Introduction to Microsoft SQL Server 2014 Clustered Columnstore Indexes Performance Testing
Introduction
If you an avid Microsoft SQL Server database user and/or had a chance to work with SQL Server 2012 version and its new indexing options, you’ve probably heard of columnstore index concept. Columnstore index, first introduced in SQL Server 2012, stores data in columnar fashion (unlike the traditional B-tree structures used for clustered and non-clustered rowstore indexes) to speed-up the processing time of common data warehousing queries. Typical data warehousing workloads involve summarizing large amounts of data. The techniques typically used in data warehousing and decision support systems to improve performance are pre-computed summary tables, indexed views or OLAP cubes. Although these can greatly speed up query processing, they can also prove inflexible, difficult to maintain, must be designed specifically for each query problem and require certain level of OLAP expertise. Leveraging their existing SQL skills, developers and DBAs can now achieve near OLAP-like performance by means of utilising columnstore indexes. A columnstore index organizes the data in individual columns that are joined together to form the index. This structure can offer significant performance gains for queries that summarize large quantities of data, the sort typically used for business intelligence (BI) and data warehousing.
Architecture and Performance Testing
Just like a normal clustered index, a clustered columnstore index defines how the data is physically stored on the disc. A columnstore backed table is initially organized into segments known as row groups. Each rowgroup holds from 102,400 to 1,048,576 rows. Once a rowgroup is identified it is broken up into column segments, which are then compressed and inserted into the actual columnstore. When dealing with small amounts of data, small being defined as less than a hundred thousand rows, the data is staged in a section known as the deltastore. Once it reaches the minimum size the deltastore can be drained, its data being processed as a new rowgroup. This is depicted in the MSDN diagram below.
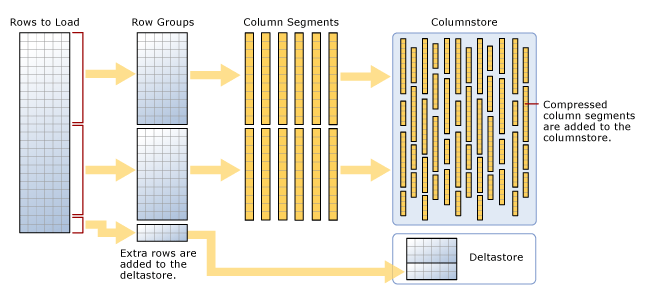
A deltastore will be closed while it is being converted. This, however, is not a blocking operation for the table as a whole. An additional deltastore can be created for a given table when the current deltastores are unavailable due to locking. And if the table is partitioned, then each partition gets its own set of deltastores.
Columnstore indexes are not the panacea for all potential performance issues. While it’s possible to build a system that stores all data in columnar format, row stores still have advantages in some situations. A B-tree is a very efficient data structure for looking up or modifying a single row of data. So if your workload entails many single row lookups and many updates and deletes, which is common for OLTP workloads, you will probably continue to use row store technology. Data warehouse workloads typically scan, aggregate, and join large amounts of data. In those scenarios, column stores really shine.
Let’s look at some performance gains which can be achieved by using columnstore index technology. For the purpose of this demonstration I used a couple of text files (all files and SQL queries for this presentation can be downloaded from HERE) holding the subset of data I intend to load into my tables. These files have been placed in a folder on my c:\ drive and their data loaded into a ‘sandbox’ database for performance testing. I also ‘stretched out’ one of the tables to take advantage of much larger volume of data to run a few test queries, comparing execution times between tables with ‘classic’ b-tree indexes vs. columnstore indexes. Again, all scripts used in this presentation as well as additional files can be downloaded from HERE.
The quick video footage below demonstrates the process of test environment preparation as well as all performance tests executed with their corresponding results. At the very last moment I also decided to include some rudimentary data I managed to collect regarding table compression efficiency (by the way, great achievement by SQL Server team at MSFT!) when implemented using a columnstore index. Enjoy and leave me a comment if you find it useful or otherwise!
http://scuttle.org/bookmarks.php/pass?action=add
This entry was posted on Wednesday, December 11th, 2013 at 4:58 am and is filed under SQL. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.


