Snowflake Scale-Out Metadata-Driven Ingestion Framework (Snowpark, JDBC, Python)
Note: All code from supporting this architecture can be downloaded from my OneDrive folder HERE.
Introduction
Organizations looking to modernize and improve their data ingestion capabilities have traditionally relied on ETL/ELT tools for their data ingestion and transformation needs. This created a thriving tangential industry, with a wide ecosystem of tools fit for all possible scenarios, however, relying on a separate platform for ETL/ELT introduces additional costs and complexity. Specifically, external ETL tools demand extra licensing fees which are often tied to data ingress/egress volumes or API calls. They also create architectural complexity as developers need to become familiar with the functionality, creating more cognitive load and distracting from the main problem statement. This usually results is harder maintenance, slower development, and a lack of unified governance over the entire data lifecycle.
The rise of the modern Data Cloud, particularly Snowflake, offers a powerful alternative: building sophisticated ETL/ELT pipelines directly within the platform using native code. By leveraging key features like JDBC/ODBC connectivity for seamless data movement, User-Defined Functions (UDFs) for custom, reusable logic, and the scale-out power of Snowpark (which allows data engineers to write Python, Java, or Scala code), we can bypass proprietary external tools completely.
The following solution design offers a simple metadata-driven ingestion framework (baseline implementation) for loading data from Azure SQL Database or other JDBC-supported RDBMS engines into Snowflake with intelligent parallelization and cluster-aware scaling. Built as a single scalable process, the solution implements a work-stealing pattern where workers continuously pull tasks from a dynamic queue as they complete, ensuring optimal resource utilization across multi-cluster Snowflake warehouses. The framework