Designing data acquisition framework in SQL Server and SSIS – how to source and integrate external data for a decision support system or data warehouse (Part 2)
May 25th, 2016 / No Comments » / by admin
Note: Part 1 to this series can be found HERE, Part 3 HERE, Part 4 HERE and all the code and additional files for this post can be downloaded from my OneDrive folder HERE.
Continuing on from part 1 to this series, having set up all the scaffolding and support databases/objects, we are now ready to roll with the punches and start implementing the actual code responsible for some preliminary activities (before acquisition commences) as well as all heavy lifting when acquiring the source data. As per activities outlined in part 1, this post looks into pre-acquisition tasks (activities which facilitate subsequent data coping e.g. source server availability checking, schema modifications check, pre-load indexes management) and acquisition code for large tables, so jumping ahead a little bit into the actual package design (see SSIS package design details in part 4), the area of focus is as per the image below.
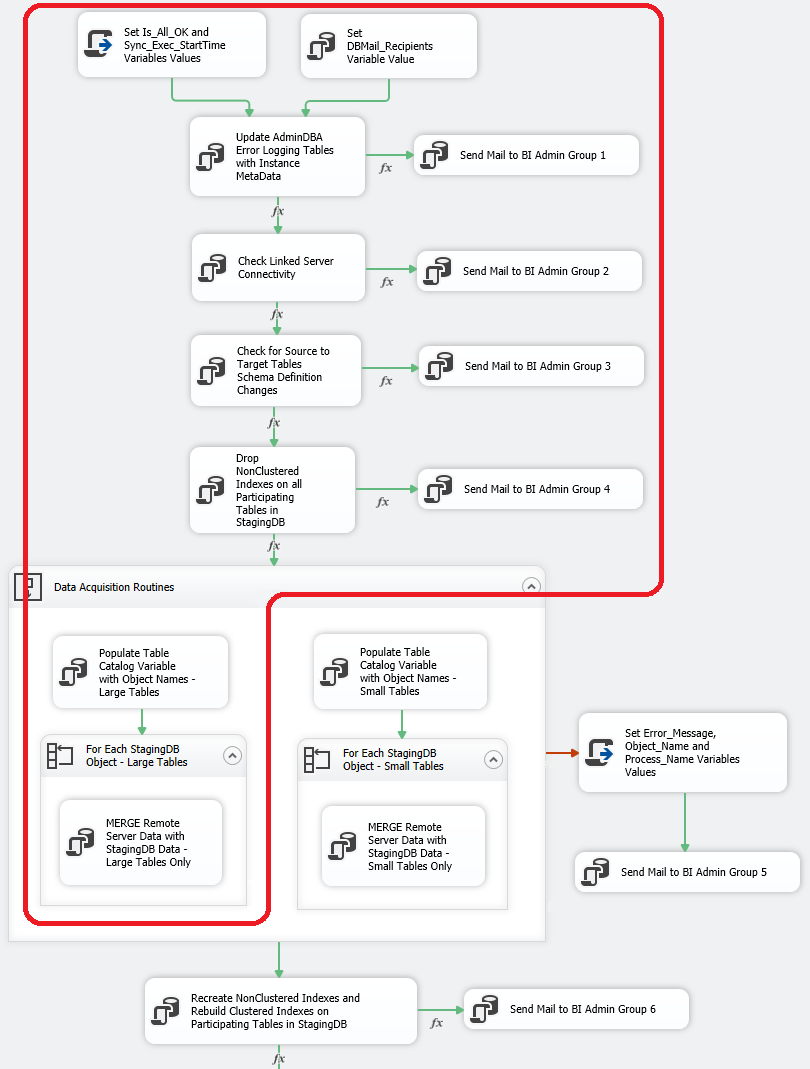
Pre-acquisition Tasks Overview and Code
To start with, we will set the initial values for the three variables used in the package using a combination of two transformations i.e. Script Task and Execute SQL Task. The Script Task transformation will run a snippet of C# code which sets the initial values of ‘Is_All_OK’ and ‘Sync_Exec_StartTime’ variables responsible for binary task execution status and package execution start time respectively. Since one of post-execution steps deals with checking the AdminDBA database for an errors encountered during package runtime, it is important to log package execution start date and time (used as log search query parameters when defining search time frame). The code run in this step (most of it just boilerplate, with the main sections highlighted) is as per below whereas all the package configuration details are described in part 4 to this series.
#region Help: Introduction to the script task
/* The Script Task allows you to perform virtually any operation that can be accomplished in
* a .Net application within the context of an Integration Services control flow.
*
* Expand the other regions which have "Help" prefixes for examples of specific ways to use
* Integration Services features within this script task. */
#endregion
#region Namespaces
using System;
using System.Data;
using Microsoft.SqlServer.Dts.Runtime;
using System.Windows.Forms;
#endregion
namespace ST_44c20947eb6c4c5cb2f698bdd17b3534
{
/// <summary>
/// ScriptMain is the entry point class of the script. Do not change the name, attributes,
/// or parent of this class.
/// </summary>
[Microsoft.SqlServer.Dts.Tasks.ScriptTask.SSISScriptTaskEntryPointAttribute]
public partial class ScriptMain : Microsoft.SqlServer.Dts.Tasks.ScriptTask.VSTARTScriptObjectModelBase
{
#region Help: Using Integration Services variables and parameters in a script
/* To use a variable in this script, first ensure that the variable has been added to
* either the list contained in the ReadOnlyVariables property or the list contained in
* the ReadWriteVariables property of this script task, according to whether or not your
* code needs to write to the variable. To add the variable, save this script, close this instance of
* Visual Studio, and update the ReadOnlyVariables and
* ReadWriteVariables properties in the Script Transformation Editor window.
* To use a parameter in this script, follow the same steps. Parameters are always read-only.
*
* Example of reading from a variable:
* DateTime startTime = (DateTime) Dts.Variables["System::StartTime"].Value;
*
* Example of writing to a variable:
* Dts.Variables["User::myStringVariable"].Value = "new value";
*
* Example of reading from a package parameter:
* int batchId = (int) Dts.Variables["$Package::batchId"].Value;
*
* Example of reading from a project parameter:
* int batchId = (int) Dts.Variables["$Project::batchId"].Value;
*
* Example of reading from a sensitive project parameter:
* int batchId = (int) Dts.Variables["$Project::batchId"].GetSensitiveValue();
* */
#endregion
#region Help: Firing Integration Services events from a script
/* This script task can fire events for logging purposes.
*
* Example of firing an error event:
* Dts.Events.FireError(18, "Process Values", "Bad value", "", 0);
*
* Example of firing an information event:
* Dts.Events.FireInformation(3, "Process Values", "Processing has started", "", 0, ref fireAgain)
*
* Example of firing a warning event:
* Dts.Events.FireWarning(14, "Process Values", "No values received for input", "", 0);
* */
#endregion
#region Help: Using Integration Services connection managers in a script
/* Some types of connection managers can be used in this script task. See the topic
* "Working with Connection Managers Programatically" for details.
*
* Example of using an ADO.Net connection manager:
* object rawConnection = Dts.Connections["Sales DB"].AcquireConnection(Dts.Transaction);
* SqlConnection myADONETConnection = (SqlConnection)rawConnection;
* //Use the connection in some code here, then release the connection
* Dts.Connections["Sales DB"].ReleaseConnection(rawConnection);
*
* Example of using a File connection manager
* object rawConnection = Dts.Connections["Prices.zip"].AcquireConnection(Dts.Transaction);
* string filePath = (string)rawConnection;
* //Use the connection in some code here, then release the connection
* Dts.Connections["Prices.zip"].ReleaseConnection(rawConnection);
* */
#endregion
/// <summary>
/// This method is called when this script task executes in the control flow.
/// Before returning from this method, set the value of Dts.TaskResult to indicate success or failure.
/// To open Help, press F1.
/// </summary>
///
public void Main()
{
// TODO: Add your code here
DateTime saveNow = DateTime.Now;
Dts.Variables["Is_All_OK"].Value = 0;
Dts.Variables["Sync_Exec_StartTime"].Value = saveNow;
Dts.TaskResult = (int)ScriptResults.Success;
}
#region ScriptResults declaration
/// <summary>
/// This enum provides a convenient shorthand within the scope of this class for setting the
/// result of the script.
///
/// This code was generated automatically.
/// </summary>
enum ScriptResults
{
Success = Microsoft.SqlServer.Dts.Runtime.DTSExecResult.Success,
Failure = Microsoft.SqlServer.Dts.Runtime.DTSExecResult.Failure
};
#endregion
}
}
The second transformation executes user defined function created in part 1, acquiring e-mail addresses from the corresponding table and storing them in a DBMail_Receipients SSIS variable. These email addresses can be used for operator notifications handling part of the process, when an exception is raised at package runtime. I will dive into package structure in more details in the next post to this series so at this stage is only important to understand that these two steps run simultaneously and as a prelude to further tasks execution.
Next up, we will proceed to update AdminDBA database based on the target server instance metadata. For this purpose, I have used the UPDATE stored procedure described in detail in two of my previous posts, mainly HERE and HERE. The code is quite complex and lengthy so for the sake of succinctness I will refrain from posting it here but you can read more about its functionality HERE and grab a copy from my OneDrive folder HERE. This stored procedure is run in order to update AdminDBA database with the latest instance metadata. As AdminDBA database stores a granular data of all databases, objects, schemas etc. for error log reference purposes, this data needs to be kept up-to-date to account for every change that has either added, deleted or updated the object and/or its status. This code does exactly that – it ploughs through the SQL Server instance and packages metadata, making sure that all changes have been accounted for so that any error in the package execution can be logged and referenced across instance, database, schema and object level.
Since one of the assumptions made in Part 1 was that in case any connectivity issues occur, the job will wait for a predefined period of time, a predefined number of times before reporting a failed connectivity status, the first thing to do is to ensure that at the initiation phase the linked server connection status is validated. For this purpose, we can use the SQL Server connection status system stored procedure along with a re-try routine delayed by the predefined amount of time as per the code below.
USE StagingDB;
GO
CREATE PROCEDURE [dbo].[usp_checkRemoteSvrConnectionStatus]
@Remote_Server_Name VARCHAR(256) ,
@Is_All_OK INT OUTPUT ,
@Error_Message VARCHAR(2000) OUTPUT ,
@Process_Name VARCHAR(250) OUTPUT
AS
BEGIN
SET NOCOUNT ON;
SET @Process_Name = ( SELECT OBJECT_NAME(objectid)
FROM sys.dm_exec_requests r
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) a
WHERE session_id = @@spid
);
DECLARE @errno INT;
DECLARE @errMsg VARCHAR(2048);
DECLARE @isDebugMode INT = 1;
DECLARE @Remote_Server_NameConv sysname;
DECLARE @ct INT = 4;
IF @isDebugMode = 1
BEGIN
PRINT 'Checking for Linked Server Connection...';
END;
Start:
BEGIN TRY
SELECT @Remote_Server_NameConv = CONVERT(sysname, @Remote_Server_Name);
EXEC sys.sp_testlinkedserver @Remote_Server_NameConv;
END TRY
BEGIN CATCH
SET @errno = @@ERROR;
SET @errMsg = ERROR_MESSAGE();
SET @Is_All_OK = 0;
END CATCH;
IF @Is_All_OK = 0
AND @ct > 1
BEGIN
SET @ct = @ct - 1;
IF @isDebugMode = 1
BEGIN
PRINT 'Connection to Linked Server '
+ @Remote_Server_Name
+ ' cannot be established. Will attempt to connect again in 5 minutes. Number of re-tries left: '
+ CAST(@ct AS VARCHAR(10)) + '';
END;
WAITFOR DELAY '00:05:00';
GOTO Start;
END;
IF @Is_All_OK = 1
BEGIN
GOTO Finish;
END;
Finish:
IF @errno <> 0
OR @Is_All_OK = 0
BEGIN
SET @Error_Message = 'Connection to Linked Server '
+ @Remote_Server_Name
+ ' has dropped or cannot be resolved. The error massage recorded by this process is as follows: '
+ @errMsg
+ ' This package cannot proceed any further....please troubleshoot!';
IF @isDebugMode = 1
BEGIN
PRINT @Error_Message;
END;
END;
ELSE
BEGIN
SET @Is_All_OK = 1;
SET @Error_Message = 'All Good !';
IF @isDebugMode = 1
BEGIN
PRINT 'Connection to Linked Server '
+ @Remote_Server_Name + ' successfull !';
END;
END;
END;
In case of persisting connection issues (the code will execute 3 times, with the 5-minute wait time between each interval), error message, process name and binary error variable will be passed back to the SSIS package triggering sending an error event (more on the SSIS package implementation in part 4 to this series).
