Building rapid data import interfaces with PySimpleGUI and Streamlit
December 5th, 2022 / 3 Comments » / by admin
Note: All code from this post can be downloaded from my OneDrive folder HERE.
Introduction
The proliferation of low-code or no-code solutions for building simple apps has taken a solid foothold in the industry and a lot can be achieved with minimal effort and supporting code. As we enter an era of AI-enabled development, we’re seeing a lot of productivity gains from complex linguistic framework e.g. ChatGPT which can take requirements as input and generate comprehensive code in a matter of seconds. This creates an interesting conundrum – are developers automating themselves out of their jobs or are they making their work more enjoyable by ‘outsourcing’ the most mundane parts of their job to focus on what’s truly important – providing business value. It’s a discussion for a separate post but there’s no denying that the days of manually crafting application ‘scaffolding’ and reinventing the wheel are coming to an end as more of us lean towards using mobile, desktop or Web frameworks, ORMs, predefined libraries and packages or other adaptive software development approaches to expedite output delivery.
For those who need to provide a visual interface for either data entry or data output, there is a plethora of choices out there. Building a simple data entry form or a bare-bones site with a few widgets to allow end-users to interact with the content typically involves a combination of multiple technologies and languages but it’s surprising how much functionality can be achieved using some of the frameworks available in Python. In this post I’d like to explore how anyone can build a simple flat file data import interface for SQL Server. The need for this type of solution came out of multiple requests from non-technical clients needing to interface data sources familiar to them e.g. CSV, Excel with their internal database(s) and with a few button clicks upload/insert the required dataset to augment or change upstream reporting or analytics. It’s nothing cutting-edge and most visualisation tools provide the means to do a low-level data prep through pseudo ETL-like process e.g. Power BI Data Flows or Tableau Prep Builder but they still require technical expertise and the knowledge of underlying schemas and structures. Sometimes, all that’s required is a simple interface with a few widgets – that’s where frameworks like PySimpleGUI and Streamlit shine.
For this exercise, let’s look at a very simple interface for validating and loading flat file data into a database table. The objective is to provide end-users with an app which allows them to:
- Authenticate to Microsoft SQL Server instance running on their network using either Windows Authentication or SQL Server authentication
- Validate their supplied credentials
- Search for the required file on their file system
- Select a table this data needs to be loaded into
- Run a series of validation steps and if no issues are detected, load the CSV file into the nominated table
Let’s dive in and see how quick and productive one can be using these two frameworks.
PySimpleGUI
Launched in 2018, PySimpleGUI is a python library that wraps tkinter, Qt (pyside2), wxPython and Remi (for browser support), allowing very fast and simple-to-learn GUI programming. Your code is not required to have an object-oriented architecture – one of the major obstacles when writing GUI applications – which makes the package usable by a larger audience. PySimpleGUI code is simpler and shorter than writing directly using the underlying framework because PySimpleGUI implements much of the “boilerplate code” for you. Additionally, interfaces are simplified to require as little code as possible (half to 1/10th) to get the desired result.
This app interface can be designed in many different ways but for this exercise, I have kept the functionality and output to minimum and when executing app.py file we get the following output.