operates entirely through centralized metadata tables that define source-to-target mappings, partitioning strategies, JDBC configurations, and column-level transformations, enabling automated schema introspection and dynamic query construction without hard-coded configurations. It features Snowflake secrets integration for secure connection, comprehensive error handling with task-level failure recovery, and linear scalability that automatically adapts to different warehouse configurations.
The following diagram depicts the framework’s high-level topology and how each of these components work in concert to ingest source data into Snowflake landing objects (click on image to enlarge).
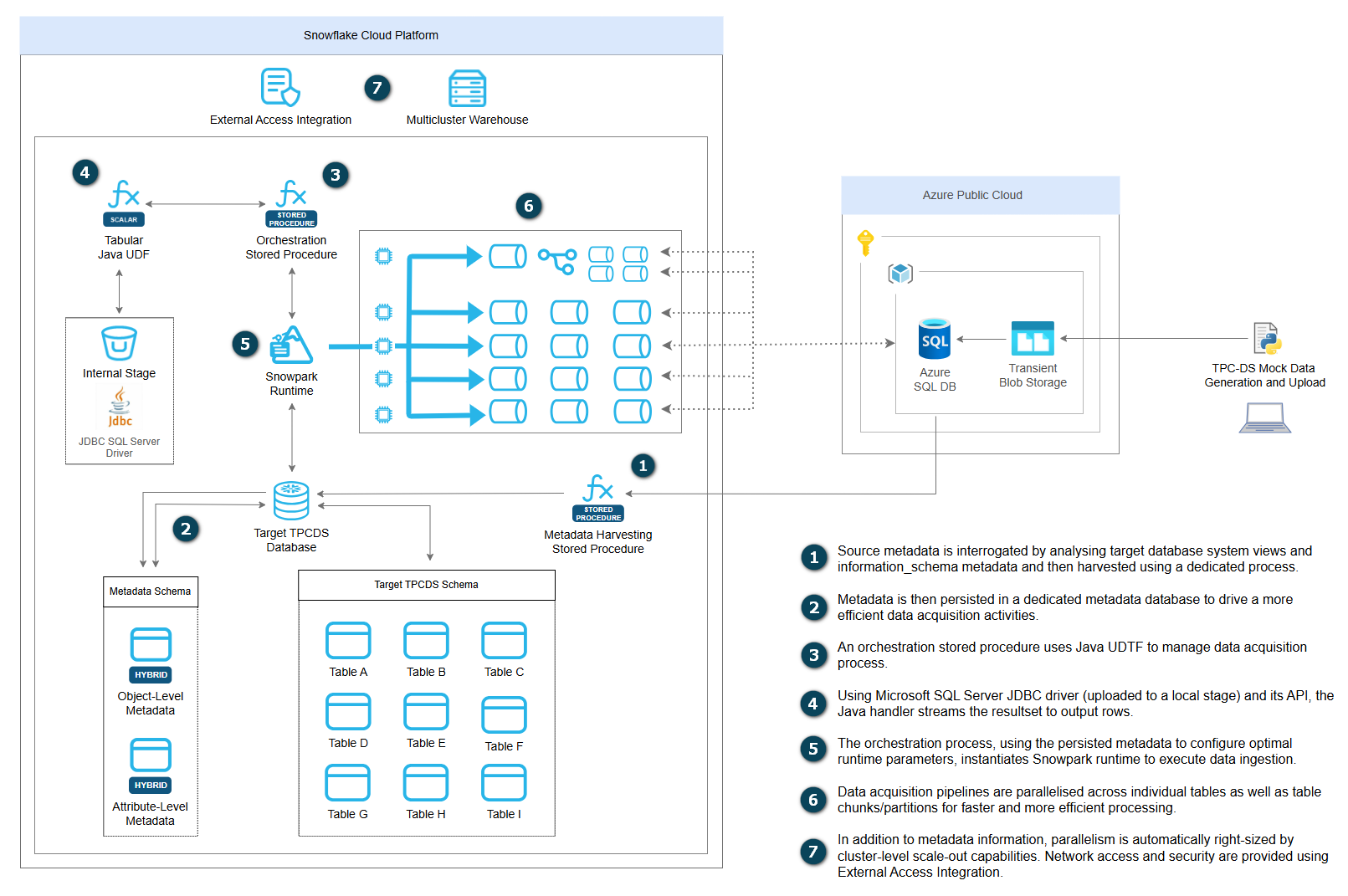
Source Data and Environment Prep
To demonstrate how this architecture works in practice, this demo utilizes a standard TPC-DS dataset (10GB volume) as a data source. The source data files (csv format) generated by TPC-DS utility were uploaded to a newly created Azure Blob container and then loaded into the Azure SQL Database. As TPC-DS utility does not generate headers which are useful for a range of subsequent data operations, a separate script was used to “merge” header files (also csv file format) with the TPC-DS output files.
On the Snowflake end (target environment) a dedicated database and metadata schema were created. The metadata schema is used to store two objects which govern data ingestion execution at a table and down to individual attributes level – etl_meta_object table is designed to hold all object-specific information e.g. row counts, source schema and table name, index size, data size, partition key whereas etl_meta_attribute table goes down to the individual field level, capturing information such as column name, data type, numeric precision and scale etc. This metadata-driven approach enables automated schema introspection, intelligent partition boundary calculations, and dynamic query construction without hard-coded configurations.
