September 18th, 2013 / 2 Comments » / by admin
In the FIRST POST to this series I outlined how to synchronised data across two different databases using dynamic MERGE SQL statement. The idea was that the code built MERGE SQL statement on the fly based on database objects’ metadata and as long the table had a primary key constraint present, it automatically handled INSERT and UPDATE based on its content. In this post I would like to expand on this approach and show you how to provide a looping functionality by means of using another stored procedure or an SSIS package to pick up all relevant object and execute it as many times as there is tables to merge together without listing object names individually. All the code and solution files for this series can be downloaded from HERE.
Using SQL Stored Procedure With Cursor
The simplest way to loop through a collection of tables which qualify for synchronisation is to create a simple stored procedure with a cursor. Before we get to the nuts and bolts of this solution, however, let’s first create sample databases, objects and dummy data for this demonstration. The below SQL code creates two databases, each containing three tables. Each table located in Source_DB database has 1000 records in it. We can also notice that our destination database has seemingly similar structure, however, from the data point of view, there is only 500 records in each table. Also, attributes with IDs numbered from 1 to 10 are different in source database to IDs in target database. This creates a good foundation for inserting and updating source data based on those discrepancies using MERGE SQL statement. Let’s go ahead and create all necessary databases, objects and dummy data.
USE [master]
GO
IF EXISTS (SELECT name FROM sys.databases WHERE name = N'Source_DB')
BEGIN
-- Close connections to the DW_Sample database
ALTER DATABASE [Source_DB] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [Source_DB]
END
GO
CREATE DATABASE [Source_DB]
IF EXISTS (SELECT name FROM sys.databases WHERE name = N'Target_DB')
BEGIN
-- Close connections to the DW_Sample database
ALTER DATABASE [Target_DB] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [Target_DB]
END
GO
CREATE DATABASE [Target_DB]
USE Source_DB
CREATE TABLE Tbl1 (
ID int NOT NULL,
Sample_Data_Col1 varchar (50) NOT NULL,
Sample_Data_Col2 varchar (50) NOT NULL,
Sample_Data_Col3 varchar (50) NOT NULL)
GO
USE Target_DB
CREATE TABLE Tbl1 (
ID int NOT NULL,
Sample_Data_Col1 varchar (50) NOT NULL,
Sample_Data_Col2 varchar (50) NOT NULL,
Sample_Data_Col3 varchar (50) NOT NULL)
GO
USE Source_DB
DECLARE @rowcount int = 0
WHILE @rowcount < 1000
BEGIN
SET NOCOUNT ON
INSERT INTO Tbl1
(ID, Sample_Data_Col1, Sample_Data_Col2, Sample_Data_Col3)
SELECT
@rowcount,
'Sample_Data' + CAST(@rowcount as varchar(10)),
'Sample_Data' + CAST(@rowcount as varchar(10)),
'Sample_Data' + CAST(@rowcount as varchar(10))
SET @rowcount = @rowcount + 1
END
GO
SELECT * INTO Tbl2 FROM Tbl1
SELECT * INTO Tbl3 FROM Tbl1
USE Target_DB
DECLARE @rowcount int = 0
WHILE @rowcount < 1000
BEGIN
SET NOCOUNT ON
INSERT INTO Tbl1
(ID, Sample_Data_Col1, Sample_Data_Col2, Sample_Data_Col3)
SELECT
@rowcount,
'Sample_Data' + CAST(@rowcount as varchar(10)),
'Sample_Data' + CAST(@rowcount as varchar(10)),
'Sample_Data' + CAST(@rowcount as varchar(10))
SET @rowcount = @rowcount + 1
END
GO
DELETE FROM Target_DB.dbo.Tbl1
WHERE ID >= 500
UPDATE Source_DB.dbo.Tbl1
SET Sample_Data_Col1 = 'Changed_Data'
WHERE ID < 10
UPDATE Source_DB.dbo.Tbl1
SET Sample_Data_Col2 = 'Changed_Data'
WHERE ID < 10
UPDATE Source_DB.dbo.Tbl1
SET Sample_Data_Col3 = 'Changed_Data'
WHERE ID < 10
SELECT * INTO Tbl2 FROM Tbl1
SELECT * INTO Tbl3 FROM Tbl1
CREATE UNIQUE CLUSTERED INDEX [Clustered_Idx_Id] ON Source_DB.dbo.Tbl1
([ID] ASC)
GO
CREATE UNIQUE CLUSTERED INDEX [Clustered_Idx_Id] ON Source_DB.dbo.Tbl2
([ID] ASC)
GO
CREATE UNIQUE CLUSTERED INDEX [Clustered_Idx_Id] ON Source_DB.dbo.Tbl3
([ID] ASC)
GO
CREATE UNIQUE CLUSTERED INDEX [Clustered_Idx_Id] ON Target_DB.dbo.Tbl1
([ID] ASC)
GO
CREATE UNIQUE CLUSTERED INDEX [Clustered_Idx_Id] ON Target_DB.dbo.Tbl2
([ID] ASC)
GO
CREATE UNIQUE CLUSTERED INDEX [Clustered_Idx_Id] ON Target_DB.dbo.Tbl3
([ID] ASC)
GO
Next, let’s recreate the usp_DBSync stored procedure from the PREVIOUS POST. The SQL code can be found either going back to the start of this series – POST 1 – or alternatively downloaded from HERE. Without usp_DBSync stored procedure on the server the rest of the solution will not work so make sure that you re-create it first. Now that we have all necessary objects, we are ready to create the construct which will provide our looping functionality based on metadata and allow for multiple objects processing without the need to specify their names. In order to do this, let’s create a ‘wrapper’ stored procedure around usp_DBSync procedure executing the following code.
