November 7th, 2014 / 3 Comments » / by admin
In PART 1 of this series I analysed the execution error tracking database schema as well as the code for ‘scraping’ SQL Server metadata in order to populate the database tables with instance, database, schema and objects-specific information. In this part I will briefly describe SQL code modifications which are applied the original stored procedure (see PART 1) to customize it in order to handle metadata changes as well as the actual implementation and error-logging mechanism during package/stored procedure execution. Also, all the code and any additional files presented in this and previous part can be downloaded from my OneDrive folder HERE.
Before I get into the nuts and bolts on how to log into LogSSISErrors_Error table, which in this case will form the base for all errors entries, let create a sample database, schema, table and stored procedure containing an error-invoking code i.e. executing division by 0. This stored procedure, which will later be appended with additional error-handling code it in order to capture and log execution error(s) through TRY/CATCH T-SQL, will be used as the basis for demonstrating error capturing mechanism.
USE master
IF EXISTS ( SELECT TOP 1
*
FROM sys.databases
WHERE name = 'TestDB' )
DROP DATABASE TestDB
CREATE DATABASE TestDB
GO
USE TestDB
EXEC sp_executesql N'CREATE SCHEMA dummyschema;';
GO
CREATE TABLE dummyschema.DummyTable
(
ID INT IDENTITY(1, 1) ,
Column1 VARCHAR(56) ,
Column2 VARCHAR(56) ,
Column3 VARCHAR(56)
)
INSERT INTO dummyschema.DummyTable
( Column1 ,
Column2 ,
Column3
)
SELECT 'dummy value1' ,
'dummy value1' ,
'dummy value1'
UNION ALL
SELECT 'dummy value1' ,
'dummy value1' ,
'dummy value1'
UNION ALL
SELECT 'dummy value1' ,
'dummy value1' ,
'dummy value1'
GO
CREATE PROCEDURE dummyschema.usp_DummySP
(
@ExecutionInstanceGUID UNIQUEIDENTIFIER ,
@PackageName NVARCHAR(256)
)
AS
BEGIN
INSERT INTO TestDB.dummyschema.DummyTable
( Column1 )
SELECT 1 / 0
END
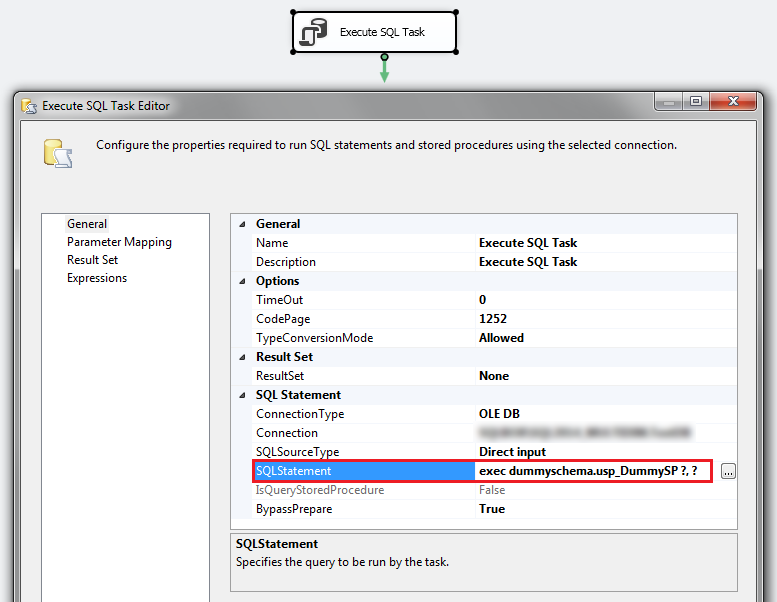
As this database is supposed to be working mainly in conjunction with an SSIS package (standalone stored procedure execution error capture is also fine but in this case the SSIS component would have to be omitted and replaced with a place-holder value), I have also created a sample package used primarily to trigger stored procedure execution, with a couple of system variables capturing package execution instance GUID identifier and package name metadata. This package needs to be saved somewhere on the C:\ drive for the metadata updating stored procedure to find the relevant info and populate LogSSISErrors_Package table accordingly.

Most of that code from PART 1 is also applicable to maintaining the error tracking database by means of modifying INSERT statements into MERGE statements, thus allowing for applying changes to already existing data and inserting new records. The core difference is that in PART 1 all AdminSQL database objects required to be (re)created before we could proceed with SQL Server instance metadata analysis and capture thus making its execution only applicable to a new environment, where the database needed to be rebuilt from scratch. Once SQLAdmin database has been created and initially populated with the code from PART 1, any subsequent execution should account for updates and new data inserts only which are implemented by means of subtle changes to the stored procedure code, mainly replacing INSERTS with MERGE T-SQL. Below is a couple of examples where the code from PART 1 stored procedure was replaced with MERGE SQL statements with the complete code available for download from HERE.
-------------------------------------------------------------------------------------------------------
--Update LogSSISErrors_Schema table
-------------------------------------------------------------------------------------------------------
MERGE INTO AdminDBA.dbo.LogSSISErrors_Schema AS t
USING
( SELECT DISTINCT
db.ID AS ID ,
meta.SchemaID AS SchemaID ,
meta.SchemaName AS SchemaName ,
meta.SchemaOwner AS SchemaOwner ,
1 AS CurrentlyUsed
FROM @EnumDBMeta meta
JOIN AdminDBA.dbo.LogSSISErrors_DB db ON meta.DBName = db.DBName
WHERE db.CurrentlyUsed = 1
) s
ON ( t.SchemaName = s.SchemaName
AND s.ID = t.FKDBID
)
WHEN MATCHED THEN
UPDATE SET [SchemaID] = s.[SchemaID] ,
[SchemaName] = s.[SchemaName] ,
[SchemaOwner] = s.[SchemaOwner] ,
[CurrentlyUsed] = s.[CurrentlyUsed]
WHEN NOT MATCHED THEN
INSERT ( [FKDBID] ,
[SchemaID] ,
[SchemaName] ,
[SchemaOwner] ,
[CurrentlyUsed]
)
VALUES ( s.[ID] ,
s.[SchemaID] ,
s.[SchemaName] ,
s.[SchemaOwner] ,
s.[CurrentlyUsed]
)
WHEN NOT MATCHED BY SOURCE THEN
UPDATE SET [CurrentlyUsed] = 0;
-------------------------------------------------------------------------------------------------------
--Update LogSSISErrors_Process table
-------------------------------------------------------------------------------------------------------
MERGE INTO AdminDBA.dbo.LogSSISErrors_Process AS t
USING
( SELECT DISTINCT
meta.ProcessObjectID ,
meta.ProcessObjectName ,
sch.ID ,
1 AS CurrentlyUsed
FROM @EnumDBMeta meta
JOIN AdminDBA.dbo.LogSSISErrors_Schema AS sch ON sch.SchemaName = meta.SchemaName
AND meta.ProcessObjectSchemaID = sch.SchemaID
JOIN AdminDBA.dbo.LogSSISErrors_DB db ON meta.DBName = db.DBName
AND sch.FKDBID = db.ID
WHERE sch.CurrentlyUsed = 1
AND db.CurrentlyUsed = 1
AND ProcessObjectType IN ( 'SQL Stored Procedure',
'Aggregate Function',
'SQL DML Trigger',
'Assembly DML Trigger',
'Extended Stored Procedure',
'Assembly Stored Procedure',
'Replication Filter Procedure',
'Assembly Scalar Function',
'SQL Scalar Function' )
) s
ON ( t.ProcessName = s.ProcessObjectName
AND s.ID = t.FKSchemaID
)
WHEN MATCHED THEN
UPDATE SET [ProcessID] = s.ProcessObjectID ,
[ProcessName] = s.ProcessObjectName ,
[CurrentlyUsed] = s.[CurrentlyUsed]
WHEN NOT MATCHED THEN
INSERT ( [ProcessID] ,
[ProcessName] ,
[FKSchemaID] ,
[CurrentlyUsed]
)
VALUES ( s.ProcessObjectID ,
s.ProcessObjectName ,
s.ID ,
s.[CurrentlyUsed]
)
WHEN NOT MATCHED BY SOURCE THEN
UPDATE SET [CurrentlyUsed] = 0;
Upon execution of the modified stored procedure from PART 1, the code should pick up our new database, schema, table and stored procedure which in turn should be reflected in AdminDBA database tables’ entries i.e. LogSSISErrors_Package, LogSSISErrors_DB, LogSSISErrors_Schema, LogSSISErrors_Object, and LogSSISErrors_Process tables as per the image below.

