Note: Part 2 can be found HERE and code files downloaded from HERE
Introduction
Last time I wrote about cloud-enabled data warehousing (see the 3-part series starting HERE), only one vendor and product qualify as a truly enterprise PaaS offering – Amazon Redshift running on AWS. Yes, there were other providers coming out of the woodwork, boasting their readiness to take on this juggernaut of cloud computing e.g. Bityota (already acquired by LifeLock) or SnowflakeDB (headed by a former Microsoft executive Bob Muglia) but none of them made it past the TechCrunch mention deep into the CxO’s wallets and capitalized on the data boom. Microsoft has been touting their Azure Data Warehouse as a formidable competitor to Redshift since mid-2015, with a host of features that may appeal to spending-cautious departments making their first foray into the cloud. In addition to competing on price, Microsoft also strives to differentiate itself with several features that Redshift does not offer. Some distinctive characteristics that separate Azure Data Warehouse from Redshift are:
Wide support of SQL and integration with other services – The SQL Data Warehouse extends the T-SQL constructs most developers are already familiar with to create indexes, partitions and stored procedures, which allow for an easy migration to the cloud. With native integration with Azure Data Factory, Azure Machine Learning and Power BI, Microsoft claims that customers are able to quickly ingest data, utilize learning algorithms, and visualize data born either in the cloud or on-premises
Separating compute and storage with ability to pause an instance – Azure SQL Data Warehouse independently scales compute and storage so customers only pay for the query performance they need. Dynamic pause enables businesses to optimize the utilization of the compute infrastructure by ramping down compute while persisting the data with no need to back up the data, delete the existing cluster, and, upon resume, generate a new cluster and restore data
PolyBase for structured and unstructured data blending – SQL Data Warehouse can query unstructured and semi-structured data stored in Azure Storage, Hortonworks Data Platform, or Cloudera using familiar T-SQL skills
Hybrid infrastructure for supporting on-premises and/or in the cloud
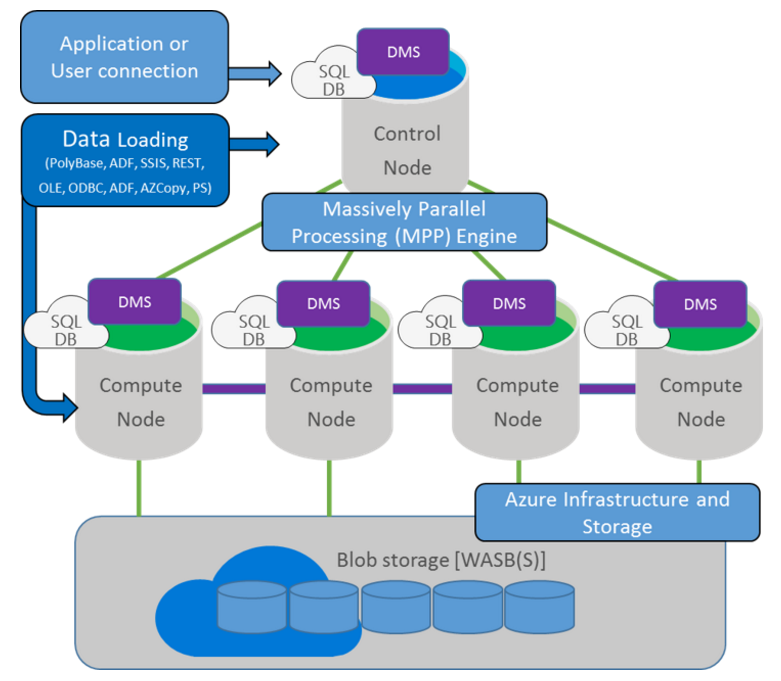
At its core, SQL Data Warehouse uses Microsoft’s massive parallel processing (MPP) architecture, originally designed to run some of the largest on-premises enterprise data warehouses. This architecture takes advantage of built-in data warehousing performance improvements and also allows SQL Data Warehouse to easily scale-out and parallelize computation of complex SQL queries. In addition, SQL Data Warehouse’s architecture is designed to take advantage of its presence in Azure. Combining these two aspects, the architecture breaks up into 4 key components:
Control node: You connect to the Control node when using SQL Data Warehouse with any development, loading, or business intelligence tools. In SQL Data Warehouse, the Control node is a SQL Database, and connecting it looks and feels like a standard SQL Database. However, under the surface, it coordinates all of the data movement and computation that takes place in the system. When a command is issued to the Control node, it breaks it down into a set of queries that will be passed onto the compute nodes of the service
Compute Nodes: Like the control node, the compute nodes of SQL Data Warehouse are powered using SQL Databases. Their job is to serve as the compute power of the service. Behind the scenes, any time data is loaded into SQL Data Warehouse, it is distributed across the nodes of the service. Then, any time the control node receives a command it breaks it into pieces for each compute node, and the compute nodes operate over their corresponding data. After completing their computation, compute nodes pass partial results to the control node which then aggregates results before returning an answer
Storage: All storage for SQL Data Warehouse is standard Azure Storage Blobs. This means that when interacting with data, compute nodes are writing and reading directly to/from Blobs. Azure Storage’s ability to expand transparently and nearly limitlessly allows us to automatically scale storage, and to do so separately from compute. Azure Storage also allows us to persist storage while scaling or paused, streamline our back-up and restore process, and have safer, more fault tolerant storage
Data Movement Services: The final piece holding everything together in SQL Data Warehouse is our Data Movement Services. The data movement services allows the control node to communicate and pass data to all of the compute nodes. It also enables the compute nodes to pass data between each other, which gives them access to data on other compute nodes, and allows them to get the data that they need to complete joins and aggregations
Microsoft provides a good intro into Azure Data Warehouse which outlines all of the above features and more in the video below.
All features and fancy bells and whistles aside, a typical business would also be interested in what sort of performance per dollar Microsoft’s offering would bring to the table as well as the level of integration the product can provide. As indicated in my previous post on AWS Redshift, building an enterprise data warehouse is a very costly and time-intensive activity regardless of which vendor or technology one chooses to peruse. In most if not all cases performance consideration would only constitute a fraction of the overall project plan so performance statistics alone should not become the sole merit on the technology choice, especially when coupled with a paradigm-shifting data warehouse architecture like the cloud computing. With that in mind, query execution speed is one of the most basic and fastest way of testing vendor offering and in this post I will provide a rudimentary analysis of the query execution speed based on Amazon’s TICKIT database which I used for my Redshift review a while ago and try to compare and contrast Azure Data Warehouse (preview edition) with the AWS equivalent based on predefined price/performance points. I would also like to briefly touch on Azure Data Warehouse integration with other vendors/partners, manly from analytical and reporting angle e.g. connecting from and analyzing the data in Tableau and Microsoft Power BI.