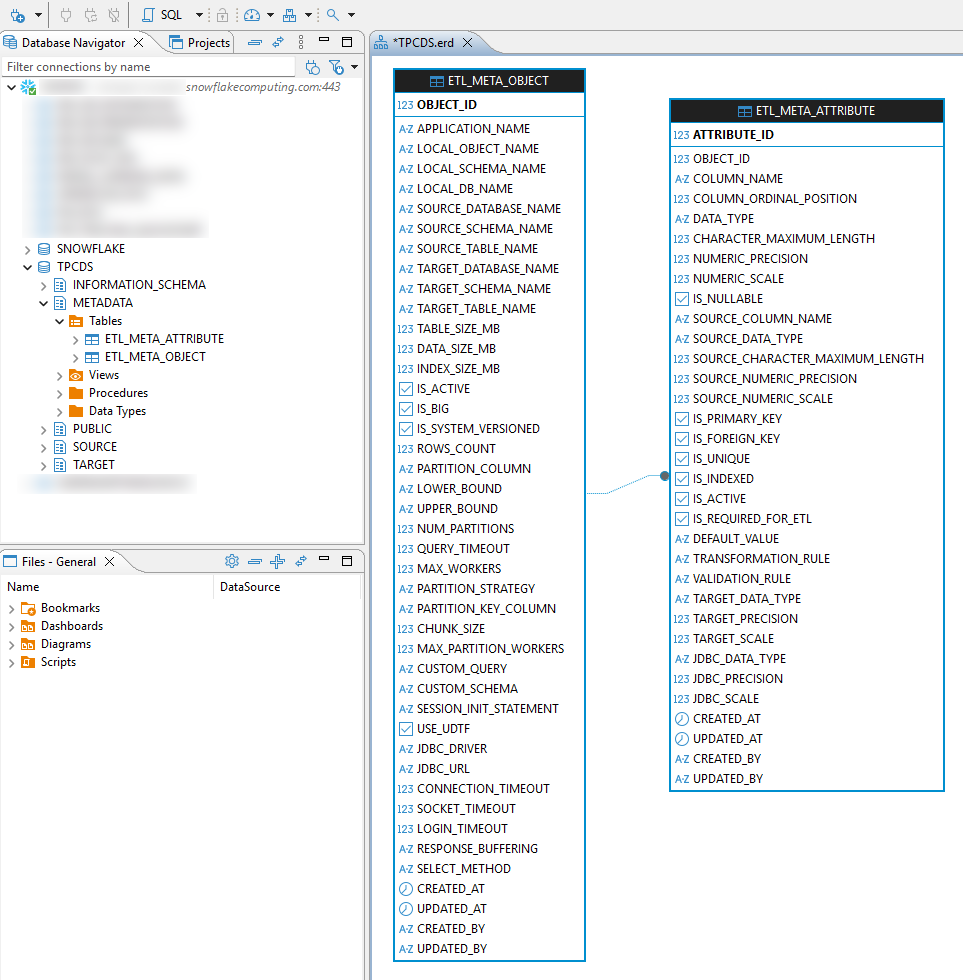
TPC-DS tables were replicated in the public schema, creating a like-for-like source-to-target mapping between the Azure SQL DB and Snowflake environments. The stage used for storing JDBC driver which provides the required API for interfacing Azure SQL DB with Snowflake was also created in the metadata schema. A dedicated script (utilizing Snow CLI) handles downloading, decompressing, and uploading JDBC driver from one of Microsoft’s repositories. The JDBC components provide encrypted connections, optimized connection pooling, and configurable timeout settings that ensure reliable data transfer across network boundaries.
Java Tabular function (READ_JDBC) is used to manage source connections, SQL execution and returning the results back to Snowflake. When invoked, it accepts a JDBC configuration OBJECT (driver class, connection URL, timeouts) and a SQL query string, establishes a JDBC connection to Azure SQL Server through the network rule, executes the query, and streams results as a TABLE of OBJECT rows. Each row is a map of column names to string values, which can be cast to specific types in SQL. This design allows Snowflake stored procedures to query external SQL Server databases and load data directly into Snowflake tables using INSERT…SELECT patterns, bypassing intermediate staging and enabling real-time data access through Snowflake’s secure egress framework. SQL connection authentication is managed via Snowflake-stored secret, network rule and access integration.
A dedicated stored procedure – sp_load_tpcds_data – is used to “harvest” all the required SQL Server metadata from its underlying system views and calculate additional parameters governing partitioning strategies and distribution across multiple partitions. To demonstrate its core concepts, its metadata-harvesting capability has been reduced to support only the most fundamental ingestion parameters across source objects and attributes levels, however, this can be expended with additional capabilities with no changes to this architecture.
Finally, the single-cluster and multi-cluster warehouse Snowpark ingestion stored procedures were developed to manage data acquisition across Azure SQL DB and Snowflake environments. It’s a metadata-driven orchestration engine designed for high-performance data ingestion from Azure SQL into Snowflake.