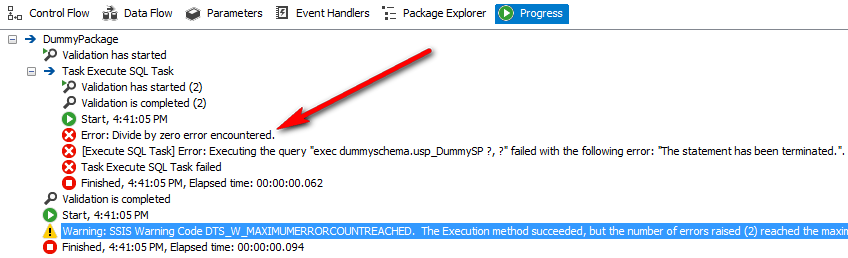
When trying to execute the package, an error message is thrown due to T-SQL in usp_DummySP stored procedure attempting to divide by zero, which is in accordance with our expectations. The stored procedure does not contain error handling code therefore division by zero operation is handled by halting execution and returning the error message back to Execution Results view as per below. Also, the package invoking the stored procedure needs to be saved
Now let’s alter the dummyschema.usp_DummySP stored procedure’s code to allow error capture and handling capabilities. By default SQL Server has a number of system functions available to troubleshoot execution flow and expose error details. In combination with SSIS package system parameters i.e. execution instance GUID and package name, we can capture and log those details in LogSSISErrors_Error table, referencing other tables which provide other metadata details for richer analysis.
The following ALTER SQL statements implements TRY/CATCH SQL Server error handling capabilities and allows for logging execution issues e.g. dividing by zero in the highlighted SELECT statement section.
USE [TestDB]
GO
ALTER PROCEDURE [dummyschema].[usp_DummySP]
(
@ExecutionInstanceGUID UNIQUEIDENTIFIER ,
@PackageName NVARCHAR(256)
)
AS
BEGIN
BEGIN TRY
BEGIN TRANSACTION
INSERT INTO TestDB.dummyschema.DummyTable
( Column1 )
SELECT 1 / 0
COMMIT TRANSACTION
END TRY
BEGIN CATCH
ROLLBACK TRANSACTION;
WITH TempErr ( [ErrorNumber], [ErrorSeverity], [ErrorState], [ErrorLine], [ErrorMessage], [ErrorDateTime],
[LoginName], [UserName], PackageName, [ObjectID], [ProcessID], [ExecutionInstanceGUID], [DBName] )
AS ( SELECT ERROR_NUMBER() AS ErrorNumber ,
ERROR_SEVERITY() AS ErrorSeverity ,
ERROR_STATE() AS ErrorState ,
ERROR_LINE() AS ErrorLine ,
ERROR_MESSAGE() AS ErrorMessage ,
SYSDATETIME() AS ErrorDateTime ,
SYSTEM_USER AS LoginName ,
USER_NAME() AS UserName ,
@PackageName ,
OBJECT_ID('TestDB.dummyschema.DummyTable') AS ObjectID ,
( SELECT a.objectid
FROM sys.dm_exec_requests r
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) a
WHERE session_id = @@spid
) AS ProcessID ,
@ExecutionInstanceGUID AS ExecutionInstanceGUID ,
DB_NAME() AS DatabaseName
)
INSERT INTO AdminDBA.dbo.LogSSISErrors_Error
( [ErrorNumber] ,
[ErrorSeverity] ,
[ErrorState] ,
[ErrorLine] ,
[ErrorMessage] ,
[ErrorDateTime] ,
[FKLoginID] ,
[FKUserID] ,
[FKPackageID] ,
[FKObjectID] ,
[FKProcessID] ,
[ExecutionInstanceGUID]
)
SELECT ErrorNumber = COALESCE(err.ErrorNumber, -1) ,
ErrorSeverity = COALESCE(err.[ErrorSeverity], -1) ,
ErrorState = COALESCE(err.[ErrorState], -1) ,
ErrorLine = COALESCE(err.[ErrorLine], -1) ,
ErrorMessage = COALESCE(err.[ErrorMessage], 'Unknown') ,
ErrorDateTime = ErrorDateTime ,
FKLoginID = src_login.ID ,
FKUserID = src_user.ID ,
[FKPackageID] = src_package.ID ,
[FKObjectID] = src_object.ID ,
[FKProcessID] = src_process.ID ,
[ExecutionInstanceGUID] = err.ExecutionInstanceGUID
FROM TempErr err
LEFT JOIN AdminDBA.dbo.LogSSISErrors_Login src_login
ON err.LoginName = src_login.LoginName
LEFT JOIN AdminDBA.dbo.LogSSISErrors_User src_user
ON err.UserName = src_user.UserName
AND src_user.FKDBID =
(SELECT ID
FROM AdminDBA.dbo.LogSSISErrors_DB db
WHERE db.DBName = err.DBName)
LEFT JOIN AdminDBA.dbo.LogSSISErrors_Package src_package
ON err.PackageName = (LEFT(src_package.PackageName, CHARINDEX('.', src_package.PackageName) - 1))
LEFT JOIN AdminDBA.dbo.LogSSISErrors_Object src_object
ON err.ObjectID = src_object.ObjectID
LEFT JOIN AdminDBA.dbo.LogSSISErrors_Process src_process
ON err.ProcessID = src_process.ProcessID
--WHERE
--src_login.CurrentlyUsed = 1 AND
--src_user.CurrentlyUsed = 1 AND
--src_package.CurrentlyUsed = 1 AND
--src_object.CurrentlyUsed = 1 AND
--src_process.CurrentlyUsed = 1
END CATCH
END
Once altered, the stored procedure executed through the package will write into the table if BEGIN CATCH/END CATCH statement is invoked as per image below.