Continuing on, conforming to part 1 requirement which stated that ‘The source database schema is under constant development so target database, where the acquired data is stored, needs to be adjusted automatically’, we will focus on automated schema reconciliation. There are number of ways this functionality can be achieved but the simplest (and cheapest, since it does not involve third party tooling) way would be to use plain, old T-SQL wrapped around a stored procedure. The code below compares MySQL internal metadata for selected tables with the one in the staging database on the SQL Server instance and in case any dichotomies are found, it drops and recreates the affected object(s) while resolving any data types, null-ability, characters precisions, scale, length etc. This stored procedure is only applicable to MySQL-to-MSSQL schema synchronisation but I have developed similar code for a PostgreSQL-to-MSSQL job (see my blog post HERE) and also included a snipped of T-SQL which transforms it into a MSSQL-to-MSSQL job (please refer to the commented-out section). Also, in order for this code to work correctly, a unique primary key needs to be present on the tables participating in the comparison. Another thing to notice is that this code takes advantage of the data in one of the control tables storing database object names etc. This to ensure that in case we wish to take one or a number of tables out of this process, we can do so via including or excluding it in the referenced control table rather than hardcoding their names in the stored procedure. This allows for a central point of control at a granular level and prevents catering for specific scenarios in the procedure’s code.
USE StagingDB;
GO
CREATE PROCEDURE [dbo].[usp_checkRemoteSvrMySQLTablesSchemaChanges]
(
@Remote_Server_Name VARCHAR(256) ,
@Remote_Server_DB_Name VARCHAR(128) ,
@Remote_Server_DB_Schema_Name VARCHAR(128) ,
@Target_DB_Name VARCHAR(128) ,
@Target_DB_Schema_Name VARCHAR(128) ,
@Is_All_OK INT OUTPUT ,
@Process_Name VARCHAR(250) OUTPUT ,
@Error_Message VARCHAR(MAX) OUTPUT
)
WITH RECOMPILE
AS
SET NOCOUNT ON;
BEGIN
DECLARE @Is_ReCheck BIT = 0;
DECLARE @SQL NVARCHAR(MAX);
DECLARE @Is_Debug_Mode BIT = 0;
SET @Process_Name = ( SELECT OBJECT_NAME(objectid)
FROM sys.dm_exec_requests r
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) a
WHERE session_id = @@spid
);
Check_RemoteSvr_Schema:
IF OBJECT_ID('tempdb..#t_TblsMetadata') IS NOT NULL
BEGIN
DROP TABLE [#t_TblsMetadata];
END;
CREATE TABLE tempdb..[#t_TblsMetadata]
(
table_name VARCHAR(256) ,
column_name VARCHAR(256) ,
ordinal_position INT ,
is_nullable BIT ,
data_type VARCHAR(256) ,
character_maximum_length BIGINT ,
numeric_scale SMALLINT ,
numeric_precision SMALLINT ,
is_primary_key BIT ,
local_schema_name VARCHAR(55) ,
remote_schema_name VARCHAR(55) ,
local_or_remote VARCHAR(25)
);
SET @SQL = '
INSERT INTO #t_TblsMetadata
(
[table_name]
,[column_name]
,[ordinal_position]
,[is_nullable]
,[data_type]
,[character_maximum_length]
,[numeric_scale]
,[numeric_precision]
,[is_primary_key]
,[local_schema_name]
,[remote_schema_name]
,[local_or_remote]
)
SELECT
LTRIM(RTRIM(a.table_name)) AS table_name ,
LTRIM(RTRIM(a.column_name)) AS column_name ,
LTRIM(RTRIM(a.ordinal_position)) AS ordinal_position ,
CASE WHEN a.is_nullable = ''YES''
THEN 1 ELSE 0 END AS is_nullable ,
LTRIM(RTRIM(a.data_type)) AS data_type ,
LTRIM(RTRIM(a.character_maximum_length)) AS character_maximum_length ,
LTRIM(RTRIM(a.numeric_scale)) AS numeric_scale ,
LTRIM(RTRIM(a.numeric_precision)) AS numeric_precision ,
CASE WHEN a.column_key =
LTRIM(RTRIM(''pri'')) THEN 1 ELSE 0 END AS is_primary_key ,
m.local_schema_Name AS local_schema_name ,
LTRIM(RTRIM(a.table_schema)) AS remote_schema_name,
''remote'' AS local_or_remote
FROM OPENQUERY(' + @Remote_Server_Name + ',
''select
table_name,
column_name,
ordinal_position,
is_nullable,
data_type,
character_maximum_length,
numeric_scale,
numeric_precision ,
column_key,
table_schema
from information_Schema.columns
where table_schema = '''''
+ @Remote_Server_DB_Schema_Name + ''''''') a
JOIN
ControlDB.dbo.Ctrl_RemoteSvrs_Tables2Process m
ON a.table_name = m.local_table_name
AND m.local_schema_name = ''' + @Target_DB_Schema_Name + '''
AND m.Remote_Server_Name = ''' + @Remote_Server_Name + '''
WHERE m.Is_Active = 1
AND NOT EXISTS (SELECT 1
FROM ControlDB.dbo.Ctrl_RemoteSvrs_Tables2Process_ColumnExceptions o
WHERE
o.Local_Field_Name = a.column_name AND
o.local_table_name = a.table_name AND
o.local_schema_name = m.local_schema_name AND
o.Remote_Schema_Name = m.remote_schema_name
AND o.Is_Active = 1)';
/*===========================================================================================
-- SQL Server Version for reference only
SET @SQL = 'INSERT INTO #t_TblsMetadata
(
[table_name]
,[column_name]
,[ordinal_position]
,[is_nullable]
,[data_type]
,[character_maximum_length]
,[numeric_scale]
,[numeric_precision]
,[is_primary_key]
,[local_schema_name]
,[remote_schema_name]
,[local_or_remote]
)
SELECT
a.table_name,
a.column_name,
a.ordinal_position,
a.is_nullable,
a.data_type,
a.character_maximum_length,
a.numeric_scale,
a.numeric_precision,
a.is_primary_key,
m.local_schema_name,
a.remote_schema_name,
''Remote'' as local_or_remote
FROM OPENQUERY(' + @Remote_Server_Name
+ ',''SELECT
t.name AS table_name ,
c.name AS column_name ,
c.column_id AS ordinal_position ,
c.is_nullable ,
ss.name ,
tp.name AS data_type ,
c.max_length AS character_maximum_length ,
c.scale AS numeric_scale ,
c.precision AS numeric_precision ,
ISNULL(idx.pk_flag,0) as ''''is_primary_key'''' ,
ss.name AS remote_schema_name
FROM sys.tables t
JOIN sys.columns c ON t.object_id = c.object_id
JOIN sys.types tp ON c.user_type_id = tp.user_type_id
JOIN sys.objects so ON so.object_id = t.object_id
JOIN sys.schemas ss ON so.schema_id = ss.schema_id
LEFT JOIN (select i.name as index_name,
i.is_primary_key as pk_flag,
OBJECT_NAME(ic.OBJECT_ID) AS table_name,
COL_NAME(ic.OBJECT_ID,ic.column_id) AS column_name
FROM sys.indexes AS i INNER JOIN
sys.index_columns AS ic ON i.OBJECT_ID = ic.OBJECT_ID
AND i.index_id = ic.index_id
WHERE i.is_primary_key = 1) idx
ON idx.table_name = t.name and idx.column_name = c.name
WHERE ss.name =''''' + @Remote_Server_DB_Schema_Name + '''''
AND t.type = ''''u'''''') a
JOIN
ControlDB.dbo.Ctrl_RemoteSvrs_Tables2Process m
ON a.table_name = m.local_table_name
WHERE
m.Remote_Server_Name = ''' + @Remote_Server_Name + '''
AND m.Is_Active = 1
AND NOT EXISTS (SELECT 1
FROM ControlDB.dbo.Ctrl_RemoteSvrs_Tables2Process_ColumnExceptions o
WHERE
o.Local_Field_Name = a.column_name AND
o.local_table_name = a.table_name AND
o.local_schema_name = m.Local_Schema_Name AND
o.Remote_Schema_Name = a.remote_schema_name
AND o.Is_Active = 1)';
===========================================================================================*/
EXEC(@SQL);
IF @Is_Debug_Mode = 1
BEGIN
PRINT @SQL;
SELECT '#t_TblsMetadata table content for remote objects metadata:' AS 'HINT';
SELECT *
FROM #t_TblsMetadata
WHERE local_or_remote = 'Remote'
ORDER BY table_name ,
ordinal_position;
END;
IF @Is_ReCheck = 1
BEGIN
GOTO Check_Local_Schema;
END;
Check_Local_Schema:
SET @SQL = 'INSERT INTO #t_TblsMetadata
(
[table_name]
,[column_name]
,[ordinal_position]
,[is_nullable]
,[data_type]
,[character_maximum_length]
,[numeric_scale]
,[numeric_precision]
,[is_primary_key]
,[local_schema_name]
,[remote_schema_name]
,[local_or_remote]
)
SELECT
t.name AS table_name ,
c.name AS column_name ,
c.column_id AS ordinal_position ,
c.is_nullable ,
tp.name AS data_type ,
c.max_length AS character_maximum_length ,
c.scale AS numeric_scale ,
c.precision AS numeric_precision ,
ISNULL(idx.pk_flag,0) as ''is_primary_key'' ,
m.local_schema_name,
m.remote_schema_name ,
''local'' AS local_or_remote
FROM sys.tables t
JOIN sys.columns c ON t.object_id = c.object_id
JOIN sys.types tp ON c.user_type_id = tp.user_type_id
JOIN sys.objects so ON so.object_id = t.object_id
JOIN sys.schemas ss ON so.schema_id = ss.schema_id
LEFT JOIN (select i.name as index_name, i.is_primary_key as pk_flag, OBJECT_NAME(ic.OBJECT_ID) AS table_name,
COL_NAME(ic.OBJECT_ID,ic.column_id) AS column_name FROM sys.indexes AS i INNER JOIN
sys.index_columns AS ic ON i.OBJECT_ID = ic.OBJECT_ID
AND i.index_id = ic.index_id
WHERE i.is_primary_key = 1) idx on idx.table_name = t.name and idx.column_name = c.name
JOIN ControlDB.dbo.Ctrl_RemoteSvrs_Tables2Process m ON t.name = m.local_table_name AND m.local_schema_name = ss.name
WHERE t.type = ''u''
AND m.Remote_Server_Name = ''' + @Remote_Server_Name + '''
AND ss.name = ''' + @Target_DB_Schema_Name + '''
';
EXEC(@SQL);
IF @Is_Debug_Mode = 1
BEGIN
PRINT @SQL;
SELECT '#t_TblsMetadata table content for local objects metadata:' AS 'HINT';
SELECT *
