Asynchronous SQL Execution via SQL Server Agent Jobs
May 27th, 2015 / No Comments » / by admin
Recently, one of the clients tasked me with creating a data acquisition routine for an externally hosted MySQL database data, a part of a larger ETL solution to merge dispersed data sources into a staging area for further data warehouse processing. The database size was very small i.e. just over a few gigabytes, distributed across around 35 tables with the largest object holding over 15 million records. Microsoft SQL Server 2014 instance served as the local data storage engine and all the code required to be Microsoft dialect of SQL i.e. Transact-SQL, with data flow and execution governed by Integration Services packages (SSIS). The interface to querying MySQL database data was through a linked server set up on the SQL Server instance using Oracle’s ODBC driver, over 100Mbps internet link. The requirements seemed quite easy to accommodate i.e. create a SSIS package to manage data acquisition pipelines, either through a collection of SSIS-specific transformations or T-SQL code. Also, a few preliminary tests showed that the connection speed should be robust enough to copy or even merge the data across source/target without much hassle.
Once the development commenced, I quickly learned that Integration Services may not have been the best tool for the job (more due to the ODBC driver stability rather then SSIS functionality). Regardless of how much reconfiguration and tweaking went into optimising SSIS package to handle moving the data across the linked server connection, the package could not cope with a few of the large tables, continually failing on execution with cryptic messages and confusing error logs. Likewise, running pure SQL MERGE statements often resulted in connection time-outs or buffer overflows, indicating that the ODBC driver was too flaky and unstable to handle long running queries. The only solution that seemed not to throw the connection out of balance was to abandon more convenient ‘upserts’ for truncations and inserts, broken down into multiple statements to dissect the data flow across the network. The less data needed to go through the network as a single transaction the more reliable the transfer was, with one caveat – the largest MySQL database table (15 million records) was taking nearly one hour to read from and insert into the local SQL Server instance. Regardless of how many batches the data acquisition job was comprised of, the performance oscillated around 55 minutes mark – an unacceptable result by both my and the client’s standards, even if proven to solve the reliability issues. As data acquisition failures occurrence increased with the source tables records count (when executed as a single transaction) and breaking it up into multiple batches seemed to provide the needed stability, albeit at the expense of prolonged execution, the one potential solution and a silver bullet to this conundrum was to find a half-point between the two approaches. That compromise turned out to be batch processing (stability) combined with asynchronous, concurrent execution (speed).
Microsoft SQL Server does not offer built-in asynchronous SQL processing – all statements part of a query execute in a sequential, non-parallel fashion. Even when looping through a process using a WHILE statement or a cursor, each SQL statement gets invoked in a synchronous manner. There are different approaches which can help achieving concurrent SQL execution, however, these require either a programming knowledge or a fair amount of inelegant hacking to circumvent this limitation. One simple solution that I found worked really well for my project was to create a number of SQL Server Agent jobs (using T-SQL only), which would get initialised in parallel to dissect the query thus ‘multi-threading’ the whole process and shaving a considerable amount of time off the final execution duration.
Let’s look at an example of two tables placed in two different databases simulating this event – first one containing ten million records of mock data and the second one containing no data which will become the target of the parallel INSERT operation. The following code creates two sample databases with their corresponding objects and populates the source table with dummy data.