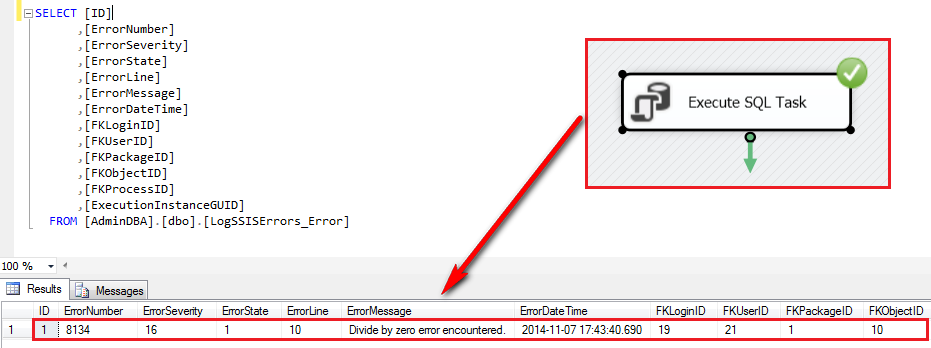
Now that error details have been inserted into our AdminDBA database table, we can query the data across all related tables if more comprehensive view is required e.g. schema, database etc. Below sample query sets up a view which can be used through a reporting platform of choice to quickly identify transactional SSIS execution issues or perform a quick analysis on errors and their related objects, schemas, processes, packages etc.
CREATE VIEW [dbo].[vw_LogSSISErrors_CoreData] AS
SELECT dbo.LogSSISErrors_Error.ID AS Error_ID ,
dbo.LogSSISErrors_Error.ErrorNumber ,
dbo.LogSSISErrors_Error.ErrorSeverity ,
dbo.LogSSISErrors_Error.ErrorState ,
dbo.LogSSISErrors_Error.ErrorLine ,
dbo.LogSSISErrors_Error.ErrorMessage ,
dbo.LogSSISErrors_Error.ErrorDateTime ,
dbo.LogSSISErrors_Object.ObjectName ,
dbo.LogSSISErrors_Object.ObjectType ,
dbo.LogSSISErrors_Object.ObjectDescription ,
dbo.LogSSISErrors_Schema.SchemaName AS ObjectSchemaName ,
dbo.LogSSISErrors_Process.ProcessName ,
LogSSISErrors_Schema_1.SchemaName AS ProcessSchemaName ,
dbo.LogSSISErrors_Package.PackageName ,
dbo.LogSSISErrors_User.UserName ,
dbo.LogSSISErrors_Login.LoginName ,
dbo.LogSSISErrors_DB.DBName ,
dbo.LogSSISErrors_Instance.InstanceName
FROM dbo.LogSSISErrors_Error
INNER JOIN dbo.LogSSISErrors_Object ON dbo.LogSSISErrors_Error.FKObjectID = dbo.LogSSISErrors_Object.ID
INNER JOIN dbo.LogSSISErrors_Schema ON dbo.LogSSISErrors_Object.FKSchemaID = dbo.LogSSISErrors_Schema.ID
INNER JOIN dbo.LogSSISErrors_DB ON dbo.LogSSISErrors_Schema.FKDBID = dbo.LogSSISErrors_DB.ID
INNER JOIN dbo.LogSSISErrors_Instance ON dbo.LogSSISErrors_DB.FKInstanceID = dbo.LogSSISErrors_Instance.ID
INNER JOIN dbo.LogSSISErrors_Package ON dbo.LogSSISErrors_Error.FKPackageID = dbo.LogSSISErrors_Package.ID
INNER JOIN dbo.LogSSISErrors_Process ON dbo.LogSSISErrors_Error.FKProcessID = dbo.LogSSISErrors_Process.ID
INNER JOIN dbo.LogSSISErrors_User ON dbo.LogSSISErrors_Error.FKUserID = dbo.LogSSISErrors_User.ID
AND dbo.LogSSISErrors_DB.ID = dbo.LogSSISErrors_User.FKDBID
INNER JOIN dbo.LogSSISErrors_Schema AS LogSSISErrors_Schema_1 ON dbo.LogSSISErrors_DB.ID = LogSSISErrors_Schema_1.FKDBID
AND dbo.LogSSISErrors_Process.FKSchemaID = LogSSISErrors_Schema_1.ID
INNER JOIN dbo.LogSSISErrors_Login ON dbo.LogSSISErrors_Error.FKLoginID = dbo.LogSSISErrors_Login.ID;
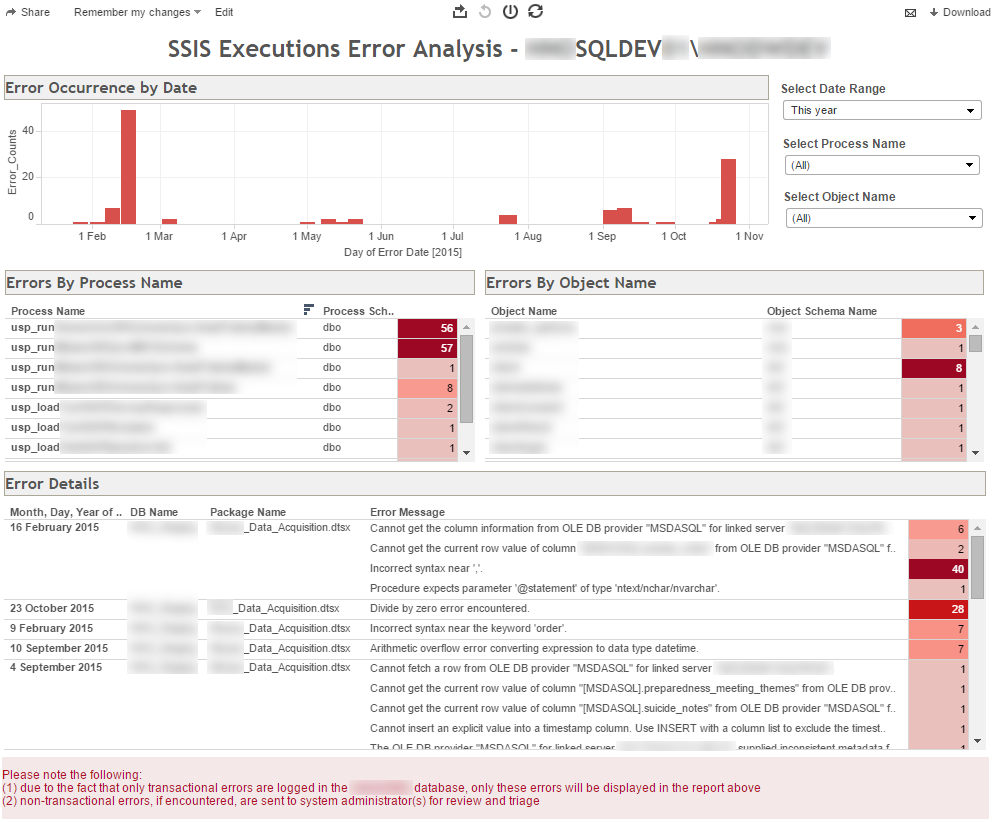
Based on the output of this code, we can set up a simple dashboard (Tableau in this case) to provide us with some core metrics on the ETL issues that require addressing at a glance (click on image to enlarge).