Pricing Overview
In case of Azure Data Warehouse Compute and Storage are billed separately. Compute usage is represented with DWU (Data Warehouse Unit) and customers can scale up and down the level of performance/DWUs they need by 100 DWU blocks. The preview price for the compute is USD 1.03/hr (~$766/mo) capped at 2000 DWU. When it comes to storage, Azure distinguishes between four types – Block blobs, Page Blobs and Disks, Tables and Queues, and Files, where total cost depends on how much you store, the volume of storage transactions and outbound data transfers, and which data redundancy option you choose. For Azure Data Warehouse, storage rates are based on standard RA-GRS Page Blob rates and cost around $0.1529 per GB (First 1 TB / Month).
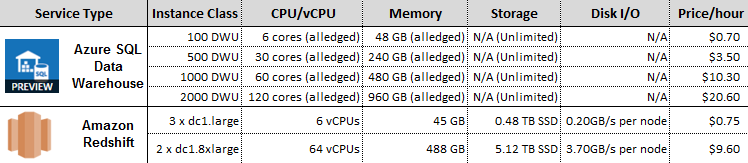
Microsoft is still quite clandestine about the actual hardware used to power Azure Data Warehouse, presumably due to the fact that it is still in a preview mode. The DWU – the unit of performance/cost that is used to scale processing capabilities is pretty much the only variable one can adjust to increase/decrease performance/price, which is not necessarily a bad thing – rather than choosing from a myriad of hardware configuration options I’d much rather select a unit of computational capability tied to a specific cost corresponding to the prospective workload. Quoting Microsoft here, ‘A DWU represents the power of the query performance and is quantified by workload objectives: how fast rows are scanned, loaded, and copied’. A bit cloak and dagger but simple and straightforward at the same time. Having said that, when attending one of Microsoft session at the Ignite conference in Gold Coast, Australia, Microsoft representative reluctantly stated that the closest hardware specifications equivalent of 100 DTU would equate to roughly one compute unit i.e. 6 cores and 48GB of memory. Again, this is at the time of publishing this post so these provisions will most likely scale up as updated version gets released. Besides, I can only see abstracting physical hardware capacity as a good thing – all I really want to do is to be as declarative as possible and tell the vendor how high (and how economically) I want them to jump and they do it, without having to worry about how it all ‘hangs together’ at the back end. Isn’t that the beauty of cloud computing after all? The image below is the only things I could find that provides a rough description of how DTU selection affects performance levels.
Amazon, on the other hand, provides a very high-level outline of some of the key features tied to individual service e.g. I/O speed for the direct-attached storage or memory size. Below is the outline of the instance classes and related parameters I used for query performance testing between individual service types. Below table outlines the ‘testbed’ configurations I used to measure SQL execution performance on both services.
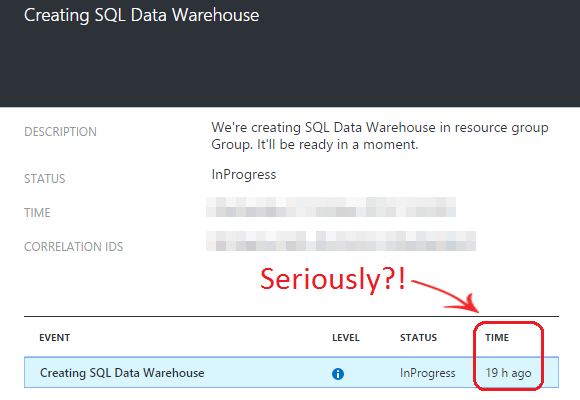
Provisioning both services could not be any simpler, in both vendors’ case it’s just a matter of selecting the desired computing capacity with its associated cost, deciding on the naming conventions for the designated servers and databases and finally configuring firewall to allow client access. In case of Azure I stumbled across a small issue when deploying the instance ‘got stuck’ on ‘In Progress’ status for over 19 hours, with no details provided by the portal on why the deployment was taking so long (see image below). Selecting a different region (initial region allocation for Azure DW deployment was Australia Southeast) seemed to rectify the problem but I wish Azure provided more information when roadblocks like this one occur, other than just a progress bar and a sparse message.
Test Data and Load
So what is Azure Data Warehouse performance like in comparison to the Amazon Redshift equivalent? To answer this question, first I needed to expand on the data provided by Amazon (TICKIT database) and copy it across to both services. This sample database helps analysts track sales activity for the fictional TICKIT web site, where users buy and sell tickets online for sporting events, shows, and concerts. In particular, analysts can identify ticket movement over time, success rates for sellers, and the best-selling events, venues, and seasons. Analysts can use this information to provide incentives to buyers and sellers who frequent the site, to attract new users, and to drive advertising and promotions. TICKIT database consists of seven tables: two fact tables and five dimensions as per the schema below.
Given the fact that there was not nearly enough data in the flat files provided (you can download text files used for this exercise from HERE) I needed a way to ‘grow’ the main fact table dataset to a more respectable size. The script I used for this purpose (saved in my OneDriver folder HERE) simply creates tables schema, inserts flat files data into the newly created database and ‘stretches out’ the main fact table into 50,000,000 rows. The last section also replaces the original sales comma delimited file with a series of files generated after sales table data expansion, each holding just over 5,000,000 records. This is to facilitate subsequent data import where smaller files are more ‘predictable’ and easier to manage when loading over the network. These 10 files containing sales data, in conjunction with the remaining dimensional data files, will form the basis for my quick query execution analysis.
Loading data into both services is a straightforward affair. In case of Redshift I used the same method as last time (see my previous blog post HERE) i.e. using Amazon’s recommended COPY utility to move text files across from S3 bucket into Redshift. There are other ways to do it but since this approach worked really well for me last time I decided to stick with the tried and tested methodology.
SQL Data Warehouse presents numerous options for loading data including PolyBase, Azure Data Factory, BCP command-line utility, SQL Server Integration Services (SSIS) as well as 3rd party data loading tools. Each method comes with its own pros and cons. Below are the slide deck shots from the Gold Coast Microsoft Ignite conference presentation roughly outlining key advantages/disadvantages and features characterizing those approaches.
The following table details the results of four separate Azure SQL Data Warehouse load tests using PolyBase, BCP, SQLBulkCopy/ADF and SSIS.
As you can see, the PolyBase method shows a significantly higher throughput rate compared to BCP, SQLBulkCopy, and SSIS Control-node client gated load methods. If PolyBase is not an option, however, BCP provides the next best load rate. Regarding loads that improved based on concurrent load (the third row in the chart), keep in mind that SQL Data Warehouse supports up to 32 concurrent queries (loads).
For this demo BCP looked like the most straightforward way to populate TICKIT database schema so I settled for the BCP utility. To partially automate BCP execution for each table I have deployed a simple batch file script (see code below) which, apart from loading the data from flat files, also creates TestDW database schema via a range of DDL statements being sourced from a SQL file, checks for record count discrepancies, and finally creates clustered columnstore indexes and statistics on all tables. If using it, just ensure that parameters highlighted have been populated with values corresponding to your environment and as always, this code, along with other scripts, can be downloaded from my OneDrive folder HERE.
