Microsoft Azure SQL Data Warehouse Quick Review and Amazon Redshift Comparison – Part 2
In the first part of this series I briefly explored Microsoft Azure Data Warehouse key differentiating features that set it apart from the likes of AWS Redshift and outlined how we can load the Azure DW with sample TICKIT database data. In this final post I will go over some of the findings from comparing query execution speed across AWS/Azure DW offerings and briefly look at the reporting/analytics status quo.
My test ‘hardware’ set-up composition was characterized by the following specifications where, as mentioned in PART ONE, Amazon seems to adopt a bit less of a cloak-and-dagger approach.
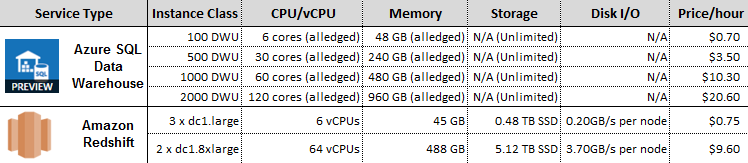
Graphing the results, I assigned the following monikers to each environment based on its specifications/price point.
- Azure SQL DW 100 DWU – Azure Data Warehouse 100 Data Warehouse Units
- Azure SQL DW 500 DWU – Azure Data Warehouse 500 Data Warehouse Units
- Azure SQL DW 1000 DWU – Azure Data Warehouse 1000 Data Warehouse Units
- Azure SQL DW 2000 DWU – Azure Data Warehouse 2000 Data Warehouse Units
- Redshift 3 x dc1.large – AWS Redshift 3 x large dense compute nodes
- Redshift 2 x dc1.8xlarge – AWS Redshift 2 x extra-large dense compute nodes
Testing Methodology and Configuration Provisions
Each table created on Azure DW also had clustered columnstore index created on it, which as of December 2015, is a default behaviour when issuing a CREATE TABLE DDL statement unless specified otherwise i.e. using a HEAP option with the table creation statement. Clustered columnstore indexes provide better performance and data compression than a heap or rowstore clustered index. Also, each fact table and its data created in Azure DW was distributed using hashing values on identity fields e.g. Sales table –> saleid column, Listing table –> listid column, whereas a round-robin algorithm was used for dimension tables data distribution. A hash distributed table is a table whose rows are dispersed across multiple distributions based on a hash function applied to a column. When processing queries involving distributed tables, SQL DW instances execute multiple internal queries, in parallel, within each SQL instance, one per distribution. These separate processes (independent internal SQL queries) are executed to handle different distributions during query and load processing. A round-robin distributed table is a table where the data is evenly (or as evenly as possible) distributed among all the distributions. Buffers containing rows of data are allocated in turn (hence the name round robin) to each distribution. The process is repeated until all data buffers have been allocated. At no stage is the data sorted or ordered in a round robin distributed table. A round robin distribution is sometimes called a random hash for this reason.
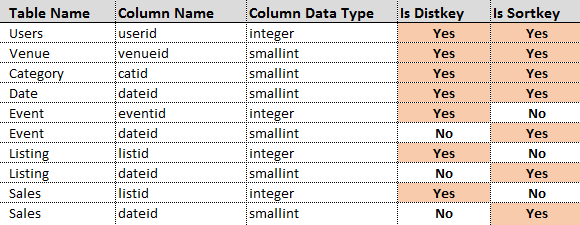
Each table on AMS Redshift database was assigned a distkey and a sortkey which are a powerful set of tools for optimizing query performance. A table’s distkey is the column on which it’s distributed to each node. Rows with the same value in this column are guaranteed to be on the same node. The goal in selecting a table distribution style is to minimize the impact of the redistribution step by locating the data where it needs to be before the query is executed. A table’s sortkey is the column by which it’s sorted within each node. The Amazon Redshift query optimizer uses sort order when it determines optimal query plans.
The following allocation was made for each table in the TICKIT database schema on AWS Redshift database.
On Azure Data Warehouse, after populating TICKIT schema and before running all queries, clustered columnstore indexes were created on each table. Also, at a minimum, Microsoft recommends creating at least single-column statistics on every column on every table which in case of SQL Data Warehouse are user-defined i.e. need to be created manually and managed manually. As SQL Data Warehouse does not have a system stored procedure equivalent to ‘sp_create_stats’ in SQL Server, the following stored procedure was used to create a single column statistics object on every column of the database that didn’t already one, with FULLSCAN option defined for @create_type.