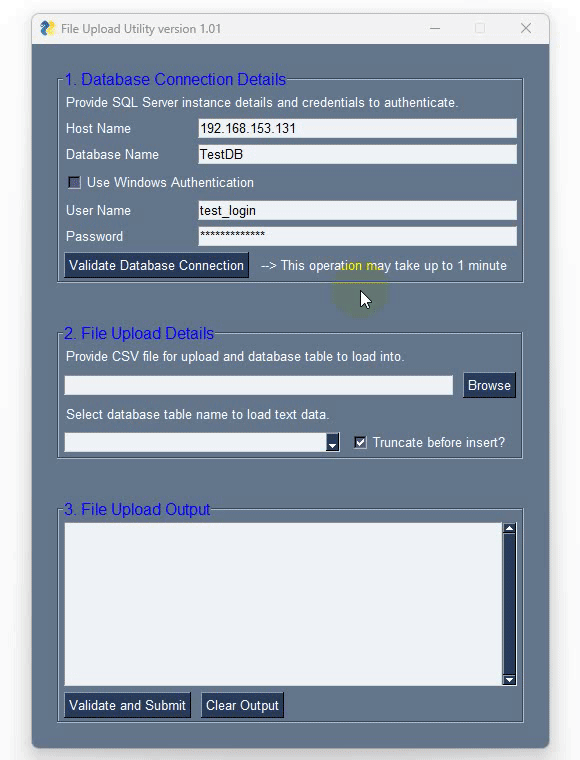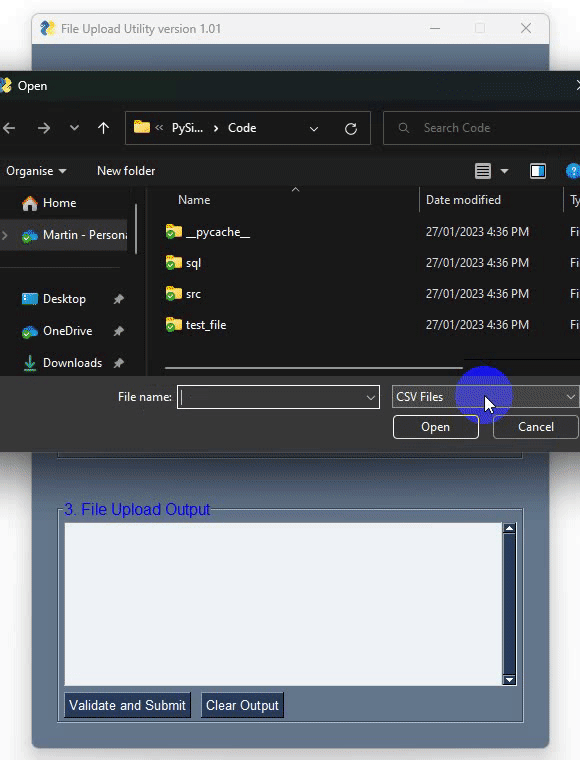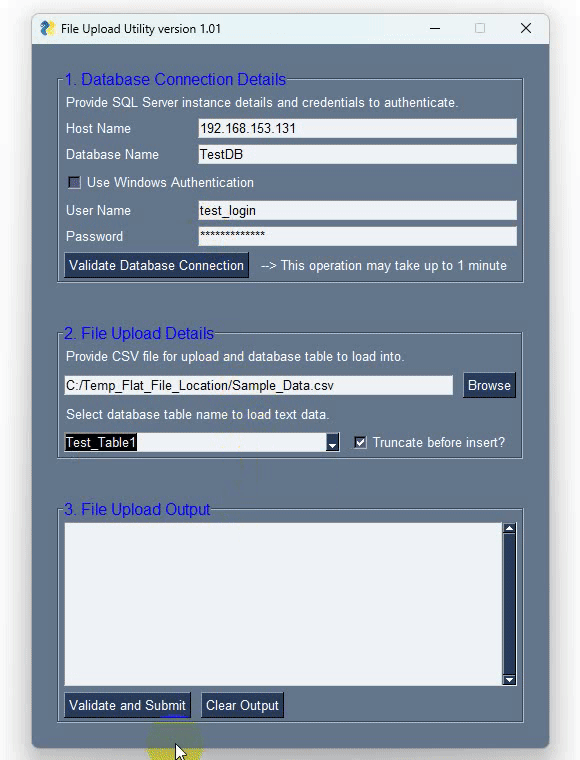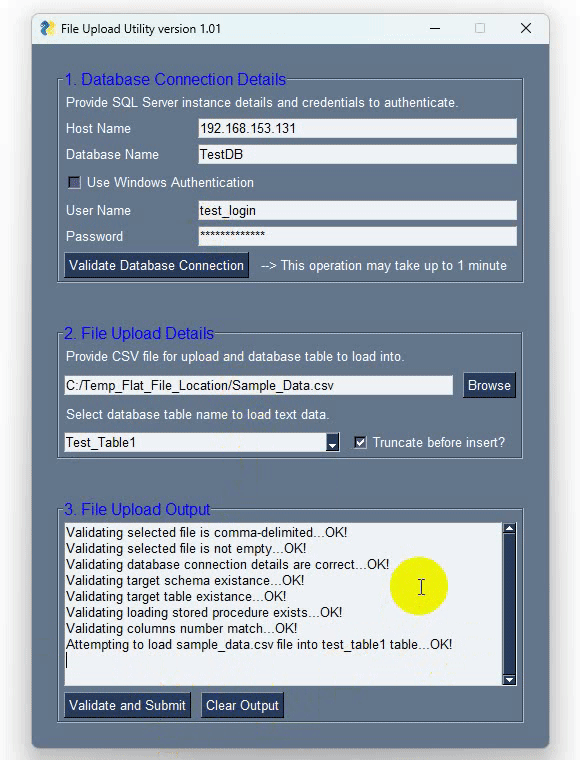
PySimpleGUI allows for creating bespoke windows and layouts using lists – in this example I’ve defined three to account for the separation between database login-specific elements, file search-specific elements and text output elements. These three are then combined using the ‘layout’ list which also ‘draws’ a frame around each of them to make these three areas visually distinct. Next, we have a function responsible for all the heavy listing i.e. data validation and load and finally the main method binding it all together. I’m not going to go over PySimpleGUI API as it’s one of those projects which has a very comprehensive support documentation. It also features over 300 Demo Programs which provide many design patterns for you to learn how to use PySimpleGUI and how to integrate PySimpleGUI with other packages and a cookbook featuring recipes covering many different scenarios. It’s by far one of the best documented open-source projects I have came across. To pip-install it into you default Python interpreter or a virtual environment simply run one of the following lines:
pip install pysimplegui or pip3 install pysimplegui
The following short snippet of Python is responsible for most of this little app’s functionality, proving that minimal amount of code is required to build a complete interface which fulfills all requirements specyfied.
import PySimpleGUI as sg
import os
import csv
from pathlib import Path
import helpers as helpers
_WORKING_DIR = os.getcwd()
_SQL_TABLES = ['Test_Table1', 'Test_Table2', 'Test_Table3']
_LOAD_STORED_PROC = 'usp_load_ext_table'
_TARGET_TABLE_SCHEMA_NAME = 'dbo'
db_layout = [[sg.Text('Provide SQL Server instance details and credentials to authenticate.')],
[sg.Text('Host Name ', size=(15, 1)), sg.Input(
key='-HOSTNAME-', default_text='192.168.153.128')],
[sg.Text('Database Name ', size=(15, 1)),
sg.Input(key='-DATABASE-', enable_events=True, default_text='TestDB')], [sg.Checkbox('Use Windows Authentication', enable_events=True, default=False, key='-USEWINAUTH-')],
[sg.Text('User Name ', size=(15, 1), key='-USERNAMELABEL-'), sg.Input(
key='-USERNAME-', enable_events=True, default_text='test_login')],
[sg.Text('Password ', size=(15, 1), key='-PASSWORDLABEL-'), sg.Input(
key='-PASSWORD-', password_char='*',
enable_events=True, default_text='test_password')],
[sg.Button('Validate Database Connection', key='-VALIDATE-'), sg.Text(
'--> This operation may take up to 1 minute', visible=True, key='_text_visible_')]
]
file_search_layout = [[sg.Text('Provide CSV file for upload and database table to load into.')],
[sg.InputText(key='-FILEPATH-', size=(55, 1)),
sg.FileBrowse(initial_folder=_WORKING_DIR, file_types=[("CSV Files", "*.csv")])],
[sg.Text('Select database table name to load text data.')],
[sg.Combo(_SQL_TABLES, size=(37), key='-TABLECHOICE-', readonly=True),
sg.Checkbox('Truncate before insert?', default=True, key='-TRUCATESOURCE-')]]
stdout_layout = [[sg.Multiline(size=(62, 10), key='-OUTPUT-')], [
sg.Button('Validate and Submit', key='-SUBMIT-'),
sg.Button('Clear Output', key='-CLEAR-')]]
layout = [[sg.Frame('1. Database Connection Details', db_layout,
title_color='blue', font='Any 12', pad=(15, 20))],
[sg.Frame('2. File Upload Details', file_search_layout,
title_color='blue', font='Any 12', pad=(15, 20))],
[sg.Frame('3. File Upload Output', stdout_layout,
title_color='blue', font='Any 12', pad=(15, 20))]]
def check_file_and_load(db_conn, full_path, table_dropdown_value, truncate_source_table_flag, _LOAD_STORED_PROC, _TARGET_TABLE_SCHEMA_NAME):
file_name = Path(full_path).name
file_path = Path(full_path).parent
# check csv file is comma delimited
window['-OUTPUT-'].print('Validating selected file is comma-delimited...', end='')
with open(full_path, 'r', newline='') as f:
reader = csv.reader(f, delimiter=",")
dialect = csv.Sniffer().sniff(f.read(1024))
if dialect.delimiter != ',':
window['-OUTPUT-'].print('Failed!', text_color='red')
return
else:
window['-OUTPUT-'].print('OK!')