REM TICKIT Database Objects Definition, Data Load and Stats Refresh Job
@echo off
REM ============================
REM Start User Defined Variables
REM ============================
set server=
set user=
set password=
set database=
REM ==========================
REM End User Defined Variables
REM ==========================
set tables=Users, Venue, Category, Date, Event, Listing, Sales
set views=vstats_columns
set storedprocs=prc_sqldw_create_stats
set ddl=tickit_ddl.sql
set validation=tickit_check.sql
set idxs_and_statistics=tickit_create_idxs_and_statistics.sql
set schema=dbo
set p1=.
set logs=%p1%\logs
set load="C:\Program Files\Microsoft SQL Server\110\Tools\Binn\bcp.exe"
set mode=reload
set login_timeout=120
mkdir %logs% 2> nul
del %logs%\*.log 2> nul
if "%server%"=="" (
echo %date% %time% Server needs to be specified.
goto eof
)
if "%user%"=="" (
echo %date% %time% User needs to be specified.
goto eof
)
if "%password%"=="" (
echo %date% %time% Password needs to be specified.
goto eof
)
if "%database%"=="" (
echo %date% %time% Database needs to be specified.
goto eof
)
if not exist %load% (
echo %date% %time% Bcp must be installed.
goto eof
)
echo %date% %time% Dropping Existing TICKIT Tables, Views and Stored Procedures
for %%t in (%tables%) do (
sqlcmd -S "%server%" -U %user% -P %password% -d %database% -I -l %login_timeout% -e -Q "IF EXISTS (SELECT NULL FROM sys.tables WHERE name = '%%t') DROP TABLE %%t" >> %logs%\drop_tables.log
)
for %%v in (%views%) do (
sqlcmd -S "%server%" -U %user% -P %password% -d %database% -I -l %login_timeout% -e -Q "IF EXISTS (SELECT NULL FROM sys.views WHERE name = '%%v') DROP VIEW %%v" >> %logs%\drop_views.log
)
for %%s in (%storedprocs%) do (
sqlcmd -S "%server%" -U %user% -P %password% -d %database% -I -l %login_timeout% -e -Q "IF EXISTS (SELECT NULL FROM sys.objects WHERE type = 'P' AND OBJECT_ID = OBJECT_ID('%%s')) DROP PROCEDURE %%s" >> %logs%\drop_stored_procs.log
)
echo %date% %time% Existing TICKIT Tables and Views Dropped
echo %date% %time% Creating TICKIT Tables and Views
sqlcmd -S "%server%" -U %user% -P %password% -d %database% -I -i %p1%\%ddl% -l %login_timeout% -b -e >> %logs%\ddl.log
if %ERRORLEVEL% NEQ 0 (
echo %date% %time% Create DDL statement failed. Please look at the file %output_file% for errors.
goto eof
)
echo %date% %time% TICKIT Tables and Views Created
echo %date% %time% Loading TICKIT Tables
for %%x in (%tables%) do (
@echo on
echo. >> %logs%\loads.log
echo %date% %time% Loading %%x >> %logs%\loads.log
IF "%%x"=="Sales" (
%load% %schema%.%%x in "%p1%\NewSales1.txt" -S%server% -U%user% -P%password% -d%database% -q -c -t "|" >> %logs%\loads.log
%load% %schema%.%%x in "%p1%\NewSales2.txt" -S%server% -U%user% -P%password% -d%database% -q -c -t "|" >> %logs%\loads.log
%load% %schema%.%%x in "%p1%\NewSales3.txt" -S%server% -U%user% -P%password% -d%database% -q -c -t "|" >> %logs%\loads.log
%load% %schema%.%%x in "%p1%\NewSales4.txt" -S%server% -U%user% -P%password% -d%database% -q -c -t "|" >> %logs%\loads.log
%load% %schema%.%%x in "%p1%\NewSales5.txt" -S%server% -U%user% -P%password% -d%database% -q -c -t "|" >> %logs%\loads.log
%load% %schema%.%%x in "%p1%\NewSales6.txt" -S%server% -U%user% -P%password% -d%database% -q -c -t "|" >> %logs%\loads.log
%load% %schema%.%%x in "%p1%\NewSales7.txt" -S%server% -U%user% -P%password% -d%database% -q -c -t "|" >> %logs%\loads.log
%load% %schema%.%%x in "%p1%\NewSales8.txt" -S%server% -U%user% -P%password% -d%database% -q -c -t "|" >> %logs%\loads.log
%load% %schema%.%%x in "%p1%\NewSales9.txt" -S%server% -U%user% -P%password% -d%database% -q -c -t "|" >> %logs%\loads.log
%load% %schema%.%%x in "%p1%\NewSales10.txt" -S%server% -U%user% -P%password% -d%database% -q -c -t "|" >> %logs%\loads.log
) ELSE (
%load% %schema%.%%x in "%p1%\%%x.txt" -S%server% -U%user% -P%password% -d%database% -q -c -t "|" >> %logs%\loads.log
)
@echo off
if %ERRORLEVEL% NEQ 0 (
echo %date% %time% Load for table %%x failed. Please look at the file %logs%\load_%%x.log for errors.
) ELSE (
echo %date% %time% Table %%x loaded
)
)
echo %date% %time% TICKIT Tables Loaded
echo %date% %time% Validating Row Counts
sqlcmd -S "%server%" -U %user% -P %password% -d %database% -I -i %p1%\%validation% -l %login_timeout%
echo %date% %time% Creating Clustered ColumStore Indexes and Statistics on all Tables
sqlcmd -S "%server%" -U %user% -P %password% -d %database% -I -i %p1%\%idxs_and_statistics% -l %login_timeout% -e -p >> %logs%\idxs_and_statistics.log
echo %date% %time% ColumnStore Indexes and Statistics Created on all Tables
:eof
Alternatively, providing you have already created all necessary tables on your DW instance, you can simply copy and paste the following ‘one-liners’ into your command prompt, adjusting files location, server name, database name and credentials parameters to match your environment.