CREATE PROCEDURE [dbo].[prc_sqldw_create_stats]
( @create_type tinyint -- 1 default 2 Fullscan 3 Sample
, @sample_pct tinyint
)
AS
IF @create_type NOT IN (1,2,3)
BEGIN
THROW 151000,'Invalid value for @stats_type parameter. Valid range 1 (default), 2 (fullscan) or 3 (sample).',1;
END;
IF @sample_pct IS NULL
BEGIN;
SET @sample_pct = 20;
END;
IF OBJECT_ID('tempdb..#stats_ddl') IS NOT NULL
BEGIN;
DROP TABLE #stats_ddl;
END;
CREATE TABLE #stats_ddl
WITH ( DISTRIBUTION = HASH([seq_nmbr])
, LOCATION = USER_DB
)
AS
WITH T
AS
(
SELECT t.[name] AS [table_name]
, s.[name] AS [table_schema_name]
, c.[name] AS [column_name]
, c.[column_id] AS [column_id]
, t.[object_id] AS [object_id]
, ROW_NUMBER()
OVER(ORDER BY (SELECT NULL)) AS [seq_nmbr]
FROM sys.[tables] t
JOIN sys.[schemas] s ON t.[schema_id] = s.[schema_id]
JOIN sys.[columns] c ON t.[object_id] = c.[object_id]
LEFT JOIN sys.[stats_columns] l ON l.[object_id] = c.[object_id]
AND l.[column_id] = c.[column_id]
AND l.[stats_column_id] = 1
LEFT JOIN sys.[external_tables] e ON e.[object_id] = t.[object_id]
WHERE l.[object_id] IS NULL
AND e.[object_id] IS NULL -- not an external table
)
SELECT [table_schema_name]
, [table_name]
, [column_name]
, [column_id]
, [object_id]
, [seq_nmbr]
, CASE @create_type
WHEN 1
THEN CAST('CREATE STATISTICS '+QUOTENAME('stat_'+table_schema_name+ '_' + table_name + '_'+column_name)+' ON '+QUOTENAME(table_schema_name)+'.'+QUOTENAME(table_name)+'('+QUOTENAME(column_name)+')' AS VARCHAR(8000))
WHEN 2
THEN CAST('CREATE STATISTICS '+QUOTENAME('stat_'+table_schema_name+ '_' + table_name + '_'+column_name)+' ON '+QUOTENAME(table_schema_name)+'.'+QUOTENAME(table_name)+'('+QUOTENAME(column_name)+') WITH FULLSCAN' AS VARCHAR(8000))
WHEN 3
THEN CAST('CREATE STATISTICS '+QUOTENAME('stat_'+table_schema_name+ '_' + table_name + '_'+column_name)+' ON '+QUOTENAME(table_schema_name)+'.'+QUOTENAME(table_name)+'('+QUOTENAME(column_name)+') WITH SAMPLE '+@sample_pct+'PERCENT' AS VARCHAR(8000))
END AS create_stat_ddl
FROM T
;
DECLARE @i INT = 1
, @t INT = (SELECT COUNT(*) FROM #stats_ddl)
, @s NVARCHAR(4000) = N''
;
WHILE @i <= @t
BEGIN
SET @s=(SELECT create_stat_ddl FROM #stats_ddl WHERE seq_nmbr = @i);
PRINT @s
EXEC sp_executesql @s
SET @i+=1;
END
DROP TABLE #stats_ddl;
AWS Redshift database, on the other hand, was issued a VACUUM REINDEX command for each table in the TICKIT database in order to analyse the distribution of the values in interleaved sort key columns, reclaims disk space and resorts all rows. Amazon recommends running ANALYZE command alongside the VACUUM statement whenever a significant number of rows is added, deleted or modified to update the statistics metadata, however, given that COPY command automatically updates statistics after loading an empty table, the statistics should already be up-to-date.