# check csv file is not empty
window['-OUTPUT-'].print('Validating selected file is not empty...', end='')
with open(full_path, 'r', newline='') as f:
reader = csv.reader(f, dialect)
ncols = len(next(reader))
f.seek(0)
nrow = len(list(reader))
if nrow < 2:
window['-OUTPUT-'].print('Failed!', text_color='red')
return
else:
window['-OUTPUT-'].print('OK!')
# check for database connection values correctness
window['-OUTPUT-'].print(
'Validating database connection details are correct...', end='')
conn = db_conn(HOSTNAME=values['-HOSTNAME-'], DATABASE=values['-DATABASE-'],
USERNAME=values['-USERNAME-'], PASSWORD=values['-PASSWORD-'], USEWINAUTH=values['-USEWINAUTH-'])
if conn:
window['-OUTPUT-'].print('OK!')
else:
window['-OUTPUT-'].print('Failed!', text_color='red')
# check required schema exists on the target server
window['-OUTPUT-'].print('Validating target schema existance...', end='')
with conn.cursor() as cursor:
sql = """SELECT TOP (1) 1 FROM {target_db}.sys.schemas
WHERE name = '{target_schema}'""".format(target_db=values['-DATABASE-'], target_schema = _TARGET_TABLE_SCHEMA_NAME)
cursor.execute(sql)
rows = cursor.fetchone()
if rows:
window['-OUTPUT-'].print('OK!')
else:
window['-OUTPUT-'].print('Failed!', text_color='red')
return
# check selected table exists on the target server
window['-OUTPUT-'].print('Validating target table existance...', end='')
with conn.cursor() as cursor:
sql = """SELECT TOP (1) 1 FROM {target_db}.information_schema.tables
WHERE table_name = '{target_table}'""".format(target_db=values['-DATABASE-'], target_table=table_dropdown_value)
cursor.execute(sql)
rows = cursor.fetchone()
if rows:
window['-OUTPUT-'].print('OK!')
else:
window['-OUTPUT-'].print('Failed!', text_color='red')
return
# check if insert sored proc exists
window['-OUTPUT-'].print("Validating loading stored procedure exists...", end='')
with conn.cursor() as cursor:
sql = """SELECT TOP (1) 1 FROM {target_db}.sys.objects WHERE type = 'P' AND OBJECT_ID = OBJECT_ID('dbo.usp_load_ext_table')""".format(
target_db=values['-DATABASE-'])
cursor.execute(sql)
sp = cursor.fetchone()
if sp:
window['-OUTPUT-'].print('OK!')
else:
window['-OUTPUT-'].print('Failed!', text_color='red')
return
# check if number of columns matches
window['-OUTPUT-'].print('Validating columns number match...', end='')
with conn.cursor() as cursor:
sql = """SELECT COUNT(1) FROM {target_db}.information_schema.columns
WHERE table_name = '{target_table}'""".format(target_db=values['-DATABASE-'], target_table=table_dropdown_value)
cursor.execute(sql)
dbcols = cursor.fetchone()[0]
if dbcols == ncols:
window['-OUTPUT-'].print('OK!')
else:
window['-OUTPUT-'].print('Failed!', text_color='red')
return
window['-OUTPUT-'].print('Attempting to load {csv_file} file into {target_table} table...'.format(
csv_file=file_name.lower(), target_table=table_dropdown_value.lower()), end='')
with conn.cursor() as cursor:
sql = '''\
DECLARE @col_names VARCHAR (MAX);
EXEC TestDB.dbo.{sp_name}
@temp_target_table_name=?,
@target_table_name=?,
@target_table_schema_name=?,
@file_path=?,
@truncate_target_table=?,
@col_names = @col_names OUTPUT;
SELECT @col_names AS col_names
'''.format(sp_name=_LOAD_STORED_PROC)
params = ('##'+table_dropdown_value, table_dropdown_value,
_TARGET_TABLE_SCHEMA_NAME, full_path, truncate_source_table_flag)
cursor.execute(sql, params)
col_names = cursor.fetchval()
if truncate_source_table_flag == 1:
test_1_sql = 'SELECT TOP (1) 1 FROM (SELECT {cols} FROM {temp_target_table_name} EXCEPT SELECT {cols} FROM {target_table_schema_name}.{target_table_name})a'.format(
temp_target_table_name='##'+table_dropdown_value, target_table_schema_name=_TARGET_TABLE_SCHEMA_NAME, target_table_name=table_dropdown_value, cols=col_names)
cursor.execute(test_1_sql)
test_1_rows = cursor.fetchone()
test_2_sql = 'SELECT TOP (1) status FROM {temp_target_table_name}'.format(
temp_target_table_name='##'+table_dropdown_value)
cursor.execute(test_2_sql)
test_2_rows = cursor.fetchone()[0]
if test_1_rows and test_2_rows != 'SUCCESS':
window['-OUTPUT-'].print('Failed!', text_color='red')
else:
window['-OUTPUT-'].print('OK!')