--CREATE 'Source' AND 'Target' DATABASES
USE master;
GO
IF DB_ID('SourceDB') IS NOT NULL
BEGIN
ALTER DATABASE SourceDB SET SINGLE_USER
WITH ROLLBACK IMMEDIATE;
DROP DATABASE SourceDB;
END;
GO
CREATE DATABASE SourceDB;
GO
ALTER DATABASE SourceDB SET RECOVERY SIMPLE;
GO
ALTER DATABASE SourceDB
MODIFY FILE
(NAME = SourceDB,
SIZE = 10240MB);
GO
USE master;
GO
IF DB_ID('TargetDB') IS NOT NULL
BEGIN
ALTER DATABASE TargetDB SET SINGLE_USER
WITH ROLLBACK IMMEDIATE;
DROP DATABASE TargetDB;
END;
GO
CREATE DATABASE TargetDB;
GO
ALTER DATABASE TargetDB SET RECOVERY SIMPLE;
GO
ALTER DATABASE TargetDB
MODIFY FILE
(NAME = TargetDB,
SIZE = 10240MB);
GO
--CREATE 'Source' AND 'Target' TABLES
USE SourceDB;
CREATE TABLE dbo.SourceTable
(
ID INT IDENTITY(1, 1) NOT NULL ,
Value1 INT NOT NULL ,
Value2 INT NOT NULL ,
Value3 DECIMAL(10, 2) NOT NULL ,
Value4 DATETIME NOT NULL ,
Value5 DATETIME NOT NULL ,
Value6 NVARCHAR (512) NOT NULL,
Value7 NVARCHAR (512) NOT NULL,
Value8 UNIQUEIDENTIFIER,
CONSTRAINT PK_ID PRIMARY KEY CLUSTERED ( ID ASC )
);
USE TargetDB;
CREATE TABLE dbo.TargetTable
(
ID INT IDENTITY(1, 1) NOT NULL ,
Value1 INT NOT NULL ,
Value2 INT NOT NULL ,
Value3 DECIMAL(10, 2) NOT NULL ,
Value4 DATETIME NOT NULL ,
Value5 DATETIME NOT NULL ,
Value6 NVARCHAR (512) NOT NULL,
Value7 NVARCHAR (512) NOT NULL,
Value8 UNIQUEIDENTIFIER,
CONSTRAINT PK_ID PRIMARY KEY CLUSTERED ( ID ASC )
);
--POPULATE 'SourceTable' WITH TEST DATA
USE SourceDB;
SET NOCOUNT ON;
DECLARE @count INT = 0;
DECLARE @records_to_insert INT = 10000000;
WHILE @count < @records_to_insert
BEGIN
INSERT INTO dbo.SourceTable
( Value1 ,
Value2 ,
Value3 ,
Value4 ,
Value5 ,
Value6 ,
Value7 ,
Value8
)
SELECT 10 * RAND() ,
20 * RAND() ,
10000 * RAND() / 100 ,
DATEADD(ss, @count, SYSDATETIME()) ,
CURRENT_TIMESTAMP ,
REPLICATE(CAST(NEWID() AS NVARCHAR(MAX)),10) ,
REPLICATE(CAST(RAND() AS NVARCHAR(MAX)),10) ,
NEWID();
SET @count = @count + 1;
END;
Next let’s test out sequential INSERT performance, inserting all records from SourceDB database and SourceTable table into TargetDB database and TargetTable table. For this purpose I simply run INSERT statement, coping all the data across with no alterations or changes in the target object generating the following execution plan.
SET STATISTICS TIME ON;
GO
INSERT INTO TargetDB.dbo.TargetTable
( Value1 ,
Value2 ,
Value3 ,
Value4 ,
Value5 ,
Value6 ,
Value7 ,
Value8
)
SELECT Value1 ,
Value2 ,
Value3 ,
Value4 ,
Value5 ,
Value6 ,
Value7 ,
Value8
FROM SourceDB.dbo.SourceTable;
GO
SET STATISTICS TIME OFF;
GO

Given that SQL Server 2014 edition offers some enhancements to SELECT…INTO execution, I think it’s worthwhile to also try it out as an alternative. If there is a provision to create the target table from scratch and the developer has the liberty to execute SELECT…INTO in place of an INSERT statement, Microsoft claims that this improvement will allow it to run in a parallel mode in SQL Server 2014 (as confirmed by the execution plan below), speeding up the execution considerably.
