Automating Tableau Workbook Exports Using Python and tabcmd Command Tool
Tableau comes with a plethora of functionality out of the box but sometimes the following will inevitably be asked/proposed to meet business reporting requirements:
- End users will ask for features which do not exist (at least until version X is released or comes out of preview)
- In order to meet those bespoke demands, some level of custom development i.e. ‘hacking the status quo’ will be required to meet those requirements
In case of Tableau automated reports generation, where pagination and more comprehensive controls are required e.g. producing the same report as a series of PDF documents based on report filter value, the software falls short of providing this level of control. However, given the fact that I am not aware of any other application which provides such fine level of functionality (it’s always a fine balance between features selection and usability) and Tableau’s ability to allow users to dive ‘under the hood’ to breech such gaps, for technically savvy analysts it’s fairly easy to accommodate those demands with a little bit reverse-engineering.
Tableau server allows end users to query its internal workgroup database sitting atop of PostgreSQL DBMS. I have previously written about PostgreSQL to Microsoft SQL Server schema and data synchronisation HERE so I will not go into details of how Tableau stores its metadata but it’s fair to say that anyone who’s ever worked with a relational data stores should have no trouble cobbling together a simple query together to acquire the details on workbooks, views, jobs etc. that Tableau database stores and manages.
Tableau server also allows users to administer some tasks through its built-in tabcmd command-line utility e.g. creating and deleting users, exporting views or workbooks, publishing data sources etc. It’s a handy tool which can simplify administrative efforts and in this specific example we will be using it for creating report exports in an automated fashion.
In order to demo this solution on a typical business-like data, let’s create a sample data set and a very rudimentary Tableau report. The following SQL builds a single table database running on a local Microsoft SQL Server platform and populates it with dummy sales data.
/*==============================================================================
STEP 1
Create SampleDB databases on the local instance
==============================================================================*/
USE [master];
GO
IF EXISTS (SELECT name FROM sys.databases WHERE name = N'SampleDB')
BEGIN
-- Close connections to the StagingDB database
ALTER DATABASE SampleDB SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE SampleDB;
END;
GO
-- Create SampleDB database and log files
CREATE DATABASE SampleDB
ON PRIMARY
(
NAME = N'SampleDB',
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQL2016DEV\MSSQL\DATA\SampleDB.mdf',
SIZE = 10MB,
MAXSIZE = 1GB,
FILEGROWTH = 10MB
)
LOG ON
(
NAME = N'SampleDB_log',
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQL2016DEV\MSSQL\DATA\SampleDB_log.LDF',
SIZE = 1MB,
MAXSIZE = 1GB,
FILEGROWTH = 10MB
);
GO
--Assign database ownership to login SA
EXEC SampleDB.dbo.sp_changedbowner @loginame = N'SA', @map = false;
GO
--Change the recovery model to BULK_LOGGED
ALTER DATABASE SampleDB SET RECOVERY BULK_LOGGED;
GO
/*======================================================================================
STEP 2
Create sample_data table on SampleDB database and insert 10000 dummy records
imitating mocked up sales transations across random dates, postcodes and SKU numbers