FROM #t_TblsMetadata
WHERE local_or_remote = 'Local'
ORDER BY table_name ,
ordinal_position;
END;
IF OBJECT_ID('tempdb..#t_sql') IS NOT NULL
BEGIN
DROP TABLE [#t_sql];
END;
SELECT DISTINCT
t1.table_name AS Table_Name ,
t1.local_schema_name AS Local_Schema_Name ,
'create table [' + t1.local_schema_name + '].['
+ LOWER(t1.table_name) + '] (' + STUFF(o.list, LEN(o.list), 1,
'') + ')'
+ CASE WHEN t2.is_primary_key = 0 THEN ''
ELSE '; ALTER TABLE [' + t1.local_schema_name + '].['
+ t1.table_name + '] ' + ' ADD CONSTRAINT pk_'
+ LOWER(t1.local_schema_name) + '_'
+ LOWER(t2.table_name) + '_'
+ LOWER(REPLACE(t2.pk_column_names, ',', '_'))
+ ' PRIMARY KEY CLUSTERED ' + '('
+ LOWER(t2.pk_column_names) + ')'
END AS Create_Table_Schema_Definition_SQL ,
'if object_id (''[' + t1.local_schema_name + '].['
+ t1.table_name + ']' + ''', ''U'') IS NOT NULL drop table ['
+ t1.local_schema_name + '].[' + t1.table_name + ']' AS Drop_Table_SQL
INTO #t_sql
FROM #t_TblsMetadata t1
CROSS APPLY ( SELECT '[' + column_name + '] '
+ CASE WHEN data_type IN ( 'tinytext',
'smalltext',
'mediumtext',
'text', 'enum',
'longtext' )
THEN 'varchar'
WHEN data_type IN ( 'timestamp' )
THEN 'datetime'
ELSE data_type
END
+ CASE WHEN data_type IN ( 'date',
'time',
'tinyint',
'smallint',
'int', 'bigint',
'timestamp',
'uniqueidentifier',
'bit',
'datetimeoffset' )
THEN ''
WHEN character_maximum_length > 8000
OR character_maximum_length = -1
THEN '(max)'
WHEN data_type IN ( 'nvarchar',
'nchar' )
THEN '('
+ CAST(character_maximum_length
/ 2 AS VARCHAR) + ')'
WHEN data_type = 'decimal'
THEN '('
+ CAST(numeric_precision AS VARCHAR)
+ ', '
+ CAST(numeric_scale AS VARCHAR)
+ ')'
ELSE COALESCE('('
+ CAST(character_maximum_length AS VARCHAR)
+ ')', '')
END + ' '
+ ( CASE WHEN is_nullable = 0
THEN 'NOT '
ELSE ''
END ) + 'NULL' + ','
FROM #t_TblsMetadata
WHERE table_name = t1.table_name
AND local_or_remote = 'Remote'
ORDER BY ordinal_position
FOR
XML PATH('')
) o ( list )
JOIN ( SELECT table_name ,
is_primary_key ,
pk_column_names ,
column_name = REVERSE(RIGHT(REVERSE(pk_column_names),
LEN(pk_column_names)
- CHARINDEX(',',
REVERSE(pk_column_names))))
FROM ( SELECT table_name ,
is_primary_key ,
pk_column_names = STUFF(( SELECT
','
+ CAST(column_name AS VARCHAR(500))
FROM
#t_TblsMetadata z2
WHERE
z1.table_name = z2.table_name
AND z2.is_primary_key = 1
AND z2.local_or_remote = 'Remote'
ORDER BY z2.column_name ASC
FOR
XML
PATH('')
), 1, 1, '')
FROM #t_TblsMetadata z1
WHERE z1.is_primary_key = 1
AND z1.local_or_remote = 'Remote'
GROUP BY z1.table_name ,
z1.is_primary_key
) a
) t2 ON t1.table_name = t2.table_name
WHERE t1.local_or_remote = 'Remote';
IF @Is_Debug_Mode = 1
BEGIN
SELECT '#t_sql table content:' AS 'HINT';
SELECT *
FROM #t_sql;
END;
IF @Is_ReCheck = 1
BEGIN
GOTO Do_Table_Diff;
END;
Do_Table_Diff:
IF OBJECT_ID('tempdb..#t_diff') IS NOT NULL
BEGIN
DROP TABLE [#t_diff];
END;
WITH Temp_CTE ( table_name, column_name, is_nullable, data_type, local_schema_name, is_primary_key, character_maximum_length, numeric_scale, numeric_precision )
AS ( SELECT table_name = m.table_name ,
column_name = m.column_name ,
is_nullable = m.is_nullable ,
data_type = CASE WHEN m.data_type IN (
'tinytext',
'smalltext',
'mediumtext', 'text',
'enum', 'longtext' )
THEN 'varchar'
WHEN m.data_type IN (
'timestamp' )
THEN 'datetime'
ELSE m.data_type
END ,
local_schema_name = m.local_schema_name ,
is_primary_key = m.is_primary_key ,
character_maximum_length = COALESCE(CASE
WHEN m.character_maximum_length > 8000
OR m.character_maximum_length = -1
THEN 'max'
WHEN m.data_type = 'timestamp'
THEN CAST(l.character_maximum_length AS VARCHAR)
ELSE CAST(m.character_maximum_length AS VARCHAR)
END,
constants.character_maximum_length,
CAST(l.character_maximum_length AS VARCHAR)) ,
numeric_scale = COALESCE(CASE
WHEN m.data_type = 'timestamp'
THEN l.numeric_scale
ELSE m.numeric_scale
END,
constants.numeric_scale,
l.numeric_scale) ,
numeric_precision = COALESCE(CASE
WHEN m.data_type = 'timestamp'
THEN l.numeric_precision
ELSE m.numeric_precision
END,
m.numeric_precision,
constants.numeric_precision,
l.numeric_precision)
FROM #t_TblsMetadata m
LEFT JOIN ( SELECT 'char' AS data_type ,
NULL AS character_maximum_length ,
0 AS numeric_scale ,
0 AS numeric_precision
UNION ALL
SELECT 'varchar' ,
NULL ,
'0' ,
'0'
UNION ALL
SELECT 'time' ,
'5' ,
'7' ,
'16'
UNION ALL
SELECT 'date' ,
'3' ,
'0' ,
'10'
UNION ALL
SELECT 'datetime' ,
'8' ,
'3' ,
'23'
UNION ALL
SELECT 'datetime2' ,
'8' ,
'7' ,
'27'
UNION ALL
SELECT 'smalldatetime' ,
'4' ,
'0' ,
'16'
UNION ALL
SELECT 'bit' ,
'1' ,
'0' ,
'1'
UNION ALL
SELECT 'float' ,
'8' ,
'0' ,
'53'
UNION ALL
SELECT 'money' ,
'8' ,
'4' ,
'19'
UNION ALL
SELECT 'smallmoney' ,
'4' ,
'4' ,
'10'
UNION ALL
SELECT 'uniqueidentifier' ,
'16' ,
'0' ,
'0'
UNION ALL
SELECT 'xml' ,
'max' ,
'0' ,
'0'
UNION ALL
SELECT 'numeric' ,
'9' ,
'0' ,
'18'
UNION ALL
SELECT 'real' ,
'4' ,
'0' ,
'24'
UNION ALL
SELECT 'tinyint' ,
'1' ,
'0' ,
'3'
UNION ALL
SELECT 'smallint' ,
'2' ,
'0' ,
'5'
UNION ALL
SELECT 'int' ,
'4' ,
'0' ,
'10'
UNION ALL
SELECT 'bigint' ,
'8' ,
'0' ,
'20'
) constants ON m.data_type = constants.data_type
LEFT JOIN #t_TblsMetadata l ON l.column_name = m.column_name
AND l.table_name = m.table_name
AND l.data_type = ( CASE
WHEN m.data_type IN (
'tinytext',
'smalltext',
'mediumtext',
'text', 'enum',
'longtext' )
THEN 'varchar'
WHEN m.data_type IN (
'timestamp' )
THEN 'datetime'
ELSE m.data_type
END )
AND l.local_or_remote = 'Local'
WHERE m.local_or_remote = 'Remote'
EXCEPT
SELECT table_name ,
column_name ,
is_nullable ,
data_type ,
local_schema_name ,
is_primary_key ,
CASE WHEN character_maximum_length > 8000
OR character_maximum_length = -1
THEN 'max'
ELSE CAST(character_maximum_length AS VARCHAR)
END AS character_maximum_length ,
numeric_scale ,
numeric_precision
FROM #t_TblsMetadata
WHERE local_or_remote = 'Local'
)
SELECT DISTINCT
table_name ,
local_schema_name
INTO #t_diff
FROM Temp_CTE;
IF @Is_Debug_Mode = 1
BEGIN
SELECT '#t_diff table content:' AS 'HINT';
SELECT *
FROM #t_diff;
END;
IF @Is_ReCheck = 1
GOTO Results;
Run_SQL:
IF NOT EXISTS ( SELECT DISTINCT
Table_Name ,
Local_Schema_Name
FROM #t_sql a
WHERE EXISTS ( SELECT table_name
FROM #t_diff i
WHERE a.Table_Name = i.table_name ) )
BEGIN
GOTO Schema_Diff_ReCheck;
END;
ELSE
BEGIN
DECLARE @schema_name VARCHAR(50);
DECLARE @table_name VARCHAR(256);
DECLARE @sql_select_dropcreate NVARCHAR(MAX);
DECLARE db_cursor CURSOR FORWARD_ONLY
FOR
SELECT DISTINCT
Table_Name ,
Local_Schema_Name
FROM #t_sql a
WHERE EXISTS ( SELECT table_name
FROM #t_diff i
WHERE a.Table_Name = i.table_name );
OPEN db_cursor;
FETCH NEXT
FROM db_cursor INTO @table_name, @schema_name;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
SET @sql_select_dropcreate = ( SELECT
Drop_Table_SQL
FROM
#t_sql
WHERE
Table_Name = @table_name
) + '; '
+ ( SELECT Create_Table_Schema_Definition_SQL
FROM #t_sql
WHERE Table_Name = @table_name
);
IF @Is_Debug_Mode = 1
BEGIN
PRINT @sql_select_dropcreate;
END;
EXEC sp_sqlexec @sql_select_dropcreate;
SET @Error_Message = 'All Good!';
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION;
SET @Is_All_OK = 0;
SET @Error_Message = 'This operation has been unexpectandly terminated due to error: '''
+ ERROR_MESSAGE() + ''' at line '
+ CAST(ERROR_LINE() AS VARCHAR);
END CATCH;
FETCH NEXT FROM db_cursor INTO @table_name,
@schema_name;
END;
CLOSE db_cursor;
DEALLOCATE db_cursor;
SET @Is_ReCheck = 1;
END;
Schema_Diff_ReCheck:
IF @Is_ReCheck = 1
BEGIN
GOTO Check_RemoteSvr_Schema;
END;
Results:
IF EXISTS ( SELECT TOP 1
*
FROM #t_diff )
BEGIN
SET @Is_All_OK = 0;
SET @Error_Message = 'Table schema reconciliation between '
+ '' + @@SERVERNAME + '' + ' and remote database on '''
+ @Remote_Server_Name + '''' + CHAR(10);
SET @Error_Message = @Error_Message
+ 'failed. Please troubleshoot.';
END;
ELSE
BEGIN
SET @Is_All_OK = 1;
SET @Error_Message = 'All Good!';
END;
IF OBJECT_ID('tempdb..#t_TblsMetadata') IS NOT NULL
BEGIN
DROP TABLE [#t_TblsMetadata];
END;
IF OBJECT_ID('tempdb..#t_sql') IS NOT NULL
BEGIN
DROP TABLE [#t_sql];
END;
IF OBJECT_ID('tempdb..#t_diff') IS NOT NULL
BEGIN
DROP TABLE [#t_diff];
END;
END;
GO
Next step in the process involves dropping any indexes. For this task, the following stored procedure can be used, which also allows indexes re-creation and reorganization once all the source data has been copied across. In this way we can reference the same code for both actions, changing variable values based on the intended action i.e. setting @Create_Drop_Idxs value to either DROP or CREATE. Again, this code references specific ControlDB database object to allow for finer control and customisations and also creates a small table on the StagingDB database later used in indexes recreation process before it gets deleted at the step completion.