IF OBJECT_ID('TargetDB.dbo.TargetTable', 'U') IS NOT NULL
BEGIN
DROP TABLE TargetDB.dbo.TargetTable
END
SET STATISTICS TIME ON;
GO
SELECT Value1 ,
Value2 ,
Value3 ,
Value4 ,
Value5 ,
Value6 ,
Value7 ,
Value8
INTO TargetDB.dbo.TargetTable
FROM SourceDB.dbo.SourceTable;
GO
SET STATISTICS TIME OFF;
GO
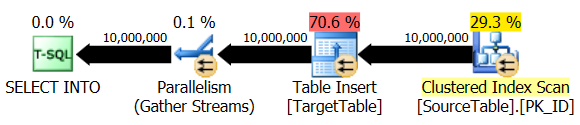
Finally, let look at the solution to enforce parallel queries execution, in this case also INSERT statement by means of ‘spinning up’ multiple SQL Server Agent jobs. The following code creates a stored procedure which ‘dissects’ all source table records into multiple, record-count comparable batches (the exact number controlled by the parameter value passed) and generates SQL Server Agent jobs executing in parallel.
USE [SourceDB]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[usp_asyncTableInsert]
(@Source_DB_Name VARCHAR (128) ,
@Source_DB_Schema_Name VARCHAR (128) ,
@Source_DB_Object_Name VARCHAR (256) ,
@Target_DB_Name VARCHAR (128) ,
@Target_DB_Schema_Name VARCHAR (128) ,
@Target_DB_Object_Name VARCHAR (256) ,
@SQL_Exec_No VARCHAR (10))
AS
BEGIN
SET NOCOUNT ON;
/*
Declare additional variables:
(1) @SQL - stores dynamic SQL string
(2) @Error_Massage - stores error message string
(3) @Is_Debug - stores a binary flag for allowing/disallowing displaying messages during procedure execution
(4) @Check_Count - stores the starting number for the cursor execution loop
(5) @Max_Check_Count - stores the maximum number for the cursor execution loop
*/
DECLARE @SQL NVARCHAR(MAX)
DECLARE @Error_Message VARCHAR (4000)
DECLARE @Is_Debug INT = 1
/*
Create temporary table to hold the ranges of values for dissecting
the 'source' table into semi-equal chunks of data for further processing
*/
IF OBJECT_ID('tempdb..#Ids_Range') IS NOT NULL
BEGIN
DROP TABLE #Ids_Range;
END;
CREATE TABLE #Ids_Range
(
id SMALLINT IDENTITY(1, 1) ,
range_FROM BIGINT ,
range_TO BIGINT
);
/*
Create and populate temporary variables and #Ids_Range temporary table with value ranges
This table contains value ranges i.e. pairs of values which will be used to build the WHERE
clause of the INSERT statment, breaking down all the 'source' records into smaller chunks
*/
SET @SQL = 'DECLARE @R1 INT = (SELECT MIN(ID) AS ID FROM ' +CHAR(13)
SET @SQL = @SQL + ''+@Source_DB_Name+'.'+@Source_DB_Schema_Name+'.'+@Source_DB_Object_Name+')' +CHAR(13)
SET @SQL = @SQL + 'DECLARE @R2 BIGINT = (SELECT (MAX(ID)-MIN(ID)+1)/'+@SQL_Exec_No+' AS ID FROM' +CHAR(13)
SET @SQL = @SQL + ''+@Source_DB_Name+'.'+@Source_DB_Schema_Name+'.'+@Source_DB_Object_Name+')' +CHAR(13)