return
elif truncate_source_table_flag == 0:
test_1_sql = 'SELECT COUNT(1) as ct FROM (SELECT {cols} FROM {temp_target_table_name} INTERSECT SELECT {cols} FROM {target_table_schema_name}.{target_table_name})a'.format(
temp_target_table_name='##'+table_dropdown_value, target_table_schema_name=_TARGET_TABLE_SCHEMA_NAME, target_table_name=table_dropdown_value, cols=col_names)
cursor.execute(test_1_sql)
test_1_rows = cursor.fetchone()[0]
test_2_sql = 'SELECT TOP (1) status FROM {temp_target_table_name}'.format(
temp_target_table_name='##'+table_dropdown_value)
cursor.execute(test_2_sql)
test_2_rows = cursor.fetchone()[0]
if nrow-1 != test_1_rows or test_2_rows != 'SUCCESS':
window['-OUTPUT-'].print('Failed!', text_color='red')
else:
window['-OUTPUT-'].print('OK!')
return
window = sg.Window('File Upload Utility version 1.01', layout)
while True:
event, values = window.read()
if event == sg.WIN_CLOSED or event == 'Exit':
break
elif '-USEWINAUTH-' in event:
win_auth_setting = values['-USEWINAUTH-']
if win_auth_setting == True:
window['-USERNAMELABEL-'].Update(visible=False)
window['-PASSWORDLABEL-'].Update(visible=False)
window['-USERNAME-'].Update(visible=False)
window['-PASSWORD-'].Update(visible=False)
elif win_auth_setting == False:
window['-USERNAMELABEL-'].Update(visible=True)
window['-PASSWORDLABEL-'].Update(visible=True)
window['-USERNAME-'].Update(visible=True)
window['-PASSWORD-'].Update(visible=True)
elif '-VALIDATE-' in event:
validation = helpers.validate_db_input_values(values)
if validation:
error_msg = ('\nInvalid: ' + value for value in validation)
error_message = helpers.generate_error_message(validation)
sg.popup(error_message, keep_on_top=True)
else:
HOSTNAME = values['-HOSTNAME-'],
DATABASE = values['-DATABASE-'],
USERNAME = values['-USERNAME-'],
PASSWORD = values['-PASSWORD-'],
USEWINAUTH = values['-USEWINAUTH-']
conn = helpers.db_conn(HOSTNAME=values['-HOSTNAME-'], DATABASE=values['-DATABASE-'],
USERNAME=values['-USERNAME-'], PASSWORD=values['-PASSWORD-'], USEWINAUTH=values['-USEWINAUTH-'])
if conn:
sg.popup('Supplied credentails are valid!',
keep_on_top=True, title='')
else:
sg.popup('Supplied credentails are invalid or there is a network connection issue.',
keep_on_top=True, title='', button_color='red')
elif '-SUBMIT-' in event:
validation = helpers.validate_file_input_values(values)
if validation:
error_msg = ('\nInvalid: ' + value for value in validation)
error_message = helpers.generate_error_message(validation)
sg.popup(error_message, keep_on_top=True)
else:
truncate_source_table_flag = bool(values['-TRUCATESOURCE-'])
table_dropdown_value = values['-TABLECHOICE-']
window['-OUTPUT-'].update('')
full_path = str(Path(values['-FILEPATH-']))
file_name = Path(full_path).name
file_path = Path(full_path).parent
db_conn = helpers.db_conn
check_file_and_load(db_conn,
full_path, table_dropdown_value, truncate_source_table_flag, _LOAD_STORED_PROC, _TARGET_TABLE_SCHEMA_NAME)
elif '-CLEAR-' in event:
window['-OUTPUT-'].update('')
window.close()
The main app.py file also import from the helper module which contains functions used for input validation, database connection and error message generation. You can find all the code used for this solution in my OneDrive folder HERE.
Finally, tying it all together is a bit of T-SQL wrapped around a stored procedure. This code takes five parameters as input values and outputs one value into the Python code defining the names of the columns of our target database table (used in Python code validation). Its primary function is to:
- Create a global temporary table mirrored on the schema of the target table
- Using BULK INSERT operation insert our flat file’s data into it
- Optionally truncate target object and insert the required data from the temp table into the destination table
- Alter temp table with the operation status i.e. Failure of Success (used in Python validation code)
The reason why a global temporary table is created and loaded into first is that we want to ensure that the CSV file’s data and schema is conforming to what the target table structure is before we make any changes to it. Having this step in place allows for an extra level of validation – if the temporary table insert fails, target table insertion code is not triggered at all. Likewise, if the temporary table with the schema identical to that of the destination table is created and populated successfully, we can be confident that the target table’s data can be purged (as denoted by one of the parameter’s value) and loaded into without any issues. The full T-SQL code is as follows:
USE [TestDB];
GO
SET ANSI_NULLS ON;
GO
SET QUOTED_IDENTIFIER ON;
GO
CREATE PROCEDURE [dbo].[usp_load_ext_table]
(
@temp_target_table_name VARCHAR(256),
@target_table_name VARCHAR(256),
@target_table_schema_name VARCHAR(256),
@file_path VARCHAR(1024),
@truncate_target_table BIT,
@col_names VARCHAR(MAX) OUTPUT
)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @cols VARCHAR(MAX);
DECLARE @sql VARCHAR(MAX);
DECLARE @error_message VARCHAR(MAX);
SELECT @sql
= 'DROP TABLE IF EXISTS ' + @temp_target_table_name + '; CREATE TABLE ' + @temp_target_table_name + ' ('
+ o.list + ')',
@cols = j.list
FROM sys.tables t
CROSS APPLY
(
SELECT STUFF(
(
SELECT ',' + QUOTENAME(c.COLUMN_NAME) + ' ' + c.DATA_TYPE
+ CASE c.DATA_TYPE
WHEN 'sql_variant' THEN
''
WHEN 'text' THEN
''
WHEN 'ntext' THEN
''
WHEN 'xml' THEN
''
WHEN 'decimal' THEN
'(' + CAST(c.NUMERIC_PRECISION AS VARCHAR) + ', '
+ CAST(c.NUMERIC_SCALE AS VARCHAR) + ')'
ELSE
COALESCE( '(' + CASE
WHEN c.CHARACTER_MAXIMUM_LENGTH = -1 THEN
'MAX'
ELSE
CAST(c.CHARACTER_MAXIMUM_LENGTH AS VARCHAR)
END + ')',
''
)
END
FROM INFORMATION_SCHEMA.COLUMNS c
JOIN sysobjects o
ON c.TABLE_NAME = o.name
WHERE c.TABLE_NAME = @target_table_name
AND TABLE_NAME = t.name
ORDER BY ORDINAL_POSITION
FOR XML PATH('')
),
1,
1,
''
)
) o(list)
CROSS APPLY
(
SELECT STUFF(
(
SELECT ',' + QUOTENAME(c.COLUMN_NAME)
FROM INFORMATION_SCHEMA.COLUMNS c
JOIN sysobjects o
ON c.TABLE_NAME = o.name
WHERE c.TABLE_NAME = @target_table_name
ORDER BY ORDINAL_POSITION
FOR XML PATH('')
),
1,
1,
''
)
) j(list)
WHERE t.name = @target_table_name;
EXEC (@sql);
SET @col_names = @cols;
IF NOT EXISTS
(
SELECT *
FROM tempdb.INFORMATION_SCHEMA.TABLES
WHERE TABLE_NAME = @temp_target_table_name
)
BEGIN
SET @error_message
= 'Global temporary placeholder table has not been successfully created in the tempdb database. Please troubleshoot.';
RAISERROR( @error_message, -- Message text.