======================================================================================*/
USE SampleDB;
GO
SET NOCOUNT ON;
IF OBJECT_ID('sample_data') IS NOT NULL
BEGIN
DROP TABLE sample_data;
END;
-- Create target object
CREATE TABLE sample_data
(
id INT IDENTITY(1, 1) NOT NULL,
product_sku VARCHAR(512) NOT NULL,
quantity INT NOT NULL,
sales_amount MONEY NOT NULL,
postcode VARCHAR(4) NOT NULL,
state VARCHAR(128) NOT NULL,
order_date DATETIME NOT NULL
);
-- Populate target object with dummy data
DECLARE @postcodestate TABLE
(
id INT IDENTITY(1, 1),
postcode VARCHAR(4),
state VARCHAR(128)
);
INSERT INTO @postcodestate
(
postcode,
state
)
SELECT '2580', 'NSW' UNION ALL SELECT '2618', 'NSW' UNION ALL SELECT '2618', 'NSW' UNION ALL SELECT '2581', 'NSW' UNION ALL
SELECT '2582', 'NSW' UNION ALL SELECT '2580', 'NSW' UNION ALL SELECT '2550', 'NSW' UNION ALL SELECT '2550', 'NSW' UNION ALL
SELECT '2450', 'NSW' UNION ALL SELECT '3350', 'VIC' UNION ALL SELECT '3350', 'VIC' UNION ALL SELECT '3212', 'VIC' UNION ALL
SELECT '3215', 'VIC' UNION ALL SELECT '3880', 'VIC' UNION ALL SELECT '3759', 'VIC' UNION ALL SELECT '3037', 'VIC' UNION ALL
SELECT '3631', 'VIC' UNION ALL SELECT '4006', 'QLD' UNION ALL SELECT '4069', 'QLD' UNION ALL SELECT '4171', 'QLD' UNION ALL
SELECT '4852', 'QLD' UNION ALL SELECT '4852', 'QLD' UNION ALL SELECT '4352', 'QLD' UNION ALL SELECT '4701', 'QLD' UNION ALL
SELECT '4218', 'QLD' UNION ALL SELECT '5095', 'SA' UNION ALL SELECT '5097', 'SA' UNION ALL SELECT '5573', 'SA' UNION ALL
SELECT '5700', 'SA' UNION ALL SELECT '5214', 'SA' UNION ALL SELECT '6209', 'WA' UNION ALL SELECT '6054', 'WA' UNION ALL
SELECT '6068', 'WA' UNION ALL SELECT '6430', 'WA' UNION ALL SELECT '6770', 'WA' UNION ALL SELECT '7054', 'TAS' UNION ALL
SELECT '7253', 'TAS' UNION ALL SELECT '7140', 'TAS' UNION ALL SELECT '7179', 'TAS' UNION ALL SELECT '7109', 'TAS' UNION ALL
SELECT '0870', 'NT' UNION ALL SELECT '0872', 'NT' UNION ALL SELECT '0852', 'NT' UNION ALL SELECT '2617', 'ACT' UNION ALL
SELECT '2617', 'ACT' UNION ALL SELECT '2913', 'ACT' UNION ALL SELECT '2905', 'ACT' UNION ALL SELECT '2903', 'ACT';
DECLARE @allchars VARCHAR(100) = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
DECLARE @max_row_number INT;
SET @max_row_number = 10000;
DECLARE @count INT = 1;
WHILE @count <= @max_row_number
BEGIN
INSERT INTO SampleDB.dbo.sample_data
(
product_sku,
quantity,
sales_amount,
postcode,
state,
order_date
)
SELECT RIGHT(LEFT(@allchars, ABS(BINARY_CHECKSUM(NEWID()) % 35) + 1), 1)
+ RIGHT(LEFT(@allchars, ABS(BINARY_CHECKSUM(NEWID()) % 35) + 1), 1)
+ RIGHT(LEFT(@allchars, ABS(BINARY_CHECKSUM(NEWID()) % 35) + 1), 1)
+ RIGHT(LEFT(@allchars, ABS(BINARY_CHECKSUM(NEWID()) % 35) + 1), 1)
+ RIGHT(LEFT(@allchars, ABS(BINARY_CHECKSUM(NEWID()) % 35) + 1), 1),
CAST(RAND() * 5 + 3 AS INT),
CAST(RAND() * 50 AS INT) / 2.5,
(
SELECT TOP 1 postcode FROM @postcodestate ORDER BY NEWID()
),
(
SELECT TOP 1 state FROM @postcodestate ORDER BY NEWID()
),
GETDATE() - (365 * 3 * RAND() - 365);
SET @count = @count + 1;
END;
This table will become the basis for the following Tableau dashboard depicting random sales data aggregated by state, postcode, date and product SKU. The sample report looks as per the image below and is located on a Tableau server instance which we will be using to generate the extracts from. You can also notice that the dashboard contains a filter called ‘state’ (as highlighted) with a number of values assigned to it. This filter, along with the filter values representing individual states, will become the basis for producing separate workbook extracts for each of the filter value e.g. NT.pdf, VIC.pdf, NSW.pdf etc.