USE [Source_DB]
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[usp_SyncMultipleTables]')
AND type IN (N'P',N'PC'))
DROP PROCEDURE [dbo].[usp_SyncMultipleTables]
GO
CREATE PROCEDURE [usp_SyncMultipleTables]
@SourceDBName varchar (256),
@SourceSchemaName varchar (50),
@TargetDBName varchar (256),
@TargetSchemaName varchar (50)
AS
BEGIN
SET NOCOUNT ON
DECLARE @Err_Msg varchar (max)
DECLARE @IsDebugMode bit = 1
DECLARE @SQLSource nvarchar (max) =
'INSERT INTO #TempTbl
(ObjectName, SchemaName, DBName, Source_vs_Target)
SELECT DISTINCT
o.name, '''+@SourceSchemaName+''', '''+@SourceDBName+''', ''S''
FROM '+@SourceDBName+'.sys.tables t
JOIN '+@SourceDBName+'.sys.schemas s ON t.schema_id = s.schema_id
JOIN '+@SourceDBName+'.sys.objects o ON t.schema_id = o.schema_id
WHERE S.name = '''+@SourceSchemaName+''' and o.type = ''U'''
DECLARE @SQLTarget nvarchar (max) =
'INSERT INTO #TempTbl
(ObjectName, SchemaName, DBName, Source_vs_Target)
SELECT DISTINCT
o.name, '''+@TargetSchemaName+''', '''+@TargetDBName+''', ''T''
FROM '+@TargetDBName+'.sys.tables t
JOIN '+@TargetDBName+'.sys.schemas s ON t.schema_id = s.schema_id
JOIN '+@TargetDBName+'.sys.objects o ON t.schema_id = o.schema_id
WHERE S.name = '''+@TargetSchemaName+''' and o.type = ''U'''
CREATE TABLE #TempTbl
(ObjectName varchar (256),
SchemaName varchar (50),
DBName varchar (50),
Source_vs_Target char(1))
EXEC sp_executesql @SQLSource
EXEC sp_executesql @SQLTarget
IF @IsDebugMode = 1
SELECT * FROM #TempTbl
CREATE TABLE #TempFinalTbl
(ID int IDENTITY (1,1),
ObjectName varchar (256))
INSERT INTO #TempFinalTbl
(ObjectName)
SELECT ObjectName
FROM #TempTbl a
WHERE Source_vs_Target = 'S'
INTERSECT
SELECT ObjectName
FROM #TempTbl a
WHERE Source_vs_Target = 'T'
IF @IsDebugMode = 1
SELECT * FROM #TempFinalTbl
IF @IsDebugMode = 1
PRINT 'The following tables will be merged between the source and target databases...'
DECLARE @ID int
DECLARE @TblName varchar (256)
DECLARE cur CURSOR FOR
SELECT ID, ObjectName FROM #TempFinalTbl
OPEN cur
FETCH NEXT FROM cur INTO @ID, @TblName
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT '' + CAST(@ID as varchar (20))+'. '+ @TblName +''
FETCH NEXT FROM cur INTO @ID, @TblName
END
CLOSE cur
DEALLOCATE cur
DECLARE @ObjectName varchar (256)
DECLARE db_cursor CURSOR
FOR
SELECT ObjectName
FROM #TempFinalTbl
OPEN db_cursor
FETCH NEXT
FROM db_cursor INTO @ObjectName
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT char(10)
PRINT 'Starting merging process...'
PRINT 'Merging ' + @SourceDBName + '.' + @SourceSchemaName + '.' + @ObjectName + ' with '+ @TargetDBName + '.' + @TargetSchemaName + '.' + @ObjectName + ''
EXEC [dbo].[usp_DBSync] @SourceDBName, @TargetDBName, @SourceSchemaName, @TargetSchemaName, @ObjectName, @ObjectName
FETCH NEXT FROM db_cursor INTO @ObjectName
END
CLOSE db_cursor
DEALLOCATE db_cursor
END
This code simply reiterates through tables which share same names between two different databases, providing necessary metadata for our code MERGE SQL stored procedure (usp_DBSync). Given we have our environment setup correctly i.e. we executed the first code snippet to prep our databases and objects and we also have usp_DBSync stored procedure sitting on our Source_DB database we can run the usp_SyncMultipleTables procedure to see if it correctly accounted for the database objects and the data they hold as well as whether data has been synchronised successfully. Let’s execute our stored procedure and observe the output using the following SQL.
USE [Source_DB]
GO
DECLARE @return_value int
EXEC @return_value = [dbo].[usp_SyncMultipleTables]
@SourceDBName = N'Source_DB',
@SourceSchemaName = N'dbo',
@TargetDBName = N'Target_DB',
@TargetSchemaName = N'dbo'
SELECT 'Return Value' = @return_value
GO
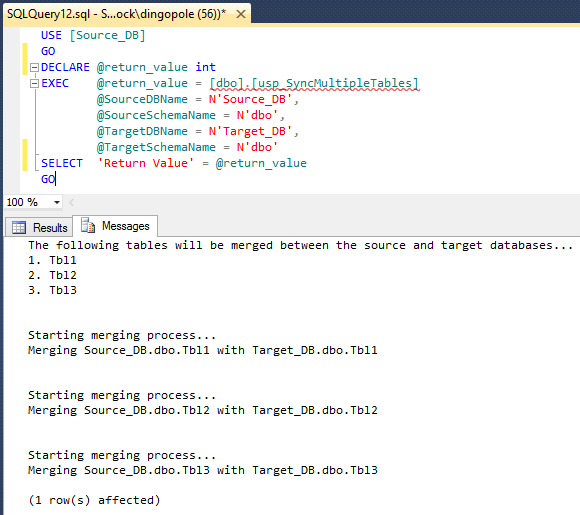
Finally, when comparing the data between the two databases, we should note that all tables i.e. Tbl1, Tbl2 and Tbl3 have been synchronised and contain the same data. Please note that only tables with same names will be synchronised. If you think of merging data from tables with different names, you need to provide additional functionality to account for source versus target objects mapping.
Using SQL Stored Procedure and SQL Server Integration Services
If you are familiar with SQL Server Integration Services, we can achieve the same result building a simple solution in BIDS or SQL Server Data Tools. Let’s re-create the environment again running the first SQL code snippet again to start with a clean slate. We also have to recreate usp_DBSync stored procedure as per PREVIOUS POST SQL code – without usp_DBSync stored procedure re-created the rest of the solution will not work. Next, we will create a simple stored procedure which will be used by our SSIS package to pass through the object names before we can initiate the looping functionality.