Architecture and Solution Design
Sequentially calling JDBC Java handler to stream data directly into Snowflake target tables might be a good idea for small scale, impromptu data interrogation activities. However, in order to take full advantage of Snowflake scale-out architecture and efficiently distribute data ingestion pipelines across multiple concurrent executing workers, a different approach is required.
The following architecture depicts how a single-node warehouse can be used to scale out and parallelize data acquisition, with no outside tooling, minimal queuing and without the need to rely on Snowflake tasks as an orchestration method.
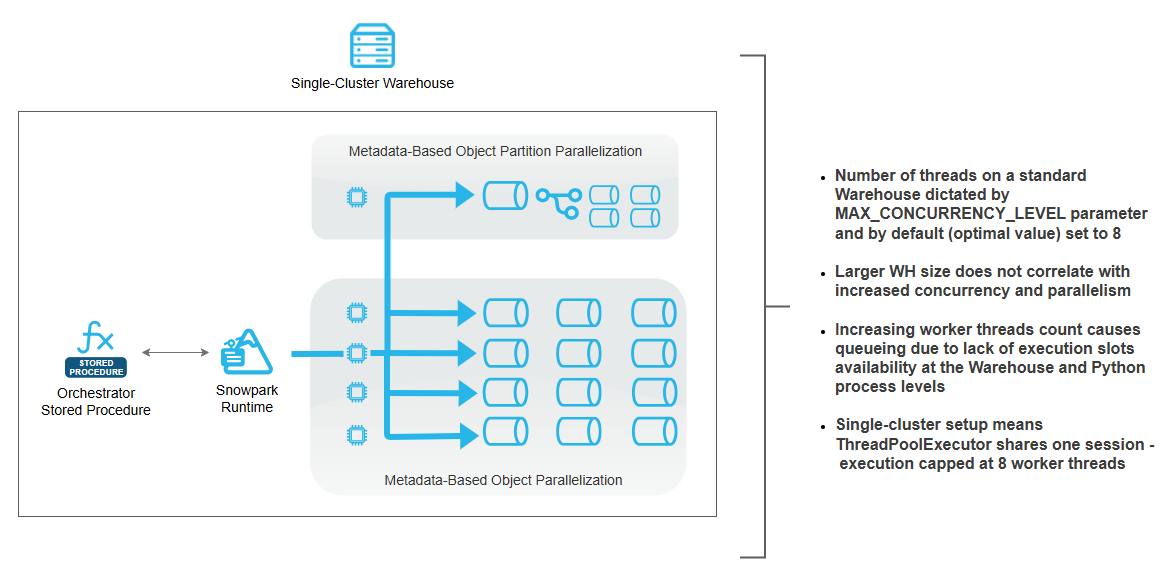
The solution implements parallel data loading framework that maximizes throughput within the constraints of a single warehouse cluster by leveraging multi-threaded concurrency patterns. At initialization, the framework performs dynamic warehouse introspection to determine the current cluster configuration, calculating theoretical worker capacity based on a fundamental assumption that each cluster node provides eight parallel execution slots. For single-node configuration, due to platform-level session constraints, the actual implementation enforces a practical concurrency ceiling of eight simultaneous operations per stored procedure invocation – this is due to default Snowflake concurrency level default cap of 8. While this threshold can be altered, Snowflake recommends caution, as this can create performance issues with memory allocation for larger queries and excessive queuing. The architecture employs a metadata-driven task generation strategy where it queries a centralized metadata repository containing table definitions, source-to-target mappings, and critically, partitioning specifications including partition columns, numeric boundary values, and desired partition counts. For large tables with defined partitioning strategies, the framework intelligently subdivides the data extraction workload into multiple independent tasks, each responsible for a specific numeric range of the partition key, enabling parallel extraction of disjoint data segments. Smaller tables without partitioning metadata are treated as atomic units requiring single-task processing. Each generated task encapsulates complete execution instructions including JDBC connection parameters, source query construction with column-level transformations (such as trimming string padding), target table specifications, and data type mapping rules that translate source database types to destination platform types. The execution engine utilizes a thread pool pattern where all tasks are submitted to a bounded worker pool that processes them asynchronously, with each worker thread independently establishing JDBC connections, executing parameterized SELECT queries with optional WHERE clause filters for partition ranges, streaming results through a custom external function that bridges the source database to the destination platform, and executing INSERT statements with explicit column mapping and type casting.