Disclaimer
Please note that beyond the measures outlined above, no tuning, tweaking or any other optimization techniques were employed when making this comparison, therefore, the results are only indicative of the performance level in the context of the same data and configuration used. Also, all tests were run when Microsoft Azure SQL Data Warehouse was still in preview hence it is possible that most of the service performance deficiencies or alternatively performance-to-price ratio have now been rectified/improved thus subsequently altering the value proposition if implemented today. Finally, all queries executed in this comparison do not reflect any specific business questions, therefore all SQL statements have a very arbitrary structure and have been assembled to only test computational performance of each service. As such, they do not represent any typical business cases and can only be viewed as a rudimentary performance testing tool.
Test Results
When comparing execution speeds on the same data between those two different services only similar instance classes should be stacked up against each other (typically based on hardware specifications). Given the sometimes ambiguous and deceptive nature of the cloud and its providers’ statements regarding the actual hardware selection/implementation, in this case it is only fair to match them based on the actual service price points. As such, when analysing the results, I excluded Azure SQL Data Warehouse 500 DTU and Azure SQL Data Warehouse 2000 DTU instances (displayed for reference only) and focused on AWS Redshift similarly priced Azure SQL Data Warehouse 100 DTU and Azure SQL Data Warehouse 1000 DTU instances. Also, storage and network transfer fees were not taken into consideration when matching up the price points as these were negligible with the amount of data I used in my case.
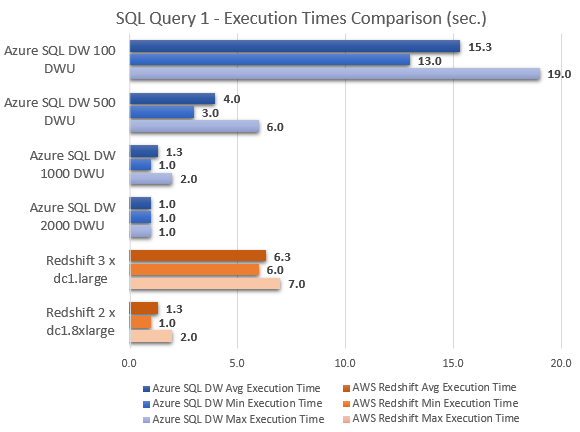
