Protecting PHI & PII data at Scale with LLMs using Snowflake, LangGraph and Streamlit for Human-in-the-Loop QA
Note: All code supporting this architecture can be downloaded from my OneDrive folder HERE.
Introduction
Organizations working with clinical data face a persistent problem: free-text clinical notes are among the most analytically valuable assets in a health data platform, yet they are also the most sensitive. Patient names, dates of birth, Medicare numbers, addresses, phone numbers, staff identifiers – these are embedded throughout care documentation in ways that are structurally unpredictable, clinically nuanced, and impossible to reliably sanitize with simple regex alone. The consequence is that access to this data is heavily restricted, manual sanitization is slow and inconsistent, and downstream AI and analytics use cases are perpetually blocked behind approval gates.
The conventional responses – regex-only scrubbing, commercial NLP tools, or synthetic data generation – each carry their own failure modes. What the problem actually demands is a layered, hybrid approach: combine the deterministic reliability of pattern matching with the contextual reasoning of large language models and the structural recognition of named entity recognition models, wrap all of it in a governed pipeline with human review capability, and make the whole thing configurable without requiring code changes.
That is what this post describes. This architecture is a config-driven de-identification pipeline built on LangGraph, powered by Snowflake Cortex for all LLM inference and deployed on Snowpark Container Services (SPCS) for optimal runtime. Rather than calling external model APIs, every LLM completion in the pipeline – normalization, entity detection, de-identification, validation, and QA feedback – runs through Snowflake’s native CORTEX.COMPLETE() function, keeping data processing within the Snowflake boundary. This solution can be hosted on SPCS against a Snowflake-hosted schema and includes a Snowflake-native deployment: the inference layer, the data store, the audit logs, the whitelist management, the containerized service deployed into SPCS for runtime and the Streamlit-based review console all live within Snowflake.
Why LangGraph?
Before getting into the architecture, it is worth explaining the choice of LangGraph as the orchestration framework. LangGraph is an open-source library within the LangChain ecosystem designed specifically for stateful LLM and agent workflows. Its core model is a directed acyclic graph (DAG) with shared state, typed nodes, and conditional edges – it is aimed at long-running workflows or agents that may need memory, branching, tool use, persistence, retries, and human review.
For a de-identification pipeline this is an excellent fit. The reasons are practical rather than theoretical:
- Typed shared state – every node reads from and writes to a single DeidState TypedDict, so inter-node data contracts are explicit and enforced at the Python type level.
- Native parallel fan-out – running three or four detectors in parallel is expressed as a proper DAG fan-out, not threads bolted on top of a function chain.
- Conditional edges – the validate → retry → de-identify loop is a first-class concept in LangGraph, not a workaround.
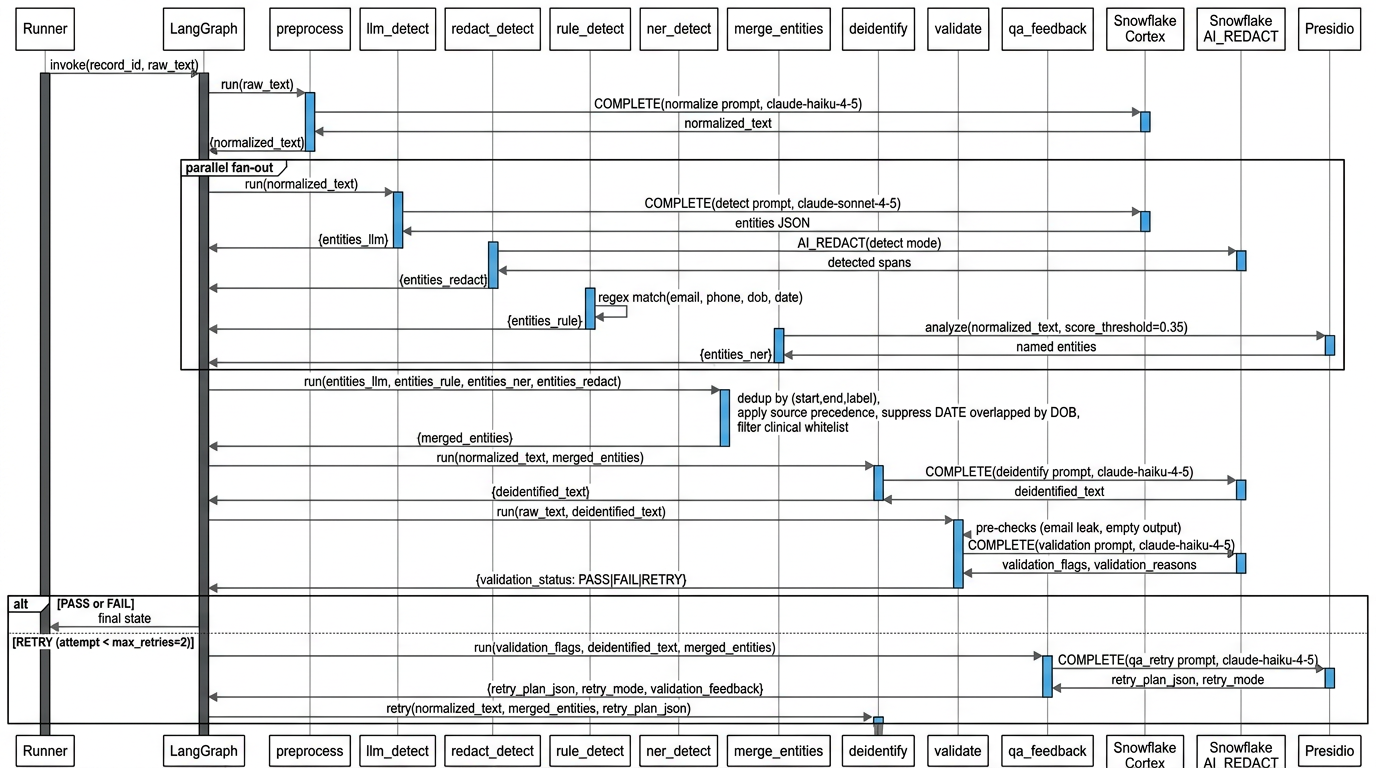
- Observability – LangGraph’s built-in Mermaid and ASCII graph renderers mean you get a live, accurate picture of whatever topology the YAML has produced, including which nodes are enabled and which models they are running.