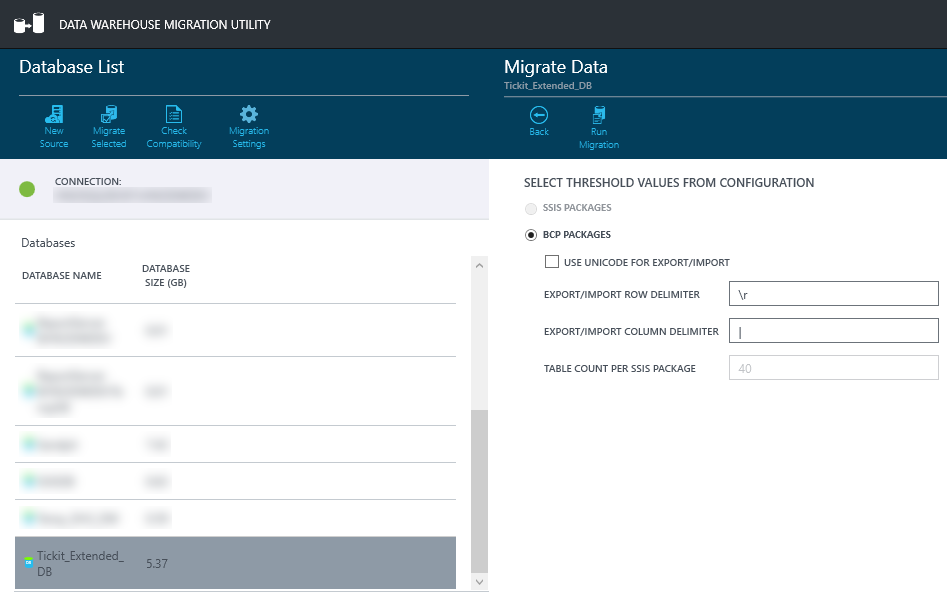
It is also worth mentioning that Microsoft provides a handy little utility to create import and export BCP files based on configured set of parameters driven by a wizard-like process. The tool is aptly called Data Warehouse Migration Utility and even though still in preview, it provides an automated schema and data migration scripts generation from SQL Server and Azure SQL Database to Azure SQL Data Warehouse.
The download link as well as the tool overview page can be found HERE.
In the next post I will provide test results from a selection of sample queries executed on both platforms stacked up against each other and briefly touch on reporting from Azure SQL DW using Power BI and Tableau tools.
Last client who engaged me to architect and develop a small data warehouse for them also made a large investment in Tableau as their default reporting platform. The warehouse data, small by today’s standards, was to be uploaded into Tableau server as a scheduled overnight extract and users granted access to reports/data on Tableau server rather than querying star schema relational tables directly (implemented on the SQL Server database engine). As data availability and therefore meeting BI SLAs was paramount to the project success, a robust notification system was put in place to log any data warehouse issues that may have arisen from all activities on the database server. However, even though all precautions were taken to ensure data warehouse failed processes were logged and corresponding issues mitigated accordingly, Tableau extract failures along with other Tableau server activities were largely unaccounted for due to the lack of data. How could one address this issue?
Tableau provides access to their internal server PostgreSQL metadata database with just a few simple steps. As it turns out, during installation Tableau Server will create the almost empty ‘workgroup’ repository with over 100+ tables, 900+ columns (about 100 of them used as Keys), 300+ joins and 16+ views which can be accessed and queried. Tableau Server works as a collection processes, processors, programs and applications, like data engine, data server, VizQL Server, application server etc. Each of those processes generates log with data about user activities, data connections, queries and extractions, errors, views and interactions, etc. which is parsed regularly and stored into PostgreSQL-based Tableau Server Administrative Database. PostgreSQL Server containing Workgroup DB usually runs on the same Windows Server as Main Tableau Server or (if Tableau Server runs on multi-mode cluster with Worker Tableau Server(s)) on other Windows Server, which runs Worker Tableau Server and uses non-standard TCP/IP port 8060. Tableau’s PostgreSQL database access is provided by means of using a few different accounts, each with its own set of privileges. In November 2014 Tableau Software introduced (Release 8.2.5) a new, default user, named ‘readonly’ with read access to all tables and views of Workgroup Repository which is what I’m going to be using to get ‘under the hood’. Other user commonly used for Tableau server metadata exploration, aptly named ‘tableau’ can also be used for Tableau server activity analysis but has access to fewer database objects.
The easiest way to connect to Tableau’s ‘workgroup’ database using ‘readonly’ account is opening an administrator command prompt on your Tableau Server, navigating to your Tableau Server bin directory and issuing the tabadmin dbpass command, specifying your chosen password. After server restart the changes should take effect and you should be able to see the following output.
PostgreSQL can now be queried using a client tool of your choice e.g. PgAdmin. This is what the ‘public’ schema with all its tables looks like when imported in Navicat Data Modeller (click on image to enlarge).
In order to connect to it from SQL Server we can simply download PostgreSQL ODBC driver and configure it with the credentials of the ‘readonly’ user.
All there is left to do is to create a linked server connection to PostgreSQL database directly from SQL Server Management Studio, exposing a collection of objects (tables and views) on the public schema.
Now we should be able to OPENQUERY Tableau metadata objects with ease but if we would like to go further and regularly copy Tableau’s data across to SQL Server (in case of my client that was precisely the requirement in order not to interfere with production database), the following code should provide this functionality.
Firstly, let’s create a sample database called ‘TableauDBCopy’ and a ‘tab’ schema on the SQL Server target instance. The below SQL snippet also creates and populates a small table called ‘tabSchemaObjectsExclude’ on the ‘dbo’ schema which stores table names we don’t want to import. The reason for this exclusion is that these tables do not contain the primary keys, therefore it is impossible to compare the two schemas using the code below which relies on primary key being defined on every single table object.
--CREATE 'TableauDBCopy' DATABASE AND 'tab' SCHEMA ON THE TARGET INSTANCE/SERVER
USE [master];
GO
IF EXISTS ( SELECT name
FROM sys.databases
WHERE name = N'TableauDBCopy' )
BEGIN
ALTER DATABASE TableauDBCopy SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE TableauDBCopy;
END;
GO
CREATE DATABASE TableauDBCopy ON
( NAME = 'TableauDBCopy_dat',
FILENAME = 'D:\SQLData\MSSQL12.ServerName\MSSQL\DATA\TableauDBCopy.mdf',
SIZE = 500MB,
MAXSIZE = 2000MB,
FILEGROWTH = 100 ) LOG ON
( NAME = 'TableauDBCopy_log',
FILENAME = 'D:\SQLData\MSSQL12.ServerName\MSSQL\DATA\TableauDBCopy.ldf',
SIZE = 100MB,
MAXSIZE = 1000MB,
FILEGROWTH = 50MB );
GO
EXEC TableauDBCopy.dbo.sp_changedbowner @loginame = N'SA', @map = false;
GO
ALTER DATABASE TableauDBCopy SET RECOVERY SIMPLE;
GO
USE TableauDBCopy;
GO
CREATE SCHEMA tab AUTHORIZATION dbo;
GO
--CREATE EXCEPTION 'tabSchemaObjectsExclude' TABLE AND POPULATE IT WITH EXCEPTION DATA
CREATE TABLE dbo.tabSchemaObjectsExclude
(ObjectName VARCHAR (256))
GO
INSERT INTO dbo.tabSchemaObjectsExclude( ObjectName )
SELECT 'dataengine_configurations' UNION ALL
SELECT 'exportable_repository_id_columns' UNION ALL
SELECT 'exportable_tables_column_transformations' UNION ALL
SELECT 'monitoring_dataengine' UNION ALL
SELECT 'monitoring_postgresql' UNION ALL
SELECT 'permission_reasons' UNION ALL
SELECT 'schema_migrations' UNION ALL
SELECT 'users_view'
Next, let’s look at a simple stored procedure which compares the source schema (Tableau server public schema on the PostgreSQL database) with the target schema (our newly created SQL Server database with the ‘tab’ schema). This code is used to interrogate both databases for their ‘compatibility’ and tables metadata structure e.g. data types, character lengths, NULL-ablity, precision, scale etc. and if the target object(s) are found to be missing or out of sync with the source version, it creates a DROP and a CREATE table SQL DDLs statement on the fly and applies the changes directly in the target environment.