USE [Source_DB]
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[usp_ReturnObjectsMetadata]')
AND type IN (N'P',N'PC'))
DROP PROCEDURE [dbo].[usp_ReturnObjectsMetadata]
GO
CREATE PROCEDURE usp_ReturnObjectsMetadata
(@SourceSchemaName varchar (50),
@SourceDBName varchar (256),
@TargetSchemaName varchar (50),
@TargetDBName varchar (256))
AS
BEGIN
SET NOCOUNT ON
DECLARE @SQLSource nvarchar (max) =
'INSERT INTO #TempTbl
(ObjectName, SchemaName, DBName, Source_vs_Target)
SELECT DISTINCT
o.name, '''+@SourceSchemaName+''', '''+@SourceDBName+''', ''S''
FROM '+@SourceDBName+'.sys.tables t
JOIN '+@SourceDBName+'.sys.schemas s ON t.schema_id = s.schema_id
JOIN '+@SourceDBName+'.sys.objects o ON t.schema_id = o.schema_id
WHERE S.name = '''+@SourceSchemaName+''' and o.type = ''U'''
DECLARE @SQLTarget nvarchar (max) =
'INSERT INTO #TempTbl
(ObjectName, SchemaName, DBName, Source_vs_Target)
SELECT DISTINCT
o.name, '''+@TargetSchemaName+''', '''+@TargetDBName+''', ''T''
FROM '+@TargetDBName+'.sys.tables t
JOIN '+@TargetDBName+'.sys.schemas s ON t.schema_id = s.schema_id
JOIN '+@TargetDBName+'.sys.objects o ON t.schema_id = o.schema_id
WHERE S.name = '''+@TargetSchemaName+''' and o.type = ''U'''
CREATE TABLE #TempTbl
(ObjectName varchar (256),
SchemaName varchar (50),
DBName varchar (50),
Source_vs_Target char(1))
EXEC sp_executesql @SQLSource
EXEC sp_executesql @SQLTarget
CREATE TABLE #TempFinalTbl
(ID int IDENTITY (1,1),
ObjectName varchar (256))
INSERT INTO #TempFinalTbl
(ObjectName)
SELECT DISTINCT ObjectName
FROM #TempTbl a
WHERE Source_vs_Target = 'S'
INTERSECT
SELECT DISTINCT ObjectName
FROM #TempTbl a
WHERE Source_vs_Target = 'T'
SELECT DISTINCT ObjectName FROM #TempFinalTbl
END
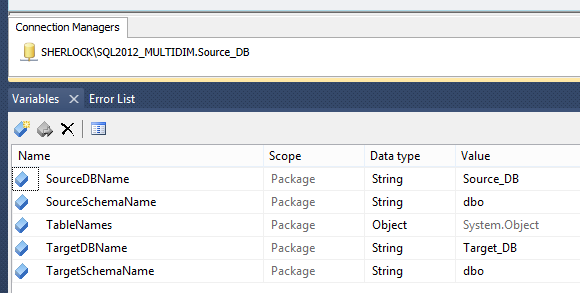
Finally, we are ready to build a simple SSIS package which will handle iterating through object names as merging occurs (all files for this package can be downloaded from HERE). Let’s create a simple SSIS solution starting with a setting up a database connection (the name will be different as per the environment which your’re developing on) and the following list of variables.
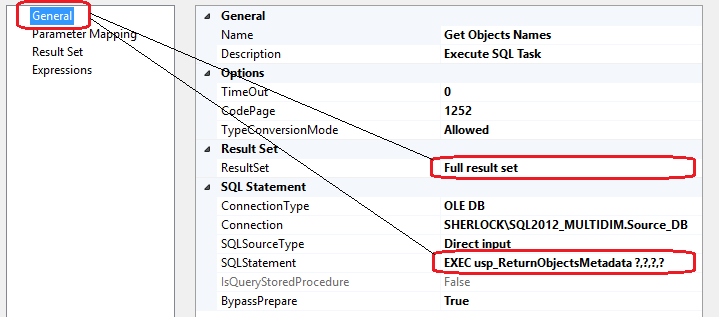
Continuing on, let’s place Execute SQL Task component on the Control Flow pane and adjust its properties under General settings to the following SQL statement and Result Set option.
Next, let’s map the parameters names to our variables and adjust Result Set properties as per the images below.


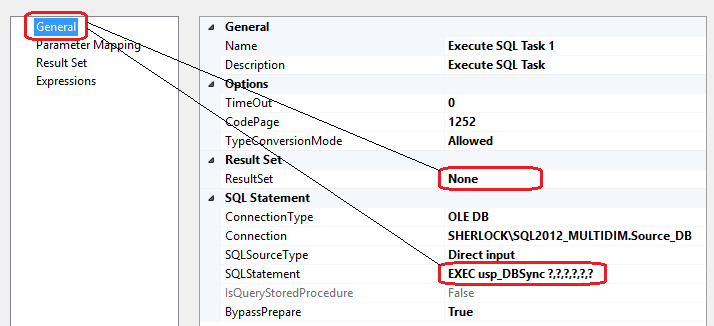
This part of package is responsible for populating our TableNames variable with the names of the objects we will be looping through. In order to reiterate through table names we will place For Each Loop container from Toolbar on the development pane, join it to the first Execute SQL Task transformation with default constraint option and place another Execute SQL Task container inside the For Each Loop one. Next, let’s adjust the second Execute SQL Task container’s properties as per below.
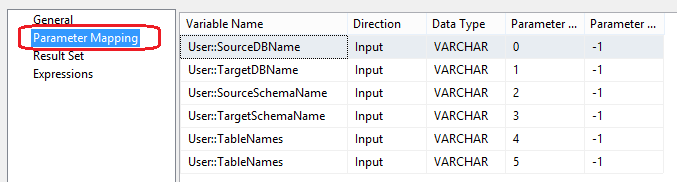
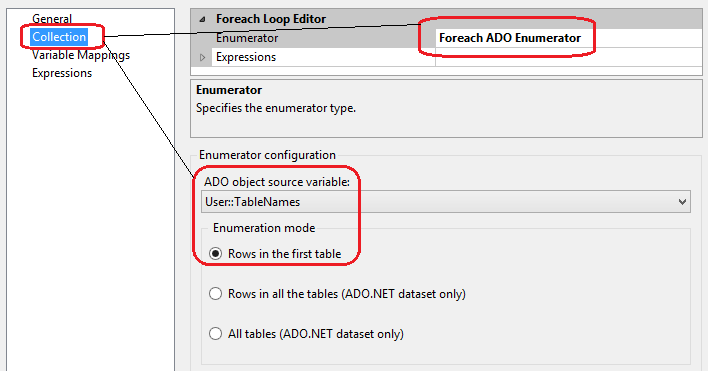
Lastly, let’s go through similar exercise with the For Each Loop transformation making sure that the Enumerator in the Collection property pane is set to Foreach ADO Enumerator, ADO Object Source Variable is set to User::TableNames variable and that Variable Mapping property is adjusted to match our User::TableNames variable as per images below.
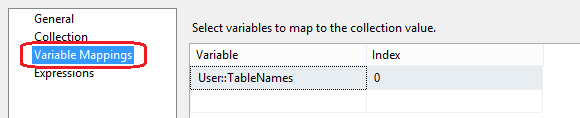
That should be just enough development to provide us with some basic, rudimentary functionality for the package to serve the intended purpose. Let’s test it out to so hopefully when you run the package it will synchronise all the database objects (can be confirmed with a simple SELECT * FROM <table_name> SQL statement) and the development pane output will be as per image below.