Architecture Overview
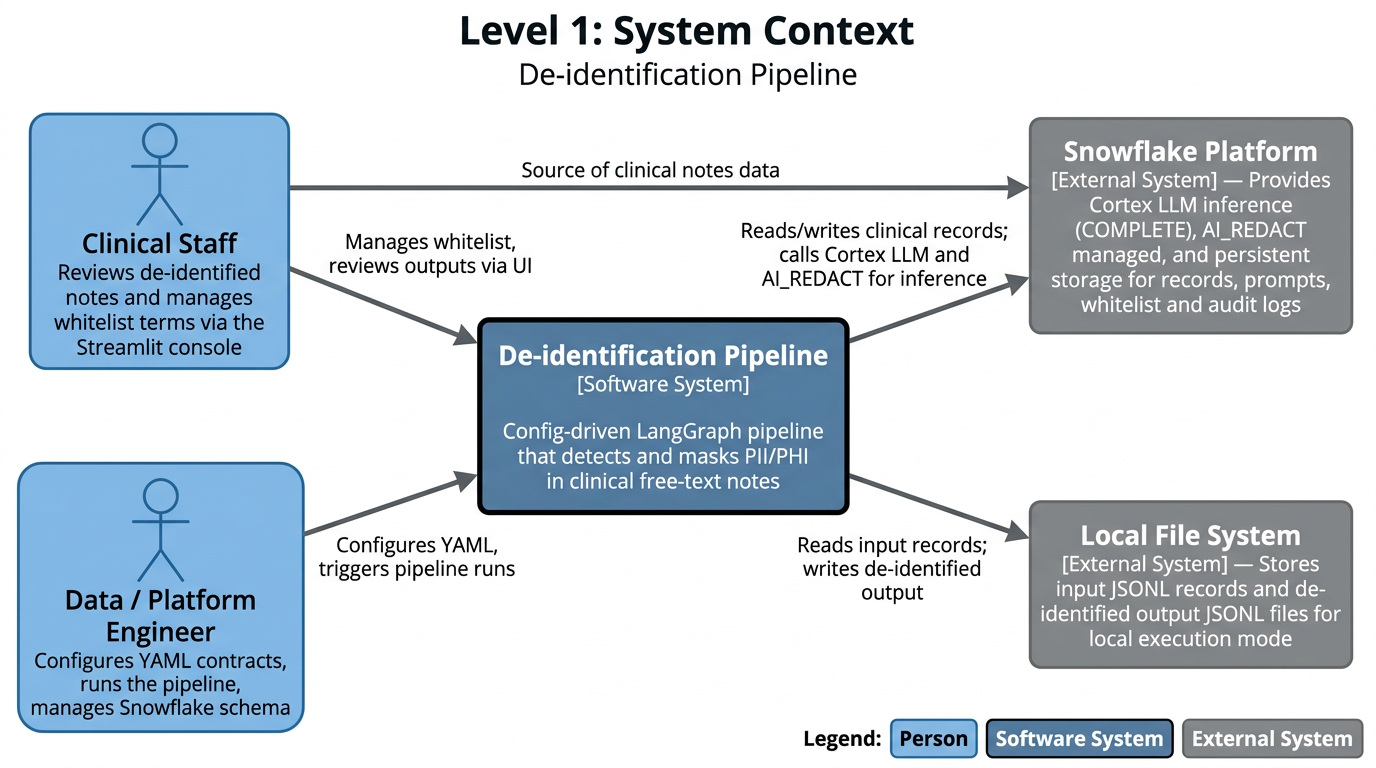
The pipeline sits at the center of a small ecosystem of two human roles and two external system dependencies. Data engineers own the operational layer – configuring YAML contracts that govern pipeline behaviour, triggering runs, and managing the Snowflake schema – without needing to touch Python code. Clinical staff are both the source of the notes being processed and the consumers of de-identified output, interacting with the system through a Streamlit review console.
Snowflake is the primary external dependency, playing a dual role: it is both the inference backend (via SNOWFLAKE.CORTEX.COMPLETE() for LLM calls and AI_REDACT for managed PII detection), hosting platform and the persistence layer for clinical records, prompt version history, QA audit logs, and the clinical whitelist table. The local file system supports an alternative execution mode for development and testing without requiring Snowflake credentials.
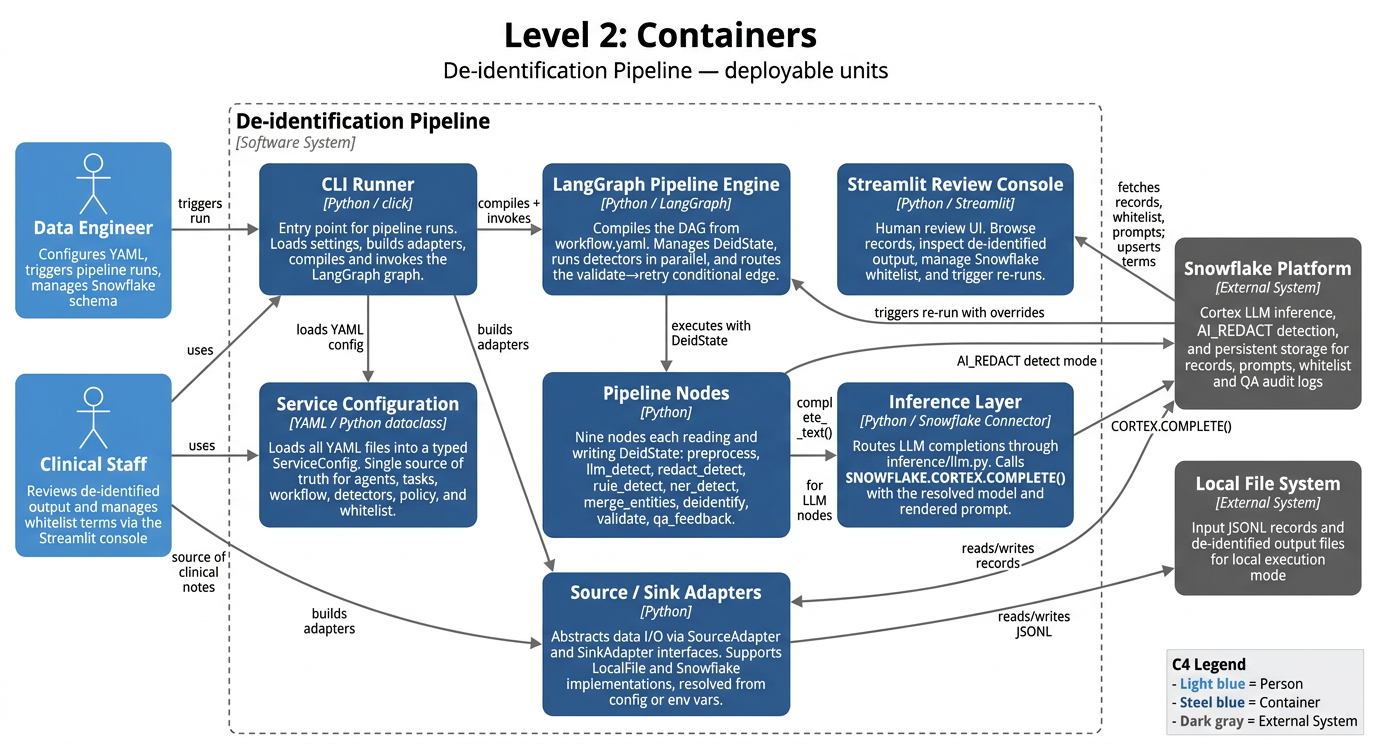
All pipeline behavior – workflow topology, LLM model selection, prompt templates, detector rules, masking policy, and validation thresholds – is declared in a bundle of YAML files loaded into a central ServiceConfig dataclass at startup. The system can be reconfigured without touching Python code. At runtime, a LangGraph pipeline engine compiles these settings into a DAG and orchestrates nine processing nodes.