During the execution phase, we can clearly observe multiple workers processing either individual objects or objects’ partitions. By decoupling task definition from execution, the procedure ensures that all available compute resources remain fully utilized, eliminating the “long-tail” problem where a single large table blocks overall progress. Functionally, the procedure operates in two phases: orchestration and execution.
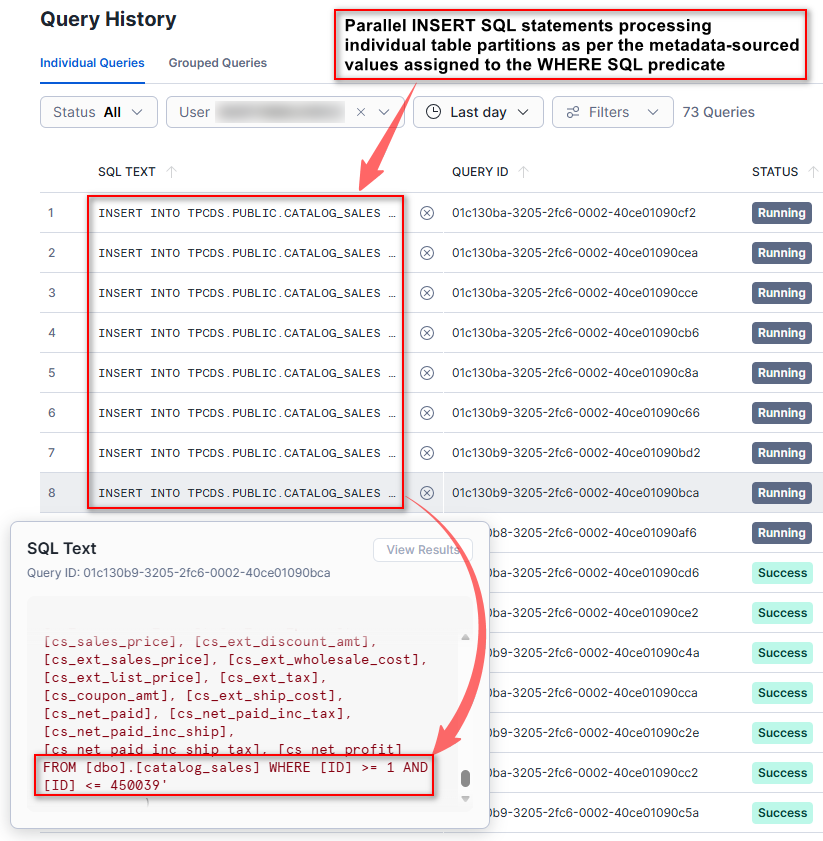
However, this approach, while maximizing warehouse resource utilization, comes with a couple of drawbacks. In a single-cluster warehouse, concurrency and parallelism are fundamentally constrained: the number of execution threads is capped by the MAX_CONCURRENCY_LEVEL parameter setting (8 by default), and increasing warehouse size has only marginal effect on the parallel execution. As a result, adding more worker threads simply leads to queuing due to limited execution slots at both the warehouse and Python process levels. Because all work shares a single session, constructs like ThreadPoolExecutor are effectively capped at the same limit, making it impossible to scale parallel workloads beyond eight concurrent workers.
To transcend single-session limitations and achieve horizontal scalability across multi-cluster warehouse configurations, the solution provides an orchestration layer that parallelizes the core loading logic across multiple independent execution contexts, each mapped to a distinct cluster node (click on image to enlarge).