USE [TableauDBCopy]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[usp_checkRemoteTableauServerTablesSchemaChanges]
(
@Remote_Server_Name VARCHAR (256),
@Remote_Server_DB_Name VARCHAR (128),
@Remote_Server_DB_Schema_Name VARCHAR (128),
@Target_DB_Name VARCHAR (128),
@Target_DB_Schema_Name VARCHAR (128),
@Is_All_OK INT OUTPUT ,
@Process_Name VARCHAR (250) OUTPUT ,
@Error_Message VARCHAR (MAX) OUTPUT
)
WITH RECOMPILE
AS
SET NOCOUNT ON
BEGIN
DECLARE @Is_ReCheck BIT = 0
DECLARE @SQL NVARCHAR (MAX)
DECLARE @Is_Debug_Mode BIT = 1
DECLARE @Remote_Server_Tableau VARCHAR(55) = 'TABPOSTGRESQLPROD'
SET @Process_Name = ( SELECT OBJECT_NAME(objectid)
FROM sys.dm_exec_requests r
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) a
WHERE session_id = @@spid
)
IF OBJECT_ID('tempdb..#t_seqfloats') IS NOT NULL
BEGIN
DROP TABLE #t_seqfloats
END
;WITH Nbrs_3 ( n )
AS ( SELECT 1
UNION
SELECT 0
),
Nbrs_2 ( n )
AS ( SELECT 1
FROM Nbrs_3 n1
CROSS JOIN Nbrs_3 n2
),
Nbrs_1 ( n )
AS ( SELECT 1
FROM Nbrs_2 n1
CROSS JOIN Nbrs_2 n2
),
Nbrs_0 ( n )
AS ( SELECT 1
FROM Nbrs_1 n1
CROSS JOIN Nbrs_1 n2
),
Nbrs ( n )
AS ( SELECT 1
FROM Nbrs_0 n1
CROSS JOIN Nbrs_0 n2
)
SELECT 'float' + CAST(n AS VARCHAR(2)) seq_floats
INTO #t_seqfloats
FROM ( SELECT ROW_NUMBER() OVER ( ORDER BY n )
FROM Nbrs
) D ( n )
WHERE n <= 53
UNION ALL
SELECT 'float'
Check_RemoteSvr_Schema:
IF OBJECT_ID('tempdb..#t_allTblMetadata') IS NOT NULL
BEGIN
DROP TABLE [#t_allTblMetadata]
END
CREATE TABLE tempdb..[#t_allTblMetadata]
(
table_name VARCHAR(256),
column_name VARCHAR(256),
ordinal_position INT ,
is_nullable BIT ,
data_type VARCHAR (256) ,
character_maximum_length BIGINT,
numeric_scale SMALLINT,
numeric_precision SMALLINT,
is_primary_key BIT,
local_schema_name VARCHAR(55),
remote_schema_name VARCHAR(55),
local_or_remote VARCHAR(25)
)
SET @SQL = '
INSERT INTO #t_allTblMetadata
(
[table_name]
,[column_name]
,[ordinal_position]
,[is_nullable]
,[data_type]
,[character_maximum_length]
,[numeric_scale]
,[numeric_precision]
,[is_primary_key]
,[local_schema_name]
,[remote_schema_name]
,[local_or_remote]
)
SELECT
LTRIM(RTRIM(a.table_name)) AS table_name,
LTRIM(RTRIM(a.column_name)) AS column_name,
LTRIM(RTRIM(a.ordinal_position)) AS ordinal_position,
CASE WHEN a.is_nullable = ''YES''
THEN 1 ELSE 0 END AS is_nullable,
LTRIM(RTRIM(a.udt_name)) AS data_type,
--a.data_type AS data_type,
LTRIM(RTRIM(a.character_maximum_length)) AS character_maximum_length,
LTRIM(RTRIM(a.numeric_scale)) AS numeric_scale,
LTRIM(RTRIM(a.numeric_precision)) AS numeric_precision,
--b.primary_key_definition,
CASE WHEN b.PK_column_name IS NULL
THEN 0 ELSE 1 END AS is_primary_key,
''tab'' AS local_schema_name,
LTRIM(RTRIM(a.table_schema)) AS remote_schema_name,
''remote'' AS local_or_remote
FROM OPENQUERY(' +@remote_server_name+ ',
''select
c.table_name,
c.column_name,
c.ordinal_position,
c.is_nullable,
c.data_type,
c.udt_name ,
c.character_maximum_length,
c.numeric_scale,
c.numeric_precision,
c.table_schema
from information_schema.columns c
where c.table_catalog = ''''workgroup'''' and c.table_schema = ''''public'''''') a
LEFT JOIN
OPENQUERY(' +@remote_server_name+ ',
''select
cl.relname as table_name,
co.conname as constraint_name,
co.contype conatraint_type,
pg_get_constraintdef(co.oid) AS primary_key_definition ,
ns.nspname as schema_name,
pa.attname as PK_column_name
from pg_class cl join pg_constraint co on cl.oid = co.conrelid
join pg_namespace ns on cl.relnamespace = ns.oid
join pg_attribute pa on pa.attrelid = cl.oid and pa.attnum = co.conkey[1]
where co.contype = ''''p''''
and cl.relkind=''''r''''
and ns.nspname = ''''public'''''') b
ON a.table_name = b.table_name AND a.table_schema = b.[schema_name] AND a.column_name = b.PK_column_name
WHERE SUBSTRING(a.table_name, 1, 1) <> ''_'' AND SUBSTRING(a.table_name, 1, 7) <> ''orphans''
AND NOT EXISTS (SELECT objectname FROM TableauDBCopy.dbo.tabSchemaObjectsExclude o WHERE o.objectname = a.table_name)
ORDER BY a.table_name, a.ordinal_position'
IF @Is_Debug_Mode = 1
BEGIN
PRINT CHAR(13) + 'SQL statement for acquiring ''source'' tables metadata into #t_allTblMetadata temp table:'
PRINT '-----------------------------------------------------------------------------------------------'
PRINT @SQL +REPLICATE(CHAR(13),2)
END
EXEC(@SQL)
IF @Is_Debug_Mode = 1
BEGIN
SELECT '#t_allTblMetadata table content for remote objects metadata:' AS 'HINT'
SELECT *
FROM #t_allTblMetadata WHERE local_or_remote = 'Remote'
ORDER BY table_name, ordinal_position
END
IF @Is_ReCheck = 1
BEGIN
GOTO Check_Local_Schema
END
Check_Local_Schema:
SET @SQL =
'INSERT INTO #t_allTblMetadata
(
[table_name]
,[column_name]
,[ordinal_position]
,[is_nullable]
,[data_type]
,[character_maximum_length]
,[numeric_scale]
,[numeric_precision]
,[is_primary_key]
,[local_schema_name]
,[remote_schema_name]
,[local_or_remote]
)
SELECT
t.name AS table_name ,
c.name AS column_name ,
c.column_id AS ordinal_position ,
c.is_nullable ,
tp.name AS data_type ,
c.max_length AS character_maximum_length ,