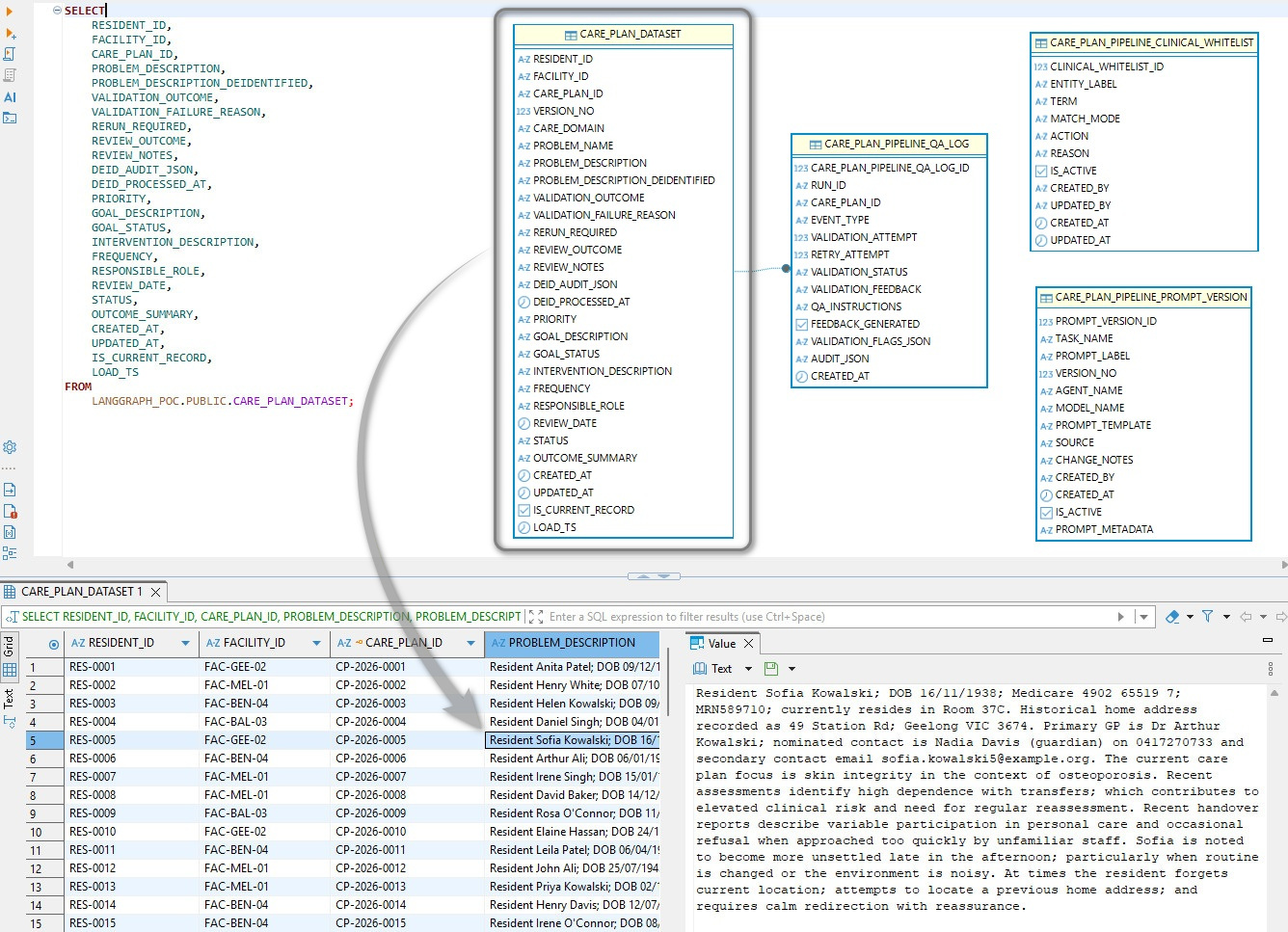
The Snowflake schema is centered on CARE_PLAN_DATASET, which stores the core care-plan record (resident/facility/care plan IDs, clinical narrative fields, validation outcomes, review metadata, and audit timestamps) with IS_CURRENT_RECORD and LOAD_TS supporting versioned ingestion. Resident description data was synthesized using LLM and while it hasn’t been checked for clinical accuracy, its content should align with typical aged care resident scenarios. Around that, the pipeline is governed by supporting tables capturing run-level QA/validation events and feedback, providing controlled prompt/model versioning and approved clinical term matching rules used by the validation workflow.
Node-by-Node Breakdown
The pipeline runs nine nodes in sequence. Each has a clearly scoped responsibility and a defined set of state fields it reads from and writes back to. Nodes requiring LLM inference call Snowflake Cortex at temperature 0.0. Nodes that don’t require inference run as pure Python with no external calls.