16, -- Severity.
1 -- State.
);
RETURN;
END;
SET @sql
= '
BULK INSERT ' + @temp_target_table_name + '
FROM ' + QUOTENAME(@file_path, '''')
+ '
WITH
(
FIRSTROW = 2,
FIELDTERMINATOR = '','',
ROWTERMINATOR = ''\n'',
MAXERRORS=0,
TABLOCK
)';
EXEC (@sql);
SET @sql = CASE
WHEN @truncate_target_table = 1 THEN
'TRUNCATE TABLE ' + @target_table_schema_name + '.' + @target_table_name + '; '
ELSE
''
END + 'INSERT INTO ' + @target_table_schema_name + '.' + @target_table_name + ' (' + @cols + ') ';
SET @sql = @sql + 'SELECT ' + @cols + ' FROM ' + @temp_target_table_name + '';
BEGIN TRANSACTION;
BEGIN TRY
EXEC (@sql);
SET @sql
= 'ALTER TABLE ' + @temp_target_table_name + ' ADD status VARCHAR(56) DEFAULT ''FAILURE'', ' + CHAR(13);
SET @sql = @sql + 'status_message varchar(256) NULL; ' + CHAR(13);
EXEC (@sql);
SET @sql = 'UPDATE ' + @temp_target_table_name + ' SET status = ''SUCCESS'', ' + CHAR(13);
SET @sql = @sql + 'status_message = ''Operation executed successfully!''' + CHAR(13);
EXEC (@sql);
END TRY
BEGIN CATCH
SET @error_message = ERROR_MESSAGE();
SET @sql
= 'ALTER TABLE ' + @temp_target_table_name + ' ADD outcome varchar (56) DEFAULT ''FAILURE'',' + CHAR(13);
SET @sql = @sql + 'outcome_message varchar(256) NULL; ' + CHAR(13);
EXEC (@sql);
SET @sql = 'UPDATE ' + @temp_target_table_name + ' SET outcome_message = ''' + @error_message + '''';
EXEC (@sql);
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION;
END CATCH;
IF @@TRANCOUNT > 0
COMMIT TRANSACTION;
END;
One drawback of this code is that it assumes the nominated flat file is located on the same server as our SQL Server instance – the above SQL code uses T-SQL BULK INSERT operation which expects access to the underlying file system and the file itself. This limitation can be alleviated by reading the file’s content into a dataframe and populating the target table using, for example, Python’s Pandas library instead. However, in this instance, I expected end users to have access to the system hosting MSSQL instance so all ‘heavy lifting’ i.e. data insertion is done using pure T-SQL.
Streamlit
As desktop GUI apps only work in certain scenarios, leveraging the previously created code (both T-SQL and Python) we can build a Web front end instead. Streamlit, an open-source Python app framework, allows anyone to transform scripts into sharable web apps, all without the prior knowledge of CSS, HTML or JavaScript. It’s a purely Python-based framework (though some customizations can be achieved with a sprinkling of HTML), claimed to be used by over 80% of Fortune 50 companies and with the backing of Snowflake (which recently acquired it for $800 million), is set to democratize access to data. Streamlit boasts a large gallery of apps, most of them with source code, so it’s relatively easy to explore its capabilities and poke around ‘under the hood’. It also offers Community Cloud where one can deploy, manage, and share apps with the world, directly from Streamlit — all for free. To pip-install it into you default Python interpreter or a virtual environment simply run the following:
pip install streamlit
To spin up a local web server and run the app in your default web browser you can run the following from the command line:
streamlit run your_script.py [-- script args]
For this Streamlit app, I tried to keep the interface layout largely unchanged from our previous PySimpleGUI app even though I was tempted to add a bit of eye-candy to the page – Streamlit has a pretty good integrations with some of the major plotting and visualization Python packages so adding a widget or two would be very easy and make the whole app a lot more appealing. The draft version of the app is as per the image below.