c.scale AS numeric_scale ,
c.precision AS numeric_precision ,
ISNULL(idx.pk_flag,0) as ''is_primary_key'' ,
ss.name ,
''public'' ,
''local'' AS local_or_remote
FROM sys.tables t
JOIN sys.columns c ON t.object_id = c.object_id
JOIN sys.types tp ON c.user_type_id = tp.user_type_id
JOIN sys.objects so ON so.object_id = t.object_id
JOIN sys.schemas ss ON so.schema_id = ss.schema_id
LEFT JOIN (select i.name as index_name, i.is_primary_key as pk_flag, OBJECT_NAME(ic.OBJECT_ID) AS table_name,
COL_NAME(ic.OBJECT_ID,ic.column_id) AS column_name FROM sys.indexes AS i INNER JOIN
sys.index_columns AS ic ON i.OBJECT_ID = ic.OBJECT_ID
AND i.index_id = ic.index_id
WHERE i.is_primary_key = 1) idx on idx.table_name = t.name and idx.column_name = c.name
JOIN INFORMATION_SCHEMA.TABLES tt on tt.table_schema = ss.name and tt.table_name = t.name
WHERE t.type = ''u''
AND tt.TABLE_CATALOG = '''+@Target_DB_Name+'''
AND ss.name = '''+@Target_DB_Schema_Name+''''
IF @Is_Debug_Mode = 1
BEGIN
PRINT 'SQL statement for acquiring ''target'' tables metadata into #t_allTblMetadata temp table:'
PRINT '-----------------------------------------------------------------------------------------------'
PRINT @SQL +REPLICATE(CHAR(13),2)
END
EXEC(@SQL)
IF @Is_Debug_Mode = 1
BEGIN
SELECT '#t_allTblMetadata table content for local objects metadata:' AS 'HINT'
SELECT *
FROM #t_allTblMetadata WHERE local_or_remote = 'local'
ORDER BY table_name, ordinal_position
END
IF OBJECT_ID('tempdb..#t_sql') IS NOT NULL
BEGIN
DROP TABLE [#t_sql]
END
SELECT DISTINCT
t1.table_name AS Table_Name ,
t1.local_schema_name AS Local_Schema_Name ,
'create table [' + t1.local_schema_name + '].['
+ LOWER(t1.table_name) + '] (' + STUFF(o.list, LEN(o.list), 1, '')
+ ')' + CASE WHEN t2.is_primary_key = 0 THEN ''
ELSE '; ALTER TABLE [' + t1.local_schema_name
+ '].[' + t1.table_name + '] '
+ ' ADD CONSTRAINT pk_'
+ LOWER(t1.local_schema_name) + '_'
+ LOWER(t2.table_name) + '_' +
LOWER(REPLACE(t2.pk_column_names,',','_'))
+' PRIMARY KEY CLUSTERED ' + '('
+ LOWER(t2.pk_column_names) + ')'
END AS Create_Table_Schema_Definition_SQL ,
'if object_id (''[' + t1.local_schema_name + '].['
+ t1.table_name + ']' + ''', ''U'') IS NOT NULL drop table ['
+ t1.local_schema_name + '].[' + t1.table_name + ']' AS Drop_Table_SQL
INTO #t_sql
FROM #t_allTblMetadata t1
CROSS APPLY ( SELECT '[' + column_name + '] '
+ CASE WHEN data_type IN ( 'bigint',
'int8',
'bigserial')
THEN 'bigint'
WHEN data_type IN ( 'integer',
'serial4',
'serial',
'int4',
'int',
'oid')
THEN 'int'
WHEN data_type IN ( 'smallint',
'serial2',
'smallserial',
'int2')
THEN 'smallint'
WHEN data_type IN ( 'uuid')
THEN 'uniqueidentifier'
WHEN data_type IN ( 'bool',
'boolean' )
THEN 'bit'
WHEN data_type IN ( 'timestamp',
'timestamptz')
THEN 'datetime'
WHEN data_type IN ( 'bytea',
'json',
'text',
'varchar')
THEN 'nvarchar'
WHEN data_type IN ( SELECT * FROM #t_seqfloats )
THEN 'float'
ELSE data_type
END
+ CASE WHEN data_type IN ('int2',
'int4',
'int8',
'oid',
'timestamp',
'uuid',
'bool')
THEN ''
WHEN
data_type IN ('text', 'json', 'bytea') OR (data_type = 'varchar' and character_maximum_length IS NULL) OR character_maximum_length > 8000
THEN '(max)'
WHEN data_type = 'decimal'
THEN '('
+ CAST(numeric_precision AS VARCHAR)
+ ', '
+ CAST(numeric_scale AS VARCHAR)
+ ')'
WHEN data_type in (SELECT * FROM #t_seqfloats)
THEN '(53)'
ELSE COALESCE('(' + CAST(character_maximum_length AS VARCHAR) + ')', '')
END + ' '
+( CASE WHEN is_nullable = 0
THEN 'NOT '
ELSE ''
END ) + 'NULL' + ','
FROM #t_allTblMetadata
WHERE table_name = t1.table_name AND local_or_remote = 'Remote'
ORDER BY ordinal_position
FOR
XML PATH('')
) o ( list )
JOIN ( SELECT table_name ,
is_primary_key ,
pk_column_names ,
column_name = REVERSE(RIGHT(REVERSE(pk_column_names),
LEN(pk_column_names)
- CHARINDEX(',',
REVERSE(pk_column_names))))
FROM ( SELECT table_name ,
is_primary_key ,
pk_column_names = STUFF(( SELECT
','
+CAST(column_name AS VARCHAR(500))
FROM
#t_allTblMetadata z2
WHERE
z1.table_name = z2.table_name
AND z2.is_primary_key = 1
AND z2.local_or_remote = 'Remote'
ORDER BY z2.column_name ASC
FOR
XML
PATH('')
), 1, 1, '')
FROM #t_allTblMetadata z1
WHERE z1.is_primary_key = 1
AND z1.local_or_remote = 'Remote'
GROUP BY z1.table_name ,
z1.is_primary_key
) a
) t2 ON t1.table_name = t2.table_name
WHERE t1.local_schema_name <> 'unknown' and t1.local_or_remote = 'Remote'
IF @Is_Debug_Mode = 1
BEGIN
SELECT '#t_sql table content:' AS 'HINT'
SELECT *
FROM #t_sql
ORDER BY Table_Name
END
IF @Is_ReCheck = 1
BEGIN
GOTO Do_Table_Diff
END
Do_Table_Diff:
IF OBJECT_ID('tempdb..#t_diff') IS NOT NULL
BEGIN
DROP TABLE [#t_diff]
END
;WITH Temp_CTE ( table_name, column_name, is_nullable, data_type, local_schema_name, is_primary_key, character_maximum_length, numeric_scale, numeric_precision )
AS (
SELECT table_name = m.table_name ,
column_name = m.column_name ,
is_nullable = m.is_nullable ,
data_type = CASE WHEN m.data_type IN ( 'bigint',
'int8',
'bigserial')
THEN 'bigint'
WHEN m.data_type IN ( 'integer',