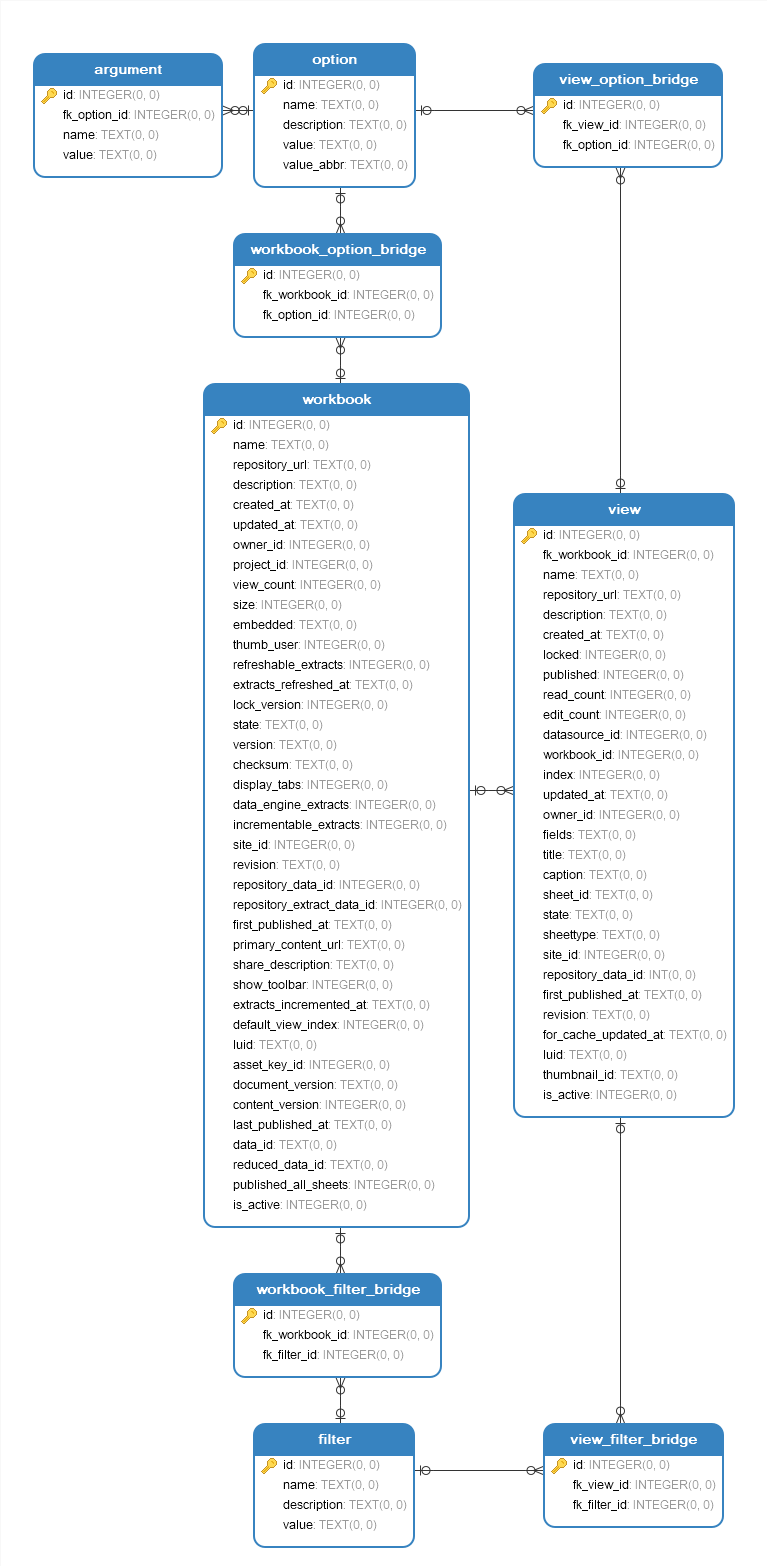
Next, let’s create a very simple database which will hold necessary metadata used for subsequent reports generation. SQLite is more than adequate for such low volumes of data. The database schema is an amalgamation of Tableau’s own workbook and view tables and other objects defined to store tabcmd options, attributes and filters we’d like to use in this example. The schema is generated and populated by the following Python script. The actual SQL used to define the DDL and DML statements can be found on my OneDrive folder HERE and is required as part of the overall solution.