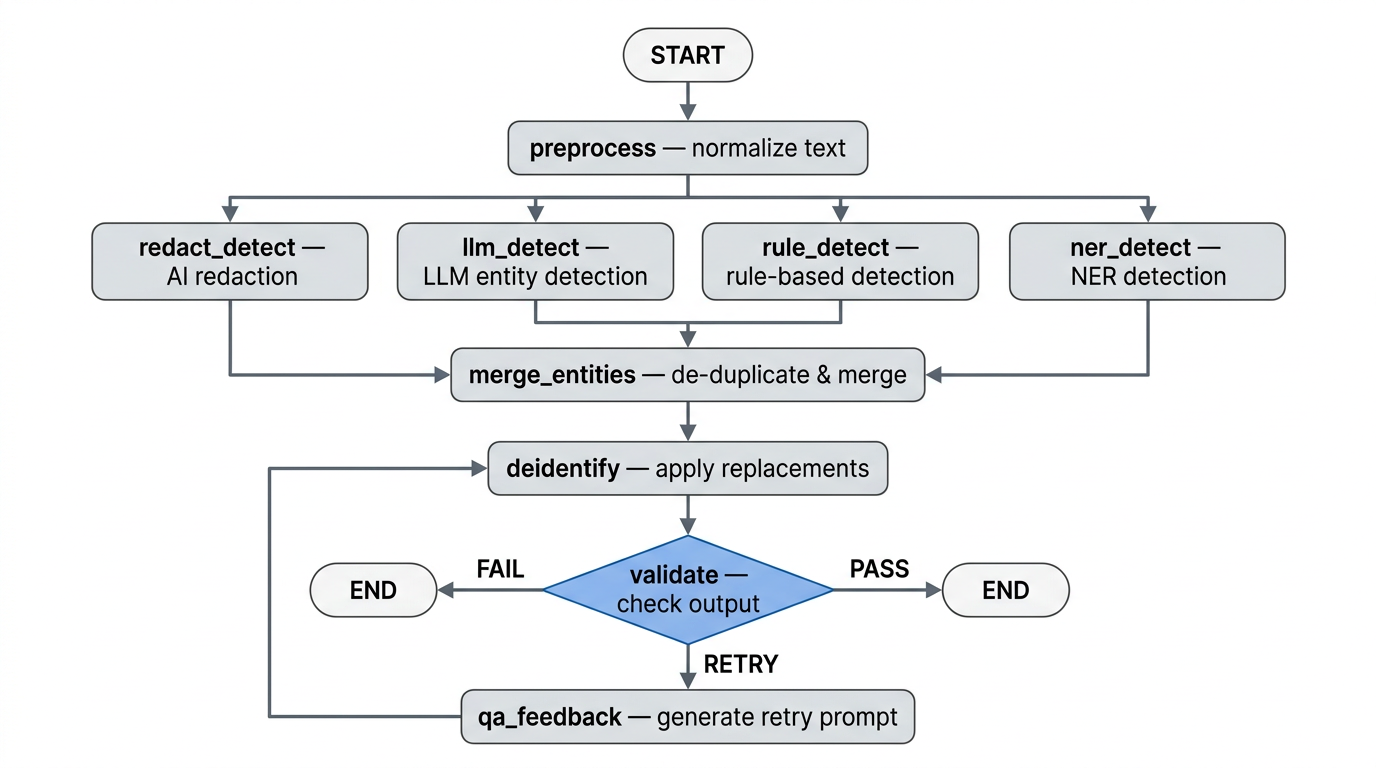
preprocess – Normalize Text
Takes raw_text from state and produces normalized_text with minimal cleanup: collapsing whitespace and fixing unambiguous OCR artifacts. The constraint is faithfulness – names, numbers, dates, and clinical facts must be preserved exactly as written. claude-haiku-4-5 is used here because normalization is low-risk and cost per token matters at scale.
llm_detect – LLM Entity Detection
The primary, highest-recall detector. Sends normalized_text to claude-sonnet-4-5 via Snowflake Cortex with a prompt instructing it to identify all PII/PHI spans and return strict JSON only. Entity types targeted: NAME, STAFF, PHONE, EMAIL, ADDRESS, LOCATION, DOB, DATE, ID, ORGANISATION. The model prefers recall over precision and returns exact character-level start and end offsets. Sonnet is used rather than Haiku because distinguishing a patient name from a facility name, or finding a Medicare number in free prose, requires genuine clinical context understanding.
redact_detect – Snowflake AI_REDACT
Delegates to Snowflake’s native AI_REDACT SQL function in detect mode, which returns detected spans rather than masked text. Results are mapped into the shared entity schema. This layer is fast, auditable, and makes no additional LLM call – it serves as a redundant coverage layer for spans the LLM detector misses or mis-indexes.
rule_detect – Regex Pattern Detector
Fully deterministic, no external calls. Compiled regex patterns from detectors.yaml are applied directly to normalized_text using Python’s re module. The pattern set covers four high-confidence types: EMAIL, PHONE, DOB (only when preceded by an explicit label such as “DOB:” or “Date of Birth:”), and DATE (only in unambiguous formats). The rule detector only fires on unambiguous structural patterns and never infers – its value is zero false-negative misses on structured entities, providing an auditable baseline that operates independently of any model.
ner_detect – Named Entity Recognition (Presidio)
Runs Microsoft Presidio’s AnalyzerEngine over normalized_text at a score threshold of 0.35. Presidio provides contextual entity recognition beyond what regex can capture – particularly for person names, locations, and organizations without a fixed structural pattern. It uses spaCy or Hugging Face transformers as the underlying NER engine, running locally with no external API call.
merge_entities – Deduplicate and Merge
Once all four detector branches complete, LangGraph synchronizes at merge_entities. Entities are iterated in configured source precedence order (llm – rule – ner – redact), keyed on (start, end, label). Duplicates are dropped on a first-source-wins basis. A DATE entity overlapping a DOB entity is also dropped, since DOB is the more specific classification. The surviving list is sorted by character offset ascending.
Before the final list is written to state, each entity is checked against the clinical whitelist. Matches are silently dropped and never reach the de-identify node. This is what prevents the pipeline from masking common clinical vocabulary – terms like “daily”, “nocte”, or “mobility” – which detectors may legitimately tag but which carry no privacy risk in context. The whitelist is managed in clinical_whitelist.yaml for file-based runs and in a Snowflake-backed table editable through the Streamlit console at runtime.
deidentify – Apply Masking
Applies the replacement policy from deid_policy.yaml over normalized_text using merged_entities. Each span is replaced with a bracketed label token – [NAME], [DOB], [PHONE] – with a default template of [{LABEL}] for anything not explicitly mapped. Replacements are applied right-to-left so that modifying a span later in the string does not invalidate the offsets of earlier spans. On retry passes the node receives a structured repair plan from state and applies only the narrow QA-directed corrections rather than re-running the full masking pass.
validate – Quality Gate
Validation runs in two layers. First, deterministic Python pre-checks with no LLM call flag obvious failures such as a potential email leak or empty output. Second, claude-haiku-4-5 audits the output for residual PII/PHI leakage or severe readability breakage under a permissive standard – minor stylistic differences are not flagged. The model returns validation flags, human-readable reasons, and issues, each requiring an evidence substring copied directly from the de-identified output. The conditional edge then routes: PASS to END, FAIL to END with audit logging, and RETRY to qa_feedback if the attempt count is below max_retries (default 2, configurable in validation.yaml).
qa_feedback – Retry Prompt Generation
Only reached on a RETRY route from validate. Translates the validation output into a structured JSON repair plan for the deidentify node, containing a retry mode, entity-level corrections (drop, relabel, or adjust span), exact substring text replacements, and an acceptance criteria checklist. The model is instructed to prefer targeted corrections over broad rewriting and to flag likely false positives explicitly rather than correcting them blindly.