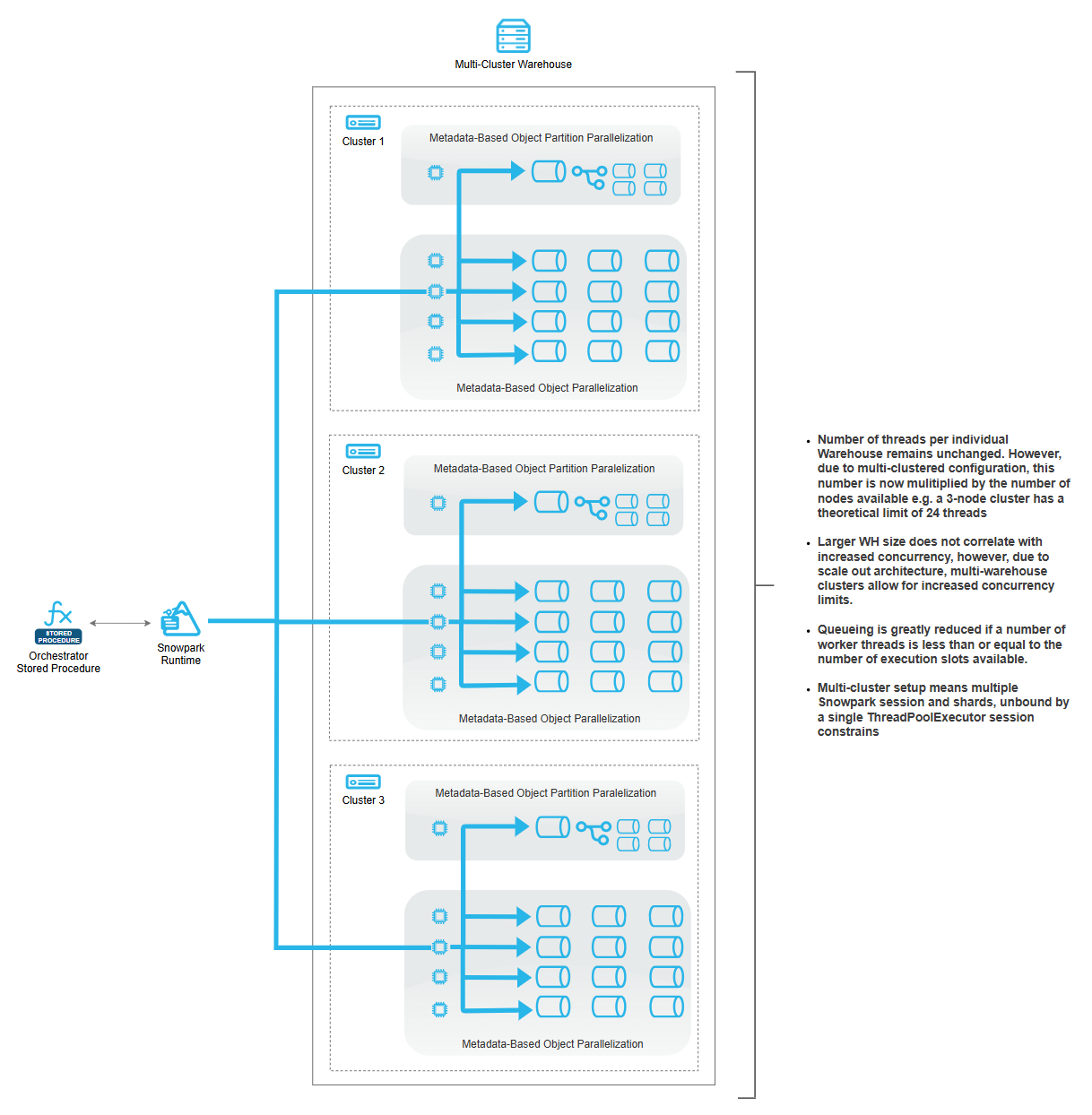
This orchestrator layer performs warehouse introspection to determine active cluster node count and spawns an equivalent number of concurrent stored procedure invocations using multi-threaded execution patterns, effectively multiplying available parallelism by the cluster multiplier. The orchestrator implements workload distribution algorithms that vary based on the loading scenario: for single-table operations with partitioned data, it calculates partition-per-cluster allocations and assigns non-overlapping partition ranges to each parallel invocation, ensuring complete coverage without duplication; for multi-table workloads, it employs table-level distribution where each cluster node receives a subset of tables to process sequentially with internal parallelism. This cluster-aware architecture enables near-linear horizontal scaling where doubling cluster count approximately doubles aggregate throughput, transforming the solution from a session-constrained single-node system into a distributed computing framework capable of leveraging the full computational capacity of multi-cluster warehouse configurations.