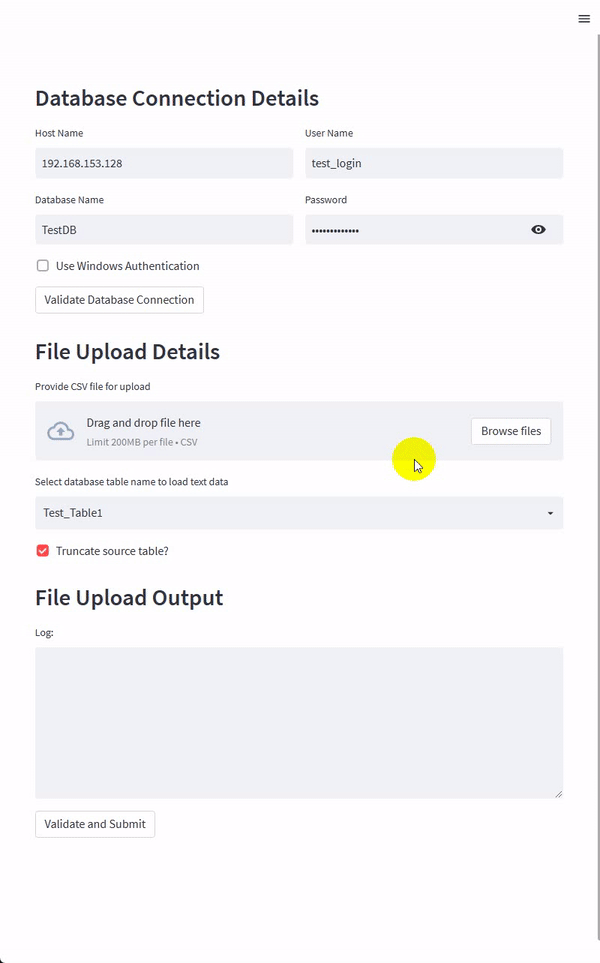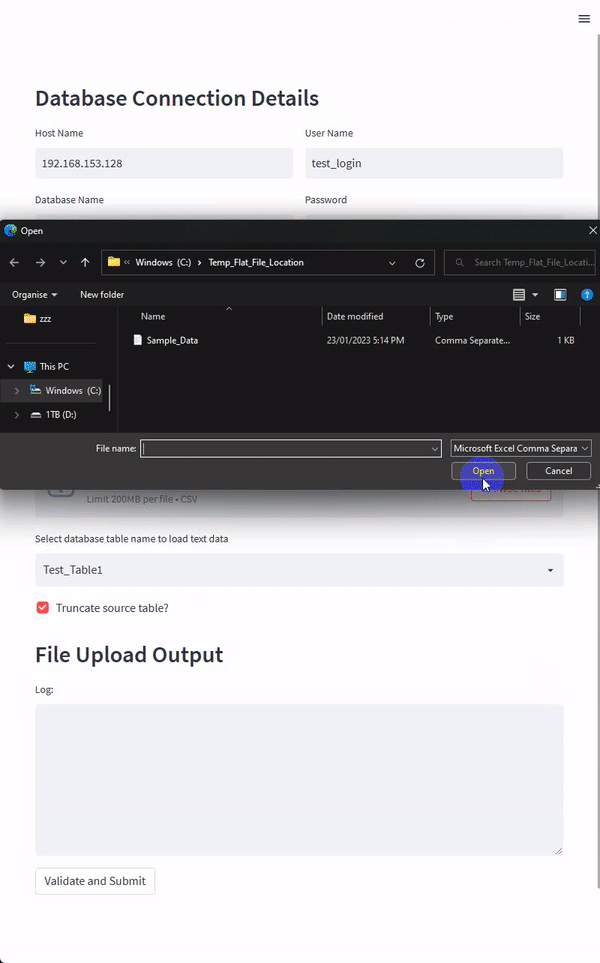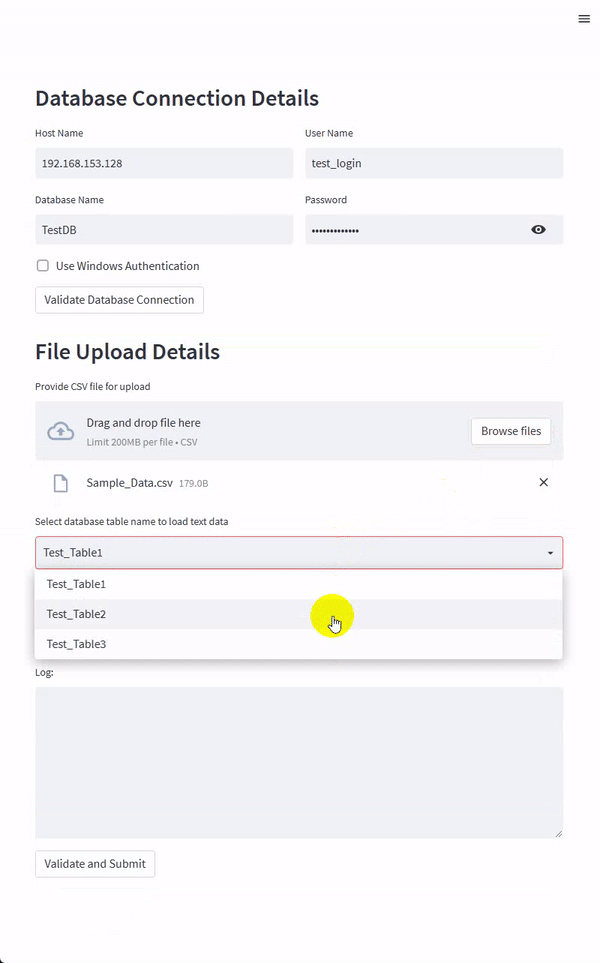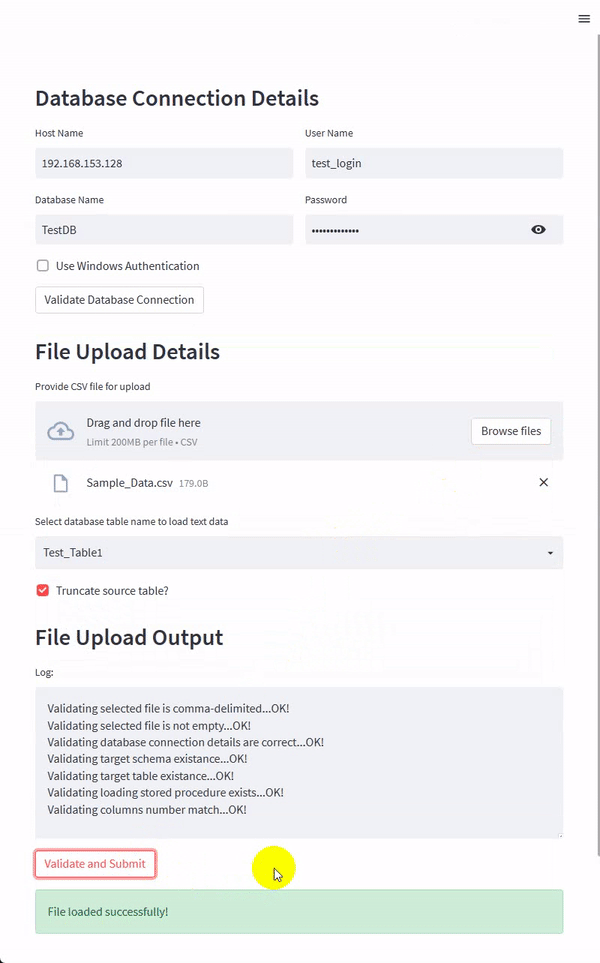
Most of the code changes relate to how Streamlit API works, and the components required to replicate the GUI app functionality. This means that any Python code handling the logic was mostly left unchanged – a testament to how easy both Streamlit and PySimpleGUI are to get up and running with. The below snippet of Python is used to build this tiny Streamlit app.