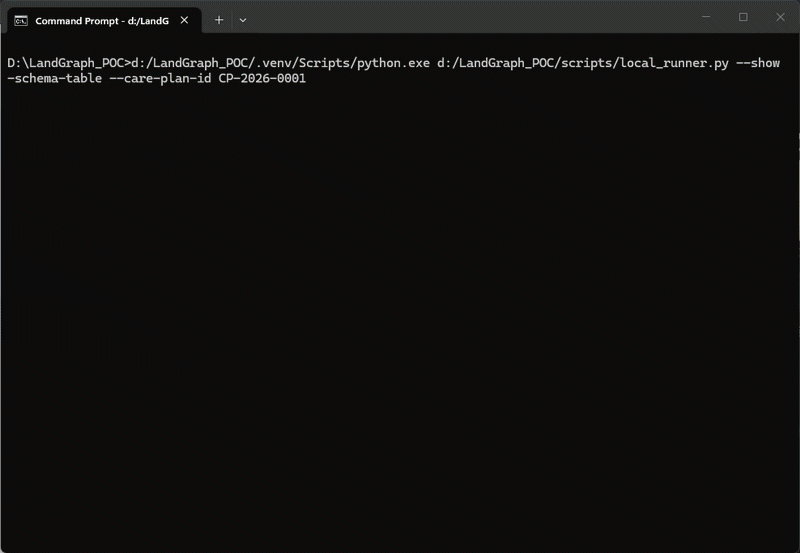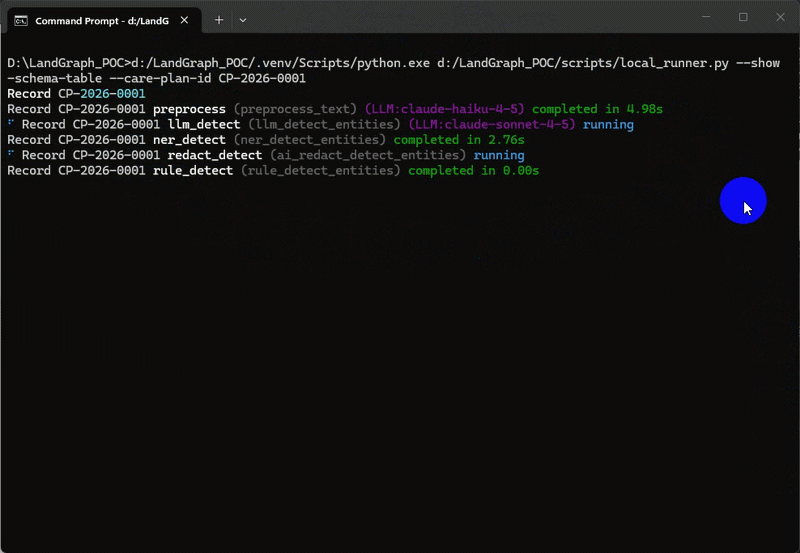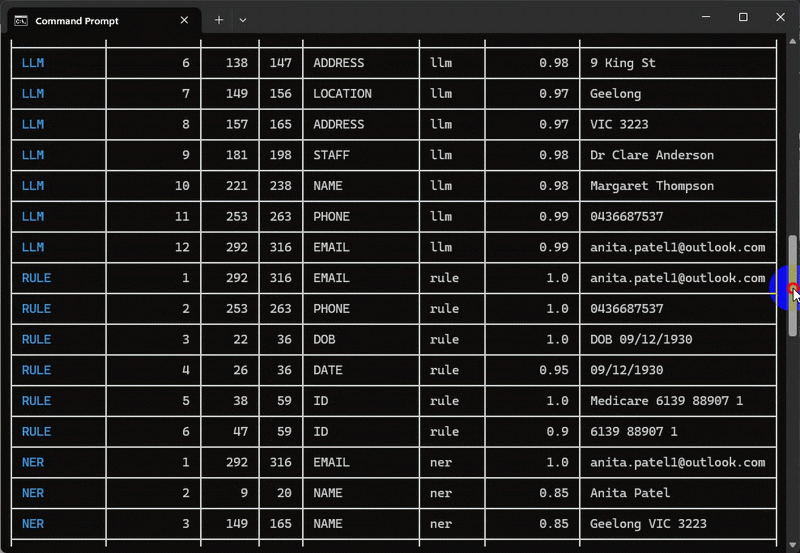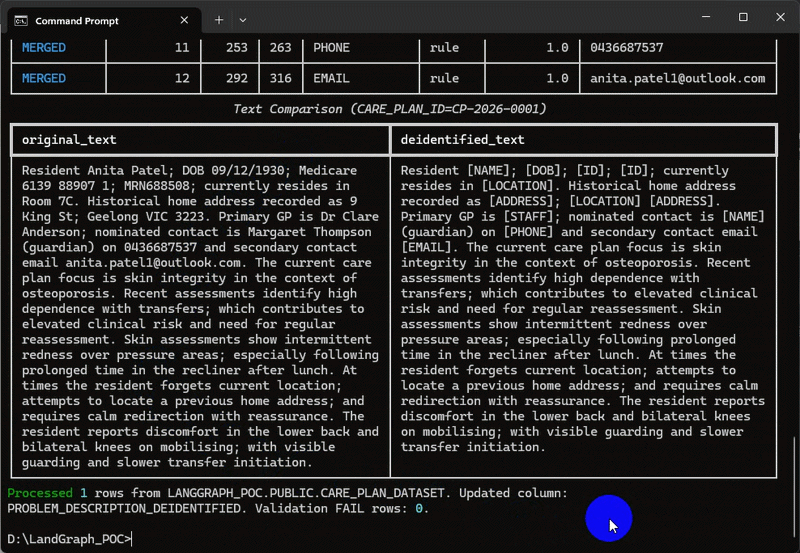
The following screen capture depicts the de-identification pipeline running in terminal for a single care plan id with the added option to display two tables – first one containing summary (counts) of PPI/PHI entities for each active detector and the second one providing additional details for each entity found e.g. starting and ending index, confidence score etc. alongside the actual entity text.
The Streamlit Review Console
The Streamlit application is the operational front-end of the de-identification platform. It translates a technically complex, multi-step NLP/LLM workflow into an interface that clinical, data, and governance users can run safely and repeatedly. Rather than treating de-identification as a one-off batch script, the app positions it as a managed process with monitoring, controls, and auditability built in.
From an architecture perspective, the app has a clean layered model. The presentation layer handles user interaction, filtering, and visualization. A session and state layer tracks selected filters, model choices, and run state across reruns. An orchestration layer manages background execution and stop requests. The runtime layer invokes the configurable de-identification graph. The persistence layer reads and writes operational data to Snowflake. This separation is important because it allows each concern to evolve independently – interface changes do not require workflow rewrites, and model or prompt updates do not require UI redevelopment.