'serial4',
'serial',
'int4',
'int',
'oid')
THEN 'int'
WHEN m.data_type IN ( 'smallint',
'serial2',
'smallserial',
'int2')
THEN 'smallint'
WHEN m.data_type IN ( 'uuid')
THEN 'uniqueidentifier'
WHEN m.data_type IN ( 'bool',
'boolean' )
THEN 'bit'
WHEN m.data_type IN ( 'timestamp',
'timestamptz')
THEN 'datetime'
WHEN m.data_type IN ( 'bytea',
'json',
'text',
'varchar')
THEN 'nvarchar'
WHEN m.data_type IN ( SELECT * FROM #t_seqfloats )
THEN 'float'
ELSE m.data_type
END,
local_schema_name = m.local_schema_name ,
is_primary_key = m.is_primary_key ,
character_maximum_length = COALESCE(CASE WHEN
m.data_type IN ('text', 'json', 'bytea') OR (m.data_type = 'varchar' and m.character_maximum_length IS NULL) OR m.character_maximum_length > 8000
THEN 'max'
ELSE CAST(m.character_maximum_length AS VARCHAR) END,
constants.character_maximum_length ,
CAST(l.character_maximum_length AS VARCHAR)),
numeric_scale = COALESCE( constants.numeric_scale,
CAST(m.numeric_scale AS VARCHAR),
CAST(l.numeric_scale AS VARCHAR)),
numeric_precision = COALESCE( constants.numeric_precision,
CAST(m.numeric_precision AS VARCHAR),
CAST(l.numeric_precision AS VARCHAR))
FROM #t_allTblMetadata m
LEFT JOIN ( SELECT 'char' AS data_type ,
NULL AS character_maximum_length ,
0 AS numeric_scale ,
0 AS numeric_precision
UNION ALL
SELECT 'varchar' ,
NULL ,
'0' ,
'0'
UNION ALL
SELECT 'time' ,
'5' ,
'7' ,
'16'
UNION ALL
SELECT 'date' ,
'3' ,
'0' ,
'10'
UNION ALL
SELECT 'datetime' ,
'8' ,
'3' ,
'23'
UNION ALL
SELECT 'datetime2' ,
'8' ,
'7' ,
'27'
UNION ALL
SELECT 'smalldatetime' ,
'4' ,
'0' ,
'16'
UNION ALL
SELECT 'bit' ,
'1' ,
'0' ,
'1'
UNION ALL
SELECT 'float' ,
'8' ,
'0' ,
'53'
UNION ALL
SELECT 'money' ,
'8' ,
'4' ,
'19'
UNION ALL
SELECT 'smallmoney' ,
'4' ,
'4' ,
'10'
UNION ALL
SELECT 'uniqueidentifier' ,
'16' ,
'0' ,
'0'
UNION ALL
SELECT 'xml' ,
'max' ,
'0' ,
'0'
UNION ALL
SELECT 'numeric' ,
'9' ,
'0' ,
'18'
UNION ALL
SELECT 'real' ,
'4' ,
'0' ,
'24'
UNION ALL
SELECT 'tinyint' ,
'1' ,
'0' ,
'3'
UNION ALL
SELECT 'smallint' ,
'2' ,
'0' ,
'5'
UNION ALL
SELECT 'int' ,
'4' ,
'0' ,
'10'
UNION ALL
SELECT 'bigint' ,
'8' ,
'0' ,
'19'
) constants ON (CASE WHEN m.data_type IN ( 'bigint',
'int8',
'bigserial')
THEN 'bigint'
WHEN m.data_type IN ( 'integer',
'serial4',
'serial',
'int4',
'int',
'oid')
THEN 'int'
WHEN m.data_type IN ( 'smallint',
'serial2',
'smallserial',
'int2')
THEN 'smallint'
WHEN m.data_type IN ( 'uuid')
THEN 'uniqueidentifier'
WHEN m.data_type IN ( 'bool',
'boolean' )
THEN 'bit'
WHEN m.data_type IN ( 'timestamp',
'timestamptz')
THEN 'datetime'
WHEN m.data_type IN ( 'bytea',
'json',
'text',
'varchar')
THEN 'nvarchar'
WHEN m.data_type IN ( SELECT * FROM #t_seqfloats )
THEN 'float'
ELSE m.data_type
END ) = constants.data_type
LEFT JOIN #t_allTblMetadata l ON l.column_name = m.column_name
AND l.table_name = m.table_name
AND l.data_type = ( CASE WHEN m.data_type IN ( 'bigint',
'int8',
'bigserial')
THEN 'bigint'
WHEN m.data_type IN ( 'integer',
'serial4',
'serial',
'int4',
'int',
'oid')
THEN 'int'
WHEN m.data_type IN ( 'smallint',
'serial2',
'smallserial',
'int2')
THEN 'smallint'
WHEN m.data_type IN ( 'uuid')
THEN 'uniqueidentifier'
WHEN m.data_type IN ( 'bool',
'boolean' )
THEN 'bit'
WHEN m.data_type IN ( 'timestamp',
'timestamptz')
THEN 'datetime'
WHEN m.data_type IN ( 'bytea',
'json',
'text',
'varchar')
THEN 'nvarchar'
WHEN m.data_type IN ( SELECT * FROM #t_seqfloats )
THEN 'float'
ELSE m.data_type
END ) AND l.local_or_remote = 'Local'
WHERE m.local_or_remote = 'Remote'
EXCEPT
SELECT table_name ,
column_name ,
is_nullable ,
data_type ,
local_schema_name ,
is_primary_key ,
CASE WHEN character_maximum_length > 8000 OR character_maximum_length = -1
THEN 'max'
WHEN data_type IN ('nvarchar', 'nchar') THEN CAST(character_maximum_length/2 AS VARCHAR)
ELSE CAST(character_maximum_length AS VARCHAR) END AS character_maximum_length,
numeric_scale ,
numeric_precision
FROM #t_allTblMetadata
WHERE local_or_remote ='Local'
)
SELECT DISTINCT
table_name ,
local_schema_name
INTO #t_diff
FROM Temp_CTE
IF @Is_Debug_Mode = 1
BEGIN
SELECT '#t_diff table content:' AS 'HINT'
SELECT *
FROM #t_diff
END
IF @Is_ReCheck = 1
GOTO Results
Run_SQL:
IF NOT EXISTS ( SELECT DISTINCT
Table_Name ,
Local_Schema_Name
FROM #t_sql a
WHERE EXISTS ( SELECT table_name
FROM #t_diff i
WHERE a.Table_Name = i.table_name ) )
BEGIN
GOTO Schema_Diff_ReCheck
END
ELSE
BEGIN
DECLARE @schema_name VARCHAR(50)
DECLARE @table_name VARCHAR(256)
DECLARE @sql_select_dropcreate NVARCHAR(MAX)
DECLARE db_cursor CURSOR FORWARD_ONLY
FOR
SELECT DISTINCT
Table_Name ,
Local_Schema_Name
FROM #t_sql a
WHERE EXISTS ( SELECT table_name
FROM #t_diff i
WHERE a.Table_Name = i.table_name )
OPEN db_cursor
FETCH NEXT
FROM db_cursor INTO @table_name, @schema_name
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
BEGIN TRANSACTION
SET @sql_select_dropcreate = ( SELECT
Drop_Table_SQL
FROM
#t_sql
WHERE
Table_Name = @table_name
) + '; ' +CHAR(13)
+ ( SELECT Create_Table_Schema_Definition_SQL
FROM #t_sql