USE StagingDB;
GO
CREATE PROCEDURE [dbo].[usp_runCreateDropStagingIDXs]
(
@Target_DB_Name VARCHAR(128) ,
@Target_DB_Schema_Name VARCHAR(128) ,
@Create_Drop_Idxs VARCHAR(6) ,
@Reorg_PKs CHAR(3) ,
@Drop_TempTbls CHAR(3) ,
@Error_Message VARCHAR(2000) OUTPUT ,
@Process_Name VARCHAR(256) OUTPUT ,
@Is_All_OK INT OUTPUT
)
WITH RECOMPILE
AS
SET NOCOUNT ON;
BEGIN
DECLARE @Is_Debug_Mode BIT = 1;
DECLARE @err INT;
DECLARE @SQL NVARCHAR(MAX);
DECLARE @Index_Or_PKName VARCHAR(256);
DECLARE @Tgt_Object_Name VARCHAR(256);
DECLARE @ID INT;
DECLARE @Index_Type VARCHAR(128);
DECLARE @Index_ColNames VARCHAR(1024);
DECLARE @PkColNames VARCHAR(1024);
DECLARE @Is_Unique VARCHAR(56);
DECLARE @Indx_Options VARCHAR(MAX);
SET @Process_Name = ( SELECT OBJECT_NAME(objectid)
FROM sys.dm_exec_requests r
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) a
WHERE session_id = @@spid
);
IF EXISTS ( SELECT a.TABLE_NAME ,
a.TABLE_SCHEMA ,
b.create_date
FROM INFORMATION_SCHEMA.TABLES a
JOIN sys.objects b ON a.TABLE_NAME = b.name
WHERE a.TABLE_NAME = 'Temp_Staging_PKsIndexes_MetaData'
AND a.TABLE_SCHEMA = 'dbo' --AND DATEDIFF(SECOND, b.create_date, SYSDATETIME()) > 10
)
BEGIN
DROP TABLE StagingDB.dbo.Temp_Staging_PKsIndexes_MetaData;
END;
CREATE TABLE [dbo].[Temp_Staging_PKsIndexes_MetaData]
(
ID INT IDENTITY(1, 1)
NOT NULL ,
[DBName] [sysname] NOT NULL ,
[SchemaName] [sysname] NOT NULL ,
[TableName] [NVARCHAR](128) NULL ,
[IndexOrPKName] [sysname] NULL ,
[IndexType] [NVARCHAR](60) NULL ,
[IsUnique] [VARCHAR](6) NOT NULL ,
[IsPK] [VARCHAR](11) NOT NULL ,
[PKColNames] [VARCHAR](MAX) NULL ,
[IndexColNames] [VARCHAR](MAX) NULL ,
[Indx_Options] VARCHAR(MAX) NULL ,
[From_MetaData] [BIT] NULL
);
;
WITH TempTbl ( dbName, schemaName, tableName, indexOrPKName, isUniqueConstraint, isUnique, isPK, indexType, colNames )
AS ( SELECT dbName = tt.TABLE_CATALOG ,
schemaName = s.name ,
tableName = OBJECT_NAME(i.object_id) ,
indexOrPKName = i.name ,
isUniqueConstraint = i.is_unique_constraint ,
isUnique = i.is_unique ,
isPK = i.is_primary_key ,
indexType = i.type_desc ,
participatingColNames = c.name
FROM StagingDB.sys.indexes i
JOIN StagingDB.sys.index_columns AS ic ON i.object_id = ic.object_id
AND i.index_id = ic.index_id
JOIN StagingDB.sys.columns AS c ON ic.object_id = c.object_id
AND c.column_id = ic.column_id
JOIN StagingDB.sys.tables t ON c.object_id = t.object_id
JOIN StagingDB.sys.schemas s ON t.schema_id = s.schema_id
JOIN INFORMATION_SCHEMA.TABLES tt ON tt.TABLE_SCHEMA = s.name
AND tt.TABLE_NAME = OBJECT_NAME(i.object_id)
WHERE t.type = 'U'
AND s.name = @Target_DB_Schema_Name
AND tt.TABLE_CATALOG = @Target_DB_Name
)
INSERT INTO [Temp_Staging_PKsIndexes_MetaData]
( [DBName] ,
[SchemaName] ,
[TableName] ,
[IndexOrPKName] ,
[IndexType] ,
[IsUnique] ,
[IsPK] ,
[PKColNames] ,
[IndexColNames] ,
[Indx_Options] ,
[From_MetaData]
)
SELECT DISTINCT
OutTab.dbName ,
OutTab.schemaName ,
OutTab.tableName ,
OutTab.indexOrPKName ,
OutTab.indexType ,
CASE WHEN OutTab.isUnique = 1 THEN 'UNIQUE'
ELSE ''
END AS 'IsUnique' ,
CASE WHEN OutTab.isPK = 1 THEN 'PRIMARY KEY'
ELSE ''
END AS 'IsPK' ,
PKColNames = COALESCE(STUFF((SELECT
','
+ InrTab.colNames
FROM TempTbl InrTab
WHERE
InrTab.tableName = OutTab.tableName
AND InrTab.indexOrPKName = OutTab.indexOrPKName
AND IsPK = 1
ORDER BY InrTab.colNames
FOR XML PATH('') ,
TYPE).value('.',
'VARCHAR(MAX)'),
1, 1, SPACE(0)), '') ,
IndexColNames = COALESCE(STUFF((SELECT
','
+ InrTab.colNames
FROM
TempTbl InrTab
WHERE
InrTab.tableName = OutTab.tableName
AND InrTab.indexOrPKName = OutTab.indexOrPKName
AND IsPK <> 1
ORDER BY InrTab.colNames
FOR XML
PATH('') ,
TYPE).value('.',
'VARCHAR(MAX)'),
1, 1, SPACE(0)), '') ,
'' ,
1
FROM ( SELECT DISTINCT
tr.dbName ,
tr.schemaName ,
tr.tableName ,
tr.indexOrPKName ,
tr.indexType ,
tr.colNames ,
tr.isUnique ,
tr.isPK
FROM TempTbl tr
) AS OutTab;
INSERT INTO Temp_Staging_PKsIndexes_MetaData
( DBName ,
SchemaName ,
TableName ,
IndexOrPKName ,
IndexType ,
IsUnique ,
IsPK ,
PKColNames ,
IndexColNames ,
Indx_Options ,
From_MetaData
)
SELECT [Database_Name] ,
[Schema_Name] ,
[Table_Name] ,
[Index_or_PKName] ,
[Index_Type] ,
[Is_Unique] ,
[Is_PK] ,
[PK_ColNames] ,
[Indx_ColNames] ,
[Indx_Options] ,
0
FROM [ControlDB].[dbo].[Ctrl_INDXandPKs2Process]
WHERE Database_Name = @Target_DB_Name
AND [Schema_Name] = @Target_DB_Schema_Name;
IF @Is_Debug_Mode = 1
BEGIN
SELECT *
FROM Temp_Staging_PKsIndexes_MetaData
WHERE DBName = @Target_DB_Name
AND SchemaName = @Target_DB_Schema_Name;
END;
IF @Create_Drop_Idxs = LTRIM(RTRIM(UPPER('DROP')))
AND ( SELECT COUNT(1) AS ct
FROM StagingDB.dbo.Temp_Staging_PKsIndexes_MetaData
WHERE From_MetaData = 1
AND DBName = @Target_DB_Name
AND SchemaName = @Target_DB_Schema_Name
AND ( IsPK IS NULL
OR IsPK = ''
)
AND IndexColNames IS NOT NULL
) > 0
BEGIN
IF CURSOR_STATUS('global', 'db_idxcursor') >= -1
BEGIN
DEALLOCATE db_idxcursor;
END;
DECLARE db_idxcursor CURSOR FORWARD_ONLY
FOR
SELECT IndexOrPKName ,
SchemaName ,
TableName ,
ID
FROM Temp_Staging_PKsIndexes_MetaData
WHERE From_MetaData = 1
AND ( IsPK IS NULL
OR IsPK = ''
)
AND IndexColNames IS NOT NULL
AND DBName = @Target_DB_Name
AND SchemaName = @Target_DB_Schema_Name;
SELECT @err = @@error;
IF @err <> 0
BEGIN
DEALLOCATE db_idxcursor;
RETURN @err;
END;
OPEN db_idxcursor;
SELECT @err = @@error;
IF @err <> 0
BEGIN
DEALLOCATE db_idxcursor;
RETURN @err;
END;
FETCH NEXT FROM db_idxcursor INTO @Index_Or_PKName,
@Target_DB_Schema_Name, @Tgt_Object_Name, @ID;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @SQL = N'DROP INDEX ' + @Index_Or_PKName + ''
+ CHAR(10);
SET @SQL = @SQL + 'ON ' + @Target_DB_Schema_Name
+ '.[' + @Tgt_Object_Name + '];';
IF @Is_Debug_Mode = 1
BEGIN
PRINT @SQL;
END;
BEGIN TRY
BEGIN TRANSACTION;
EXEC (@SQL);
COMMIT TRANSACTION;
SET @Is_All_OK = 1;
SET @Error_Message = 'All Good!';
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION;
SET @Is_All_OK = 0;
SET @Error_Message = 'This operation has been unexpectandly terminated due to error: '''
+ ERROR_MESSAGE() + ''' at line '
+ CAST(ERROR_LINE() AS VARCHAR);
THROW;
END CATCH;
FETCH NEXT FROM db_idxcursor INTO @Index_Or_PKName,
@Target_DB_Schema_Name, @Tgt_Object_Name, @ID;
END;
CLOSE db_idxcursor;
DEALLOCATE db_idxcursor;
END;
IF @Create_Drop_Idxs = LTRIM(RTRIM(UPPER('DROP')))
AND ( SELECT COUNT(1) AS ct
FROM StagingDB.dbo.Temp_Staging_PKsIndexes_MetaData
WHERE From_MetaData = 1
AND ( IsPK IS NULL
OR IsPK = ''
)
AND IndexColNames IS NOT NULL
AND DBName = @Target_DB_Name
AND SchemaName = @Target_DB_Schema_Name
) = 0
BEGIN
SET @Is_All_OK = 1;
SET @Error_Message = 'All Good! No indexes (outside of Primary Keys) have been found on participating tables '
+ CHAR(10);
SET @Error_Message = @Error_Message
+ 'therefore tables have not been altered by the cursor.';
END;
IF @Create_Drop_Idxs = LTRIM(RTRIM(UPPER('CREATE')))
AND EXISTS ( SELECT TOP 1
*
FROM ( SELECT [DBName] ,
[SchemaName] ,
[TableName] ,
[IndexOrPKName]
FROM StagingDB.dbo.Temp_Staging_PKsIndexes_MetaData
WHERE From_MetaData = 0
AND ( IsPK IS NULL
OR IsPK = ''
)
AND IndexColNames IS NOT NULL
AND DBName = @Target_DB_Name
AND SchemaName = @Target_DB_Schema_Name
EXCEPT
SELECT [DBName] ,
[SchemaName] ,
[TableName] ,
[IndexOrPKName]
FROM StagingDB.dbo.Temp_Staging_PKsIndexes_MetaData
WHERE From_MetaData = 1
AND ( IsPK IS NULL
OR IsPK = ''
)
AND IndexColNames IS NOT NULL
AND DBName = @Target_DB_Name
AND SchemaName = @Target_DB_Schema_Name
) a
JOIN ( SELECT t.name AS TblName
FROM sys.tables t
JOIN sys.schemas s ON t.schema_id = s.schema_id
WHERE s.name = @Target_DB_Schema_Name
AND t.name NOT LIKE 'Temp%'
) b ON a.TableName = b.TblName )
BEGIN
IF CURSOR_STATUS('global', 'db_fkcursor') >= -1
BEGIN
DEALLOCATE db_idxcursor;
END;
DECLARE db_idxcursor CURSOR FORWARD_ONLY
FOR
SELECT DISTINCT
a.[ID] ,
a.[DBName] ,
a.[SchemaName] ,
a.[TableName] ,
a.[IndexOrPKName] ,
a.[indexType] ,
a.[IndexColNames] ,
a.[PkColNames] ,
a.[Indx_Options] ,
a.[IsUnique]
FROM StagingDB.dbo.Temp_Staging_PKsIndexes_MetaData a
INNER JOIN ( SELECT a.*
FROM ( SELECT [DBName] ,
[SchemaName] ,
[TableName] ,
[IndexOrPKName]
FROM StagingDB.dbo.Temp_Staging_PKsIndexes_MetaData
WHERE From_MetaData = 0
AND ( IsPK IS NULL
OR IsPK = ''
)
AND IndexColNames IS NOT NULL
AND DBName = @Target_DB_Name
AND SchemaName = @Target_DB_Schema_Name
EXCEPT
SELECT [DBName] ,
[SchemaName] ,
[TableName] ,
[IndexOrPKName]
FROM StagingDB.dbo.Temp_Staging_PKsIndexes_MetaData
WHERE From_MetaData = 1
AND ( IsPK IS NULL
OR IsPK = ''
)
AND IndexColNames IS NOT NULL
AND DBName = @Target_DB_Name
AND SchemaName = @Target_DB_Schema_Name
) a
JOIN ( SELECT t.name AS TblName
FROM sys.tables t
JOIN sys.schemas s ON t.schema_id = s.schema_id
WHERE s.name = @Target_DB_Schema_Name
) b ON a.TableName = b.TblName
) d ON d.[TableName] = a.[TableName]
AND d.[IndexOrPKName] = a.[IndexOrPKName]
AND d.[SchemaName] = a.[SchemaName]
AND d.DBName = a.DBName;
SELECT @err = @@error;
IF @err <> 0
BEGIN
DEALLOCATE db_idxcursor;
RETURN @err;
END;
OPEN db_idxcursor;
SELECT @err = @@error;
IF @err <> 0
BEGIN
DEALLOCATE db_idxcursor;
RETURN @err;
END;
FETCH NEXT
FROM db_idxcursor
INTO @ID, @Target_DB_Name, @Target_DB_Schema_Name,
@Tgt_Object_Name, @Index_Or_PKName, @Index_Type,
@Index_ColNames, @PkColNames, @Indx_Options, @Is_Unique;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @SQL = 'CREATE ' + @Index_Type + ' INDEX '
+ @Index_Or_PKName + ' ON [' + @Target_DB_Name
+ '].[' + @Target_DB_Schema_Name + '].['
+ @Tgt_Object_Name + ']' + CHAR(10);
SET @SQL = @SQL
+ CASE WHEN @Index_Type = 'CLUSTERED'
THEN ' (' + @PkColNames + ')'
WHEN @Index_Type = 'CLUSTERED COLUMNSTORE'
THEN ''
ELSE ' (' + @Index_ColNames + ')'
END + CHAR(10);
SET @SQL = @SQL + '' + @Indx_Options + '' + CHAR(10);
BEGIN TRY
IF @Is_Debug_Mode = 1
BEGIN
PRINT @SQL;
END;
BEGIN TRANSACTION;
EXEC (@SQL);
COMMIT TRANSACTION;
SET @Is_All_OK = 1;
SET @Error_Message = 'All Good!';
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION;
SET @Is_All_OK = 0;
SET @Error_Message = 'This operation has been unexpectandly terminated due to error: '''
+ ERROR_MESSAGE() + ''' at line '
+ CAST(ERROR_LINE() AS VARCHAR);
--THROW;
END CATCH;
FETCH NEXT FROM db_idxcursor
INTO @ID, @Target_DB_Name, @Target_DB_Schema_Name,
@Tgt_Object_Name, @Index_Or_PKName, @Index_Type,
@Index_ColNames, @PkColNames, @Indx_Options,
@Is_Unique;
END;
CLOSE db_idxcursor;
DEALLOCATE db_idxcursor;
--END
END;
IF @Create_Drop_Idxs = LTRIM(RTRIM(UPPER('CREATE')))
AND NOT EXISTS ( SELECT TOP 1
*
FROM ( SELECT [DBName] ,
[SchemaName] ,
[TableName] ,
[IndexOrPKName]