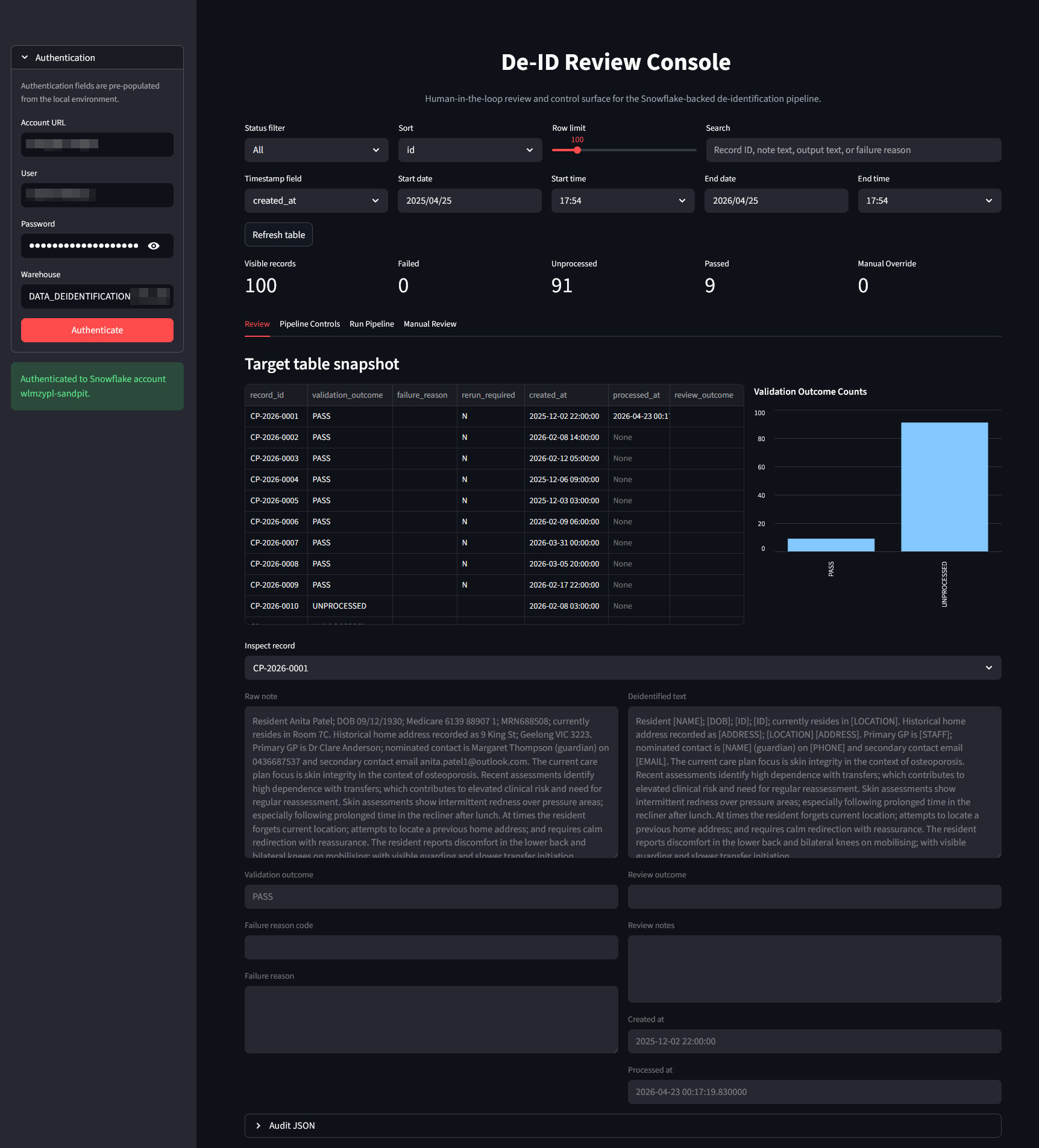
Once authenticated, users move into a structured record exploration workflow. They can filter records by lifecycle state (failed, unprocessed, passed, manual override), narrow by free-text search, and constrain by timestamp windows. This gives teams operational triage capability: QA reviewers can prioritize records requiring intervention, while engineering or analytics teams can inspect trends and isolate specific cohorts.
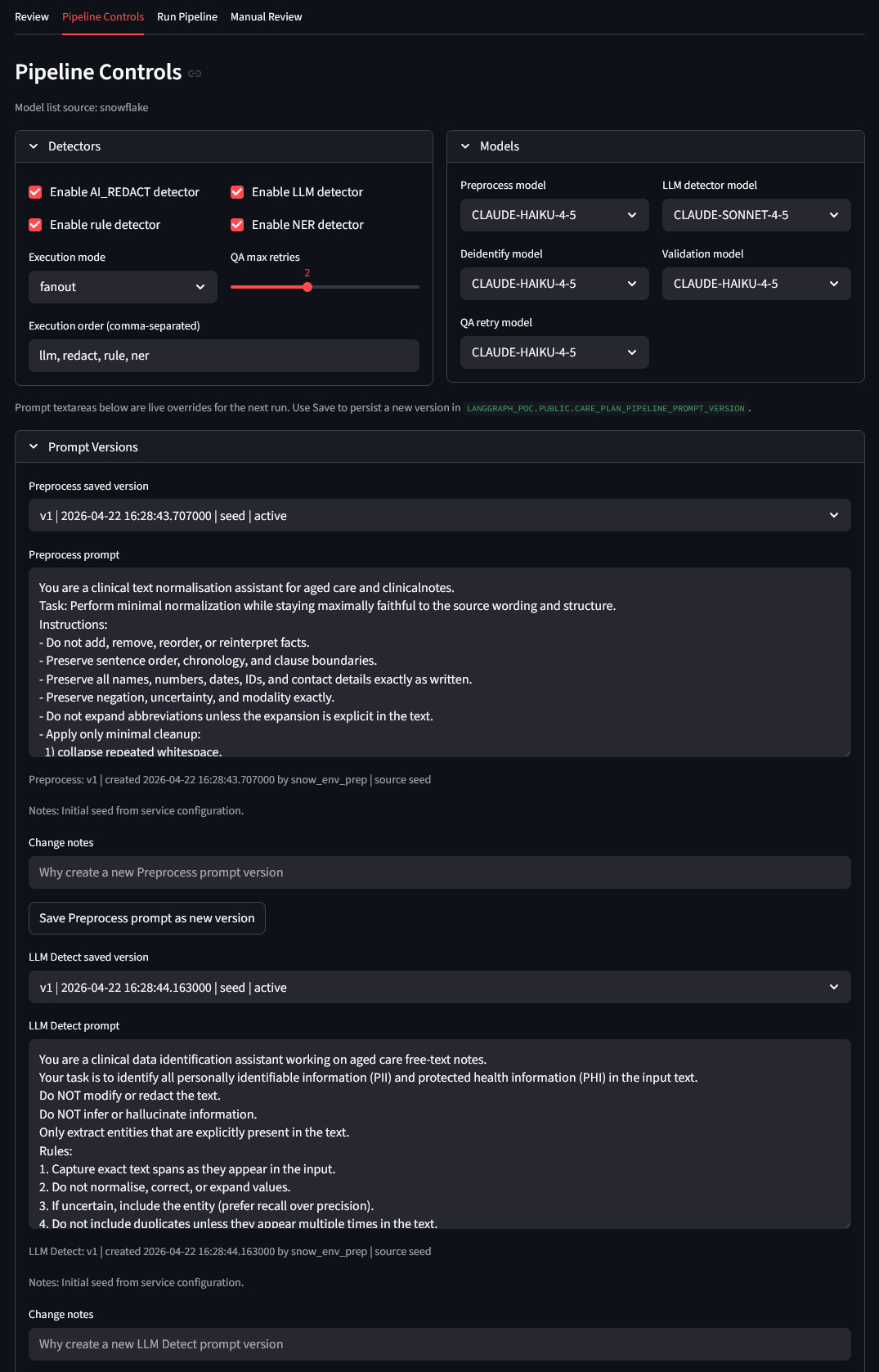
A core capability is runtime configurability. The app exposes detector toggles and execution strategy (parallel fanout or sequential), QA retry limits, and per-task model selection. This enables controlled experimentation and tuning without direct code edits. Teams can respond quickly to operational findings, such as adjusting model assignments or changing detector execution order when false positives or misses are observed.
