Which One Should I Use – NOT EXISTS, NOT IN, OUTER APPLY, EXCEPT and LEFT OUTER JOIN Performance Optimization
Introduction
Lately I have been involved in a large enterprise data warehouse deployment project and the in last few weeks we have been at a point where the team slowly begun transitioning from dimension tables development to fact tables development. Working with many different teams e.g. contractors, consultants, internal data professionals etc. what caught my attention was the fact that different developers tend to use different techniques to differentiate between the ‘new’ vs. ‘old’ data e.g. source OLTP system vs. target fact table in the OLAP schema to determine whether a given set of transactions have already been inserted or not. Given that most data flow logic was embedded into SQL stored procedures, with SQL Server Integration Services only controlling execution flow, a typical scenario for source vs. target comparison would involve applying dataset differentiating statement e.g. NOT EXISTS or NOT IN to account for any new transactions. There is a number of different options available here so I thought it would be a good idea to put them to the test and find out how performance is affected when using the most common ones i.e. NOT EXISTS, NOT IN, OUTER APPLY, EXCEPT and LEFT OUTER JOIN, on a well-structured dataset, with and without an index and with columns defined as NULLable vs. Non-NULLable.
The short-winded version is that when presented with a choice of using either one of those 5 statements you should preferably stay away from NOT IN for reasons I described below. This will depend heavily on your schema, data and resources at your disposal but as a rule of thumb, NOT IN should never be the first option to give consideration to when other alternatives are possible.
TL;DR Version
Let’s start with two sample datasets – Tbl1 and Tbl2 – where Tbl2 differs from its archetype by removing a small number of records (in this case around 50). The two tables and their data were created using the following SQL.
USE [master] GO IF EXISTS (SELECT name FROM sys.databases WHERE name = N'TestDB') BEGIN -- Close connections to the DW_Sample database ALTER DATABASE [TestDB] SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE [TestDB] END GO CREATE DATABASE [TestDB] GO USE [TestDB] GO CREATE TABLE Tbl1 (ID int identity (1,1), ID_NonIdentity int NOT NULL DEFAULT 0, object_id int NOT NULL) GO CREATE TABLE Tbl2 (ID int identity (1,1), ID_NonIdentity int NOT NULL, object_id int NOT NULL) GO INSERT INTO Tbl1 (object_id) SELECT c1.object_id FROM sys.objects c1 CROSS JOIN (SELECT Top 100 name FROM sys.objects) c2 CROSS JOIN (SELECT Top 100 type_desc FROM sys.objects) c3 GO 25 UPDATE Tbl1 SET ID_NonIdentity = ID INSERT INTO Tbl2 (ID_NonIdentity, object_id) SELECT ID_NonIdentity, object_id FROM Tbl1 SET NOCOUNT ON DECLARE @start int = 0 DECLARE @finish int = (SELECT MAX(id) FROM Tbl2) WHILE @start <= @finish BEGIN DELETE FROM Tbl2 WHERE id = @start SET @start = @start+250000 END CREATE INDEX idx_Tbl1_ID_NonIdentity ON Tbl1 (ID_NonIdentity) CREATE INDEX idx_Tbl2_ID_NonIdentity ON Tbl2 (ID_NonIdentity)
Given that the two objects’ data is slightly different, we can now compare their content and extract the dichotomies using ID_NonIdentity attribute or simply run EXCEPT statement across the two tables. You can also notice that at this stage both tables are defined using non-NULLable data types and have indexes created on ID_NonIdentity column. Let’s run the sample SELECT statements using NOT EXISTS, NOT IN, OUTER APPLY, EXCEPT AND LEFT OUTER JOIN and look at execution times and plans in more detail.
--QUERY 1 DBCC FREEPROCCACHE DBCC DROPCLEANBUFFERS SET STATISTICS TIME ON SELECT ID FROM tbl1 a WHERE a.ID_NonIdentity NOT IN (SELECT b.ID_NonIdentity FROM tbl2 b) SET STATISTICS TIME OFF --QUERY 2 DBCC FREEPROCCACHE DBCC DROPCLEANBUFFERS SET STATISTICS TIME ON SELECT ID FROM tbl1 a WHERE NOT EXISTS (SELECT ID_NonIdentity FROM tbl2 b WHERE a.ID_NonIdentity = b.ID_NonIdentity) SET STATISTICS TIME OFF --QUERY 3 DBCC FREEPROCCACHE DBCC DROPCLEANBUFFERS SET STATISTICS TIME ON SELECT a.ID FROM Tbl1 a LEFT OUTER JOIN Tbl2 b ON a.ID_NonIdentity = b.ID_NonIdentity --11sec WHERE b.ID_NonIdentity IS NULL SET STATISTICS TIME OFF --QUERY 4 DBCC FREEPROCCACHE DBCC DROPCLEANBUFFERS SET STATISTICS TIME ON SELECT a.ID FROM tbl1 a OUTER APPLY (SELECT ID_NonIdentity FROM Tbl2 b WHERE a.ID_NonIdentity=b.ID_NonIdentity) z WHERE z.ID_NonIdentity IS NULL SET STATISTICS TIME OFF --QUERY 5 DBCC FREEPROCCACHE DBCC DROPCLEANBUFFERS SET STATISTICS TIME ON SELECT ID FROM tbl1 a EXCEPT SELECT ID FROM tbl2 b SET STATISTICS TIME OFF
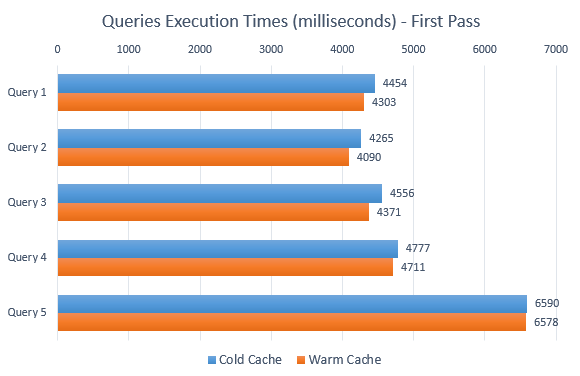
Looking closely at the execution plans, utilizing NOT EXISTS and NOT IN produced identical query plans with Right Anti Semi Join being the most expensive operation here.