import streamlit as st
import tempfile
import csv
import os
from pathlib import Path
import helpers as helpers
_SQL_TABLES = ['Test_Table1', 'Test_Table2', 'Test_Table3']
_LOAD_STORED_PROC = 'usp_load_ext_table'
_TARGET_TABLE_SCHEMA_NAME = 'dbo'
st.header('Database Connection Details')
col1, col2 = st.columns([1, 1])
host_name = col1.text_input('Host Name', value='192.168.153.128')
db_name = col1.text_input('Database Name', value='TestDB')
win_auth = col1.checkbox('Use Windows Authentication', value=False)
validate = col1.button('Validate Database Connection')
user_name = col2.text_input('User Name', value='test_login')
password = col2.text_input('Password', type='password', value='test_password')
if validate:
validation = helpers.validate_db_input_values(
host_name, db_name, user_name, password)
if validation:
error_message = helpers.generate_error_message(validation)
st.error(error_message)
else:
conn = helpers.db_conn(HOSTNAME=host_name, DATABASE=db_name,
USERNAME=user_name, PASSWORD=password, USEWINAUTH=win_auth)
if conn:
st.success('Supplied credentails are valid.')
else:
st.error(
'Supplied credentials are invalid or there is a network connection issue!')
st.header('File Upload Details')
uploaded_file = st.file_uploader(
label='Provide CSV file for upload', type=['.csv'])
table_dropdown_value = st.selectbox(
'Select database table name to load text data', options=_SQL_TABLES)
truncate_source_table = st.checkbox('Truncate source table?', value=True)
st.header('File Upload Output')
logtxtbox = st.empty()
logtxt = ''
logtxtbox.text_area("Log: ", logtxt, height=200, key='fdgfgjjj')
upload_status = st.button('Validate and Submit')
def check_file_and_load(db_conn, full_path, table_dropdown_value, truncate_source_table_flag, _LOAD_STORED_PROC, _TARGET_TABLE_SCHEMA_NAME):
logtxt = 'Validating selected file is comma-delimited...'
logtxtbox.text_area("Log: ", logtxt, height=200)
# check csv file is comma delimited
with open(full_path, 'r', newline='') as f:
reader = csv.reader(f, delimiter=",")
dialect = csv.Sniffer().sniff(f.read(1024))
if dialect.delimiter != ',':
logtxt = ''.join((logtxt, 'Failed!\n'))
logtxtbox.text_area('Log: ', logtxt, height=200)
return
else:
logtxt = ''.join((logtxt, 'OK!\n'))
logtxtbox.text_area('Log: ', logtxt, height=200)
# check csv file is not empty
logtxt = ''.join((logtxt, 'Validating selected file is not empty...'))
with open(full_path, 'r', newline='') as f:
reader = csv.reader(f, dialect)
ncols = len(next(reader))
f.seek(0)
nrow = len(list(reader))
if nrow < 2:
logtxt = ''.join((logtxt, 'Failed!\n'))
logtxtbox.text_area('Log: ', logtxt, height=200)
return
else:
logtxt = ''.join((logtxt, 'OK!\n'))
logtxtbox.text_area('Log: ', logtxt, height=200)
# check for database connection values correctness
logtxt = ''.join(
(logtxt, 'Validating database connection details are correct...'))
conn = db_conn(host_name, db_name, user_name, password, win_auth)
if conn:
logtxt = ''.join((logtxt, 'OK!\n'))
logtxtbox.text_area('Log: ', logtxt, height=200)
else:
logtxt = ''.join((logtxt, 'Failed!\n'))
logtxtbox.text_area('Log: ', logtxt, height=200)
return
# check required schema exists on the target server
logtxt = ''.join((logtxt, 'Validating target schema existance...'))
with conn.cursor() as cursor:
sql = """SELECT TOP (1) 1 FROM {target_db}.sys.schemas
WHERE name = '{target_schema}'""".format(target_db=db_name, target_schema=_TARGET_TABLE_SCHEMA_NAME)
cursor.execute(sql)
rows = cursor.fetchone()
if rows:
logtxt = ''.join((logtxt, 'OK!\n'))
logtxtbox.text_area('Log: ', logtxt, height=200)
else:
logtxt = ''.join((logtxt, 'Failed!\n'))
logtxtbox.text_area('Log: ', logtxt, height=200)
return
# check selected table exists on the target server
logtxt = ''.join((logtxt, 'Validating target table existance...'))
with conn.cursor() as cursor:
sql = """SELECT TOP (1) 1 FROM {target_db}.information_schema.tables
WHERE table_name = '{target_table}'""".format(target_db=db_name, target_table=table_dropdown_value)
cursor.execute(sql)
rows = cursor.fetchone()
if rows:
logtxt = ''.join((logtxt, 'OK!\n'))
logtxtbox.text_area('Log: ', logtxt, height=200)
else:
logtxt = ''.join((logtxt, 'Failed!\n'))
logtxtbox.text_area('Log: ', logtxt, height=200)
return
# check if insert sored proc exists
logtxt = ''.join((logtxt, 'Validating loading stored procedure exists...'))