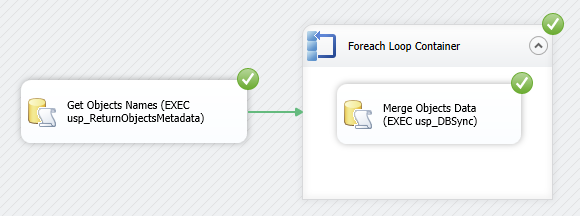
This concludes this mini-series. If you happen to stumble upon this blog and find it somewhat useful, please don’t hesitate to leave me a comment – any feedback is appreciate, good or bad! Again, the first post to this series can be viewed HERE and all the SQL code as well as the solution files can be downloaded from HERE.
Posted in: How To's, SQL
Tags: SQL
September 17th, 2013 / No Comments » / by admin
Note: This series is comprised of two posts – this one and another one which can be viewed HERE.
Lately I have been working on a project which involves synchronising data across two different databases without using any proprietary solution. As you know, there are many great tool out there which can automate such process hassle-free, however, given the requirements set out by the client i.e. having to use existing SQL Server infrastructure with no third-party tools, the project posed some interesting challenges. To cut the long story short, solution architect in consultation with the client decided to settle on utilising log shipping but I also experimented with other approaches, one of those described below. Given the fact that the data required to be synchronised was heavily de-normalised and that all of the tables had a primary key constraint on them I took advantage of the SQL code encapsulated in a stored procedure, which was preliminarily developed by my colleague – Fredy. The code builds MERGE SQL statement on the fly based on database objects’ metadata and as long the table has a primary key constraint present, it automatically handles INSERT and UPDATE based on its content.
Let’s take a closer look at the possible scenario where such dynamic MERGE statement could be used. Suppose we have two tables, one created on a source database and one on target database. The source table has just been updated with some new data and also some of the old data has been modified. Target table, on the other hand, has some overlapping data, however, given that the source has is more up-to-date, target object requires to be synchronised to replicate the changes – both inserts and updates. To materialise this scenario on a database level, let’s execute the following SQL and create the above databases, objects and some dummy data.
USE [master]
GO
IF EXISTS (SELECT name FROM sys.databases WHERE name = N'Source_DB')
BEGIN
-- Close connections to the DW_Sample database
ALTER DATABASE [Source_DB] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [Source_DB]
END
GO
CREATE DATABASE [Source_DB]
IF EXISTS (SELECT name FROM sys.databases WHERE name = N'Target_DB')
BEGIN
-- Close connections to the DW_Sample database
ALTER DATABASE [Target_DB] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [Target_DB]
END
GO
CREATE DATABASE [Target_DB]
USE Source_DB
CREATE TABLE Source_Tbl (
ID int NOT NULL,
Sample_Data_Col1 varchar (50) NOT NULL,
Sample_Data_Col2 varchar (50) NOT NULL,
Sample_Data_Col3 varchar (50) NOT NULL)
GO
USE Target_DB
CREATE TABLE Target_Tbl (
ID int NOT NULL,
Sample_Data_Col1 varchar (50) NOT NULL,
Sample_Data_Col2 varchar (50) NOT NULL,
Sample_Data_Col3 varchar (50) NOT NULL)
GO
USE Source_DB
DECLARE @rowcount int = 0
WHILE @rowcount < 1000
BEGIN
SET NOCOUNT ON
INSERT INTO Source_Tbl
(ID, Sample_Data_Col1, Sample_Data_Col2, Sample_Data_Col3)
SELECT
@rowcount,
'Sample_Data' + CAST(@rowcount as varchar(10)),
'Sample_Data' + CAST(@rowcount as varchar(10)),
'Sample_Data' + CAST(@rowcount as varchar(10))
SET @rowcount = @rowcount + 1
END
GO
USE Target_DB
DECLARE @rowcount int = 0
WHILE @rowcount < 1000
BEGIN
SET NOCOUNT ON
INSERT INTO Target_Tbl
(ID, Sample_Data_Col1, Sample_Data_Col2, Sample_Data_Col3)
SELECT
@rowcount,
'Sample_Data' + CAST(@rowcount as varchar(10)),
'Sample_Data' + CAST(@rowcount as varchar(10)),
'Sample_Data' + CAST(@rowcount as varchar(10))
SET @rowcount = @rowcount + 1
END
GO
DELETE FROM Target_DB.dbo.Target_Tbl
WHERE ID >= 500
UPDATE Source_DB.dbo.Source_Tbl
SET Sample_Data_Col1 = 'Changed_Data'
WHERE ID < 10
UPDATE Source_DB.dbo.Source_Tbl
SET Sample_Data_Col2 = 'Changed_Data'
WHERE ID < 10
UPDATE Source_DB.dbo.Source_Tbl
SET Sample_Data_Col3 = 'Changed_Data'
WHERE ID < 10
CREATE UNIQUE CLUSTERED INDEX [Clustered_Idx_Id] ON Target_DB.dbo.Target_Tbl
([ID] ASC)
GO
CREATE UNIQUE CLUSTERED INDEX [Clustered_Idx_Id] ON Source_DB.dbo.Source_Tbl
([ID] ASC)
GO
SELECT COUNT(1) AS Target_Count FROM Target_DB.dbo.Target_Tbl
SELECT COUNT(1) AS Source_Count FROM Source_DB.dbo.Source_Tbl
SELECT COUNT(1) AS Records_Count_Difference FROM
(SELECT ID FROM Target_DB.dbo.Target_Tbl
INTERSECT
SELECT ID FROM Source_DB.dbo.Source_Tbl) AS Records_Count_Difference
SELECT COUNT(1) AS Data_Records_Count_Difference FROM
(SELECT * FROM Target_DB.dbo.Target_Tbl
INTERSECT
SELECT * FROM Source_DB.dbo.Source_Tbl) AS Data_Records_Count_Difference
When the two databases and tables have been created and populated, the Results pane should display the difference status as per image below.