Prompt lifecycle management is treated as a first-class operational function. Users can view saved prompt versions by task, load a baseline or historical version, apply temporary live overrides for the next run, and persist a new version with metadata and change notes. This establishes a practical governance loop: prompt edits are traceable, versioned operational artifacts rather than ad hoc text changes buried in code.
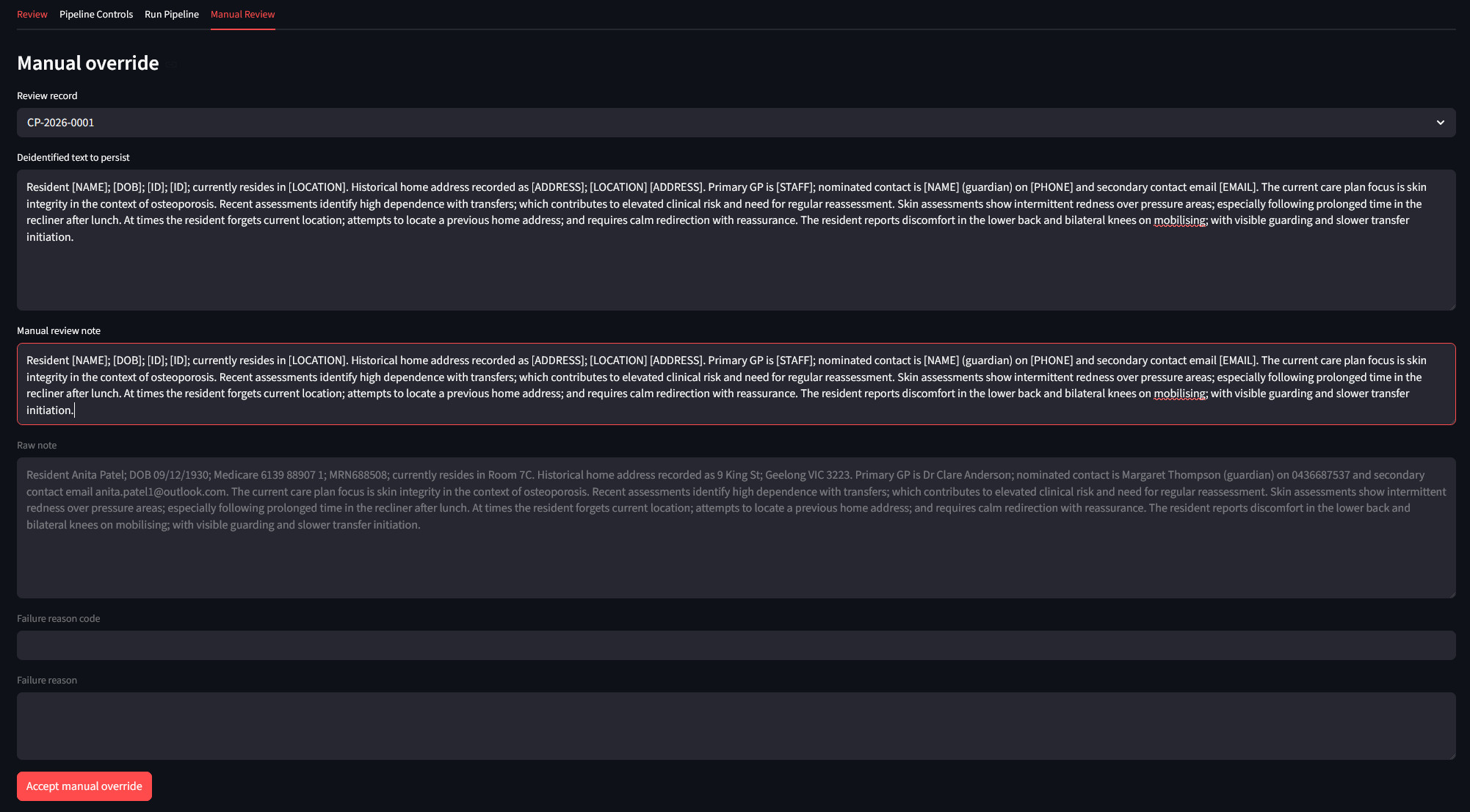
Where automation is insufficient, a manual review capability closes the loop. A reviewer can edit de-identified output, provide review notes, and persist an explicit acceptance decision. This ensures difficult cases are resolved in-system rather than through offline workarounds. The result is a complete human-in-the-loop pathway: automated detection and transformation, machine validation and retry, then reviewer adjudication when needed.
Snowpark Container Services (SPCS) Deployment
One of the deliberate architectural decisions in this solution is that Snowflake is not just a data store – it is the runtime. All LLM inference runs through Snowflake Cortex, all persistent state lives in Snowflake tables, and the Streamlit review console is designed to run as a Snowflake-hosted app.
Snowpark Container Services (SPCS) allows Docker containers to run directly within a Snowflake account, with native access to Snowflake objects, secrets, network egress rules, and compute pools – without data ever leaving the Snowflake boundary. For runtime, the solution deploys a Python FastAPI de-identification service into SPCS, exposing an internal HTTP endpoint that is called through a Snowflake service function, thus allowing SQL users and procedures to run the LangGraph de-identification workflow against care plan records stored in Snowflake. The runtime is containerized from the project Dockerfile and deployed by scripts/deploy_spcs.py. Deployment creates the Snowflake image repository, pushes the container image, uploads the rendered SPCS service specification, creates the compute pool and service, and registers the SQL function/procedure used to invoke the service.