You can also download all the code samples, SSIS package solution files and database schema model (saved in a format compatible with Navicat Data Modeler database design tool) from my OneDrive folder HERE.
Posted in: How To's, SQL
Tags: Data Modelling, SQL, SQL Server
November 5th, 2014 / 2 Comments » / by admin
Introduction
Two part series (second part can be found HERE) on how to create and implement an ETL execution error capturing database (schema model, SQL code, implementation etc.) based on Microsoft SQL Server stored procedures default error handling capabilities.
TL;DR Version
My last client engagement required me to create an ETL errors tracking solution which would serve as a central repository for all data related to SSIS packages execution failures. Given the initial scope and assumptions pointed to a small project size, thus the number of ETL routines involved kept at a minimum, my first intention was to build a single table encompassing all key information related to the package metadata and execution state. However, as the project grew in size, execs started to demand richer, more detailed data and the constricting schema of a single table became too evident, I decided to expand it with a proper relational database schema with additional metadata attributes at all common data-grouping hierarchies i.e. instance, database, schema and objects. In addition, I have also extracted metadata pertaining to users, logins and packages which complemented the whole data set with a comprehensive suite of variables for error-related analysis. Please note that this model and the subsequently discussed implementation is based primarily on capturing errors resulting from stored procedures execution as per my project demands. Since version 2012, SQL Server included the SSISDB catalog as the central point for working with Integration Services (SSIS) projects deployed to the Integration Services server which contains a rich set of data for all execution eventualities and should be treated as a default logging option for comprehensive SSIS runtime events capture.
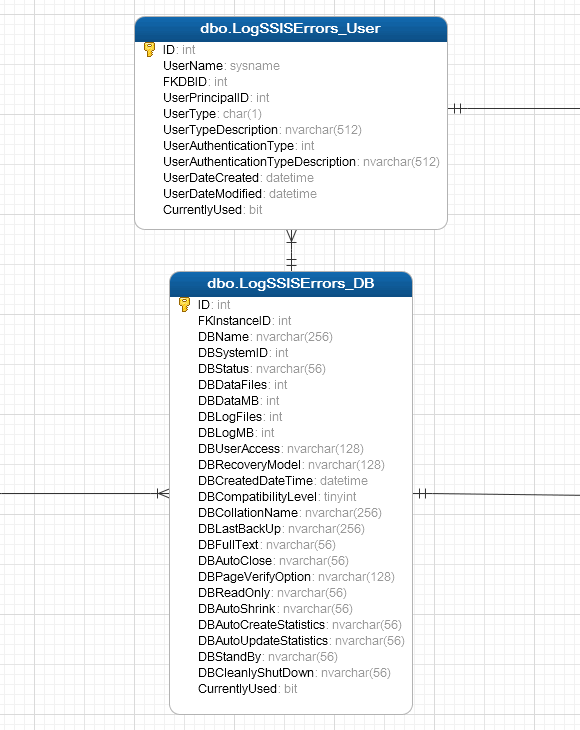
Below is a breakdown of a database schema model which accounts for most of the database-related objects as well as some handy information on individual packages, logins and users. First up, we have instance and database data specific tables – LogSSISErrors_Instance and LogSSISErrors_DB – in a one-to-many relationship i.e. one SQL Server instance to multiple databases.

As each database can have multiple schemas, LogSSISErrors_DB has a one-to-many relationship to LogSSISErrors_Schema table, which in turn can be further related to LogSSISErrors_Object and LogSSISErrors_Process tables, each storing object-level data. The only distinction between ‘Object’ and ‘Process’ specific tables is the fact that ‘Object’ table stores table and view metadata whereas ‘Process’ table is concerned with stored procedures, assemblies, functions and triggers, even though on the database level they are all technically treated as objects.

Both, LogSSISErrors_Object and LogSSISErrors_Process have a one-to-many relationship with LogSSISErrors_Error table – the centrepiece of all the logging activities. LogSSISErrors_Error table is also linked up with LogSSISErrors_User, LogSSISErrors_Package and LogSSISErrors_Login tables, storing users, local SSIS packages and logins metadata.

LogSSISErrors_user table is also connected to LogSSISErrors_DB table as one database can have multiple users created against it.
Full entity relational diagram for AdminDBA is as per the image below.