FROM StagingDB.dbo.Temp_Staging_PKsIndexes_MetaData
WHERE From_MetaData = 0
AND ( IsPK IS NULL
OR IsPK = ''
)
AND IndexColNames IS NOT NULL
AND DBName = @Target_DB_Name
AND SchemaName = @Target_DB_Schema_Name
EXCEPT
SELECT [DBName] ,
[SchemaName] ,
[TableName] ,
[IndexOrPKName]
FROM StagingDB.dbo.Temp_Staging_PKsIndexes_MetaData
WHERE From_MetaData = 1
AND ( IsPK IS NULL
OR IsPK = ''
)
AND IndexColNames IS NOT NULL
AND DBName = @Target_DB_Name
AND SchemaName = @Target_DB_Schema_Name
) a
JOIN ( SELECT t.name AS TblName
FROM sys.tables t
JOIN sys.schemas s ON t.schema_id = s.schema_id
WHERE s.name = @Target_DB_Schema_Name
AND t.name NOT LIKE 'Temp%'
) b ON a.TableName = b.TblName )
BEGIN
SET @Is_All_OK = 1;
SET @Error_Message = 'All Good! All indexes have already been created on the referenced tables.';
END;
IF @Reorg_PKs = LTRIM(RTRIM(UPPER('YES')))
AND EXISTS ( SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_NAME = 'Temp_Staging_PKsIndexes_MetaData'
AND TABLE_SCHEMA = 'dbo' )
BEGIN
BEGIN
IF CURSOR_STATUS('global', 'db_pkreorgcursor') >= -1
BEGIN
DEALLOCATE db_pkreorgcursor;
END;
DECLARE db_pkreorgcursor CURSOR FORWARD_ONLY
FOR
SELECT DISTINCT
temp.ID ,
temp.DBName ,
temp.SchemaName ,
temp.TableName ,
i.name AS IndexName
FROM sys.indexes AS i
JOIN sys.index_columns AS ic ON i.object_id = ic.object_id
AND i.index_id = ic.index_id
JOIN StagingDB.dbo.Temp_Staging_PKsIndexes_MetaData temp ON temp.IndexOrPKName = i.name
JOIN INFORMATION_SCHEMA.TABLES t ON t.TABLE_SCHEMA = temp.SchemaName
AND t.TABLE_NAME = temp.TableName
AND t.TABLE_CATALOG = temp.DBName
WHERE i.is_primary_key = 1
AND temp.From_MetaData = 1
AND temp.SchemaName = @Target_DB_Schema_Name
AND temp.DBName = @Target_DB_Name;
SELECT @err = @@error;
IF @err <> 0
BEGIN
DEALLOCATE db_pkreorgcursor;
RETURN @err;
END;
OPEN db_pkreorgcursor;
SELECT @err = @@error;
IF @err <> 0
BEGIN
DEALLOCATE db_pkreorgcursor;
RETURN @err;
END;
FETCH NEXT
FROM db_pkreorgcursor INTO @ID, @Target_DB_Name,
@Target_DB_Schema_Name, @Tgt_Object_Name,
@Index_Or_PKName;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @SQL = N'ALTER INDEX [' + @Index_Or_PKName
+ ']' + CHAR(10);
SET @SQL = @SQL + 'ON [' + @Target_DB_Name
+ '].[' + @Target_DB_Schema_Name + '].['
+ @Tgt_Object_Name + '] ';
SET @SQL = @SQL
+ 'REBUILD PARTITION = ALL WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON);';
BEGIN TRY
IF @Is_Debug_Mode = 1
BEGIN
PRINT @SQL;
END;
BEGIN TRANSACTION;
EXEC (@SQL);
COMMIT TRANSACTION;
SET @Is_All_OK = 1;
SET @Error_Message = 'All Good!';
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION;
SET @Is_All_OK = 0;
SET @Error_Message = 'This operation has been unexpectandly terminated due to error: '''
+ ERROR_MESSAGE() + ''' at line '
+ CAST(ERROR_LINE() AS VARCHAR);
END CATCH;
FETCH NEXT FROM db_pkreorgcursor INTO @ID,
@Target_DB_Name, @Target_DB_Schema_Name,
@Tgt_Object_Name, @Index_Or_PKName;
END;
CLOSE db_pkreorgcursor;
DEALLOCATE db_pkreorgcursor;
END;
END;
IF @Drop_TempTbls = LTRIM(RTRIM(UPPER('YES')))
BEGIN
IF EXISTS ( SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_NAME = 'Temp_Staging_PKsIndexes_MetaData'
AND TABLE_SCHEMA = 'dbo' )
BEGIN
DROP TABLE StagingDB.dbo.Temp_Staging_PKsIndexes_MetaData;
END;
END;
END;
GO
Large Tables Acquisition Tasks Overview and Code
Most environments can be characterised as having a mixture of large and small tables. Even though a single approach can be employed, sometimes a two-pronged approach can be more beneficial i.e. break up the source schema into groups of small and large tables and handle those two by two separate processes, in this case two distinct stored procedures.
In case of large tables, with at least hundreds of thousands of records, we can take advantage of a parallel load, spinning up multiple SQL Server Agent jobs responsible for simultaneous reads and inserts. I have written a blog post about this approach previously HERE. In case of smaller tables e.g. hundreds to few thousands records, an automated row-for-row MERGE may be a better solution. Let’s explore those two eventualities in more detail.
When synchronising larger tables, reading and inserting data in a sequential order is a rather slow process. Breaking it up into multiple parallel batches, in my experience increases the speed considerably and unless we have an option to drop the target table and use SELECT…INTO SQL Server 2014 or higher functionality, which executes it in parallel mode by default, spooling up multiple SQL Server Agent jobs may be a good alternative. The code below creates a ‘master’ and ‘slave’ stored procedures which achieve just that. The ‘master’ version queries the source data metadata, looking for the primary key column, using a simple algorithm subdivides or partitions the primary key field into a number of ranges and finally assigns each range into its own SQL Server Agent job, which in turn executes the ‘slave’ stored procedure. The number of ranges is controlled by the variable assigned from the package directly and the whole process is monitored to ensure that if the job does not finish within an allocated time, it is terminated. The second ‘slave’ stored procedure reconciles any reserved words that may exist across the schemas and further breaks up the batches into smaller, more manageable INSERT statements.
Looking at the ‘master’ stored procedure, you may notice a few interesting things about it. Firstly, it uses ControlDB tables to validate which objects are to be queried and replicated across the source and target database instances. This allows for easy access and control of any tables we may wish to exclude from the job, without having to hardcode their names directly into the procedure itself. Secondly, it uses as simple algorithm which subdivides the primary key field into smaller, manageable ‘buckets‘ of data, each handled by its own SQL Agent process. This allows for much faster source reads and target writes and an additional level of customisation since the number of SQL Agent jobs is driven by the variable value. Another interesting feature is the provision of a simple termination endpoint for the jobs which were supposed to be executed a predefined number of times but for some reason failed to transfer the data and went beyond the threshold allocated. This is achieved by querying ‘sysjobs_view’ and ‘sysjobactivity’ system objects every 10 seconds to validate execution status. In the event the jobs are still active and the iteration number has been exceeded, the jobs are terminated using ‘sp_stop_jobs’ system stored procedure. Finally, I added an error capturing code to allow execution issues to be logged in the AdminDBA database (see Part 1 or a full write-up HERE) and reference to the view storing MySQL reserved words to reconcile any naming conventions incompatibility (‘slave’ stored procedure). This makes meaningful notifications possible and allows for any naming inconstancies across the two vendors to be rectified at runtime.
The code for creating ‘master’ and ‘slave’ stored procedures, responsible for loading larger tables, is as per below.
/*=========================================================================
Create 'MASTER' usp_runRemoteSvrDBSchemaSyncBigTablesMaster stored
procedure used to truncate and re-populate 'large' target staging tables.
=========================================================================*/
USE StagingDB
GO
CREATE PROCEDURE [dbo].[usp_runRemoteSvrDBSchemaSyncBigTablesMaster]
(@Remote_Server_Name SYSNAME ,
@Remote_Server_DB_Name VARCHAR (128) ,
@Remote_Server_DB_Schema_Name VARCHAR (128) ,
@Target_DB_Name VARCHAR (128) ,
@Target_DB_Schema_Name VARCHAR (128) ,
@Target_DB_Object_Name VARCHAR (256) ,
@Exec_Instance_GUID UNIQUEIDENTIFIER ,
@Package_Name VARCHAR (256) ,
@Proc_Name VARCHAR (256) ,
@Proc_Exec_No VARCHAR (10) ,
@Iterations_No VARCHAR (10))
AS
BEGIN
SET NOCOUNT ON
DECLARE @SQL NVARCHAR(MAX)
DECLARE @Error_Message VARCHAR (4000)
DECLARE @PK_Col_Name VARCHAR (256)
DECLARE @Is_Debug_Mode INT = 1
DECLARE @Check_Count TINYINT = 1
DECLARE @Max_Check_Count TINYINT = 250
DECLARE @Remote_DB_Object_Name VARCHAR (128) = @Target_DB_Object_Name
IF OBJECT_ID('tempdb..#Objects_List') IS NOT NULL
BEGIN
DROP TABLE [#Objects_List]
END
CREATE TABLE #Objects_List
(
DatabaseName sysname ,
SchemaName sysname ,
ObjectName sysname ,
Is_Source_Target VARCHAR (56)
)
SET @SQL = 'SELECT table_catalog, table_schema, table_name, ''Target'' as Is_Source_Target
FROM INFORMATION_SCHEMA.tables
WHERE table_type = ''base table''
and table_catalog = '''+@Target_DB_Name+'''
and table_schema = '''+@Target_DB_Schema_Name+'''
and table_name = '''+@Target_DB_Object_Name+''''
INSERT INTO #Objects_List (DatabaseName, SchemaName, ObjectName, Is_Source_Target)
EXEC (@SQL)
IF @Is_Debug_Mode = 0
BEGIN
PRINT 'SQL statement for acquiring ''target'' table metadata into #Objects_List temp table:'
PRINT '------------------------------------------------------------------------------------'
PRINT @SQL +REPLICATE(CHAR(13),2)
SELECT * FROM #Objects_List
END
SET @SQL = 'INSERT INTO #Objects_List (DatabaseName, SchemaName, ObjectName, Is_Source_Target)
SELECT table_schema, table_schema, table_name, ''Source'' as Is_Source_Target
FROM OPENQUERY ('+@Remote_Server_Name+', ''select table_schema as DatabaseName, table_schema as SchemaName, table_schema, table_name
from information_schema.tables
WHERE table_type = ''''base table''''
and table_name = '''''+@Remote_DB_Object_Name+'''''
and table_schema ='''''+@Remote_Server_DB_Name+''''''')'
INSERT INTO #Objects_List (DatabaseName, SchemaName, ObjectName, Is_Source_Target)
EXEC (@SQL)
IF @Is_Debug_Mode = 1
BEGIN
PRINT 'SQL statement for acquiring ''source'' table metadata into #Objects_List temp table:'
PRINT '------------------------------------------------------------------------------------'
PRINT @SQL +REPLICATE(CHAR(13),2)
SELECT * FROM #Objects_List WHERE Is_Source_Target = 'Source'
END
IF @Is_Debug_Mode = 1
BEGIN
SELECT Source_Server_Name = @Remote_Server_Name,
Source_Server_DB_Name = @Remote_Server_DB_Name,
Source_Object_Name = @Remote_DB_Object_Name,
Target_DB_Name = @Target_DB_Name,
Target_DB_Schema_Name = @Target_DB_Schema_Name,
Target_DB_Object_Name = @Target_DB_Object_Name
END
IF NOT EXISTS ( SELECT TOP 1 1
FROM #Objects_List a
WHERE a.DatabaseName = @Remote_Server_DB_Name AND a.Is_Source_Target = 'Source' )
BEGIN
SET @Error_Message = 'Source database cannot be found. You nominated "'
+ @Remote_Server_DB_Name + '".
