterns are well documented on Microsoft’s website (link HERE) and can be applied or extended to a variety of requirements using tools like DuckDB.
Conclusion
This post wasn’t supposed to be a pure benchmark results comparison across ClickHouse and DuckDB in-memory capabilities and serve more as an exploratory exercise into some of the features of both engines. Also, I’d like to note that ClickHouse does scale-out, MPP-style architecture very well and the application I used it for in this post (single node, small data, command like-type utility) is just one of the niche workflow flavors ClickHouse can service out-of-the-box. Most traditional implementations are focused on multi-terabyte, scale-out, MPP-style cloud-first deployments and that’s its forte architecture pattern – just look at this video from Microsoft, explaining how they’re using it as their data analytics engine for two of their internal products.
I don’t think either of these two engines will set the corporate data management world on fire – most big orgs still gravitate towards the stalwarts of this industry e.g. Snowflake, Vertica, Teradata for different reasons (some of them which have nothing to do with technical superiority of any of these products). However, there’s a lot of niche applications which these tools excel at and where a standalone server (cloud or on-prem) is just too much hassle to provision and maintain. These may include the following:
- Query processor for local or remote files, including semi-structured data
- Input stream pre-processor
- Can handle large volumes of data with no need for scale-out and MPP-style architecture (ClickHouse does both well)
- Local, no-dependency OLAP engines for analytics and data processing
- Portability (single-file databases); can even run inside a browser
- Good integration and rich API for programming languages and external platforms/frameworks
- Cost (open-source)
- Good integration with serverless computing e.g. AWS Lambda, Azure Functions
- POCs and MVPs due to speed of deployment
I also hope that as they mature, these RDBMS engines gain more momentum in the industry. Changing database vendor is the most difficult, important and lasting decision many organizations make and generally, there is a level of trepidation associated with moving away from tried technologies. However, the level of innovation and rapid improvement I’ve seen in these platforms is astounding and I genuinely believe that with a bit less risk-averse corporate strategies, more industry outreach and recognition and perhaps some of the Snowflake PR budget, they would be in the top 10 DB-Engines Ranking for OLAP databases.