SET @SQL = @SQL + 'DECLARE @R3 BIGINT = (SELECT MAX(ID) AS ID FROM ' +CHAR(13)
SET @SQL = @SQL + ''+@Source_DB_Name+'.'+@Source_DB_Schema_Name+'.'+@Source_DB_Object_Name+')' +CHAR(13)
SET @SQL = @SQL + 'DECLARE @t int = @r2+@r2+2 ' +CHAR(13)
SET @SQL = @SQL + 'INSERT INTO #Ids_Range ' +CHAR(13)
SET @SQL = @SQL + '(range_FROM, range_to) ' +CHAR(13)
SET @SQL = @SQL + 'SELECT @R1, @R2 ' +CHAR(13)
SET @SQL = @SQL + 'UNION ALL ' +CHAR(13)
SET @SQL = @SQL + 'SELECT @R2+1, @R2+@R2+1 ' +CHAR(13)
SET @SQL = @SQL + 'WHILE @t<=@r3 ' +CHAR(13)
SET @SQL = @SQL + 'BEGIN ' +CHAR(13)
SET @SQL = @SQL + 'INSERT INTO #Ids_Range ' +CHAR(13)
SET @SQL = @SQL + '(range_FROM, range_to) ' +CHAR(13)
SET @SQL = @SQL + 'SELECT @t, CASE WHEN (@t+@r2)>=@r3 THEN @r3 ELSE @t+@r2 END ' +CHAR(13)
SET @SQL = @SQL + 'SET @t = @t+@r2+1 ' +CHAR(13)
SET @SQL = @SQL + 'END' +CHAR(13)
EXEC(@SQL)
/*
Truncate Target table if any data exists
*/
SET @SQL = 'IF EXISTS (SELECT TOP 1 1 FROM ' +CHAR(13)
SET @SQL = @SQL + ''+@Target_DB_Name+'.'+@Target_DB_Schema_Name+'.'+@Target_DB_Object_Name+'' +CHAR(13)
SET @SQL = @SQL + 'WHERE ID IS NOT NULL) BEGIN ' +CHAR(13)
SET @SQL = @SQL + 'TRUNCATE TABLE ' +CHAR(13)
SET @SQL = @SQL + ''+@Target_DB_Name+'.'+@Target_DB_Schema_Name+'.'+@Target_DB_Object_Name+' END' +CHAR(13)
EXEC(@SQL)
/*
Create temporary #Temp_Tbl_AgentJob_Stats table to store SQL Server Agent job
*/
IF OBJECT_ID('tempdb..#Temp_Tbl_AgentJob_Stats') IS NOT NULL
BEGIN
DROP TABLE #Temp_Tbl_AgentJob_Stats;
END;
CREATE TABLE #Temp_Tbl_AgentJob_Stats
(
ID SMALLINT IDENTITY(1, 1) ,
Job_Name VARCHAR(256) ,
Job_Exec_Start_Date DATETIME
);
/*
Create a cursor and a range of variables to define SQL execution string
to create and manage SQL Server Agent jobs (exact count defined by @SQL_Exec_No
varaiable). This SQL splits the INSERT statment into multiple, concurrently-executing
batches which run in asunchronous mode. This part of code also manages stopping
and deleting already created jobs in case a re-run is required as well as deleting
SQL Agent jobs created as part of this process on successful completion
*/
IF CURSOR_STATUS('global', 'sp_cursor') >= -1
BEGIN
DEALLOCATE sp_cursor
END
DECLARE @z INT
DECLARE @err INT
DECLARE sp_cursor CURSOR
FOR
SELECT id FROM #ids_range
SELECT @err = @@error
IF @err <> 0
BEGIN
DEALLOCATE sp_cursor
RETURN @err
END
OPEN sp_cursor
FETCH NEXT
FROM sp_cursor INTO @z
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE
@range_from VARCHAR(10) = (SELECT CAST(range_FROM AS VARCHAR(10)) FROM #ids_range where id = @z),