Check that the database of that name exists on the instance'
RAISERROR (
@Error_Message -- Message text.
,16 -- Severity.
,1 -- State.
)
RETURN
END
IF NOT EXISTS ( SELECT 1
FROM #Objects_List a
WHERE a.DatabaseName = @Target_DB_Name AND a.Is_Source_Target = 'Target')
BEGIN
SET @Error_Message = 'Target database cannot be found. You nominated "'
+ @Target_DB_Name + '".
Check that the database of that name exists on the instance'
RAISERROR (
@Error_Message -- Message text.
,16 -- Severity.
,1 -- State.
)
RETURN
END
IF NOT EXISTS ( SELECT TOP 1 1
FROM #Objects_List a
WHERE a.SchemaName = @Remote_Server_DB_Schema_Name AND a.Is_Source_Target = 'Source' )
BEGIN
SET @Error_Message = 'Source schema cannot be found. You nominated "'
+ @Remote_Server_DB_Schema_Name + '".
Check that the schema of that name exists on the database'
RAISERROR (
@Error_Message -- Message text.
,16 -- Severity.
,1 -- State.
)
END
IF NOT EXISTS ( SELECT TOP 1 1
FROM #Objects_List a
WHERE a.SchemaName = @Target_DB_Schema_Name AND a.Is_Source_Target = 'Target' )
BEGIN
SET @Error_Message = 'Target schema cannot be found. You nominated "'
+ @Target_DB_Schema_Name + '".
Check that the schema of that name exists on the database'
RAISERROR (
@Error_Message -- Message text.
,16 -- Severity.
,1 -- State.
)
RETURN
END
IF NOT EXISTS ( SELECT TOP 1 1
FROM #Objects_List a
WHERE a.ObjectName = @Remote_DB_Object_Name AND a.Is_Source_Target = 'Source')
BEGIN
SET @Error_Message = 'Source object cannot be found. You nominated "'
+ @Remote_DB_Object_Name + '".
Check that the object of that name exists on the database'
RAISERROR (
@Error_Message -- Message text.
,16 -- Severity.
,1 -- State.
)
RETURN
END
IF NOT EXISTS ( SELECT 1
FROM #Objects_List a
WHERE a.ObjectName = @Target_DB_Object_Name AND a.Is_Source_Target = 'Target')
BEGIN
SET @Error_Message = 'Target object cannot be found. You nominated "'
+ @Target_DB_Object_Name + '".
Check that the object of that name exists on the database'
RAISERROR (
@Error_Message -- Message text.
,16 -- Severity.
,1 -- State.
)
RETURN
END
IF OBJECT_ID('tempdb..#Temp_Tbl_Metadata') IS NOT NULL
BEGIN
DROP TABLE #Temp_Tbl_Metadata;
END;
CREATE TABLE #Temp_Tbl_Metadata
(
ID SMALLINT IDENTITY(1, 1) ,
Table_Name VARCHAR (256) ,
Column_Name VARCHAR(128) ,
Column_DataType VARCHAR(56) ,
Is_PK_Flag BIT
);
IF OBJECT_ID('tempdb..#Ids_Range') IS NOT NULL
BEGIN
DROP TABLE #Ids_Range;
END;
CREATE TABLE #Ids_Range
(
id SMALLINT IDENTITY(1, 1) ,
range_FROM BIGINT ,
range_TO BIGINT
);
SET @SQL = 'INSERT INTO #Temp_Tbl_Metadata (Table_Name, Column_Name, Column_DataType, Is_PK_Flag)' +CHAR(13)
SET @SQL = @SQL + 'SELECT a.table_name, a.column_name, a.data_type, CASE WHEN a.column_key = ''PRI'' ' +CHAR(13)
SET @SQL = @SQL + 'THEN 1 ELSE 0 END FROM OPENQUERY('+@Remote_Server_Name+', ' +CHAR(13)
SET @SQL = @SQL + '''SELECT table_name, table_schema, column_name, data_type, column_key from information_schema.columns' +CHAR(13)
SET @SQL = @SQL + 'WHERE table_name = '''''+@Target_DB_Object_Name+''''''') a ' +CHAR(13)
SET @SQL = @SQL + 'JOIN ControlDB.dbo.Ctrl_RemoteSvrs_Tables2Process b ' +CHAR(13)
SET @SQL = @SQL + 'ON a.Table_Name = b.Remote_Table_Name and' +CHAR(13)
SET @SQL = @SQL + 'a.Table_Schema = '''+@Remote_Server_DB_Schema_Name+''' and ' +CHAR(13)
SET @SQL = @SQL + 'b.Remote_Schema_Name = '''+@Remote_Server_DB_Schema_Name+''' and ' +CHAR(13)
SET @SQL = @SQL + 'b.Remote_DB_Name = '''+@Remote_Server_DB_Name+''' and' +CHAR(13)
SET @SQL = @SQL + 'b.Remote_Server_Name = '''+@Remote_Server_Name+'''' +CHAR(13)
SET @SQL = @SQL + 'WHERE b.Is_Active = 1' +CHAR(13)
SET @SQL = @SQL + 'AND NOT EXISTS (SELECT 1 ' +CHAR(13)
SET @SQL = @SQL + 'FROM ControlDB.dbo.Ctrl_RemoteSvrs_Tables2Process_ColumnExceptions o' +CHAR(13)
SET @SQL = @SQL + 'WHERE o.Is_Active = 1 AND ' +CHAR(13)
SET @SQL = @SQL + 'o.Remote_Field_Name = a.Column_Name AND ' +CHAR(13)
SET @SQL = @SQL + 'o.Remote_Table_Name = a.Table_Name AND ' +CHAR(13)
SET @SQL = @SQL + 'o.Remote_Schema_Name = '''+@Remote_Server_DB_Schema_Name+''' AND ' +CHAR(13)
SET @SQL = @SQL + 'o.Remote_DB_Name = '''+@Remote_Server_DB_Name+''' AND' +CHAR(13)
SET @SQL = @SQL + 'o.Remote_Server_Name = '''+@Remote_Server_Name+''')' +CHAR(13)
IF @Is_Debug_Mode = 1
BEGIN
PRINT 'SQL statement for populating ''metadata'' #Temp_Tbl_Metadata temp table:'
PRINT '------------------------------------------------------------------------'
PRINT @SQL +REPLICATE(CHAR(13),2)
END
EXEC (@SQL)
IF NOT EXISTS ( SELECT TOP 1 1
FROM #Temp_Tbl_Metadata
WHERE Is_PK_Flag = 1 AND ISNUMERIC(Is_PK_Flag)=1)
BEGIN
SET @Error_Message = 'Primary key column in "Temp_Tbl_Metadata" table not found. Please troubleshoot!'
RAISERROR (
@Error_Message -- Message text
,16 -- Severity
,1 -- State
)
RETURN
END
SET @PK_Col_Name = ( SELECT TOP 1 Column_Name
FROM #Temp_Tbl_Metadata
WHERE Is_PK_Flag = 1
AND Column_DataType IN ('INT', 'SMALLINT', 'BIGINT', 'TINYINT'))
SET @SQL = 'DECLARE @R1 INT = (SELECT id FROM OPENQUERY ('+@Remote_Server_Name+', ' +CHAR(13)
SET @SQL = @SQL + '''SELECT MIN('+@PK_Col_Name+') as id from '+@Target_DB_Object_Name+''')) ' +CHAR(13)
SET @SQL = @SQL + 'DECLARE @R2 BIGINT = (SELECT id FROM OPENQUERY ('+@Remote_Server_Name+', ' +CHAR(13)
SET @SQL = @SQL + '''SELECT (MAX('+@PK_Col_Name+')-MIN('+@PK_Col_Name+')+1)/'+@Proc_Exec_No+' as id FROM' +CHAR(13)
SET @SQL = @SQL + ''+@Target_DB_Object_Name+'''))' +CHAR(13)
SET @SQL = @SQL + 'DECLARE @R3 BIGINT = (SELECT id FROM OPENQUERY ('+@Remote_Server_Name+', ' +CHAR(13)
SET @SQL = @SQL + '''SELECT MAX('+@PK_Col_Name+') as id from '+@Target_DB_Object_Name+''')) ' +CHAR(13)
SET @SQL = @SQL + 'DECLARE @t int = @r2+@r2+2 ' +CHAR(13)
SET @SQL = @SQL + 'INSERT INTO #Ids_Range ' +CHAR(13)
SET @SQL = @SQL + '(range_FROM, range_to) ' +CHAR(13)
SET @SQL = @SQL + 'SELECT @R1, @R2 ' +CHAR(13)
SET @SQL = @SQL + 'UNION ALL ' +CHAR(13)
SET @SQL = @SQL + 'SELECT @R2+1, @R2+@R2+1 ' +CHAR(13)
SET @SQL = @SQL + 'WHILE @t <= @r3 ' +CHAR(13)
SET @SQL = @SQL + 'BEGIN ' +CHAR(13)
SET @SQL = @SQL + 'INSERT INTO #Ids_Range ' +CHAR(13)
SET @SQL = @SQL + '(range_FROM, range_to) ' +CHAR(13)
SET @SQL = @SQL + 'SELECT @t, CASE WHEN (@t+@r2) >= @r3 THEN @r3 ELSE @t+@r2 END ' +CHAR(13)
SET @SQL = @SQL + 'SET @t = @t+@r2+1 ' +CHAR(13)
SET @SQL = @SQL + 'END' +CHAR(13)
IF @Is_Debug_Mode = 1
BEGIN
PRINT 'SQL statement for populating ''range'' variables and #Ids_Range temp table:'
PRINT '---------------------------------------------------------------------------'
PRINT @SQL +REPLICATE(CHAR(13),2)
END
EXEC(@SQL)
IF @Is_Debug_Mode = 1
BEGIN
SELECT * FROM #Ids_Range
END
SET @SQL = 'IF EXISTS (SELECT TOP 1 1 FROM ' +CHAR(13)
SET @SQL = @SQL + ''+@Target_DB_Name+'.'+@Target_DB_Schema_Name+'.'+@Target_DB_Object_Name+'' +CHAR(13)
SET @SQL = @SQL + 'WHERE '+@PK_Col_Name+' IS NOT NULL) BEGIN ' +CHAR(13)
SET @SQL = @SQL + 'TRUNCATE TABLE ' +CHAR(13)
SET @SQL = @SQL + ''+@Target_DB_Name+'.'+@Target_DB_Schema_Name+'.'+@Target_DB_Object_Name+' END' +CHAR(13)
IF @Is_Debug_Mode = 1
BEGIN
PRINT 'SQL statement for truncating '''+@Target_DB_Object_Name+''' table:'
PRINT '------------------------------------------------------------------'
PRINT @SQL +REPLICATE(CHAR(13),2)
END
EXEC(@SQL)
IF OBJECT_ID('tempdb..#Temp_Tbl_AgentJob_Stats') IS NOT NULL
BEGIN
DROP TABLE #Temp_Tbl_AgentJob_Stats;
END;
CREATE TABLE #Temp_Tbl_AgentJob_Stats
(
ID SMALLINT IDENTITY(1, 1) ,
Job_Name VARCHAR(256) ,
Job_Exec_Start_Date DATETIME
);
IF CURSOR_STATUS('global', 'sp_cursor') >= -1
BEGIN
DEALLOCATE sp_cursor
END
DECLARE @z INT
DECLARE @err INT
DECLARE sp_cursor CURSOR
FOR
SELECT id FROM #ids_range
SELECT @err = @@error
IF @err <> 0
BEGIN
DEALLOCATE sp_cursor
RETURN @err
END
OPEN sp_cursor
FETCH NEXT
FROM sp_cursor INTO @z
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE
@range_from VARCHAR(10) = (SELECT CAST(range_FROM AS VARCHAR(10)) FROM #ids_range where id = @z),
@range_to VARCHAR(10) = (SELECT CAST(range_TO AS VARCHAR(10)) FROM #ids_range where id = @z),
@job_name VARCHAR (256) = 'Temp_'+UPPER(LEFT(@Target_DB_Object_Name,1))+LOWER(SUBSTRING(@Target_DB_Object_Name,2,LEN(@Target_DB_Object_Name)))+'_TableSync_'+'AsyncJob'+'_'+CAST(@z AS VARCHAR (20)),
@job_owner VARCHAR (256) = 'sa'
DECLARE
@delete_job_sql VARCHAR (400) = 'EXEC msdb..sp_delete_job @job_name='''''+@job_name+''''''
DECLARE
@sql_job NVARCHAR(MAX) =
'USE [StagingDB]
EXEC [dbo].['+@Proc_Name+']
@Remote_Server_Name = '+@Remote_Server_Name+',
@Remote_Server_DB_Name = '''''+@Remote_Server_DB_Name+''''',
@Remote_Server_DB_Schema_Name = '''''+@Remote_Server_DB_Schema_Name+''''',
@Target_DB_Name = N'''''+@Target_DB_Name+''''',
@Target_DB_Schema_Name = '''''+@Target_DB_Schema_Name+''''',
@Target_DB_Object_Name = '''''+@Target_DB_Object_Name+''''',
@Iterations_No ='''''+@Iterations_No+''''' ,
@Min_Value ='''''+@range_from+''''',
@Max_Value ='''''+@range_to+''''',
@Exec_Instance_GUID ='''''+CAST(@Exec_Instance_GUID AS VARCHAR(128))+''''',
@Package_Name='''''+@Package_Name+''''' '
SET @SQL = 'IF EXISTS'