All SQL queries run to collect execution times (expressed in seconds) as well as graphical representation of their duration are as per below.
--QUERY 1
SELECT COUNT(*)
FROM ( SELECT COUNT(*) AS counts ,
salesid ,
listid ,
sellerid ,
buyerid ,
eventid ,
dateid ,
qtysold ,
pricepaid ,
commission ,
saletime
FROM sales
GROUP BY salesid ,
listid ,
sellerid ,
buyerid ,
eventid ,
dateid ,
qtysold ,
pricepaid ,
commission ,
saletime
) sub;
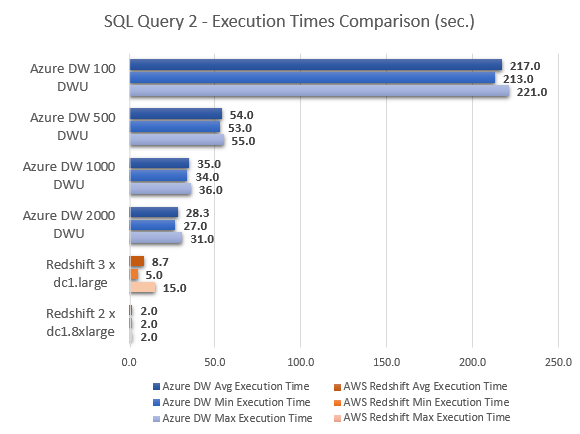
--QUERY 2
WITH cte
AS ( SELECT SUM(s.pricepaid) AS pricepaid ,
sub.* ,
u1.email ,
DENSE_RANK() OVER ( PARTITION BY sub.totalprice ORDER BY d.caldate DESC ) AS daterank
FROM sales s
JOIN ( SELECT l.totalprice ,
l.listid ,
v.venuecity ,
c.catdesc
FROM listing l
LEFT JOIN event e ON l.eventid = e.eventid
INNER JOIN category c ON e.catid = c.catid
INNER JOIN venue v ON e.venueid = v.venueid
GROUP BY v.venuecity ,
c.catdesc ,
l.listid ,
l.totalprice
) sub ON s.listid = sub.listid
LEFT JOIN users u1 ON s.buyerid = u1.userid
LEFT JOIN Date d ON d.dateid = s.dateid
GROUP BY sub.totalprice ,
sub.listid ,
sub.venuecity ,
sub.catdesc ,
u1.email ,
d.caldate
)
SELECT COUNT(*)
FROM cte;
--QUERY 3
SELECT COUNT(*)
FROM ( SELECT s.* ,
u.*
FROM sales s
LEFT JOIN event e ON s.eventid = e.eventid
LEFT JOIN date d ON d.dateid = s.dateid
LEFT JOIN users u ON u.userid = s.buyerid
LEFT JOIN listing l ON l.listid = s.listid
LEFT JOIN category c ON c.catid = e.catid
LEFT JOIN venue v ON v.venueid = e.venueid
INTERSECT
SELECT s.* ,
u.*
FROM sales s
LEFT JOIN event e ON s.eventid = e.eventid
LEFT JOIN date d ON d.dateid = s.dateid
LEFT JOIN users u ON u.userid = s.buyerid
LEFT JOIN listing l ON l.listid = s.listid
LEFT JOIN category c ON c.catid = e.catid
LEFT JOIN venue v ON v.venueid = e.venueid
WHERE d.holiday = 0
) sub;
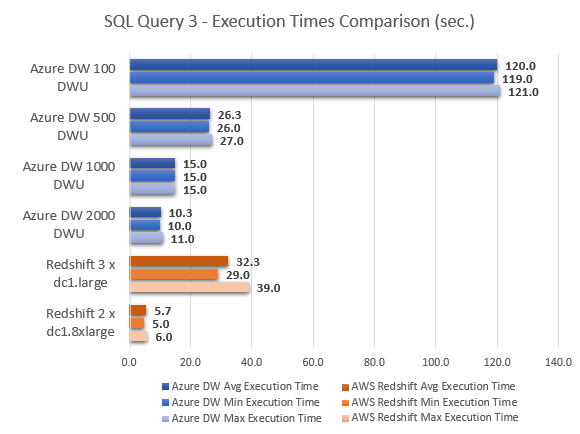
--QUERY 4
SELECT COUNT(*)
FROM ( SELECT SUM(sub1.pricepaid) AS price_paid ,
sub1.caldate AS date ,
sub1.username