Anecdotal Performance Testing
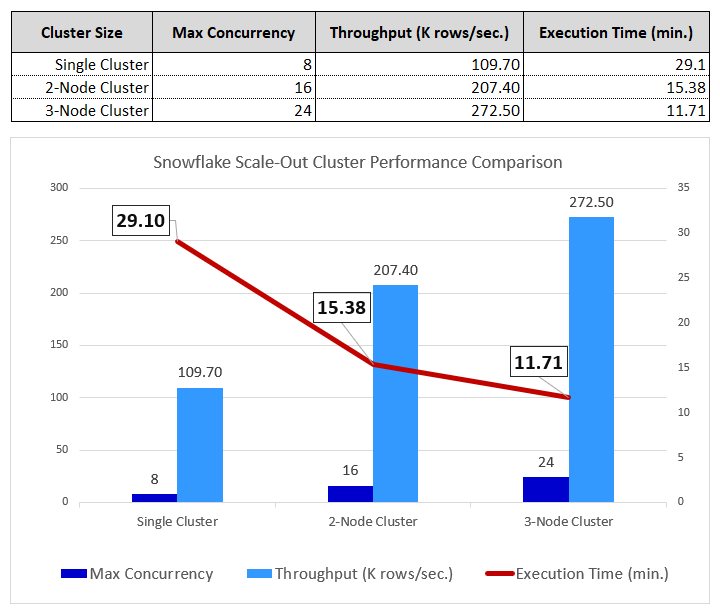
The scale-out architecture’s effectiveness is validated by actual cluster utilization metrics. The concurrency per cluster averaged 24 concurrent queries (in a 3-node cluster setup), demonstrating that each node was effectively utilizing allocated resources, with no extensive disk spills and queues. This architecture maintains perfect data integrity through deterministic sharding (all three tests loaded exactly 191,496,628 rows with no duplicates or losses), while the efficiency scores of 94.5% for 2-cluster and 83% for 3-cluster deployments reflect typical diminishing returns in parallel systems due to coordination overhead and workload imbalances. The external orchestration pattern is the key innovation that breaks through Snowflake’s single-session concurrency ceiling, enabling true horizontal scalability limited only by the multi-cluster warehouse configuration and the available table count for sharding distribution.