@range_to VARCHAR(10) = (SELECT CAST(range_TO AS VARCHAR(10)) FROM #ids_range where id = @z),
@job_name VARCHAR (256) = 'Temp_'+UPPER(LEFT(@Target_DB_Object_Name,1))+LOWER(SUBSTRING(@Target_DB_Object_Name,2,LEN(@Target_DB_Object_Name)))+'_TableSync_'+'AsyncJob'+'_'+CAST(@z AS VARCHAR (20)),
@job_owner VARCHAR (256) = 'sa'
DECLARE
@sql_job_delete VARCHAR (400) = 'EXEC msdb..sp_delete_job @job_name='''''+@job_name+''''''
DECLARE
@sql_job NVARCHAR(MAX) =
'INSERT INTO TargetDB.dbo.TargetTable
(Value1, Value2, Value3, Value4, Value5, Value6, Value7,Value8)
SELECT Value1, Value2, Value3, Value4, Value5, Value6, Value7, Value8
FROM SourceDB.dbo.SourceTable
WHERE id >= '+cast(@range_FROM as varchar (20))+' AND ID <= '+cast(@range_to as varchar(20))+''
SET @SQL = 'IF EXISTS'
SET @SQL = @SQL + '(SELECT TOP 1 1 FROM msdb..sysjobs_view job JOIN msdb.dbo.sysjobactivity activity' +CHAR(13)
SET @SQL = @SQL + 'ON job.job_id = activity.job_id WHERE job.name = N'''+@job_name+'''' +CHAR(13)
SET @SQL = @SQL + 'AND activity.start_execution_date IS NOT NULL AND activity.stop_execution_date IS NULL)' +CHAR(13)
SET @SQL = @SQL + 'BEGIN' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_stop_job @job_name=N'''+@job_name+''';' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_delete_job @job_name=N'''+@job_name+''', @delete_unused_schedule=1' +CHAR(13)
SET @SQL = @SQL + 'END' +CHAR(13)
SET @SQL = @SQL + 'IF EXISTS' +CHAR(13)
SET @SQL = @SQL + '(SELECT TOP 1 1 FROM msdb..sysjobs_view job JOIN msdb.dbo.sysjobactivity activity' +CHAR(13)
SET @SQL = @SQL + 'ON job.job_id = activity.job_id WHERE job.name = N'''+@job_name+'''' +CHAR(13)
SET @SQL = @SQL + 'AND activity.start_execution_date IS NULL AND activity.stop_execution_date IS NOT NULL)' +CHAR(13)
SET @SQL = @SQL + 'BEGIN' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_delete_job @job_name=N'''+@job_name+''', @delete_unused_schedule=1' +CHAR(13)
SET @SQL = @SQL + 'END' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_add_job '''+@job_name+''', @owner_login_name= '''+@job_owner+''';' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_add_jobserver @job_name= '''+@job_name+''';' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_add_jobstep @job_name='''+@job_name+''', @step_name= ''Step1'', ' +CHAR(13)
SET @SQL = @SQL + '@command = '''+@sql_job+''', @database_name = '''+@Target_DB_Name+''', @on_success_action = 3;' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_add_jobstep @job_name = '''+@job_name+''', @step_name= ''Step2'',' +CHAR(13)