FROM ( SELECT s.pricepaid ,
d.caldate ,
u.username
FROM Sales s
LEFT JOIN date d ON s.dateid = s.dateid
LEFT JOIN users u ON s.buyerid = u.userid
WHERE s.saletime BETWEEN '2008-12-01' AND '2008-12-31'
) sub1
GROUP BY sub1.caldate ,
sub1.username
) AS sub2;
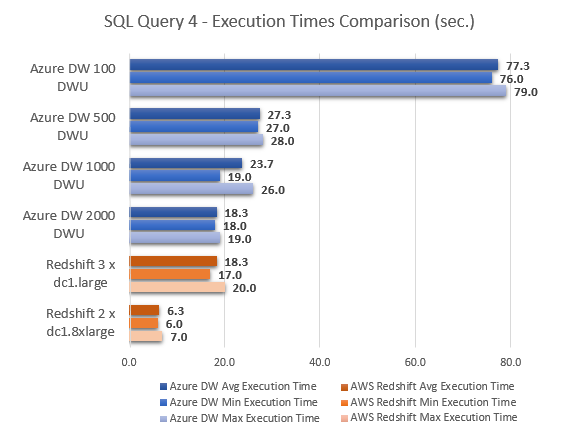
--QUERY 5
WITH CTE1 ( c1 )
AS ( SELECT COUNT(1) AS c1
FROM Sales s
WHERE saletime BETWEEN '2008-12-01' AND '2008-12-31'
GROUP BY salesid
HAVING COUNT(*) = 1
),
CTE2 ( c2 )
AS ( SELECT COUNT(1) AS c2
FROM Listing e
WHERE listtime BETWEEN '2008-12-01' AND '2008-12-31'
GROUP BY listid
HAVING COUNT(*) = 1
),
CTE3 ( c3 )
AS ( SELECT COUNT(1) AS c3
FROM Date d
GROUP BY dateid
HAVING COUNT(*) = 1
)
SELECT COUNT(*)
FROM CTE1
RIGHT JOIN CTE2 ON CTE1.c1 <> CTE2.c2
RIGHT JOIN CTE3 ON CTE3.c3 = CTE2.c2
AND CTE3.c3 <> CTE1.c1
GROUP BY CTE1.c1
HAVING COUNT(*) > 1;
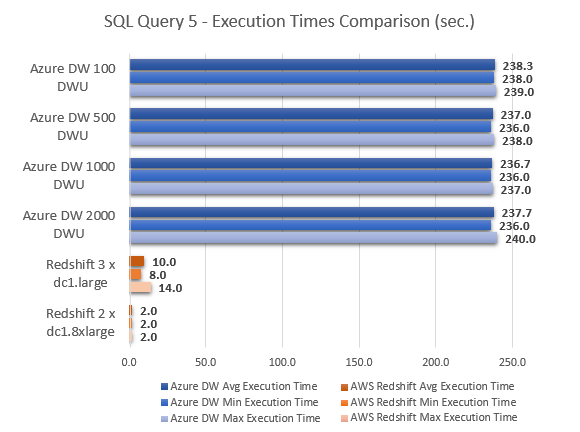
--QUERY 6
WITH cte
AS ( SELECT s1.* ,
COALESCE(u.likesports, u.liketheatre, u.likeconcerts,
u.likejazz, u.likeclassical, u.likeopera,
u.likerock, u.likevegas, u.likebroadway,
u.likemusicals) AS interests
FROM sales s1
LEFT JOIN users u ON s1.buyerid = u.userid
WHERE EXISTS ( SELECT s2.*
FROM sales s2
LEFT JOIN event e ON s2.eventid = e.eventid
LEFT JOIN date d ON d.dateid = s2.dateid
LEFT JOIN listing l ON l.listid = s2.listid
AND s1.salesid = s2.salesid )
AND NOT EXISTS ( SELECT s3.*
FROM sales s3
LEFT JOIN event e ON s3.eventid = e.eventid
LEFT JOIN category c ON c.catid = e.catid
WHERE c.catdesc = 'National Basketball Association'
AND s1.salesid = s3.salesid )
)
SELECT COUNT(*)
FROM cte
WHERE cte.dateid IN (
SELECT dateid
FROM ( SELECT ss.dateid ,
ss.buyerid ,
RANK() OVER ( PARTITION BY ss.dateid ORDER BY ss.saletime DESC ) AS daterank
FROM sales ss
) sub
WHERE sub.daterank = 1 );
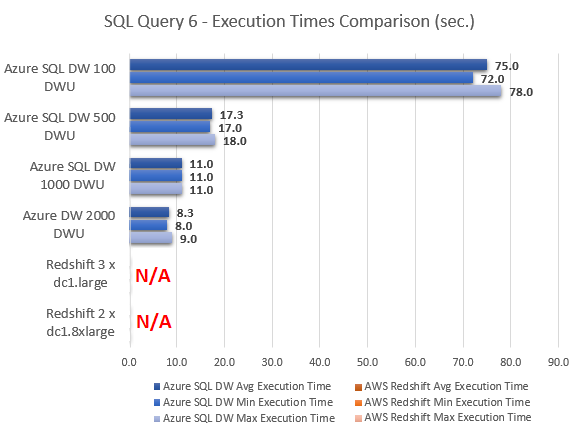
--QUERY 7
WITH Temp ( sum_pricepaid, sum_commission, sum_qtysold, eventname, caldate, username, Row1 )