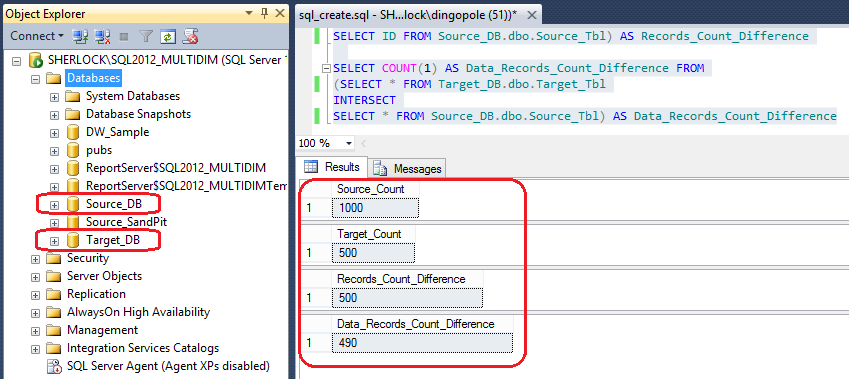
You will notice that the difference for record count between the source and the target is 500 and that out of the data which should be overlapping, 10 records have different values i.e. 490 out of 500 records remained the same whereas 10 records have been changed in the source. This is a very rudimentary scenario and its simplicity is only for demonstration purposes.
Next, let’s assume that we want to synchronise the data between those two tables and databases to account for changed and new records in the target table. Below is the SQL for a stored procedure which accomplishes that, you can also download the SQL for this short series from HERE. As mentioned previously, the code builds MERGE SQL statement on the fly based on database objects’ metadata and as long the table has a primary key constraint present, it automatically handles INSERT and UPDATE based on its content.
USE [Source_DB]
GO
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[usp_DBSync]')
AND type IN (N'P',N'PC'))
DROP PROCEDURE [dbo].[usp_DBSync]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER OFF
GO
CREATE PROCEDURE [dbo].[usp_DBSync]
(@Src_DB varchar (100),
@Tgt_DB varchar (100),
@Src_Schema_Name varchar (10),
@Tgt_Schema_Name varchar (10),
@Src_Object_Name varchar (256),
@Tgt_Object_Name varchar (256))
AS
SET NOCOUNT ON
DECLARE
@IsDebugMode bit,
@ExecSQL nvarchar(max),
@Err_Msg nvarchar (1000)
SET
@IsDebugMode = 0
/*====================================================================================
CREATE TEMP TABLES
======================================================================================*/
CREATE TABLE #Src_Tgt_Tables
(
[Data_Obj_Id] [int] NOT NULL,
[Src_Tgt_Flag] [varchar](1) NOT NULL,
[Object_Id] [int] NOT NULL,
[Object_Name] [sysname] NOT NULL,
[Schema_Name] [sysname] NOT NULL,
[Schema_Object_Name] [varchar](260) NOT NULL,
[Column_Id] [smallint] NULL,
[Column_Name] [varchar](200) NULL,
[IsIdentity] [tinyint] NULL,
[IsComputed] [tinyint] NULL,
[IsNullable] [tinyint] NULL,
[Default] [varchar](max) NULL,
[DataType] [varchar](152) NULL,
[DataType_CastGroup] [varchar](134) NOT NULL,
[Collation_Name] [sysname] NULL
)
CREATE TABLE #Tgt_NK_Cols
(
[Data_Obj_Id] [int] NOT NULL,
[Schema_Object_Name] [varchar](260) NOT NULL,
[Where_Clause] [varchar](max) NULL,
S_Schema_Object_Name [varchar](260) NOT NULL
)
IF @IsDebugMode = 1
SELECT
[Source DB] = @Src_DB,
[Target DB] = @Tgt_DB,
[Source_Schema_Name] = @Src_Schema_Name,
[Target_Schema_Name] = @Tgt_Schema_Name,
[Source_Objects_Name] = @Src_Object_Name,
[Target_Objects_Name] = @Tgt_Object_Name
/*====================================================================================
PERFORM DATABASES, SCHEMAS AND OBJECTS CHECKS
======================================================================================*/
DECLARE @CMD varchar (1024)
CREATE TABLE #Objects_List(
DatabaseName sysname,
SchemaName sysname,
ObjectName sysname)
SET @CMD = 'USE [?]; SELECT DB_NAME() DATABASE_NAME, SCHEMA_NAME(schema_id),
NAME FROM sys.tables'
INSERT INTO #Objects_List
EXEC SP_MSFOREACHDB @CMD
DELETE FROM #Objects_List
WHERE DatabaseName IN ('master', 'msdb', 'tempdb', 'model')
IF NOT EXISTS (SELECT 1 FROM #Objects_List a WHERE a.databasename = @Src_DB)
BEGIN
SET
@Err_Msg = 'Source database cannot be found. You nominated "' + @Src_DB + '".
Check that the database of that name exists on the instance'
RAISERROR (
@Err_Msg -- Message text.
,16 -- Severity.
,1 -- State.
)
END
IF NOT EXISTS (SELECT 1 FROM #Objects_List a WHERE a.databasename = @Tgt_DB)
BEGIN
SET
@Err_Msg = 'Target database cannot be found. You nominated "' + @Tgt_DB + '".
Check that the database of that name exists on the instance'
RAISERROR (
@Err_Msg -- Message text.
,16 -- Severity.
,1 -- State.
)
END
IF NOT EXISTS (SELECT 1 FROM #Objects_List a WHERE a.SchemaName = @Src_Schema_Name)
BEGIN
SET
@Err_Msg = 'Source schema cannot be found. You nominated "' + @Src_Schema_Name + '".
Check that the schema of that name exists on the database'
RAISERROR (
@Err_Msg -- Message text.
,16 -- Severity.
,1 -- State.
)
END
IF NOT EXISTS (SELECT 1 FROM #Objects_List a WHERE a.SchemaName = @Tgt_Schema_Name)
BEGIN
SET
@Err_Msg = 'Target schema cannot be found. You nominated "' + @Tgt_Schema_Name + '".
Check that the schema of that name exists on the database'
RAISERROR (
@Err_Msg -- Message text.
,16 -- Severity.
,1 -- State.
)
END
IF NOT EXISTS (SELECT 1 FROM #Objects_List a WHERE a.ObjectName = @Src_Object_Name)
BEGIN
SET
@Err_Msg = 'Source object cannot be found. You nominated "' + @Src_Object_Name + '".
Check that the object of that name exists on the database'
RAISERROR (
@Err_Msg -- Message text.
,16 -- Severity.
,1 -- State.
)
END
IF NOT EXISTS (SELECT 1 FROM #Objects_List a WHERE a.ObjectName = @Tgt_Object_Name)
BEGIN
SET
@Err_Msg = 'Target object cannot be found. You nominated "' + @Tgt_Object_Name + '".
Check that the object of that name exists on the database'
RAISERROR (
@Err_Msg -- Message text.
,16 -- Severity.
,1 -- State.