import configparser
import sqlite3
import os
import sys
import argparse
import psycopg2
config = configparser.ConfigParser()
config.read('params.cfg')
#pg tables selection
pg_tblsNames = ['workbooks', 'views']
#sqlite args
dbsqlite_location = config.get('Sqlite',os.path.normpath('dbsqlite_location'))
dbsqlite_fileName = config.get('Sqlite','dbsqlite_fileName')
dbsqlite_sql = config.get('Sqlite','dbsqlite_sql')
parser = argparse.ArgumentParser(description='Tableau data extraction solution by bicortex.com')
#tableau server args
parser.add_argument('-n','--hostname', help='Tableau postgresql server name', required=True)
parser.add_argument('-d','--dbname', help='Tableau postgresql database name', required=True)
parser.add_argument('-u','--username', help='Tableau postgresql user name', required=True)
parser.add_argument('-p','--passwd', help='Tableau postgresql password', required=True)
args = parser.parse_args()
if not args.hostname or not args.dbname or not args.username or not args.passwd:
parser.print_help()
def run_DB_built(dbsqlite_sql, dbsqlite_location, dbsqlite_fileName, dbname, username, hostname, passwd, *args):
with sqlite3.connect(os.path.join(dbsqlite_location, dbsqlite_fileName)) as sqlLiteConn:
sqlLiteConn.text_factory = lambda x: x.unicode('utf-8', 'ignore')
operations=[]
commands=[]
sql={}
#get all SQL operation types as defined by the '----SQL' prefix in tableau_export.sql file
print('Reading tableau_export.sql file...')
with open(dbsqlite_sql, 'r') as f:
for i in f:
if i.startswith('----'):
i=i.replace('----','')
operations.append(i.rstrip('\n'))
f.close()
#get all SQL DML & DDL statements from tableau_export.sql file
tempCommands=[]
f = open(dbsqlite_sql, 'r').readlines()
for i in f:
tempCommands.append(i)
l = [i for i, s in enumerate(tempCommands) if '----' in s]
l.append((len(tempCommands)))
for first, second in zip(l, l[1:]):
commands.append(''.join(tempCommands[first:second]))
sql=dict(zip(operations, commands))
#run database CREATE SQL
print('Building TableauEX.db database schema... ')
sqlCommands = sql.get('SQL 1: Create DB').split(';')
for c in sqlCommands:
try:
sqlLiteConn.execute(c)
except sqlite3.OperationalError as e:
print (e)
sqlLiteConn.rollback()
sys.exit(1)
else:
sqlLiteConn.commit()
#acquire PostgreSQL workgroup database data and populate SQLite database schema with that data
print('Acquiring Tableau PostgreSQL data and populating SQLite database for the following tables: {0}...'.format(', '.join(map(str, pg_tblsNames))))
pgConn = "dbname={0} user={1} host={2} password={3} port=8060".format(dbname, username, hostname, passwd)
pgConn = psycopg2.connect(pgConn)
pgCursor = pgConn.cursor()
for tbl in pg_tblsNames:
try:
tbl_cols={}
pgCursor.execute("""SELECT ordinal_position, column_name
FROM information_schema.columns
WHERE table_name = '{}'
AND table_schema = 'public'
AND column_name != 'index'
ORDER BY 1 ASC""".format(tbl))
rows = pgCursor.fetchall()
for row in rows:
tbl_cols.update({row[0]:row[1]})
sortd = [tbl_cols[key] for key in sorted(tbl_cols.keys())]
cols = ",".join(sortd)
pgCursor.execute("SELECT {} FROM {}".format(cols,tbl))
rows = pgCursor.fetchall()
num_columns = max(len(rows[0]) for t in rows)
pgsql="INSERT INTO {} ({}) VALUES({})".format(tbl[:-1],cols,",".join('?' * num_columns))
sqlLiteConn.executemany(pgsql,rows)
except psycopg2.Error as e:
print(e)
sys.exit(1)
else:
sqlLiteConn.commit()
#update SQLite bridging tables based on DML statements under 'SQL 2: Update DB' opertation type header
print('Updating SQLite database bridging tables...')
sqlCommands = sql.get('SQL 2: Update DB').split(';')
for c in sqlCommands:
try:
sqlLiteConn.execute(c)
except sqlite3.OperationalError as e:
print (e)
sqlLiteConn.rollback()
sys.exit(1)
else:
sqlLiteConn.commit()
sqlLiteConn.close()
pgConn.close()
if __name__ == "__main__":
run_DB_built(dbsqlite_sql, dbsqlite_location, dbsqlite_fileName, args.dbname, args.username, args.hostname, args.passwd, pg_tblsNames)
I have run this code against Tableau version 10.5 so there is a slight chance that some SQL statements will require adjustments depending on Tableau’s PostgreSQL database changes in subsequent releases. The script uses the aforementioned SQL file as well as one configuration file where some of the required parameters are stored as per the image below. Please also note that this SQL file contains data for the filter table comprised of Australian states (corresponding to Tableau workbook filter and its values as indicated above) so your actual data may contain other filter names and values or may even not use them at all. Also, Tableau workgroup database schema does not store filter names and/or values so in order to have them referenced in the script they need to be added manually.