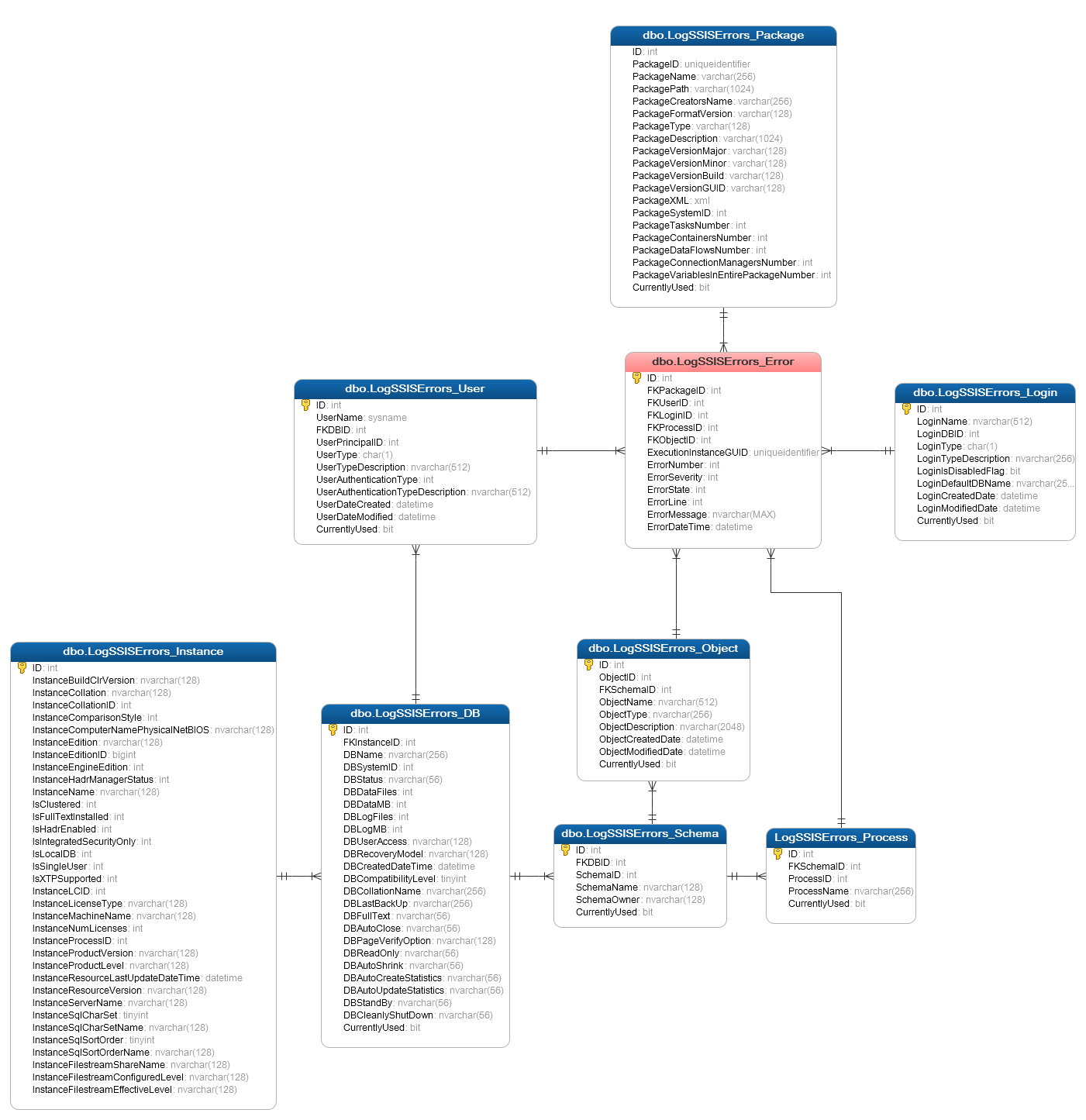
All the data represented by the above schema, with the exception of LogSSISErrors_Package table entries, should be available by querying either catalog views, information schema views or system stored procedures/functions. Most of the tables names are self-explanatory and can be easily referred back to the function they play and relevant metadata information. In case of LogSSISErrors_Process and LogSSISError_Object, these tables’ data comes from the same query with the distinction made on the object type i.e. view and tables, whereas stored procedures are bucketed as processes (even though technically they are objects too), thus placed in the LogSSISErrors_Process table. In case of LogSSISErrors_Package table, the package metadata is not stored on the server level but can be sourced from a .dtsx file using T-SQL. This part of solution was made available thanks to Jamie Thompson’s scripts which you can read about in detail in his post HERE, I simply adopted his technique for my solution.
The script used to create all database objects and populate those with SQL Server instance metadata is close to 1800 lines long so in this post I’ll only go through sections of it, skipping all the boilerplate SQL; however, a full working version is available for download from my OneDrive folder HERE. The script is divided into a few sections, main parts being AdminDBA database metadata collection for subsequent objects recreation and second part determined by a conditional logic where a counts of foreign key constraints and a count of tables from two table variables created is compared.
First part creates two table variables storing objects AdminDBA objects metadata and foreign key constraints referencing individual tables. If those tables have already been created and relationships exist, than the rest of the script utilizes this metadata in subsequent execution. The following T-SQL generates table variables and their content.
DECLARE @TempFKs TABLE
(
ID INT IDENTITY(1, 1)
NOT NULL ,
Foreign_Key_Name VARCHAR(512) ,
Parent_Object_Name VARCHAR(256) ,
Referenced_Object_Name VARCHAR(256) ,
Parent_Column_Name VARCHAR(256) ,
Referenced_Column_Name VARCHAR(256)
)
INSERT INTO @TempFKs
( Foreign_Key_Name ,
Parent_Object_Name ,
Referenced_Object_Name ,
Parent_Column_Name ,
Referenced_Column_Name
)
SELECT fk.name AS foreign_key_name ,
po.name AS parent_object_name ,
ro.name AS referenced_object_name ,
pc.name AS parent_column_name ,
rc.name AS referenced_column_name
FROM sys.foreign_key_columns fc
JOIN sys.columns pc ON pc.column_id = parent_column_id
AND parent_object_id = pc.object_id
JOIN sys.columns rc ON rc.column_id = referenced_column_id
AND referenced_object_id = rc.object_id
JOIN sys.objects po ON po.object_id = pc.object_id
JOIN sys.objects ro ON ro.object_id = rc.object_id
JOIN sys.foreign_keys fk ON fk.object_id = fc.constraint_object_id
WHERE ro.type = 'U'
AND fk.type = 'F'
DECLARE @TempTbls TABLE
(
ID INT IDENTITY(1, 1)
NOT NULL ,
Table_Name VARCHAR(128) NOT NULL ,
Table_Schema_Definition VARCHAR(MAX) NOT NULL
)
INSERT INTO @TempTbls
( Table_Name ,
Table_Schema_Definition
)
SELECT so.name AS Table_Name ,
'create table [' + so.name + '] (' + STUFF(o.list, LEN(o.list),
1, '') + ')'
+ CASE WHEN tc.CONSTRAINT_NAME IS NULL THEN ''
ELSE 'ALTER TABLE ' + so.name + ' ADD CONSTRAINT '
+ tc.CONSTRAINT_NAME + ' PRIMARY KEY ' + ' ('
+ LEFT(j.list, LEN(j.list) - 1) + ')'
END AS Table_Schema_Definition
FROM sysobjects so
CROSS APPLY ( SELECT ' [' + COLUMN_NAME + '] ' + DATA_TYPE
+ CASE DATA_TYPE
WHEN 'sql_variant' THEN ''
WHEN 'text' THEN ''
WHEN 'ntext' THEN ''
WHEN 'xml' THEN ''
WHEN 'decimal'
THEN '('
+ CAST(NUMERIC_PRECISION AS VARCHAR)
+ ', '
+ CAST(NUMERIC_SCALE AS VARCHAR)
+ ')'
ELSE COALESCE('('
+ CASE
WHEN CHARACTER_MAXIMUM_LENGTH = -1
THEN 'MAX'
ELSE CAST(CHARACTER_MAXIMUM_LENGTH AS VARCHAR)
END + ')', '')
END + ' '
+ CASE WHEN EXISTS ( SELECT
id
FROM
syscolumns
WHERE
OBJECT_NAME(id) = so.name
AND name = column_name
AND COLUMNPROPERTY(id,
name,
'IsIdentity') = 1 )
THEN 'IDENTITY('
+ CAST(IDENT_SEED(so.name) AS VARCHAR)
+ ','
+ CAST(IDENT_INCR(so.name) AS VARCHAR)
+ ')'
ELSE ''
END + ' '
+ ( CASE WHEN IS_NULLABLE = 'No'
THEN 'NOT '
ELSE ''
END ) + 'NULL '
+ CASE WHEN INFORMATION_SCHEMA.COLUMNS.COLUMN_DEFAULT IS NOT NULL
THEN 'DEFAULT '
+ INFORMATION_SCHEMA.COLUMNS.COLUMN_DEFAULT
ELSE ''
END + ', '
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = so.name
ORDER BY ORDINAL_POSITION
FOR
XML PATH('')
) o ( list )
LEFT JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS tc ON tc.TABLE_NAME = so.name
AND tc.CONSTRAINT_TYPE = 'PRIMARY KEY'
CROSS APPLY ( SELECT '[' + COLUMN_NAME + '], '
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE kcu
WHERE kcu.CONSTRAINT_NAME = tc.CONSTRAINT_NAME
ORDER BY ORDINAL_POSITION
FOR
XML PATH('')
) j ( list )
WHERE xtype = 'U'
AND name NOT IN ( 'dtproperties' )
By design, after the the database and objects have been (re)created, the number of foreign key constraints should be one fewer than the number of tables. The below piece of SQL compares the counts of foreign key constraints and the count of tables from two table variables at which point one of the two possible scenarios can be triggered – if the count is comparable than the objects are re-created using the data encapsulated in table variables which already store DDL code for individual tables as well as foreign key constraints. If, on the other hand, the count is not comparable, a different part of stored procedure gets executed, this time responsible for recreating objects based on the hard-coded DDL statements and foreign key constraints.