)
END
/*====================================================================================
EXTRACT SOURCE AND TARGET DATA
======================================================================================*/
SET
@ExecSQL =
'INSERT INTO
#Src_Tgt_Tables
SELECT
[Data_Object_Id] = so.id,
[Src_Trg_Flag] = src_tgt.Src_Trg_Flag,
[Object_Id] = so.id,
[Object_Name] = so.name,
[Schema_Name] = sh.name,
[Schema_Object_Name] = ''[' +@Src_DB+ '].[''+sh.name+''].[''+so.name+'']'',
[Column_Id] = sc.column_id,
[Column_Name] = ''[''+sc.name+'']'',
[IsIdentity] = sc.is_identity,
[IsComputed] = sc.is_computed,
[IsNullable] = sc.is_nullable,
[Default] = dc.definition,
[DataType] = (
CASE
WHEN T.system_type_id IN (167, 175, 231, 239) AND SC.max_length > 0
THEN T.Name + ''('' + CAST(SC.max_length AS varchar(10)) + '')''
WHEN T.system_type_id IN (167, 175, 231, 239) AND SC.max_length = -1 THEN T.Name + ''(MAX)''
-- For Numeric and Decimal data types
WHEN T.system_type_id IN (106, 108) THEN T.Name + ''('' + CAST(SC.precision AS varchar(10)) + '', '' +
CAST(SC.scale AS varchar(10)) + '')''
ELSE T.Name
END
),
[DataType_CastGroup] = (
CASE
WHEN T.system_type_id IN (167, 175, 231, 239) THEN ''String''
-- For Numeric and Decimal data types
WHEN T.system_type_id IN (106, 108) THEN ''Numeric''
ELSE ''Other''
END
),
[Collation_Name] = SC.collation_name
FROM
'+@Src_DB+'.sys.sysobjects so (NOLOCK)
INNER JOIN '+@Src_DB+'.sys.columns sc (NOLOCK) ON
sc.object_id = so.id
LEFT JOIN '+@Src_DB+'.sys.default_constraints dc (NOLOCK) ON
dc.parent_object_id = so.id
AND dc.parent_column_id = sc.column_id
INNER JOIN '+@Src_DB+'.sys.types t (NOLOCK) ON
t.user_type_id = sc.user_type_id
INNER JOIN '+@Src_DB+'.sys.schemas sh (NOLOCK) ON
sh.schema_id = so.uid
INNER JOIN (
select
Data_Obj_Id = t.object_id,
t.name as phisical_name,
s.name as s_name ,
Src_trg_Flag = ''S'',
Object_Type = ''U''
FROM '+@Src_DB+'.sys.tables t
JOIN sys.schemas s ON t.schema_id = s.schema_id
WHERE s.name = '''+@Src_Schema_Name+'''
and t.name = '''+@Src_Object_Name+'''
) src_tgt ON
src_tgt.phisical_name = so.name and
src_tgt.s_name = sh.name
WHERE
so.xtype = src_tgt.Object_Type'
IF @IsDebugMode = 1
PRINT @ExecSQL
EXEC sp_executesql @ExecSQL
SET
@ExecSQL =
'INSERT INTO
#Src_Tgt_Tables
SELECT
[Data_Obj_Id] = src_tgt.Data_Obj_Id,
[Src_Trg_Flag] = src_tgt.Src_Trg_Flag,
[Object_Id] = so.id,
[Object_Name] = so.name,
[Schema_Name] = sh.name,
[Schema_Object_Name] = ''[' +@Tgt_DB+ '].[''+sh.name+''].[''+so.name+'']'',
[Column_Id] = sc.column_id,
[Column_Name] = ''[''+sc.name+'']'',
[IsIdentity] = sc.is_identity,
[IsComputed] = sc.is_computed,
[IsNullable] = sc.is_nullable,
[Default] = dc.definition,
[DataType] = (
CASE
WHEN T.system_type_id IN (167, 175, 231, 239) AND SC.max_length > 0
THEN T.Name + ''('' + CAST(SC.max_length AS varchar(10)) + '')''
WHEN T.system_type_id IN (167, 175, 231, 239) AND SC.max_length = -1 THEN T.Name + ''(MAX)''
-- For Numeric and Decimal data types
WHEN T.system_type_id IN (106, 108) THEN T.Name + ''('' + CAST(SC.precision AS varchar(10)) + '', ''
+ CAST(SC.scale AS varchar(10)) + '')''
ELSE T.Name
END
),
[DataType_CastGroup] = (
CASE
WHEN T.system_type_id IN (167, 175, 231, 239) THEN ''String''
-- For Numeric and Decimal data types
WHEN T.system_type_id IN (106, 108) THEN ''Numeric''
ELSE ''Other''
END
),
[Collation_Name] = SC.collation_name
FROM
'+@Tgt_DB+'.sys.sysobjects so
INNER JOIN '+@Tgt_DB+'.sys.columns sc ON
sc.object_id = so.id
LEFT JOIN '+@Tgt_DB+'.sys.default_constraints dc ON
dc.parent_object_id = so.id
AND dc.parent_column_id = sc.column_id
INNER JOIN '+@Tgt_DB+'.sys.types t ON
t.user_type_id = sc.user_type_id
INNER JOIN '+@Tgt_DB+'.sys.schemas sh ON
sh.schema_id = so.uid
INNER JOIN (
select
Data_Obj_Id = t.object_id,
t.name as phisical_name,
s.name as s_name,
Src_trg_Flag = ''T'',
Object_Type = ''U''
FROM '+@tgt_DB+'.sys.tables t
JOIN sys.schemas s ON t.schema_id = s.schema_id
WHERE S.name = '''+@Tgt_Schema_Name+'''
and t.name = '''+@Tgt_Object_Name+'''
) src_tgt ON
src_tgt.phisical_name = so.name and
src_tgt.s_name = sh.name
WHERE
so.xtype = ''U'' -- Table
ORDER BY
so.name,
sc.column_id'
IF @IsDebugMode = 1
PRINT @ExecSQL
EXEC sp_executesql @ExecSQL
/*====================================================================================
ENSURE THAT SOURCE AND TARGET DETAILS ARE PRESENT IN TEMP TABLE
======================================================================================*/
IF @IsDebugMode = 1
SELECT [Table] = '#Src_Tgt_Tables', * FROM #Src_Tgt_Tables
IF (SELECT COUNT(*) FROM #Src_Tgt_Tables ST WHERE ST.Src_Tgt_Flag = 'S') < 1
BEGIN
SET @Err_Msg = 'No Source table details found. Configured Source Database is "' + @Src_DB + '".'
RAISERROR (
@Err_Msg -- Message text.
,16 -- Severity.
,1 -- State.
)
END
IF (SELECT COUNT(*) FROM #Src_Tgt_Tables ST WHERE ST.Src_Tgt_Flag = 'T') < 1
BEGIN
SET @Err_Msg = 'No Target table details found. Configured Source Database is "' + @Tgt_DB + '".'