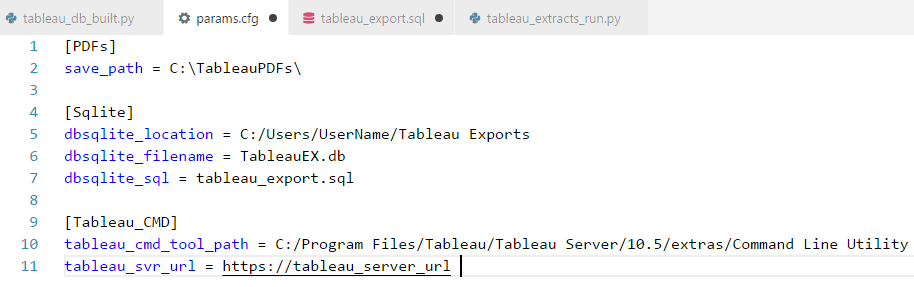
Once executed, the following schema should be built and populated.
Now that we have laid down the foundations for this solution and have the SQLite database created and populated as well as a sample Tableau dashboard deployed on Tableau server pointing to our dummy data stored in SQL Server we can run Tableau reports generation script. For this example, let’s assume that we need to generate a separate PDF copy of the dashboard for each of the states defined in the filter table. The query will look as per the following.
SELECT
w.name AS workbook_name,
v.name AS view_name,
f.name AS filter_name,
f.value AS filter_value
FROM workbook w
JOIN view v ON w.id = v.fk_workbook_id
JOIN view_filter_bridge vfb ON v.id = vfb.fk_view_id
JOIN filter f ON vfb.fk_filter_id = f.id
WHERE w.name = 'Sample_Tableau_Report'
AND v.sheettype = 'dashboard'
AND v.state = 'active';
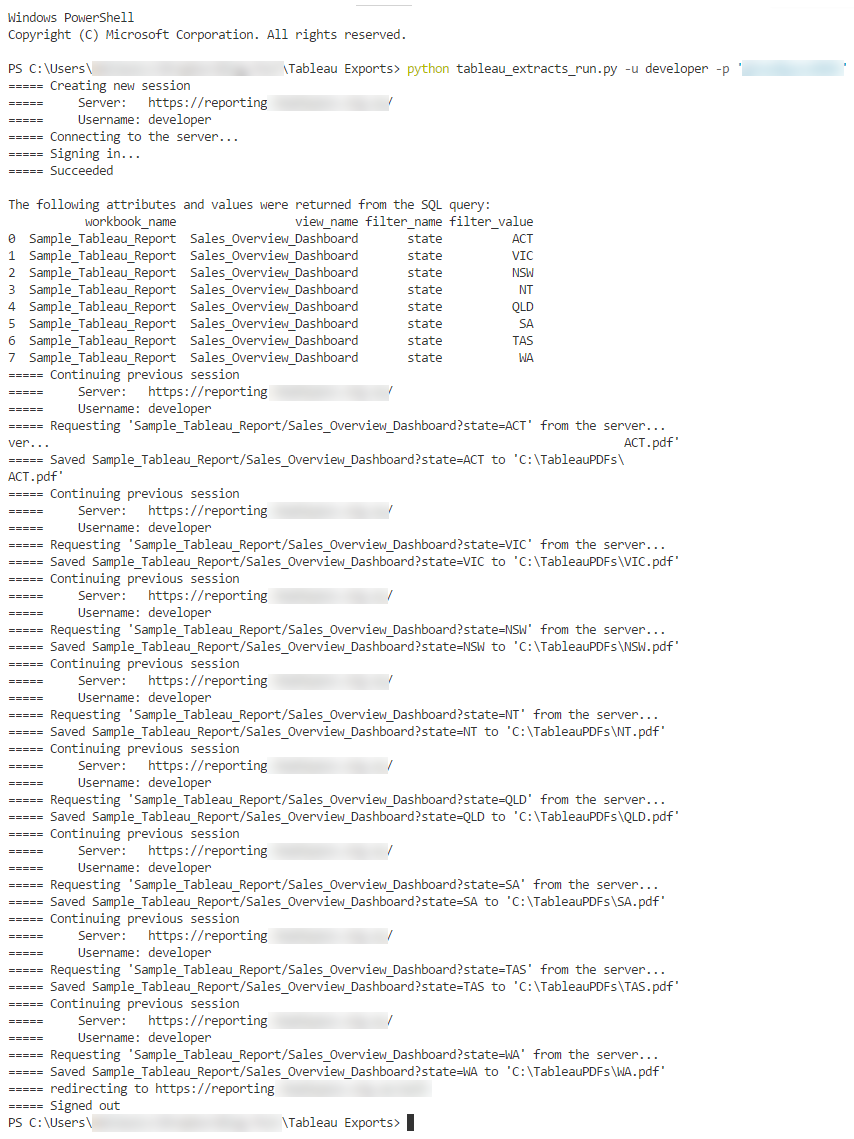
Entering the same query into a Python script, which than further breaks down the returned attributes and their values into tabcmd command arguments in a looped fashion, produces a series of statements which in turn produce PDF version of the nominated dashboard. Below is the Python script which saves a copy of Sales_Overview_Dashboard report in a PDF format for each state to the specified location.