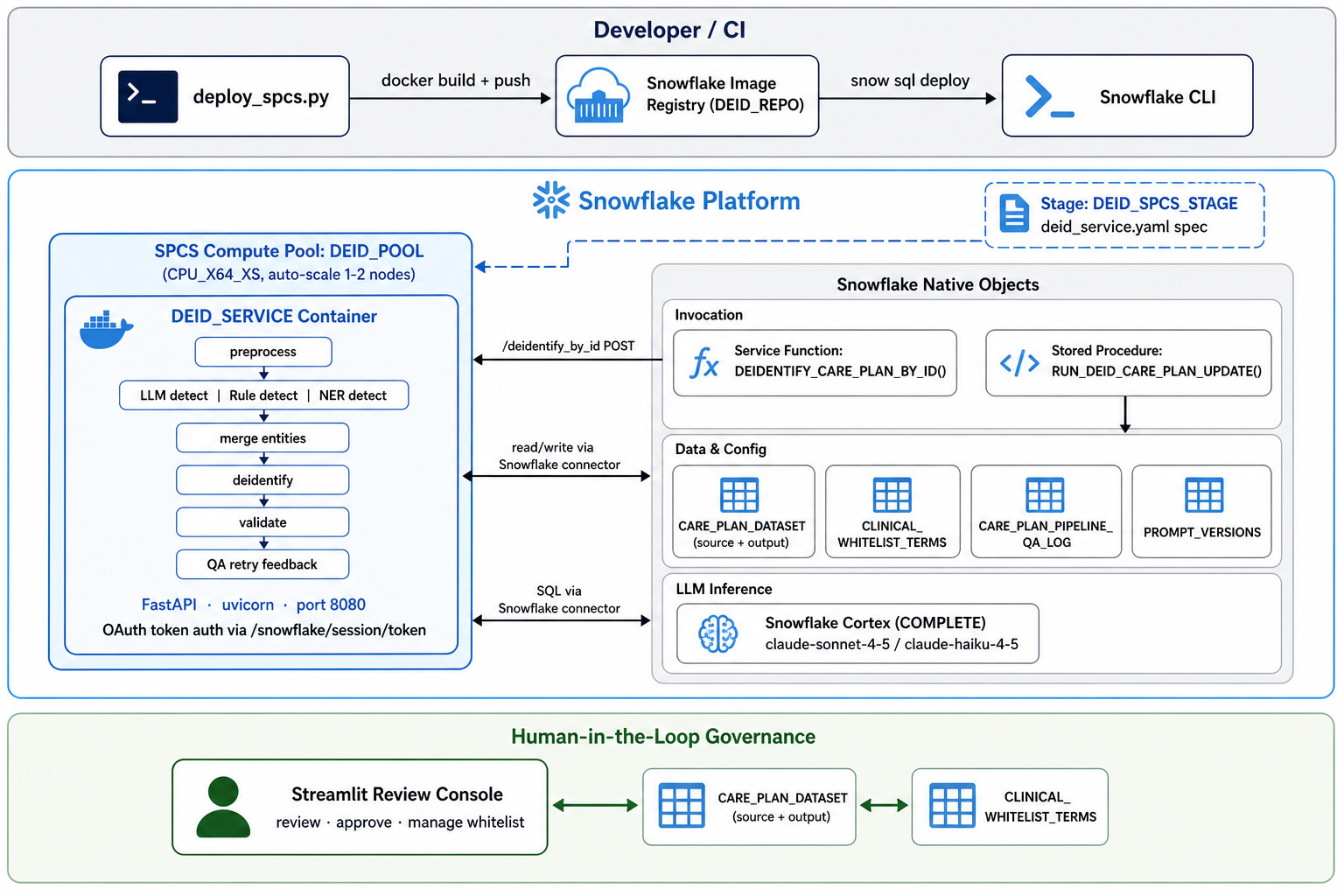
End-user implementation relies on a dedicated stored procedure, which persists de-identified output back to the care plan table, including de-identified text, validation outcome, failure reason, rerun flag, audit JSON, and processed timestamp. The service endpoint is private – this means the container is invoked internally by Snowflake service functions rather than being exposed publicly.
The result is a fully enclosed deployment topology: the pipeline container runs in SPCS, the LLM calls go through Cortex, the operational data stays in Snowflake tables, and the governance UI runs as a native Snowflake app. Governed data access, audit logging, network isolation, and compute scaling are all handled by the platform rather than bespoke infrastructure. For organizations already invested in Snowflake as their data platform, this means de-identification capability can be deployed and operated without introducing any additional services, vendors, or egress risk.
Efficacy Testing
Testing was conducted on 100 synthetically generated aged care resident notes containing GP and resident names, addresses, phone numbers, email addresses, and Medicare numbers. The initial run used claude-sonnet-4-5 for LLM detection and claude-haiku-4-5 for preprocessing, validation, de-identification, and QA feedback.
Initially, 31 of the 100 records failed validation. Every failure had the same root cause: the word “daily” in the phrase “activities of daily living” was being tagged as a DATE entity and masked as [DATE], producing the nonsensical output “activities of [DATE] living”. The validation model correctly flagged this as a material readability failure, and the QA feedback node described it precisely: “Incorrect placeholder substitution: ‘daily’ (a non-sensitive clinical descriptor) was replaced with ‘[DATE]’, creating semantic corruption. The phrase ‘activities of [DATE] living’ is nonsensical and impairs clinical readability. Switching LLM models made no difference. The root cause was not in the validation or feedback logic – it was in the detection layer. “Daily” pattern-matches temporal heuristics, and without a suppression mechanism it will be consistently mis-tagged. The fix required no code changes. Adding “daily” and related terms to clinical_whitelist.yaml and the corresponding Snowflake whitelist table achieved a 100% pass rate on the same records. This result illustrates something important about hybrid detection pipelines: failure modes are systematic and fixable at the configuration layer. The LLM correctly identified “daily” as a temporal descriptor – the problem is that in a clinical note it is standard vocabulary, not a sensitive identifier. That distinction requires domain knowledge, and the whitelist is the mechanism for encoding it.
Conclusion
The architecture described here shows that a governed, accurate de-identification pipeline does not require a monolithic NLP platform or a dedicated modelling team. YAML-driven configuration, hybrid detection with explicit precedence, a clinical whitelist for false-positive suppression, LLM-backed validation with structured retry, and a Streamlit console for human-in-the-loop governance each solve a specific, real problem – and none of them require code changes to reconfigure.
The system is also very extensible. Adding a detector, changing a prompt, or adjusting a masking policy is a configuration change. The Snowflake-native deployment means no separate infrastructure to manage. For teams looking to move beyond ad hoc de-identification, this is a practical and productizable starting point.
http://scuttle.org/bookmarks.php/pass?action=addThis entry was posted on Wednesday, May 13th, 2026 at 2:15 pm and is filed under Snowflake. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.



Great post Martin and I found that the source code worked well. My company was about procure and deploy an…