RAISERROR (
@Err_Msg -- Message text.
,16 -- Severity.
,1 -- State.
)
END
/*====================================================================================
PREPARE 'WHERE' CLAUSE FOR THE MERGE STATEMENT
======================================================================================*/
SET
@ExecSQL =
'INSERT INTO
#Tgt_NK_Cols
SELECT
TOP 1
Data_Obj_Id = tgt.Data_Obj_Id,
[Schema_Object_Name] = tgt.[Schema_Object_Name],
[Where_Clause] = STUFF(REPLACE((SELECT
'' AND'' + '' TGT.[''+ sc.name +''] =
SRC.[''+ REPLACE(REPLACE(sc.name, ''<'', ''~''), ''>'', ''!'') + '']'' + CHAR(10)
FROM
'+@Tgt_DB+'.sys.sysindexkeys sik
INNER JOIN '+@Tgt_DB+'.sys.syscolumns sc on
sc.id = sik.id
and sc.colid = sik.colid
WHERE
sik.id = si.object_id
AND sik.indid = si.index_id
ORDER BY
sik.keyno
FOR XML PATH('''')
), ''
'', ''''), 1, 5, ''''),
[S_Schema_Object_Name] = (
SELECT Top 1
S.Schema_Object_Name
FROM
#Src_Tgt_Tables S
WHERE
S.Src_Tgt_Flag = ''S'')
FROM
'+@Tgt_DB+'.sys.indexes si
INNER JOIN '+@Tgt_DB+'.sys.sysobjects so ON
so.id = si.object_id
INNER JOIN '+@Tgt_DB+'.sys.schemas sh ON
sh.schema_id = so.uid
INNER JOIN (
SELECT
[Data_Obj_Id],
[Object_Id],
[Object_Name],
[Schema_Name],
[Schema_Object_Name]
FROM
#Src_Tgt_Tables
WHERE
Src_Tgt_Flag = ''T''
) tgt ON
tgt.[Object_Id] = so.id
WHERE
si.is_unique = 1 /*Only Unique Index*/'
IF @IsDebugMode = 1
PRINT @ExecSQL
EXEC sp_executesql @ExecSQL
IF @IsDebugMode = 1
SELECT [Table] = '#Tgt_NK_Cols', * FROM #Tgt_NK_Cols
/*====================================================================================
ENSURE THAT UNIQUE KEY INDEX IS PRESENT
======================================================================================*/
IF EXISTS(SELECT 1 FROM #Tgt_NK_Cols NK WHERE NK.Where_Clause IS NULL)
BEGIN
SET
@Err_Msg = 'No Unique Key Index is found.
Configured Source Database is "' + @Tgt_DB + '".'
RAISERROR (
@Err_Msg -- Message text.
,16 -- Severity.
,1 -- State.
)
END
/*====================================================================================
PREPARE MERGE STATEMENT
======================================================================================*/
DECLARE
@MergeSQL nvarchar(max),
@UpdateColSet nvarchar(max),
@TargetColSet nvarchar(max),
@SourceColSet nvarchar(max),
@ValueColSet nvarchar(max)
SELECT
@MergeSQL = '
MERGE '+NK.Schema_Object_Name+' TGT
USING (
SELECT{SOURCE_COLUMN_SET}
FROM
'+NK.S_Schema_Object_Name+' SRC (NOLOCK)
) SRC ON
'+ NK.Where_Clause+'
WHEN MATCHED THEN
UPDATE SET{UPDATE_COLUMN_SET}
WHEN NOT MATCHED THEN
INSERT({TARGET_COLUMN_SET}
)
VALUES ({VALUE_COLUMN_SET}
)
OUTPUT $action INTO #SummaryOfChanges(Action_Name);
'
FROM
#Tgt_NK_Cols NK
SELECT
@TargetColSet = REPLACE(STUFF((SELECT ','+CHAR(10)
+ ' ' + CAST(TC.Column_Name as varchar(100))
FROM
#Src_Tgt_Tables TC (NOLOCK)
LEFT JOIN (
SELECT
T.[Data_Obj_Id]
,T.[Column_Name]
,T.[IsNullable]
,T.[Default]
,T.[DataType]
,T.[DataType_CastGroup]
FROM
#Src_Tgt_Tables T (NOLOCK)
WHERE
T.Src_Tgt_Flag = 'S'
AND T.Data_Obj_Id = TS.S_Data_Obj_Id
) SC
ON SC.Column_Name = TC.Column_Name
WHERE
TC.Src_Tgt_Flag = 'T'
AND TC.Data_Obj_Id = TS.T_Data_Obj_Id
--AND TC.IsIdentity <> 1 -- Ignore identity
AND TC.IsComputed <> 1 -- and computed columns
ORDER BY
TC.Column_Id
FOR XML PATH('')
), 1, 1, ''), '
', ''),
@SourceColSet = REPLACE(STUFF((SELECT ','+CHAR(10) + ' ' + ISNULL('SRC.' + CAST(SC.Column_Name as varchar(100)),
CAST(TC.Column_Name as varchar(100))+' = '+ REPLACE(REPLACE('{'+TC.Column_Name+'}', '{[', '{'), ']}', '}'))
FROM #Src_Tgt_Tables TC (NOLOCK)
LEFT JOIN (
SELECT
T.[Data_Obj_Id]
,T.[Column_Name]
,T.[IsNullable]
,T.[Default]
,T.[DataType]
,T.[DataType_CastGroup]
FROM
#Src_Tgt_Tables T (NOLOCK)
WHERE
T.Src_Tgt_Flag = 'S'
AND T.Data_Obj_Id = TS.S_Data_Obj_Id
) SC
ON SC.Column_Name = TC.Column_Name
WHERE
TC.Src_Tgt_Flag = 'T'
AND TC.Data_Obj_Id = TS.T_Data_Obj_Id
AND TC.IsIdentity <> 1 -- Ignore identity
AND TC.IsComputed <> 1 -- and computed columns
ORDER BY
TC.Column_Id
FOR XML PATH('')
), 1, 1, ''), '
', ''),
@UpdateColSet = REPLACE(STUFF((SELECT ','+CHAR(10) + ' ' + CAST(TC.Column_Name as varchar(100))+' = SRC.' + ISNULL(SC.Column_Name, TC.Column_Name)
FROM
#Src_Tgt_Tables TC (NOLOCK)
LEFT JOIN (
SELECT
T.[Data_Obj_Id]
,T.[Column_Name]
,T.[IsNullable]
,T.[Default]
,T.[DataType]
,T.[DataType_CastGroup]
FROM
#Src_Tgt_Tables T (NOLOCK)
WHERE
T.Src_Tgt_Flag = 'S'