import configparser
import sqlite3
import os
import sys
import argparse
import subprocess
import pandas as pd
config = configparser.ConfigParser()
config.read('params.cfg')
#sqlite & tabcmd args
dbsqlite_location = config.get('Sqlite',os.path.normpath('dbsqlite_location'))
dbsqlite_fileName = config.get('Sqlite','dbsqlite_fileName')
tabcmd_location = config.get('Tableau_CMD','tableau_cmd_tool_path')
tabcmd_url = config.get('Tableau_CMD','tableau_svr_url')
pdfs_location = config.get('PDFs', 'save_path')
parser = argparse.ArgumentParser(description='Tableau report(s) generation script by bicortex.com')
#tableau server args
parser.add_argument('-u', '--username', help='Tableau server user name', required=True)
parser.add_argument('-p', '--passwd', help='Tableau server password', required=True)
parser.add_argument('-o', '--option', help='Other options and arguments provided by tabcmd', required=False)
args = parser.parse_args()
if not args.username or not args.passwd:
parser.print_help()
#tableau login function
def tab_login(tabcmd_location, tabcmd_url, username, passwd):
try:
p=subprocess.run('{0} login -s {1} -u {2} -p {3} -no-certcheck'\
.format(os.path.join(os.path.normpath(tabcmd_location),'tabcmd'),\
tabcmd_url, args.username, args.passwd ),shell=True)
r=p.returncode
return r
except subprocess.SubprocessError as e:
print(e)
sys.exit(1)
#tableau logout function
def tab_logout(tabcmd_location):
try:
p=subprocess.run('{0} logout'.format(os.path.join(os.path.normpath(tabcmd_location),'tabcmd')),shell=True)
except subprocess.SubprocessError as e:
print(e)
sys.exit(1)
#tabcmd report export function
def run_extracts(pdfs_location, tabcmd_location, username=args.username, passwd=args.passwd, option=args.option):
standard_export_options = '--pdf --pagelayout landscape --no-certcheck --timeout 500'
login_ok = tab_login(tabcmd_location, tabcmd_url, username, passwd)
if login_ok==0:
with sqlite3.connect(os.path.join(dbsqlite_location, dbsqlite_fileName)) as sqlLiteConn:
sqliteCursor = sqlLiteConn.cursor()
sqliteCursor.execute( """
SELECT
w.name AS workbook_name,
v.name AS view_name,
f.name AS filter_name,
f.value AS filter_value
FROM workbook w
JOIN view v ON w.id = v.fk_workbook_id
JOIN view_filter_bridge vfb ON v.id = vfb.fk_view_id
JOIN filter f ON vfb.fk_filter_id = f.id
WHERE w.name = 'Sample_Tableau_Report'
AND v.sheettype = 'dashboard'
AND v.state = 'active';
""")
result_set = sqliteCursor.fetchall()
if result_set:
df = pd.DataFrame(result_set)
col_name_list = [tuple[0] for tuple in sqliteCursor.description]
df.columns = col_name_list
print('\nThe following attributes and values were returned from the SQL query:')
print(df)
for row in result_set:
workbook_name = row[0]
view_name = row[1]
filter_name = row[2]
filter_value = row[3]
if filter_name:
if ' ' in row[2]==True:
filter_name = row[2].replace(' ', '%20')
if ' ' in row[2]==True:
filter_value = row[2].replace(' ', '%20')
if not option:
option_value = standard_export_options
command = '{0} export "{1}?{2}={3}" -f "{4}{5}.pdf" {6} '\
.format(os.path.join(os.path.normpath(tabcmd_location),'tabcmd'),\
workbook_name + '/' + view_name, filter_name, filter_value, pdfs_location, filter_value, option_value)
try:
p=subprocess.run(command, shell=True)
except subprocess.SubprocessError as e:
print(e)
sys.exit(1)
else:
if not option:
option_value = standard_export_options
command = '{0} export "{1}" -f "{2}{3}.pdf" {4} '\
.format(os.path.join(os.path.normpath(tabcmd_location),'tabcmd'),\
workbook_name + '/' + view_name, pdfs_location, view_name, option_value)
try:
p=subprocess.run(command, shell=True)
except subprocess.SubprocessError as e:
print(e)
sys.exit(1)
tab_logout(tabcmd_location)
if __name__ == "__main__":
if ' ' in tabcmd_location:
tabcmd_location = '"'+ os.path.normpath(tabcmd_location) + '"'
else:
tabcmd_location = os.path.normpath(tabcmd_location)
run_extracts(pdfs_location, tabcmd_location, args.username, args.passwd)
This script assumes that tabcmd utility is installed on the local machine if not run from the Tableau server environment (which has it installed by default) and produces the following output when run from the command prompt (click on image to expand).
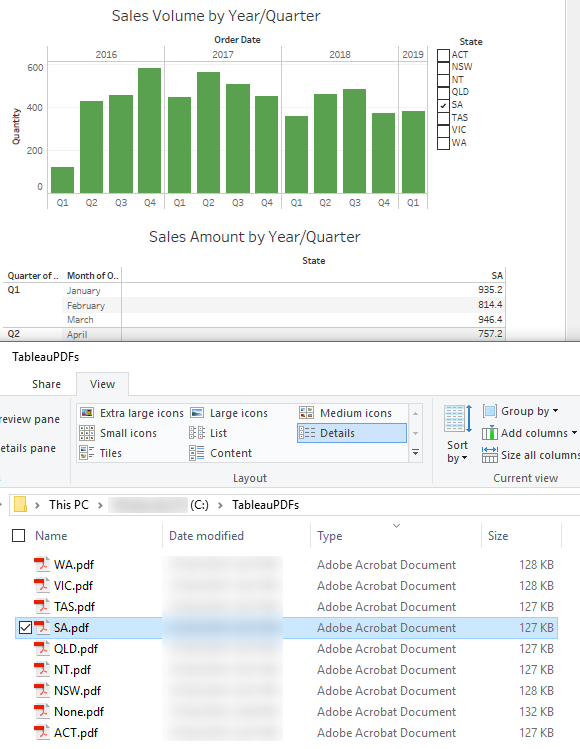
The following is the folder view of where the individual reports have been saved as well as a partial view of South Australia state report (SA.pdf) opened depicting SA data only, with remaining states filtered out of the context.
Similar scripts can be run for all states i.e. no filter assign. The difference being the SQL statement we pass in the Python script. For example, if we would like to run Sales Overview Dashboard report across all states on a single PDF sheet we could run the following SQL and embed it into the script.
SELECT
w.name AS workbook_name,
v.name AS view_name,
NULL AS filter_name,
NULL AS filter_value
FROM workbook w
JOIN view v ON w.id = v.fk_workbook_id
WHERE w.name = 'Sample_Tableau_Report'
AND v.sheettype = 'dashboard'
AND v.state = 'active';
This technique can be used across a variety of different combinations and permutations of workbooks, sheets, filters, option etc. and is just a small example of how one can generate a simple solution for an automated workbook extracts. For the full scope of tabcmd commands and associated functionality please refer to Tableau online documentation.
http://scuttle.org/bookmarks.php/pass?action=addThis entry was posted on Friday, October 27th, 2017 at 2:26 am and is filed under Programming, Tableau, Visualisation. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.



admin March 31st, 2019 at 11:50 am
Hi Lance.
No, I have not. This was a one-off but I imagine that it wouldn’t be that hard, providing Tableau API provides this functionality.