SET @SQL = @SQL + '@command = '''+@sql_job_delete+'''' +CHAR(13)
SET @SQL = @SQL + 'EXEC msdb..sp_start_job @job_name= '''+@job_name+'''' +CHAR(13)
+REPLICATE(CHAR(13),4)
EXEC (@SQL)
/*
Wait for the job to register in the SQL Server metadata sys views
*/
WAITFOR DELAY '00:00:01'
INSERT INTO #Temp_Tbl_AgentJob_Stats
(Job_Name, Job_Exec_Start_Date)
SELECT job.Name, activity.start_execution_date
FROM msdb.dbo.sysjobs_view job
INNER JOIN msdb.dbo.sysjobactivity activity
ON job.job_id = activity.job_id
WHERE job.name = @job_name
FETCH NEXT
FROM sp_cursor INTO @z
END
CLOSE sp_cursor
DEALLOCATE sp_cursor
END
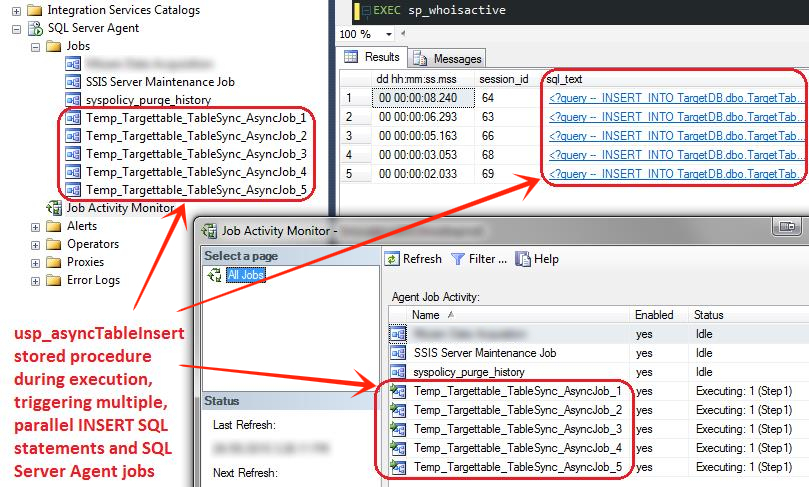
Running the stored procedure (with the prior target table truncation) will generate as many INSERT statements as specified by the value of @SQL_Exec_No parameter passed. When executed, we can observe multiple instances of the SQL statement inserting records falling between certain ID ranges, here shown as an output from Adam Mechanic’s sp_whoisactive stored procedure as well as SQL Server Agent jobs view. Given that the value of @SQL_Exec_No parameter was 5, there were five instances of this statement running in parallel as per image below.
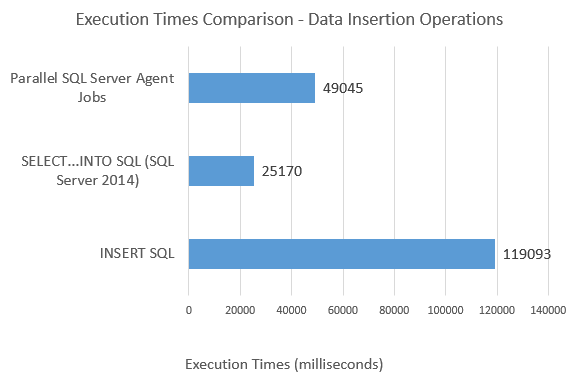
Looking at the execution times (run on my trusty Lenovo x240 laptop) and the differences between individual approaches, it is evident that the enhancements made in SQL Server 2014 edition regarding parallelisation of SELECT…INTO statement are profound, however, given the optimizer taking advantage of multiple cores I also noticed a large spike in CPU utilization i.e. 20% for INSERT and 90% for SELECT…INTO. If, on the other hand, SELECT…INTO is not an option and a substantial amount of data is to be copied as part of a long-running transaction, asynchronous execution via SQL Server Agent jobs seems like a good solution.
I have only scratched the surface of how SQL Server Agent jobs can facilitate workload distribution across the server to speed up data processing and take advantage of SQL Server available resource pool. There are other ways to achieve the same result but given the simplicity and the ease of development/provisioning I think that taking advantage of this technique can provide a quick and robust workaround to parallel SQL statements execution with SQL Server.
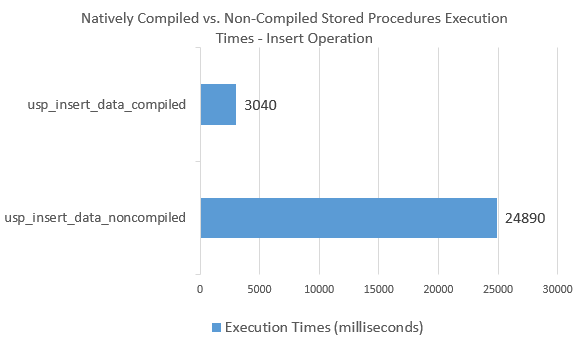



Never thought Polybase could be used in this capacity and don't think Microsoft advertised this feature (off-loading DB data as…