AND T.Data_Obj_Id = TS.S_Data_Obj_Id
) SC ON
SC.Column_Name = TC.Column_Name
WHERE
TC.Src_Tgt_Flag = 'T'
AND TC.Data_Obj_Id = TS.T_Data_Obj_Id
AND TC.IsIdentity <> 1 -- Ignore identity
AND TC.IsComputed <> 1 -- and computed columns
ORDER BY
TC.Column_Id
FOR XML PATH('')
), 1, 1, ''), '
', ''),
@ValueColSet = REPLACE(STUFF((SELECT ','+CHAR(10) + ' ' + ISNULL('SRC.' + CAST(SC.Column_Name as varchar(100)),
'SRC.' + CAST(TC.Column_Name as varchar(100)))
FROM
#Src_Tgt_Tables TC (NOLOCK)
LEFT JOIN (
SELECT
T.[Data_Obj_Id]
,T.[Column_Name]
,T.[IsNullable]
,T.[Default]
,T.[DataType]
,T.[DataType_CastGroup]
FROM
#Src_Tgt_Tables T (NOLOCK)
WHERE
T.Src_Tgt_Flag = 'S'
AND T.Data_Obj_Id = TS.S_Data_Obj_Id
) SC ON
SC.Column_Name = TC.Column_Name
WHERE
TC.Src_Tgt_Flag = 'T'
AND TC.Data_Obj_Id = TS.T_Data_Obj_Id
AND TC.IsIdentity <> 1 -- Ignore identity
AND TC.IsComputed <> 1 -- and computed columns
ORDER BY
TC.Column_Id
FOR XML PATH('')
), 1, 1, ''), '
', '')
FROM
(SELECT [T_Data_Obj_Id] = T.Data_Obj_Id,
[T_Schema_Object_Name] = T.Schema_Object_Name,
[S_Schema_Object_Name] = (
SELECT Top 1 S.Schema_Object_Name
FROM
#Src_Tgt_Tables S
WHERE
S.Src_Tgt_Flag = 'S'
),
[S_Data_Obj_Id] = (
SELECT Top 1 S.Data_Obj_Id FROM
#Src_Tgt_Tables S
WHERE
S.Src_Tgt_Flag = 'S'
)
FROM #Src_Tgt_Tables T
WHERE
T.Src_Tgt_Flag = 'T'
) TS
SELECT @MergeSQL = REPLACE(@MergeSQL, '{UPDATE_COLUMN_SET}', @UpdateColSet)
SELECT @MergeSQL = REPLACE(@MergeSQL, '{TARGET_COLUMN_SET}', @TargetColSet)
SELECT @MergeSQL = REPLACE(@MergeSQL, '{SOURCE_COLUMN_SET}', @SourceColSet)
SELECT @MergeSQL = REPLACE(@MergeSQL, '{VALUE_COLUMN_SET}', @ValueColSet)
/*====================================================================================
EXECUTE MERGE STATEMENT AND CHECK FOR EXECUTION RESULTS
======================================================================================*/
DECLARE
@UpdatedCount int,
@InsertedCount int,
@DeletedCount int,
@StartTime datetime,
@EndTime datetime
CREATE TABLE #SummaryOfChanges (Action_Name VARCHAR(50));
SET @StartTime = GETDATE()
BEGIN TRY
IF @IsDebugMode = 1
BEGIN
PRINT @MergeSQL
END
EXEC sp_executesql @MergeSQL
SELECT
@UpdatedCount = SUM(CASE WHEN Action_Name = 'UPDATE' THEN 1 ELSE 0 END),
@InsertedCount = SUM(CASE WHEN Action_Name = 'INSERT' THEN 1 ELSE 0 END),
@DeletedCount = SUM(CASE WHEN Action_Name = 'DELETE' THEN 1 ELSE 0 END)
FROM
#SummaryOfChanges
IF @IsDebugMode = 1
BEGIN
SELECT @UpdatedCount as Records_Updated
SELECT @InsertedCount as Records_Inserted
SELECT @DeletedCount as Records_Deleted
END
END TRY
BEGIN CATCH
END CATCH
SET NOCOUNT OFF;
In order to synchronise the data between the two previously created objects let’s run the usp_DBSync stored procedure (assuming you have already executed the above SQL) either from the context menu in Management Studio or by running the following code.
USE [Source_DB]
GO
DECLARE @return_value int
EXEC @return_value = [dbo].[usp_DBSync]
@Src_DB = N'Source_DB',
@Tgt_DB = N'Target_DB',
@Src_Schema_Name = N'dbo',
@Tgt_Schema_Name = N'dbo',
@Src_Object_Name = N'Source_Tbl',
@Tgt_Object_Name = N'Target_Tbl'
SELECT 'Return Value' = @return_value
GO
Finally, to check if the data has been synchronised successfully, let’s run the last few lines from the first SQL code batch used to create the databases and objects and compare the results. If everything executed as expected and the source has been merged with the target, the output should be as per below.
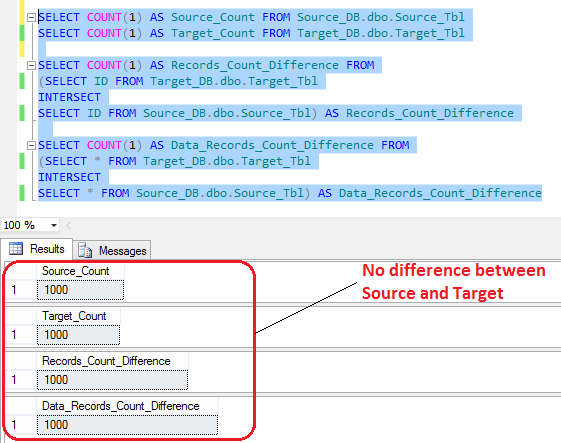
One thing to note here is that MERGE does not seem to work across two different SQL Server instances e.g. between linked servers. For that you will need to break/alter the above MERGE SQL into INSERT and UPDATE statements. In the NEXT POST to this series I will show how to synchronise multiple objects across two databases. Rather than executing our MERGE stored procedure for each database object individually, we can provide a looping functionality by means of using another stored procedure or an SSIS package to pick up all relevant object and execute it as many times as there is tables to merge together.
Just in case you have any issues coping and pasting, all SQL code as well as any additional files can be downloaded from HERE.
Posted in: How To's, SQL
Tags: SQL



Never thought Polybase could be used in this capacity and don't think Microsoft advertised this feature (off-loading DB data as…