AS ( SELECT SUM(s.pricepaid) AS sum_pricepaid ,
SUM(s.commission) AS sum_commission ,
SUM(s.qtysold) AS sum_qtysold ,
e.eventname ,
d.caldate ,
u.username ,
ROW_NUMBER() OVER ( PARTITION BY e.eventname ORDER BY e.starttime DESC ) AS Row1
FROM Sales s
JOIN Event e ON s.eventid = e.eventid
JOIN Date d ON s.dateid = d.dateid
JOIN Listing l ON l.listid = s.listid
JOIN Users u ON l.sellerid = u.userid
WHERE d.holiday <> 1
GROUP BY e.eventname ,
d.caldate ,
e.starttime ,
u.username
)
SELECT COUNT(*)
FROM Temp
WHERE Row1 = 1;
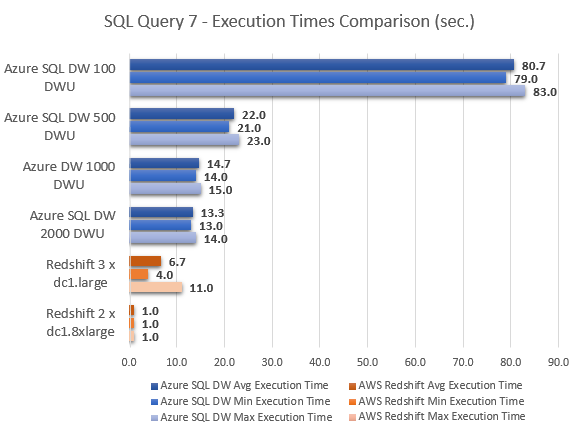
--QUERY 8
SELECT COUNT(*)
FROM ( SELECT a.pricepaid ,
a.eventname ,
NTILE(10) OVER ( ORDER BY a.pricepaid DESC ) AS ntile_pricepaid ,
a.qtysold ,
NTILE(10) OVER ( ORDER BY a.qtysold DESC ) AS ntile_qtsold ,
a.commission ,
NTILE(10) OVER ( ORDER BY a.commission DESC ) AS ntile_commission
FROM ( SELECT SUM(pricepaid) AS pricepaid ,
SUM(qtysold) AS qtysold ,
SUM(commission) AS commission ,
e.eventname
FROM Sales s
JOIN Date d ON s.dateid = s.dateid
JOIN Event e ON s.eventid = e.eventid
JOIN Listing l ON l.listid = s.listid
WHERE d.caldate > l.listtime
GROUP BY e.eventname
) a
) z;
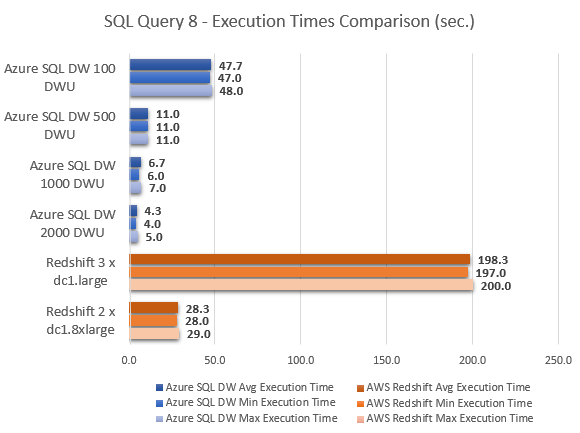
Even taking Azure SQL DW 500 DWU and Azure SQL DW 2000 DWU out of equation, at face value, it is easy to conclude that Amazon Redshift MPP performed much better across most queries. With the exception of query 8, where Azure SQL DW came out performing a lot better Redshift, Azure SQL DW took a lot longer to compute the results, in some instances 40 times slower then cooperatively priced Redshift instance e.g. query 2. The very last query results, however, show Azure SQL DW performing considerably better in comparison to Redshift, with Amazon’s service also having troubles executing query 6 (hence the lack of results for this particular execution) and indicating the lack of support for the sub-query used by throwing the following error message.