IF NOT EXISTS ( SELECT COUNT(*) - 1 AS ct
FROM @TempFKs a
EXCEPT
SELECT COUNT(*)
FROM @TempTbls b )
AND EXISTS ( SELECT TOP 1 1 FROM @TempTbls )
Most of the SQL Server databases’ metadata comes from storing the results of the below query which extracts database, schema and objects information for each database and temporarily stores it in a table variable.
SET @SQL = N'';
SELECT
@SQL = @SQL + ' UNION ALL
SELECT
[database] = ''' + name + ''',
[schema] = s.name COLLATE Latin1_General_CI_AI,
[schemaid] = s.schema_id,
[schemaowner] = dp.name COLLATE Latin1_General_CI_AI,
[processobjectname] = ob.name COLLATE Latin1_General_CI_AI,
[processobjectid] = ob.object_id,
[processobjectschemaid] = ob.schema_id,
[ProcessObjectDescription] = NULL,
[processobjecttype] = CASE
WHEN ob.type = ''AF'' THEN ''Aggregate Function''
WHEN ob.type = ''C'' THEN ''Check Constraint''
WHEN ob.type = ''D'' THEN ''Default Constraint''
WHEN ob.type = ''F'' THEN ''Foreign Key Constraint''
WHEN ob.type = ''FN'' THEN ''SQL Scalar Function''
WHEN ob.type = ''FS'' THEN ''Assembly Scalar Function''
WHEN ob.type = ''FT'' THEN ''Assembly Table Valued Function''
WHEN ob.type = ''IF'' THEN ''SQL Inline Table-valued Function''
WHEN ob.type = ''IT'' THEN ''Internal Table''
WHEN ob.type = ''P'' THEN ''SQL Stored Procedure''
WHEN ob.type = ''PC'' THEN ''Assembly Stored Procedure''
WHEN ob.type = ''PG'' THEN ''Plan Guide''
WHEN ob.type = ''PK'' THEN ''Primary Key Constraint''
WHEN ob.type = ''R'' THEN ''Rule''
WHEN ob.type = ''RF'' THEN ''Replication Filter Procedure''
WHEN ob.type = ''S'' THEN ''System Base Table''
WHEN ob.type = ''SN'' THEN ''Synonym''
WHEN ob.type = ''SO'' THEN ''Sequence Object''
WHEN ob.type = ''SQ'' THEN ''Service Queue''
WHEN ob.type = ''TA'' THEN ''Assembly DML Trigger''
WHEN ob.type = ''TF'' THEN ''SQL Table Table Valued Function''
WHEN ob.type = ''TR'' THEN ''SQL DML Trigger''
WHEN ob.type = ''TT'' THEN ''Table Type''
WHEN ob.type = ''U'' THEN ''User Defined Table''
WHEN ob.type = ''UQ'' THEN ''Unique Constraint''
WHEN ob.type = ''V'' THEN ''View''
WHEN ob.type = ''X'' THEN ''Extended Stored Procedure''
ELSE ''Unknown Object Type''
END,
[createdate] = CAST(ob.create_date as date),
[modifieddate] = CAST(ob.modify_date as date)
FROM ' + QUOTENAME(name) + '.sys.schemas AS s
INNER JOIN ' + QUOTENAME(name)
+ '.sys.database_principals dp
on s.principal_id = dp.principal_id
INNER JOIN ' + QUOTENAME(name) + '.sys.objects AS ob
ON s.[schema_id] = ob.[schema_id]
where s.name <> ''sys'''
FROM sys.databases
WHERE database_id > 4
AND name NOT IN ( 'ReportServer$SQL2014_MULTIDIM',
'ReportServer$SQL2014_MULTIDIMTempDB' );
SET @SQL = @SQL + N' ORDER BY [database],[schema];';
SET @SQL = STUFF(@SQL, 1, 11, '');
DECLARE @EnumDBMeta TABLE
(
ID INT NOT NULL
IDENTITY(1, 1) ,
DBName NVARCHAR(128) ,
SchemaName NVARCHAR(128) ,
SchemaID INT ,
SchemaOwner NVARCHAR(128) ,
ProcessObjectName NVARCHAR(128) ,
ProcessObjectID INT ,
ProcessObjectSchemaID INT ,
ProcessObjectDescription NVARCHAR(2048) ,
ProcessObjectType NVARCHAR(128) ,
ProcessObjectCreatedDate DATE ,
ProcessObjectModifiedDate DATE
)
INSERT INTO @EnumDBMeta
( DBName ,
SchemaName ,
SchemaID ,
SchemaOwner ,
ProcessObjectName ,
ProcessObjectID ,
ProcessObjectSchemaID ,
ProcessObjectDescription ,
ProcessObjectType ,
ProcessObjectCreatedDate ,
ProcessObjectModifiedDate
)
EXEC sp_executesql @SQL
Instance level metadata comes mainly from appending different arguments to a SERVERPROPERTY function to return instance-specific information. Database users metadata comes from sys.database_principals, whereas login details are returned from sys.server_principals catalog views.
SSIS package metadata is a little bit more complex to interrogate. In case of LogSSISErrors_Package table, the package metadata is not stored on the server level but can be sourced from a .dtsx file using T-SQL. As mentioned before, this part of solution was made available thanks to Jamie Thompson’s scripts which you can read about in detail in his post HERE. This part of script accesses the file system and reads .dtsx XML content, storing relevant attributes in LogSSISErrors_Package table.