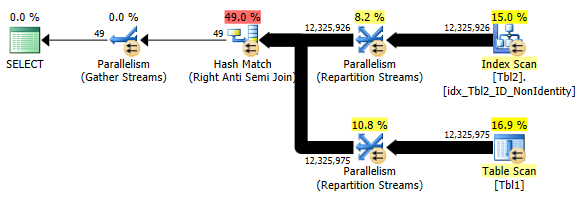
This was somewhat similar to OUTER APPLY and LEFT OUTER JOIN, however for those two query types the optimizer chose Right Outer Join which seemed a little bit more expensive compared to Right Anti Semi Join due to the query bringing in all matching and non-matching records first and then applying a filter to eliminate matches as per image below.
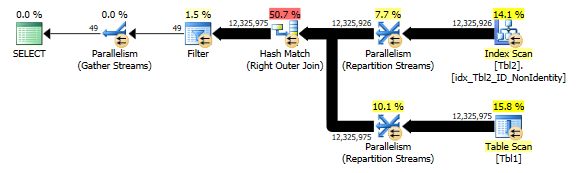
Using EXCEPT yielded similar execution plan to NOT EXISTS and NOT IN with the exception of optimizer utilizing Hash Match (Aggregate) to build a hash table in order to remove duplicates. This is an important point to make as EXCEPT includes implicit DISTINCT – if cases multiple rows with the same value are found, they will be eliminated from the left ‘side of the equation’ much like UNION vs. UNION ALL operators. Not an issue in this specific instance but something to watch out for when planning to query data differences.
Regardless of the slight differences in execution plans, all queries with the exception of the one using EXCEPT run in a comparable time. Typically, such statements in a production environment would run over a potentially larger datasets with much more complex logic involved so larger variances can be expected. Generally though, performance is maintained on par and disparities should be minimal. Also, removing indexes from both tables did little to increase execution time for the above queries. But what happens if we enable NULL values ID_NonIdentity attribute? Let’s execute the following SQL to change column NULLability and run the representative SQL SELECT statements again to see if a change can be attributed to ID_NonIdentity accepting NULL values. Notice that there is no change to the underlying data and previously created indexes are still in place.
ALTER TABLE Tbl1 ALTER COLUMN ID_NonIdentity int NULL GO ALTER TABLE Tbl2 ALTER COLUMN ID_NonIdentity int NULL GO
Execution times are as per the chart below and it’s clear to see that while query 2, 3, 4 and 5 behaved in a predictable manner and returned all records within respectable time, query 1 failed abominably.
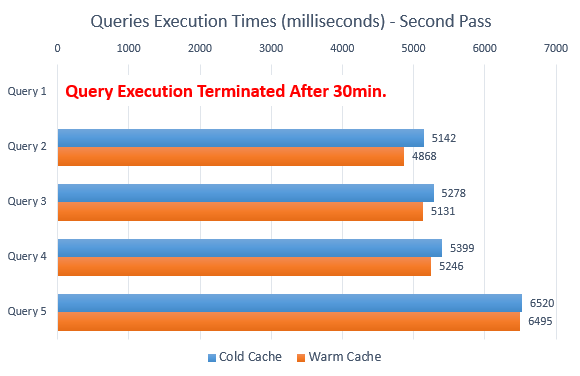
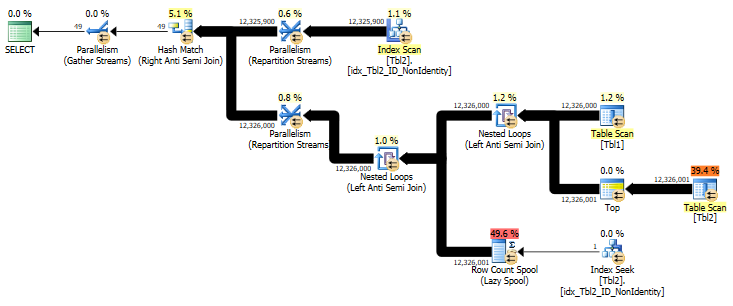
The main problem here is that the results can be surprising if the target column is NULLable as SQL Server cannot reliably tell if a NULL on the right side is or isn’t equal to the reference record on the left side when executing the query using NOT IN clause. And that’s regardless whether the column actually contain any NULL values or not. I let query 1 to run for 30 minutes after which it was clear that it was going to take a while to complete and was a good indication of the problems the NOT IN clause was causing to optimizer trying to select the most representative plan. You can also tell that the query plan generated after the column modification is quite a bit more involved with Nested Loops, Row Count Spool and heavy tempdb database usage to accomplish what seemed straightforward in the first pass.
Conclusion
The upshot to this quick exercise in query performance is that whenever you plan to compare data in table A against data in table B where some condition does not exists in table B, using NOT IN clause should be avoided as much as possible. This, of course will be dependent on your workloads, hardware, data, schema and environment in general but it would be safe to say that using NOT EXISTS instead of NOT IN would most likely result in best query performance and execution time.
http://scuttle.org/bookmarks.php/pass?action=addThis entry was posted on Wednesday, February 12th, 2014 at 1:42 am and is filed under SQL. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.



Hello Kind of what I've been looking for - thanks for posting. I don't use Snowflake but gives me an…