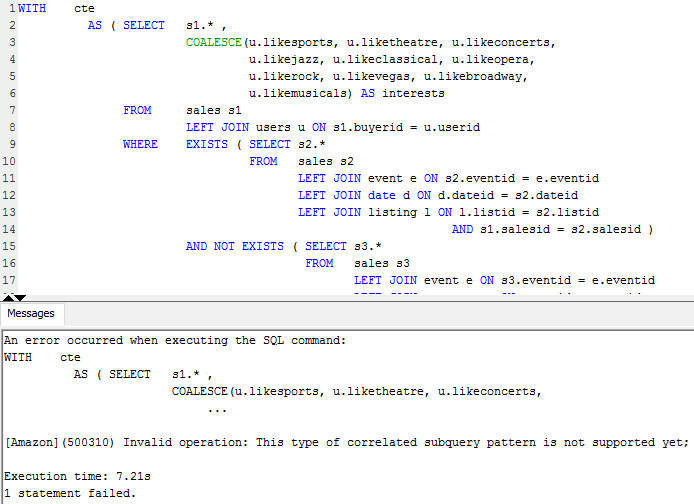
This only goes to show that the performance achieved from those two cloud MPP databases heavily depends on the type of workload performed, with some queries favouring AWS offering more than Azure and vice versa. Also, it is worth noting that for a typical business scenarios where standard queries issued by analysts will mostly be comprised of some level of data aggregation across a few schema objects e.g. building a summary report, the performance difference was marginal. Interestingly, query number 5 performed identically irrespective of the number of DTUs allocated to the instance. Majority of the time allocated to computing the output was dedicated to a ‘ReturnOperation’, as shown by the optimizer, with the following query issued to this step.

This leads me to another observation – the performance increase between 100, 500, 1000 and 2000 DWU increments wasn’t as linear as I expected across all queries (average execution speed). With the exception of query 5 which looks like an outlier, the most significant improvements were registered when moving from 100 DWU to 500 DWU (which roughly corresponded to price increments). However, going above 500 DWU yielded less noticeable speed increases for further cumulative changes to the instance scale.
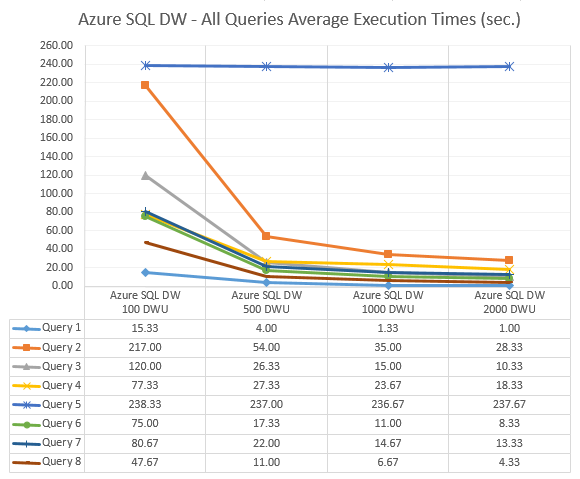
Data Connectivity and Visualization
Figuring out how to best store the data underpinning business transactions is only half the battle; making use of it through reporting and analytics is the ultimate goal of data collection. Using the same test data set I briefly tried Microsoft’s Power BI Desktop and Tableau applications to create a simple visualizations of the sales data stored in the fictitious TICKIT database. Microsoft SQL DW Azure portal also offers direct access link to Power BI online analytics service (see image below), with Azure SQL Data Warehouse listed among the supported data sources but I opted for a local install of Power BI Desktop instead for my quick analysis.

Power BI Desktop offers Azure SQL DW specific connection as per image below but specifying a standard SQL Server instance (Azure or on premise) also yielded a valid connection.

Building a sample ‘Sales Analysis’ report was a very straightforward affair but most importantly the execution speed when dragging measures and dimensions around onto the report development pane was very fast in DirectQuery mode even when configured with minimal number of DWUs. Once all object relationships and their cardinality was configured I could put together a simple report or visualize my data without being distracted by query performance lag or excessive wait times.
In case of Tableau, you can connect to Azure SQL Data Warehouse simply by selecting Microsoft SQL Server from the server options available, there is no Azure SQL DW dedicated connection type. Performance-wise, Tableau executed all aggregation and sorting queries with minimal lag and I could easily perform basic exploratory data analysis on my test data set with little to no delay.
Below is a short example video clip depicting the process of connecting to Azure SQL DW (running on the minimal configuration from performance standpoint i.e. 100 DWU) and creating a few simple graphs, aggregating sales data. You can immediately notice that in spite of minimal resource allocation the queries run quite fast (main table – dbo.Sales – comprised of over 50,000,000 records) with little intermission between individual aggregation executions. Query execution speed improved considerably when the instance was scaled out to 500 DWU with same or similar queries recording sub-second execution times.