EXEC sp_configure 'show advanced options', 1;
RECONFIGURE;
EXEC sp_configure 'xp_cmdshell', 1;
RECONFIGURE;
DECLARE @Path VARCHAR(2000);
SET @Path = 'C:\*.dtsx';
--Must be of form [drive letter]\...\*.dtsx
DECLARE @MyFiles TABLE
(
MyID INT IDENTITY(1, 1)
PRIMARY KEY ,
FullPath VARCHAR(2000)
);
DECLARE @CommandLine VARCHAR(4000);
SELECT @CommandLine = LEFT('dir "' + @Path + '" /A-D /B /S ', 4000);
INSERT INTO @MyFiles
( FullPath )
EXECUTE xp_cmdshell @CommandLine;
DELETE FROM @MyFiles
WHERE FullPath IS NULL
OR FullPath = 'File Not Found'
OR FullPath = 'The system cannot find the path specified.'
OR FullPath = 'The system cannot find the file specified.';
IF EXISTS ( SELECT *
FROM sys.tables
WHERE name = N'pkgStats' )
DROP TABLE pkgStats;
CREATE TABLE pkgStats
(
PackagePath VARCHAR(900) NOT NULL
PRIMARY KEY ,
PackageXML XML NOT NULL
);
DECLARE @FullPath VARCHAR(2000);
DECLARE file_cursor CURSOR
FOR
SELECT FullPath
FROM @MyFiles;
OPEN file_cursor
FETCH NEXT FROM file_cursor INTO @FullPath;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @SQL = '
INSERT pkgStats (PackagePath,PackageXML)
select ''@FullPath'' as PackagePath
, cast(BulkColumn as XML) as PackageXML
from openrowset(bulk ''@FullPath'',
single_blob) as pkgColumn';
SELECT @SQL = REPLACE(@SQL, '@FullPath', @FullPath);
EXEC sp_executesql @SQL;
FETCH NEXT FROM file_cursor INTO @FullPath;
END
CLOSE file_cursor;
DEALLOCATE file_cursor;
DECLARE @pkgStatsBase TABLE
(
PackagePath VARCHAR(900) ,
PackageId UNIQUEIDENTIFIER ,
PackageCreatorsName NVARCHAR(500) ,
PackageFormatVersion SMALLINT ,
PackageType NVARCHAR(50) ,
PackageDescription NVARCHAR(2000) ,
PackageVersionMajor SMALLINT ,
PackageVersionMinor SMALLINT ,
PackageVersionBuild SMALLINT ,
PackageVersionGUID UNIQUEIDENTIFIER ,
PackageXML XML
);
INSERT INTO @pkgStatsBase
SELECT PackagePath ,
CAST(PackageXML.value('declare namespace DTS="www.microsoft.com/SqlServer/Dts";
/DTS:Executable[1]/DTS:Property[@DTS:Name=''DTSID''][1]',
'nvarchar(500)') AS UNIQUEIDENTIFIER) AS PackageID ,
PackageXML.value('declare namespace DTS="www.microsoft.com/SqlServer/Dts";
/DTS:Executable[1]/DTS:Property[@DTS:Name=''CreatorName''][1]',
'nvarchar(500)') AS PackageCreatorsName ,
CAST(PackageXML.value('declare namespace DTS="www.microsoft.com/SqlServer/Dts";
/DTS:Executable[1]/DTS:Property[@DTS:Name=''PackageFormatVersion''][1]',
'varchar(3)') AS SMALLINT) AS PackageFormatVersion ,
CAST(PackageXML.value('declare namespace DTS="www.microsoft.com/SqlServer/Dts";
DTS:Executable[1]/@DTS:ExecutableType[1]',
'nvarchar(50)') AS NVARCHAR(50)) AS PackageType ,
PackageXML.value('declare namespace DTS="www.microsoft.com/SqlServer/Dts";
/DTS:Executable[1]/DTS:Property[@DTS:Name=''Description''][1]',
'nvarchar(2000)') AS PackageDescription ,
CAST(PackageXML.value('declare namespace DTS="www.microsoft.com/SqlServer/Dts";
/DTS:Executable[1]/DTS:Property[@DTS:Name=''VersionMajor''][1]',
'varchar(3)') AS SMALLINT) AS PackageVersionMajor ,
CAST(PackageXML.value('declare namespace DTS="www.microsoft.com/SqlServer/Dts";
/DTS:Executable[1]/DTS:Property[@DTS:Name=''VersionMinor''][1]',
'varchar(3)') AS SMALLINT) AS PackageVersionMinor ,
CAST(PackageXML.value('declare namespace DTS="www.microsoft.com/SqlServer/Dts";
/DTS:Executable[1]/DTS:Property[@DTS:Name=''VersionBuild''][1]',
'varchar(3)') AS SMALLINT) AS PackageVersionBuild ,
CAST(PackageXML.value('declare namespace DTS="www.microsoft.com/SqlServer/Dts";
/DTS:Executable[1]/DTS:Property[@DTS:Name=''VersionGUID''][1]',
'char(38)') AS UNIQUEIDENTIFIER) AS PackageVersionGUID ,
PackageXML
FROM pkgStats
DECLARE @AllpkgStats TABLE
(
PackageId UNIQUEIDENTIFIER NULL ,
PackagePath VARCHAR(900) PRIMARY KEY
NOT NULL ,
PackageName VARCHAR(900) NULL ,
PackageCreatorsName NVARCHAR(500) NULL ,
PackageFormatVersion SMALLINT NULL ,
PackageType NVARCHAR(50) NULL ,
PackageDescription NVARCHAR(2000) NULL ,
PackageVersionMajor SMALLINT NULL ,
PackageVersionMinor SMALLINT NULL ,
PackageVersionBuild SMALLINT NULL ,
PackageVersionGUID UNIQUEIDENTIFIER NULL ,
PackageTasksNumber INT NULL ,
PackageContainersNumber INT NULL ,
PackageDataFlowsNumber INT NULL ,
PackageConnectionManagersNumber INT NULL ,
PackageVariablesInEntirePackageNumber INT NULL ,
PackageXML XML NULL
);
INSERT INTO @AllpkgStats
( PackageId ,
PackagePath ,
PackageName ,
PackageCreatorsName ,
PackageFormatVersion ,
PackageType ,
PackageDescription ,
PackageVersionMajor ,
PackageVersionMinor ,
PackageVersionBuild ,
PackageVersionGUID ,
PackageXML
)
SELECT p.PackageId ,
p.PackagePath ,
SUBSTRING(PackagePath,
LEN(PackagePath) - CHARINDEX('\',
REVERSE(PackagePath), 0)
+ 2, LEN(PackagePath)) AS PackageName ,
p.PackageCreatorsName ,
p.PackageFormatVersion ,
p.PackageType ,
p.PackageDescription ,