SET @SQL = @SQL + '(SELECT TOP 1 1 FROM msdb..sysjobs_view job JOIN msdb.dbo.sysjobactivity activity' +CHAR(13)
SET @SQL = @SQL + 'ON job.job_id = activity.job_id WHERE job.name = N'''+@job_name+'''' +CHAR(13)
SET @SQL = @SQL + 'AND activity.start_execution_date IS NOT NULL AND activity.stop_execution_date IS NULL)' +CHAR(13)
SET @SQL = @SQL + 'BEGIN' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_stop_job @job_name=N'''+@job_name+''';' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_delete_job @job_name=N'''+@job_name+''', @delete_unused_schedule=1' +CHAR(13)
SET @SQL = @SQL + 'END' +CHAR(13)
SET @SQL = @SQL + 'IF EXISTS' +CHAR(13)
SET @SQL = @SQL + '(SELECT TOP 1 1 FROM msdb..sysjobs_view job JOIN msdb.dbo.sysjobactivity activity' +CHAR(13)
SET @SQL = @SQL + 'ON job.job_id = activity.job_id WHERE job.name = N'''+@job_name+'''' +CHAR(13)
SET @SQL = @SQL + 'AND activity.start_execution_date IS NULL AND activity.stop_execution_date IS NOT NULL)' +CHAR(13)
SET @SQL = @SQL + 'BEGIN' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_delete_job @job_name=N'''+@job_name+''', @delete_unused_schedule=1' +CHAR(13)
SET @SQL = @SQL + 'END' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_add_job '''+@job_name+''', @owner_login_name= '''+@job_owner+''';' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_add_jobserver @job_name= '''+@job_name+''';' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_add_jobstep @job_name='''+@job_name+''', @step_name= ''Step1'', ' +CHAR(13)
SET @SQL = @SQL + '@command = '''+@sql_job+''', @database_name = '''+@Target_DB_Name+''', @on_success_action = 3;' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_add_jobstep @job_name = '''+@job_name+''', @step_name= ''Step2'',' +CHAR(13)
SET @SQL = @SQL + '@command = '''+@delete_job_sql+'''' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_start_job @job_name= '''+@job_name+'''' +CHAR(13)
+REPLICATE(CHAR(13),4)
EXEC (@SQL)
WAITFOR DELAY '00:00:01'
INSERT INTO #Temp_Tbl_AgentJob_Stats
(Job_Name, Job_Exec_Start_Date)
SELECT job.Name, activity.start_execution_date
FROM msdb.dbo.sysjobs_view job
INNER JOIN msdb.dbo.sysjobactivity activity
ON job.job_id = activity.job_id
WHERE job.name = @job_name
IF @Is_Debug_Mode = 1
BEGIN
PRINT 'SQL Server agent job execution and deletion SQL statement for job '''+@job_name+''':'
PRINT '------------------------------------------------------------------------------------------------------'
PRINT @SQL +REPLICATE(CHAR(13),2)
END
FETCH NEXT
FROM sp_cursor INTO @z
END
CLOSE sp_cursor
DEALLOCATE sp_cursor
IF @Is_Debug_Mode = 1
BEGIN
SELECT * FROM #Temp_Tbl_AgentJob_Stats
END
IF @Is_Debug_Mode = 1
BEGIN
PRINT 'Iterating through agent job(s) execution status for '''+@Target_DB_Object_Name+''' table:'
PRINT '----------------------------------------------------------------------------------------' +REPLICATE(CHAR(13),2)
END
Start:
IF EXISTS ( SELECT TOP 1 1
FROM msdb.dbo.sysjobs_view job
JOIN msdb.dbo.sysjobactivity activity
ON job.job_id = activity.job_id
JOIN #Temp_Tbl_AgentJob_Stats agent
ON agent.Job_Name = job.name)
AND @Check_Count <= @Max_Check_Count
BEGIN
IF @Is_Debug_Mode = 1
BEGIN
SELECT agent.id, job.*
FROM msdb.dbo.sysjobs_view job
JOIN msdb.dbo.sysjobactivity activity
ON job.job_id = activity.job_id
JOIN #Temp_Tbl_AgentJob_Stats agent
ON agent.Job_Name = job.name
ORDER BY agent.id ASC
DECLARE @Running_Jobs VARCHAR(2000) = NULL
SELECT @Running_Jobs = COALESCE(@Running_Jobs + CHAR(13), '') + CAST(id AS VARCHAR) +') ' + job_name
FROM
(SELECT agent.id, agent.Job_Name
FROM msdb.dbo.sysjobs_view job
JOIN msdb.dbo.sysjobactivity activity
ON job.job_id = activity.job_id
JOIN #Temp_Tbl_AgentJob_Stats agent
ON agent.Job_Name = job.name) a
ORDER BY a.id
PRINT '--> Status:'
PRINT 'Iteration number: '+CAST(@Check_Count AS VARCHAR(10))+' out of '+CAST(@Max_Check_Count AS VARCHAR(10))+''
PRINT 'Remaining jobs currently executing are:'
PRINT ''+@Running_Jobs+'' +CHAR(13)
PRINT 'Waiting for 10 seconds before next attempt...' +REPLICATE(CHAR(13),2)
END
SET @Check_Count = @Check_Count + 1;
WAITFOR DELAY '00:00:10';
GOTO Start
END
IF EXISTS ( SELECT TOP 1 1
FROM msdb.dbo.sysjobs_view job
JOIN msdb.dbo.sysjobactivity activity
ON job.job_id = activity.job_id
JOIN #Temp_Tbl_AgentJob_Stats agent
ON agent.Job_Name = job.name)
AND @Check_Count > @Max_Check_Count
BEGIN
DECLARE @i TINYINT
DECLARE @Failed_Job VARCHAR (256)
IF CURSOR_STATUS('global', 'sp_killjob') >= -1
BEGIN
DEALLOCATE sp_killjob
END
DECLARE sp_killjob CURSOR LOCAL FORWARD_ONLY
FOR
SELECT agent.ID, agent.Job_Name
FROM msdb.dbo.sysjobs_view job
JOIN msdb.dbo.sysjobactivity activity
ON job.job_id = activity.job_id
JOIN #Temp_Tbl_AgentJob_Stats agent
ON agent.Job_Name = job.name
OPEN sp_killjob
FETCH NEXT
FROM sp_killjob INTO @i, @Failed_Job
WHILE @@FETCH_STATUS = 0
BEGIN
SET @SQL = 'EXEC msdb..sp_stop_job @job_name=N'''+@Failed_Job+''''
SET @SQL = @SQL + 'EXEC msdb..sp_delete_job @job_name=N'''+@Failed_Job+''', '
SET @SQL = @SQL + '@delete_unused_schedule=1'
IF @Is_Debug_Mode = 1
BEGIN
PRINT 'Error encountered! Stoping and deleting failed job '''+@Failed_Job+''''
END
EXEC (@SQL)
FETCH NEXT FROM sp_killjob INTO @i, @Failed_Job
END
CLOSE sp_killjob
DEALLOCATE sp_killjob
END
IF OBJECT_ID('tempdb..#Objects_List') IS NOT NULL
BEGIN
DROP TABLE [#Objects_List]
END
IF OBJECT_ID('tempdb..#Temp_Tbl_Metadata') IS NOT NULL
BEGIN
DROP TABLE #Temp_Tbl_Metadata;
END;
IF OBJECT_ID('tempdb..#Ids_Range') IS NOT NULL
BEGIN
DROP TABLE #Ids_Range;
END;
END
GO
/*=========================================================================
Create 'SLAVE' usp_runRemoteSvrDBSchemaSyncBigTablesSlave stored
procedure used to re-populate 'small' target staging tables via
a dynamic MERGE SQL functionality.
=========================================================================*/
USE [StagingDB]
GO
CREATE PROCEDURE [dbo].[usp_runRemoteSvrDBSchemaSyncBigTablesSlave]
(@Remote_Server_Name SYSNAME ,
@Remote_Server_DB_Name VARCHAR (128) ,
@Remote_Server_DB_Schema_Name VARCHAR (128) ,
@Target_DB_Name VARCHAR (128) ,
@Target_DB_Schema_Name VARCHAR (128) ,
@Target_DB_Object_Name VARCHAR (256) ,
@Iterations_No VARCHAR (10) ,
@Min_Value VARCHAR (20) ,
@Max_Value VARCHAR (20) ,
@Exec_Instance_GUID VARCHAR (128) ,
@Package_Name VARCHAR (256))
AS
BEGIN
SET NOCOUNT ON
DECLARE @SQL NVARCHAR(MAX)
DECLARE @Err_Msg VARCHAR (4000)
DECLARE @PK_Col_Name VARCHAR (256)
DECLARE @Remote_DB_Object_Name VARCHAR (128) = @Target_DB_Object_Name
DECLARE @Is_Debug_Mode BIT = 1
SET @Exec_Instance_GUID = REPLACE(@Exec_Instance_GUID, '-', '')
IF OBJECT_ID('tempdb..#Temp_Tbl_Metadata') IS NOT NULL
BEGIN
DROP TABLE #Temp_Tbl_Metadata;
END;
CREATE TABLE #Temp_Tbl_Metadata
(
ID SMALLINT IDENTITY(1, 1) ,
Table_Name VARCHAR (128) ,
Column_Name VARCHAR(128) ,
Column_DataType VARCHAR(56) ,
Is_PK_Flag BIT
);
SET @SQL = 'INSERT INTO #Temp_Tbl_Metadata (Table_Name, Column_Name, Column_DataType, Is_PK_Flag)' +CHAR(13)
SET @SQL = @SQL + 'SELECT a.table_name, a.column_name, a.data_type, CASE WHEN a.column_key = ''PRI'' ' +CHAR(13)
SET @SQL = @SQL + 'THEN 1 ELSE 0 END FROM OPENQUERY('+@Remote_Server_Name+', ' +CHAR(13)
SET @SQL = @SQL + '''SELECT table_name, table_schema, column_name, data_type, column_key from information_schema.columns' +CHAR(13)
SET @SQL = @SQL + 'WHERE table_name = '''''+@Target_DB_Object_Name+''''''') a ' +CHAR(13)
SET @SQL = @SQL + 'JOIN ControlDB.dbo.Ctrl_RemoteSvrs_Tables2Process b ' +CHAR(13)
SET @SQL = @SQL + 'ON a.Table_Name = b.Remote_Table_Name and' +CHAR(13)
SET @SQL = @SQL + 'a.Table_Schema = '''+@Remote_Server_DB_Schema_Name+''' and ' +CHAR(13)
SET @SQL = @SQL + 'b.Remote_Schema_Name = '''+@Remote_Server_DB_Schema_Name+''' and ' +CHAR(13)
SET @SQL = @SQL + 'b.Remote_DB_Name = '''+@Remote_Server_DB_Name+''' and' +CHAR(13)
SET @SQL = @SQL + 'b.Remote_Server_Name = '''+@Remote_Server_Name+'''' +CHAR(13)
SET @SQL = @SQL + 'WHERE b.Is_Active = 1' +CHAR(13)
SET @SQL = @SQL + 'AND NOT EXISTS (SELECT 1 ' +CHAR(13)
SET @SQL = @SQL + 'FROM ControlDB.dbo.Ctrl_RemoteSvrs_Tables2Process_ColumnExceptions o' +CHAR(13)
SET @SQL = @SQL + 'WHERE o.Is_Active = 1 AND ' +CHAR(13)
SET @SQL = @SQL + 'o.Remote_Field_Name = a.Column_Name AND ' +CHAR(13)
SET @SQL = @SQL + 'o.Remote_Table_Name = a.Table_Name AND ' +CHAR(13)
SET @SQL = @SQL + 'o.Remote_Schema_Name = '''+@Remote_Server_DB_Schema_Name+''' AND ' +CHAR(13)
SET @SQL = @SQL + 'o.Remote_DB_Name = '''+@Remote_Server_DB_Name+''' AND' +CHAR(13)
SET @SQL = @SQL + 'o.Remote_Server_Name = '''+@Remote_Server_Name+''')' +CHAR(13)
IF @Is_Debug_Mode = 1
BEGIN
PRINT 'SQL statement for populating ''Temp_Tbl_Metadata'' temp table:'
PRINT '---------------------------------------------------------------------------'
PRINT @SQL +REPLICATE(CHAR(13),2)
END
EXEC (@SQL)
IF @Is_Debug_Mode = 1
BEGIN
SELECT * FROM #Temp_Tbl_Metadata
END
IF NOT EXISTS ( SELECT TOP 1 1
FROM #Temp_Tbl_Metadata
WHERE Is_PK_Flag = 1 AND ISNUMERIC(Is_PK_Flag)=1)
BEGIN
SET @Err_Msg = 'Primary key column "Temp_Tbl_Metadata" table not found. Please troubleshoot!'