Conclusion
With the advent of big data and ever increasing need for more computational power and bigger storage, cloud deployments are poised to become the de facto standard for any data volume, velocity and variety-intensive workloads. Microsoft has already established itself as a formidable database software vendor with its SQL Server platform gradually taking the lead away from its chief competitor in this space – Oracle (at least if you believe the 2015 Gartner Magic Quadrant for operational DBMSs) and has had a robust and service-rich cloud (Azure) database strategy in place for some time. Yet, it was Amazon, with its Redshift cloud MPP offering that saw the window of opportunity to fill the market void for a cheap and scalable data warehouse solution, something that Microsoft has not offered in its Azure ecosystem until now.
On the whole, Microsoft’s first foray into cloud-enabling their MPP architecture looks promising. As stated before this product is still in preview so chances are that there is still a ton of quirks and imperfections to iron out, however, I generally like the features, flexibility and non-byzantine approach to scaling that it offers. I like the fact that there are differentiating factors that set it apart from other vendors e.g. ability to query seamlessly across both relational data in a relational database and non-relational data in common Hadoop formats (PolyBase), hybrid architecture between on-premises and cloud and most of all, ability to pause, grow and shrink the data warehouse a matter of seconds. The fact that, for example, Azure SQL DW can integrate with an existing on-premises infrastructure and allow for a truly hybrid approach should open up new options for streamlining, integrating and cost-saving across data storage and analytics stack e.g. rather than provisioning secondary on-premises APS (Analytics Platform System) for disaster recovery and business continuity best practices (quite an expensive exercise), one could simply utilize Azure SQL DW as a drop-in replacement. Given that storage and compute have been decoupled, Azure SQL DW could operate mostly in a paused state, allowing for considerable savings, yet fulfilling the need for a robust, on-demand back up system in case of the primary appliance failure, as per diagram below (click on image to expand).
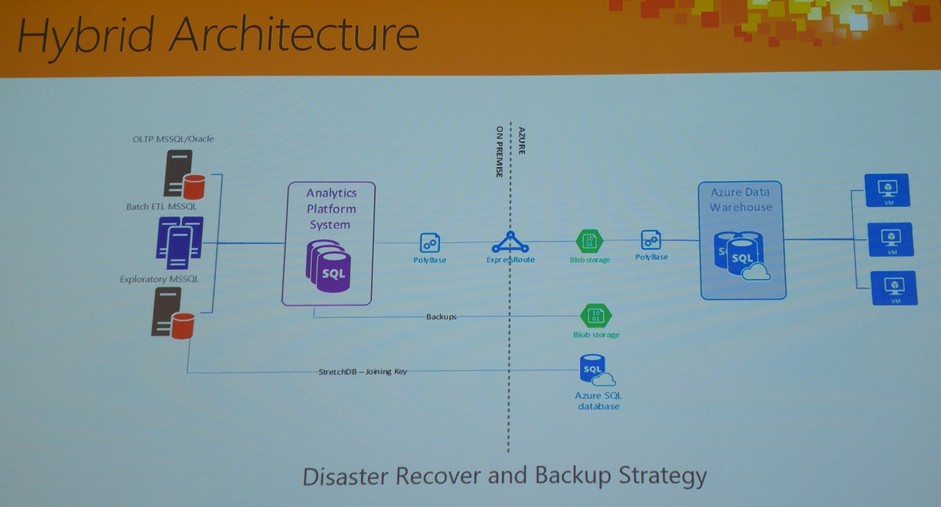
In terms of performance/cost I think that once the service comes out of preview I would expect either for the performance to improve or the price to be lowered to make it truly competitive with what’s on offer from AWS. It’s still early days and very much a work in progress so I’m looking forward to see what this service can provide with a production-ready release, but Azure SQL DW looks like a solid attempt in disrupting Amazon’s dominance of Redshift in the cloud data warehouse space, the fastest growing service in their ever expanding arsenal.
http://scuttle.org/bookmarks.php/pass?action=addThis entry was posted on Friday, January 15th, 2016 at 9:50 am and is filed under Azure, Cloud Computing. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.



admin February 22nd, 2016 at 3:03 am
Thanks for checking it out!