p.PackageVersionMajor ,
p.PackageVersionMinor ,
p.PackageVersionBuild ,
p.PackageVersionGUID ,
p.PackageXML
FROM @pkgStatsBase p;
--Number of tasks
MERGE INTO @AllpkgStats AS t
USING
( SELECT PackagePath ,
COUNT(*) AS PackageTasksNumber
FROM @pkgStatsBase p
CROSS APPLY p.PackageXML.nodes('declare namespace DTS="www.microsoft.com/SqlServer/Dts";
//DTS:Executable[@DTS:ExecutableType!=''STOCK:SEQUENCE''
and @DTS:ExecutableType!=''STOCK:FORLOOP''
and @DTS:ExecutableType!=''STOCK:FOREACHLOOP''
and not(contains(@DTS:ExecutableType,''.Package.''))]') Pkg ( props )
GROUP BY PackagePath
) s
ON ( t.PackagePath = s.PackagePath )
WHEN MATCHED THEN
UPDATE SET PackageTasksNumber = s.PackageTasksNumber;
--Number of containers
MERGE INTO @AllpkgStats AS t
USING
( SELECT PackagePath ,
COUNT(*) AS PackageContainersNumber
FROM @pkgStatsBase p
CROSS APPLY p.PackageXML.nodes('declare namespace DTS="www.microsoft.com/SqlServer/Dts";
//DTS:Executable[@DTS:ExecutableType=''STOCK:SEQUENCE''
or @DTS:ExecutableType=''STOCK:FORLOOP''
or @DTS:ExecutableType=''STOCK:FOREACHLOOP'']') Pkg ( props )
GROUP BY PackagePath
) s
ON ( t.PackagePath = s.PackagePath )
WHEN MATCHED THEN
UPDATE SET PackageContainersNumber = s.PackageContainersNumber
WHEN NOT MATCHED BY SOURCE THEN
UPDATE SET PackageContainersNumber = 0;
--Number of data flows
MERGE INTO @AllpkgStats AS t
USING
( SELECT PackagePath ,
COUNT(*) AS PackageDataFlowsNumber
FROM @pkgStatsBase p
CROSS APPLY p.PackageXML.nodes('declare namespace DTS="www.microsoft.com/SqlServer/Dts";
//DTS:Executable[contains(@DTS:ExecutableType,''.Pipeline.'')]') Pkg ( props )
GROUP BY PackagePath
) s
ON ( t.PackagePath = s.PackagePath )
WHEN MATCHED THEN
UPDATE SET PackageDataFlowsNumber = s.PackageDataFlowsNumber
WHEN NOT MATCHED BY SOURCE THEN
UPDATE SET PackageDataFlowsNumber = 0;
--Number of connection managers
MERGE INTO @AllpkgStats AS t
USING
( SELECT PackagePath ,
COUNT(*) AS PackageConnectionManagersNumber
FROM @pkgStatsBase p
CROSS APPLY p.PackageXML.nodes('declare namespace DTS="www.microsoft.com/SqlServer/Dts";
//DTS:ConnectionManager') Pkg ( props )
GROUP BY PackagePath
) s
ON ( t.PackagePath = s.PackagePath )
WHEN MATCHED THEN
UPDATE SET PackageConnectionManagersNumber = s.PackageConnectionManagersNumber
WHEN NOT MATCHED BY SOURCE THEN
UPDATE SET PackageConnectionManagersNumber = 0;
--Number of variables in entire package
MERGE INTO @AllpkgStats AS t
USING
( SELECT PackagePath ,
COUNT(*) AS PackageVariablesInEntirePackageNumber
FROM @pkgStatsBase p
CROSS APPLY p.PackageXML.nodes('declare namespace DTS="www.microsoft.com/SqlServer/Dts";
//DTS:Variable') Pkg ( props )
GROUP BY PackagePath
) s
ON ( t.PackagePath = s.PackagePath )
WHEN MATCHED THEN
UPDATE SET PackageVariablesInEntirePackageNumber = s.PackageVariablesInEntirePackageNumber
WHEN NOT MATCHED BY SOURCE THEN
UPDATE SET PackageVariablesInEntirePackageNumber = 0;
INSERT INTO AdminDBA.dbo.LogSSISErrors_Package
( PackageID ,
PackageName ,
PackagePath ,
PackageCreatorsName ,
PackageFormatVersion ,
PackageType ,
PackageDescription ,
PackageVersionMajor ,
PackageVersionMinor ,
PackageVersionBuild ,
PackageVersionGUID ,
PackageTasksNumber ,
PackageXML ,
PackageContainersNumber ,
PackageDataFlowsNumber ,
PackageConnectionManagersNumber ,
PackageVariablesInEntirePackageNumber ,
CurrentlyUsed
)
SELECT PackageId ,
PackageName ,
PackagePath ,
PackageCreatorsName ,
PackageFormatVersion ,
PackageType ,
PackageDescription ,
PackageVersionMajor ,
PackageVersionMinor ,
PackageVersionBuild ,
PackageVersionGUID ,
PackageTasksNumber ,
PackageXML ,
PackageContainersNumber ,
PackageDataFlowsNumber ,
PackageConnectionManagersNumber ,
PackageVariablesInEntirePackageNumber ,
1 AS CurrentlyUsed
FROM @AllpkgStats
IF EXISTS ( SELECT *
FROM sys.tables
WHERE name = N'pkgStats' )
DROP TABLE pkgStats;
EXEC sp_configure 'xp_cmdshell', 0;
RECONFIGURE;
EXEC sp_configure 'show advanced options', 0;
RECONFIGURE;
Upon execution completion this code should create a small set of tables starting with LogSSISErrors prefix and metadata entries in some or all tables based on your local SQL Server instance as per the image below.
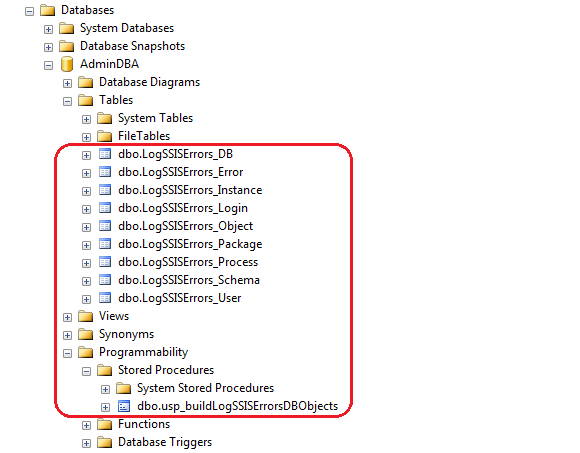
In the NEXT POST I will go through the process of creating a sample test environment, an SSIS package running an error-generating process and another variation of the above stored procedure used to update the database as the environment changes occur. Also, all the code used in this solution can be downloaded from my OneDrive folder HERE.
Posted in: Data Modelling, How To's, SQL
Tags: Data Modelling, SQL, SQL Server



Never thought Polybase could be used in this capacity and don't think Microsoft advertised this feature (off-loading DB data as…