with conn.cursor() as cursor:
sql = """SELECT TOP (1) 1 FROM {target_db}.sys.objects WHERE type = 'P' AND OBJECT_ID = OBJECT_ID('dbo.usp_load_ext_table')""".format(
target_db=db_name)
cursor.execute(sql)
sp = cursor.fetchone()
if sp:
logtxt = ''.join((logtxt, 'OK!\n'))
logtxtbox.text_area('Log: ', logtxt, height=200)
else:
logtxt = ''.join((logtxt, 'Failed!\n'))
logtxtbox.text_area('Log: ', logtxt, height=200)
return
# check if number of columns matches
logtxt = ''.join((logtxt, 'Validating columns number match...'))
with conn.cursor() as cursor:
sql = """SELECT COUNT(1) FROM {target_db}.information_schema.columns
WHERE table_name = '{target_table}'""".format(target_db=db_name, target_table=table_dropdown_value)
cursor.execute(sql)
dbcols = cursor.fetchone()[0]
if dbcols == ncols:
logtxt = ''.join((logtxt, 'OK!\n'))
logtxtbox.text_area('Log: ', logtxt, height=200)
else:
logtxt = ''.join((logtxt, 'Failed!\n'))
logtxtbox.text_area('Log: ', logtxt, height=200)
return
logtxt = ''.join((logtxt, 'Attempting to load...'))
with conn.cursor() as cursor:
sql = '''\
DECLARE @col_names VARCHAR (MAX);
EXEC TestDB.dbo.{sp_name}
@temp_target_table_name=?,
@target_table_name=?,
@target_table_schema_name=?,
@file_path=?,
@truncate_target_table=?,
@col_names = @col_names OUTPUT;
SELECT @col_names AS col_names
'''.format(sp_name=_LOAD_STORED_PROC)
params = ('##'+table_dropdown_value, table_dropdown_value,
_TARGET_TABLE_SCHEMA_NAME, full_path, truncate_source_table_flag)
cursor.execute(sql, params)
col_names = cursor.fetchval()
if truncate_source_table_flag == 1:
test_1_sql = 'SELECT TOP (1) 1 FROM (SELECT {cols} FROM {temp_target_table_name} EXCEPT SELECT {cols} FROM {target_table_schema_name}.{target_table_name})a'.format(
temp_target_table_name='##'+table_dropdown_value, target_table_schema_name=_TARGET_TABLE_SCHEMA_NAME, target_table_name=table_dropdown_value, cols=col_names)
cursor.execute(test_1_sql)
test_1_rows = cursor.fetchone()
test_2_sql = 'SELECT TOP (1) status FROM {temp_target_table_name}'.format(
temp_target_table_name='##'+table_dropdown_value)
cursor.execute(test_2_sql)
test_2_rows = cursor.fetchone()[0]
if test_1_rows and test_2_rows != 'SUCCESS':
st.error('File failed to load successfuly, please troubleshoot!')
return
else:
st.success('File loaded successfully!')
elif truncate_source_table_flag == 0:
test_1_sql = 'SELECT COUNT(1) as ct FROM (SELECT {cols} FROM {temp_target_table_name} INTERSECT SELECT {cols} FROM {target_table_schema_name}.{target_table_name})a'.format(
temp_target_table_name='##'+table_dropdown_value, target_table_schema_name=_TARGET_TABLE_SCHEMA_NAME, target_table_name=table_dropdown_value, cols=col_names)
cursor.execute(test_1_sql)
test_1_rows = cursor.fetchone()[0]
test_2_sql = 'SELECT TOP (1) status FROM {temp_target_table_name}'.format(
temp_target_table_name='##'+table_dropdown_value)
cursor.execute(test_2_sql)
test_2_rows = cursor.fetchone()[0]
if nrow-1 != test_1_rows or test_2_rows != 'SUCCESS':
st.error('File failed to load successfuly, please troubleshoot!')
return
else:
st.success('File loaded successfully!')
if upload_status:
validation = helpers.validate_db_input_values(
host_name, db_name, user_name, password)
if validation:
error_message = helpers.generate_error_message(validation)
st.error(error_message)
if uploaded_file is not None:
with tempfile.NamedTemporaryFile(delete=False, dir='.', suffix='.csv') as f:
f.write(uploaded_file.getbuffer())
fp = Path(f.name)
full_path = str(Path(f.name))
file_name = Path(full_path).name
file_path = Path(full_path).parent
db_conn = helpers.db_conn
check_file_and_load(db_conn, full_path, table_dropdown_value,
truncate_source_table, _LOAD_STORED_PROC, _TARGET_TABLE_SCHEMA_NAME)
else:
st.error('Please select at least one flat file for upload!')
Conclusion
Python has brought a large number of people into the programming community. The number of programs and the range of areas it touches is mindboggling. But more often than not, these technologies are out of reach of all but a handful of people. Most Python programs are “command line” based. This isn’t a problem for programmer-types as we’re all used to interacting with computers through a text interface. While programmers don’t have a problem with command-line interfaces, most “normal people” do. This creates a digital divide, a “GUI Gap”. Adding a GUI or a Web front end to a program opens that program up to a wider audience as it instantly becomes more approachable. Visual interfaces can also make interacting with some programs easier, even for those that are comfortable with a command-line interface.
Both PySimpleGUI and Streamlit provide an easy entry barrier for anyone, even Python novices, and democratise Web and GUI development. For simple projects, these frameworks allow citizen developers to rapidly create value and solve business problems without needing to understand complex technologies and tools. And whilst more critical LOB (Line of Business) apps will demand the use of more advanced technologies in foreseeable future, for small projects requiring simple interfaces and business logic, PySimpleGUI and Streamlit provide a ton of immediate value. Alternatively, one can go even further down the simplification route and try something like Gooey which conveniently converts (almost) any Python 3 console program into a GUI application with a single line of code!




Never thought Polybase could be used in this capacity and don't think Microsoft advertised this feature (off-loading DB data as…