WHERE Table_Name = @table_name
) + REPLICATE(CHAR(13),2)
IF @Is_Debug_Mode = 1
BEGIN
PRINT 'SQL statement for dropping/recreating ''source'' table(s):'
PRINT '-----------------------------------------------------------------------------------------------'
PRINT @sql_select_dropcreate
END
EXEC sp_sqlexec @sql_select_dropcreate
--SET @Is_All_OK = 1
SET @Error_Message = 'All Good!'
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION;
SET @Is_All_OK = 0
SET @Error_Message = 'This operation has been unexpectandly terminated due to error: '''
+ ERROR_MESSAGE() + ''' at line '
+ CAST(ERROR_LINE() AS VARCHAR);
END CATCH
FETCH NEXT FROM db_cursor INTO @table_name,@schema_name
END
CLOSE db_cursor
DEALLOCATE db_cursor
SET @Is_ReCheck = 1
END
Schema_Diff_ReCheck:
IF @Is_ReCheck = 1
BEGIN
GOTO Check_RemoteSvr_Schema
END
Results:
IF EXISTS ( SELECT TOP 1
*
FROM #t_diff )
BEGIN
SET @Is_All_OK = 0
SET @Error_Message = 'Table schema reconciliation between '
+ '' + @@SERVERNAME + ''
+ ' and remote database on '''+@remote_server_name+'''' + CHAR(10)
SET @Error_Message = @Error_Message + 'failed. Please troubleshoot.'
END
ELSE
BEGIN
SET @Is_All_OK = 1
SET @Error_Message = 'All Good!'
END
IF OBJECT_ID('tempdb..#t_seqfloats') IS NOT NULL
BEGIN
DROP TABLE #t_seqfloats
END
IF OBJECT_ID('tempdb..#t_allTblMetadata') IS NOT NULL
BEGIN
DROP TABLE [#t_allTblMetadata]
END
IF OBJECT_ID('tempdb..#t_sql') IS NOT NULL
BEGIN
DROP TABLE [#t_sql]
END
IF OBJECT_ID('tempdb..#t_sql') IS NOT NULL
BEGIN
DROP TABLE [#t_diff]
END
END
Finally, we are ready to load the Tableau PostgreSQL data into the ‘TableauDBCopy’ database tables on the ‘tab’ schema. For that we can use SQL Server Integration Services but since the ‘workgroup’ database is quite small in size and most tables have a primary key defined on them, we can load the data in a sequential order i.e. table by table using a modified version of my database replication stored procedure which I described in one of my previous blog posts HERE. The stored procedure works in a similar fashion to the one described previously but allowances needed to be made in order to enable PostgreSQL and SQL Server data types and certain conventions conformance e.g. certain PostgreSQL reserved words need to be encapsulated in double quotes in the OPENQUERY statements in order to be validated and recognized by SQL Server. Likewise, certain SQL Server reserved words need to be used with square brackets delimiters. To reference those exceptions, I have created two views (downloadable from HERE) which are used in the merging stored procedure to provide greater cross-database compatibility. The code to the stored procedure works on a table-to-table basis but it it’s would not very hard to make it loop through a collection of objects e.g. using a cursor or ‘Foreach Loop’ SSIS transformation to automate a comprehensive data load. If, on the other hand, a much faster, asynchronous load is required you can always check out one of my previous blog posts on parallel SQL statements execution using SQL Server Agent jobs HERE. All the code for the data synchronization across Tableau’s PostgreSQL database and SQL Server instance as well as other T-SQL snippets presented in the post can be downloaded from my OneDrive folder HERE.
Below is a short video depicting how this solution works using both – schema synchronisation and data synchronisation stored procedures.
The ‘workgroup’ database data dictionary with all PostgreSQL objects description can be found HERE.
My name is Martin and this site is a random collection of recipes and reflections about various topics covering information management, data engineering, machine learning, business intelligence and visualisation plus everything else that I fancy to categorise under the 'analytics' umbrella. I'm a native of Poland but since my university days I have lived in Melbourne, Australia and worked as a DBA, developer, data architect, technical lead and team manager. My main interests lie in both, helping clients in technical aspects of information management e.g. data modelling, systems architecture, cloud deployments as well as business-oriented strategies e.g. enterprise data solutions project management, data governance and stewardship, data security and privacy or data monetisation. On the whole, I am very fond of anything closely or remotely related to data and as long as it can be represented as a string of ones and zeros and then analysed and visualised, you've got my attention!
Outside sporadic updates to this site I typically find myself fiddling with data, spending time with my kids or a good book, the gym or watching a good movie while eating Polish sausage with Zubrowka (best served on rocks with apple juice and a lime twist). Please read on and if you find these posts of any interests, don't hesitate to leave me a comment!












Never thought Polybase could be used in this capacity and don't think Microsoft advertised this feature (off-loading DB data as…