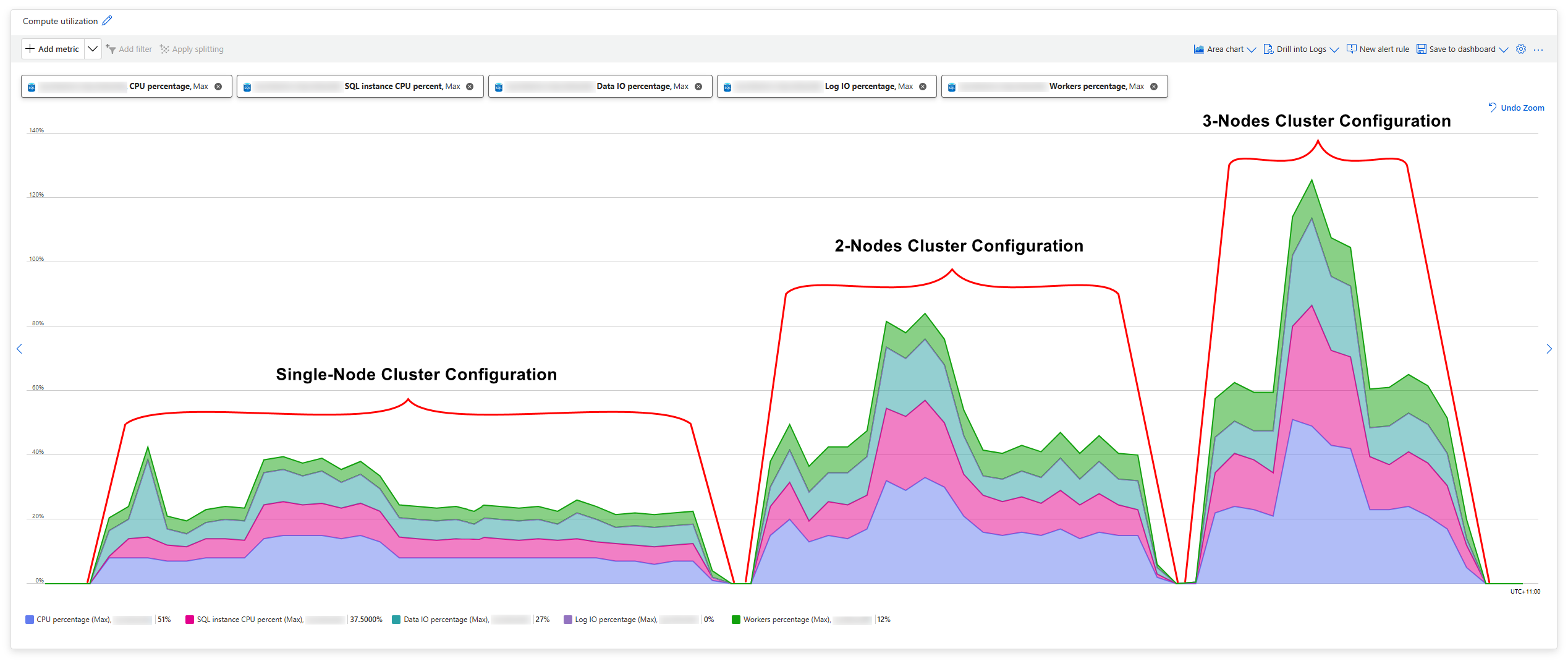
Finally, looking at the SQL Server instance resource consumption, we clearly see the correlation between the increased Snowflake cluster size, higher Azure SQL DB IO and CPU utilization and the reduced ingestion time (click on image to enlarge).
Conclusion
In summary, the Snowflake Metadata-Driven Ingestion Framework (all of the solution code can be downloaded from HERE) shows how ingestion pipelines can be simplified and hardened by pushing orchestration, transformation logic, and execution directly into Snowflake using Snowpark, JDBC, and Python. By driving ingestion behavior entirely from metadata, the framework enables new sources, tables, and ingestion patterns to be onboarded with minimal code changes, reducing operational complexity and long-term maintenance effort. Just as importantly, this approach aligns naturally with Snowflake’s elastic compute model: lightweight or low-concurrency workloads can be efficiently handled using single-node warehouses, while higher-volume or highly parallel ingestion jobs can seamlessly scale out using multi-node warehouses to increase throughput without redesigning the pipeline. This ability to scale compute independently of logic ensures consistent performance as data volumes grow, while avoiding over-provisioning for smaller workloads. Overall, the framework provides a flexible, scalable, and cloud-native foundation for building robust ingestion architectures that evolve alongside both data demands and Snowflake warehouse configurations.
http://scuttle.org/bookmarks.php/pass?action=addThis entry was posted on Sunday, January 4th, 2026 at 2:38 pm and is filed under Snowflake. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.



Huo Wang January 7th, 2026 at 8:42 pm
Nice post Martin. I was wondering if this can be used with other database vendors like MySQL, but since it’s using JDBC under the hood, I guess the answer is yes?