RAISERROR (
@Err_Msg -- Message text
,16 -- Severity
,1 -- State
)
RETURN
END
IF OBJECT_ID('tempdb..#Ids_Range') IS NOT NULL
BEGIN
DROP TABLE #Ids_Range;
END;
CREATE TABLE #Ids_Range
(
id SMALLINT IDENTITY(1, 1) ,
range_FROM BIGINT ,
range_TO BIGINT
);
SET @PK_Col_Name = ( SELECT TOP 1 Column_Name
FROM #Temp_Tbl_Metadata
WHERE Is_PK_Flag = 1
AND Column_DataType IN ('INT', 'SMALLINT', 'TINYINT', 'BIGINT'))
SET @SQL = 'DECLARE @R1 BIGINT = (SELECT id FROM OPENQUERY ('+@Remote_Server_Name+', ' +CHAR(13)
SET @SQL = @SQL + '''SELECT MIN('+@PK_Col_Name+') as id from '+@Target_DB_Object_Name+'' +CHAR(13)
SET @SQL = @SQL + ' WHERE '+@PK_Col_Name+' >= '+@Min_Value+' AND '+@PK_Col_Name+' <= '+@Max_Value+' ''))' +CHAR(13)
SET @SQL = @SQL + 'DECLARE @R2 BIGINT = (SELECT id FROM OPENQUERY ('+@Remote_Server_Name+', ' +CHAR(13)
SET @SQL = @SQL + '''SELECT (MAX('+@PK_Col_Name+')-MIN('+@PK_Col_Name+')+1)/'+@Iterations_No+' as id FROM' +CHAR(13)
SET @SQL = @SQL + ''+@Target_DB_Object_Name+'' +CHAR(13)
SET @SQL = @SQL + ' WHERE '+@PK_Col_Name+' >= '+@Min_Value+' AND '+@PK_Col_Name+' <= '+@Max_Value+' ''))' +CHAR(13)
SET @SQL = @SQL + 'DECLARE @R3 BIGINT = (SELECT id FROM OPENQUERY ('+@Remote_Server_Name+', ' +CHAR(13)
SET @SQL = @SQL + '''SELECT MAX('+@PK_Col_Name+') as id from '+@Target_DB_Object_Name+'' +CHAR(13)
SET @SQL = @SQL + ' WHERE '+@PK_Col_Name+' >= '+@Min_Value+' AND '+@PK_Col_Name+' <= '+@Max_Value+' ''))' +CHAR(13)
SET @SQL = @SQL + 'DECLARE @t int = @R1+@R2+1
INSERT INTO #Ids_Range
(range_FROM, range_to)
SELECT @R1, @R1+@R2
WHILE @t < @r3
BEGIN
INSERT INTO #Ids_Range
(range_FROM, range_to)
SELECT @t, CASE WHEN (@t+@r2)>@r3 THEN @r3 ELSE @t+@r2 END
SET @t = @t+@r2+1
END'
IF @Is_Debug_Mode = 1
BEGIN
PRINT 'SQL statement for populating ''Ids_Range'' temp table:'
PRINT '---------------------------------------------------------------------------'
PRINT @SQL+REPLICATE(CHAR(13),2)
END
EXEC (@SQL)
IF @Is_Debug_Mode = 1
BEGIN
SELECT * FROM #Ids_Range
END
DECLARE @col_list_MSSQL VARCHAR(1000) = (
SELECT
DISTINCT
STUFF((
SELECT ',' +CHAR(10) + COALESCE(vw.mssql_version, u.column_name)
FROM #Temp_Tbl_Metadata u
LEFT JOIN StagingDB.dbo.vw_MssqlReservedWords vw
ON LTRIM(RTRIM(UPPER(u.Column_Name))) = vw.reserved_word
WHERE u.column_name = column_name
ORDER BY u.column_name
FOR XML PATH('')
),1,1,'') AS columns_list
FROM #Temp_Tbl_Metadata
GROUP BY column_name)
DECLARE @col_list_MYSQL VARCHAR(1000) = (
SELECT
DISTINCT
STUFF((
SELECT ',' +CHAR(10) + COALESCE(vw.mysql_version, u.column_name)
FROM #Temp_Tbl_Metadata u
LEFT JOIN StagingDB.dbo.vw_MysqlReservedWords vw
ON LTRIM(RTRIM(UPPER(u.Column_Name))) = vw.reserved_word
WHERE u.column_name = column_name
ORDER BY u.column_name
FOR XML PATH('')
),1,1,'') AS columns_list
FROM #Temp_Tbl_Metadata
GROUP BY column_name)
IF CURSOR_STATUS('global', 'db_cursor') >= -1
BEGIN
DEALLOCATE db_cursor
END
DECLARE @z INT
DECLARE @err INT
DECLARE db_cursor CURSOR LOCAL FORWARD_ONLY
FOR
SELECT id FROM #ids_range
SELECT @err = @@error
IF @err <> 0
BEGIN
DEALLOCATE db_cursor
RETURN @err
END
OPEN db_cursor
FETCH NEXT
FROM db_cursor INTO @z
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
BEGIN TRANSACTION
DECLARE
@range_from BIGINT = (SELECT range_FROM FROM #Ids_Range where id = @z),
@range_to BIGINT = (SELECT range_TO FROM #Ids_Range where id = @z)
SET @SQL = 'INSERT INTO '+@Target_DB_Name+'.'+@Target_DB_Schema_Name+'.'+@Target_DB_Object_Name+'' +CHAR(13)
SET @SQL = @SQL + ' ('+@col_list_MSSQL+')' +CHAR(13)
SET @SQL = @SQL + 'SELECT '+@col_list_MSSQL+'' +CHAR(13)
SET @SQL = @SQL + 'FROM OPENQUERY ('+@Remote_Server_Name+', ' +CHAR(13)
SET @SQL = @SQL + '''SELECT '+@col_list_MYSQL+'' +CHAR(13)
SET @SQL = @SQL + 'FROM '+@Target_DB_Object_Name+'' +CHAR(13)
SET @SQL = @SQL + 'WHERE '+@PK_Col_Name+' >= '+cast(@range_FROM as varchar (20))+'' +CHAR(13)
SET @SQL = @SQL + 'AND '+@PK_Col_Name+' <= '+CAST(@range_to AS VARCHAR(20))+''')' +CHAR(13)
IF @Is_Debug_Mode = 1
BEGIN
PRINT 'SQL statement for populating target table '+@Target_DB_Schema_Name+'.'+@Target_DB_Object_Name+'. Iteration no: '+CAST(@z AS VARCHAR(10))
PRINT '---------------------------------------------------------------------------------------------------------------------------------------'
PRINT @SQL +REPLICATE(CHAR(13),2)
END
EXEC (@SQL);
COMMIT TRANSACTION
FETCH NEXT
FROM db_cursor INTO @z
END TRY
BEGIN CATCH
ROLLBACK TRANSACTION
;WITH TempErr ( [ErrorNumber],
[ErrorSeverity],
[ErrorState],
[ErrorLine],
[ErrorMessage],
[ErrorDateTime],
[LoginName],
[UserName],
[PackageName],
[ObjectID],
[ProcessID],
[ExecutionInstanceGUID],
[DBName] )
AS ( SELECT ERROR_NUMBER() AS ErrorNumber ,
ERROR_SEVERITY() AS ErrorSeverity ,
ERROR_STATE() AS ErrorState ,
ERROR_LINE() AS ErrorLine ,
ERROR_MESSAGE() AS ErrorMessage ,
SYSDATETIME() AS ErrorDateTime ,
SYSTEM_USER AS LoginName ,
USER_NAME() AS UserName ,
@Package_Name ,
OBJECT_ID('' + @Target_DB_Name + '.'
+ @Target_DB_Schema_Name + '.'
+ @Target_DB_Object_Name + '') AS ObjectID ,
( SELECT a.objectid
FROM sys.dm_exec_requests r
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) a
WHERE session_id = @@spid
) AS ProcessID ,
CAST(SUBSTRING(@Exec_Instance_GUID , 1, 8) + '-' + SUBSTRING(@Exec_Instance_GUID , 9, 4) + '-' + SUBSTRING(@Exec_Instance_GUID , 13, 4) + '-' +
SUBSTRING(@Exec_Instance_GUID , 17, 4) + '-' + SUBSTRING(@Exec_Instance_GUID , 21, 12) AS UNIQUEIDENTIFIER) AS ExecutionInstanceGUID,
DB_NAME() AS DatabaseName
)
INSERT INTO AdminDBA.dbo.LogSSISErrors_Error
( [ErrorNumber] ,
[ErrorSeverity] ,
[ErrorState] ,
[ErrorLine] ,
[ErrorMessage] ,
[ErrorDateTime] ,
[FKLoginID] ,
[FKUserID] ,
[FKPackageID] ,
[FKObjectID] ,
[FKProcessID] ,
[ExecutionInstanceGUID]
)
SELECT ErrorNumber = COALESCE(err.ErrorNumber, -1) ,
ErrorSeverity = COALESCE(err.[ErrorSeverity], -1) ,
ErrorState = COALESCE(err.[ErrorState], -1) ,
ErrorLine = COALESCE(err.[ErrorLine], -1) ,
ErrorMessage = COALESCE(err.[ErrorMessage], 'Unknown') ,
ErrorDateTime = ErrorDateTime ,
FKLoginID = src_login.ID ,
FKUserID = src_user.ID ,
[FKPackageID] = src_package.ID ,
[FKObjectID] = src_object.ID ,
[FKProcessID] = src_process.ID ,
[ExecutionInstanceGUID] = err.ExecutionInstanceGUID
FROM TempErr err
LEFT JOIN AdminDBA.dbo.LogSSISErrors_Login src_login ON err.LoginName = src_login.LoginName
LEFT JOIN AdminDBA.dbo.LogSSISErrors_User src_user ON err.UserName = src_user.UserName
AND src_user.FKDBID = ( SELECT
ID
FROM
AdminDBA.dbo.LogSSISErrors_DB db
WHERE
db.DBName = err.DBName
)
LEFT JOIN AdminDBA.dbo.LogSSISErrors_Package src_package ON err.PackageName = ( LEFT(src_package.PackageName,
CHARINDEX('.',
src_package.PackageName)
- 1) )
LEFT JOIN AdminDBA.dbo.LogSSISErrors_Object src_object ON err.ObjectID = src_object.ObjectID
LEFT JOIN AdminDBA.dbo.LogSSISErrors_Process src_process ON err.ProcessID = src_process.ProcessID
WHERE src_login.CurrentlyUsed = 1
AND src_user.CurrentlyUsed = 1
--AND src_package.CurrentlyUsed = 1
AND src_object.CurrentlyUsed = 1
AND src_process.CurrentlyUsed = 1
END CATCH
END
CLOSE db_cursor
DEALLOCATE db_cursor
END
GO
Thanks to each table’s DML operation that the above code executes being wrapped up in a explicit transaction and error rollback process, a robust reporting platform can be created to log and account for any issues that might have been raised during runtime. Below is an image of a simple Tableau report which may be embedded into the error notification message, giving the operator a quick, high-level view of any issues that might have been logged in AdminDBA database during package execution.
In the next post (part 3) I will look into how smaller tables can be handled using a dynamic MERGE SQL statement creation, data acquisition validation mechanisms as well as the error notifications process triggered by a failed package/procedure.







Never thought Polybase could be used in this capacity and don't think Microsoft advertised this feature (off-loading DB data as…