Twitter Data Sentiment Analysis Using etcML and Python
A while ago I put together a few posts describing Twitter sentiment analysis using a few different tools and services e.g. Zapier, RapidMiner, SQL etc. which can be found HERE, HERE and HERE. All those techniques, although presented in a rudimentary fashion in my blog require an analyst to go through a comprehensive list of processes which are a necessary prelude to getting any valid information out of the datasets processed. Data mining is still a discipline very much entrenched in a field of mathematics and supporting software and algorithms, however, recently I have witnessed an emergence of web services which tend to simplify and reduce the complexities (at least on the face value) involved in a traditional approach to advanced data mining. One such service comes from a group of Stanford machine learning researches and serves as a sentiment analysis tool for textual inputs e.g. Twitter feeds. It’s called etCML (link HERE) and even though there is no information provided on the technical aspects of the project, since the development is led by Andrew Ng and Richard Socher my guess would be that it uses NaSent (Neural Analysis of Sentiment) deep learning algorithm which you can read more about at the Stanford Engineering blog HERE.
Currently, the most widely used methods of sentiment analysis have been limited to so-called ‘bag of words’ models, which don’t take word order into account. They simply parse through a collection of words, mark each as positive or negative, and use that count to estimate whether a sentence or paragraph has a positive or negative meaning.
NaSent claims to be different. It can identify changes in the polarity of each word as it interacts with other words around it. In evaluating sample sentences, NaSent organizes words into what the scientists call grammatical tree structures (as per image below) that put the words into context.
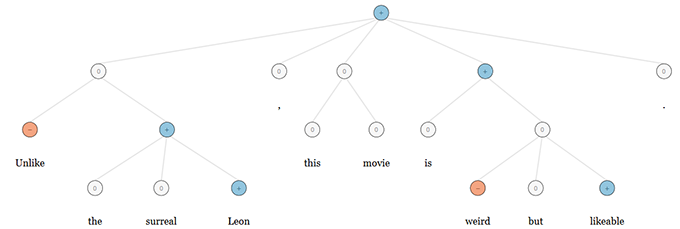
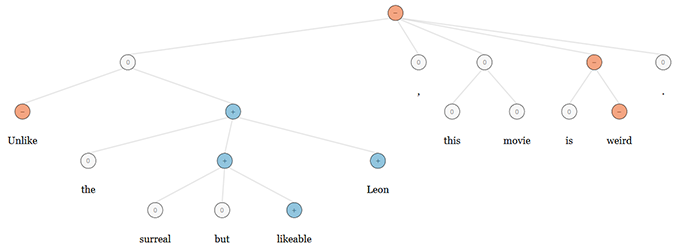
For example, NaSent’s analysis of the sentence: ‘Unlike the surreal Leon, this movie is weird but likeable.’ Red nodes indicate that the model assigned a negative sentiment to the underlying word or phrase, such as in the case of ‘weird.’ The phrase ‘is weird but likeable’ is correctly assigned a positive sentiment (indicated by blue). Similarly, in NaSent’s analysis of ‘Unlike the surreal but likeable Leon, this movie is weird.’ Sentence, the model correctly focuses on the overall negative sentiment, even though this sentence uses exactly the same words as the one above. This is represented by the grammatical tree structure as per image below.
To build NaSent, Socher and his team used 12,000 sentences taken from the movie reviews website Rotten Tomatoes. They split these sentences into roughly 214,000 phrases that were labelled as very negative, negative, neutral, positive, or very positive, and then they fed this labelled data into the system, which NaSent then used to predict whether sentences were positive, neutral or negative on its own. NaSent, the researchers say, was about 85 percent accurate, an improvement over the 80 percent accuracy of previous models. The algorithm effectiveness based on the sample text parsed can be tested and analyzed using the online demo setup HERE.
Back to etCML and specific use cases to analyse text data. The service is very easy to use indeed with step-by-step instructions provided. In fact the biggest hassle as far as utilizing it as a classification tool is the fact that data needs to be submitted in either a text (tab- separated values) or zipped format. Everything else is straightforward and anyone looking at trialling it will be pleasantly surprised. At the moment there is no publicly available API so unfortunately, manual dragging and dropping is as good as it gets. Even though the tool allows for uploading your own data for further classification (can be labelled or unlabelled) as well as to train the classifiers on your datasets, I think that many people will be using it interactively to perform sentiment analysis on Twitter data. You simply click on ‘Search fort tweets’, enter a hashtag, keyword or handle, choose a classifier (it will automatically suggest one designed for sentiment analysis on tweets) and etCML does the rest. It returns an interactive timeline visualization, a collection of tweets that scored strongly for each label, and a searchable table for table for sorting the results or finding specific words/tweets. I had a quick play with some of the more popular Twitter handles and hashtags and have to say that sentiment tagging was mostly accurate, however, not without a few odd cases where I felt the message was somewhat ‘misunderstood’. It etCML defence, majority of feeds that the algorithm failed to tag accurately were sarcastic in nature.
Below is a short video outlining etCML application and functionality so if text (sentiment) classification is what you need I think that this service can meet some basic requirements, particularly for ad hoc analysis.
Also, if you intend to use this tool for Twitter sentiment analysis with your own feeds collection, you can use the below Python code to harvest the tweets (text file and Python code file used in the above demo can be downloaded from HERE).
"""
Application:
This Python script fetches Twitter feeds for further analysis (sentiment analysis using etCML web service).
It executes multiple times (number of iterations set by the variable), stores tweets temporarily in a SQLite
database (mainly for duplicates removal functionality) and outputs relevant tweets as a text format document,
removing URL shortening links and certain characters.
For a full script application and solution overview please visit www.bicortex.com
Pre-requisites:
1. Python version 3 with Twython wrapper for Twitter API installed. Twython wrapper can be downloaded from here:
https://github.com/ryanmcgrath/twython
2. Twitter registered application in order to provide consumer_key, consumer_secret, access_token
and access_token_secret. All these can be sourced by registering and application through the following link:
https://dev.twitter.com/apps
Things to adjust:
1. Insert you own consumer_key, consumer_secret, access_token and access_token_secret keys.
2. Populate 'harvest_list' with the key words of interest which will be reflected in the Twitter
feeds search content output.
3. Adjust 'file_location' variable to correspond to the folder path of your choice
"""
#import necessary modules
from twython import Twython
import sys
import os
import time
import sqlite3
import re
#set up some of the variables/lists
db_filename = r"c:\Twitter_Test_Data_Folder\temp_db" #database file name
consumer_key = "" #application's consumer key
consumer_secret = "" #application's consumer secret
access_token = "" #application's access_token
access_token_secret = "" #application's access_token_secret
harvest_keyword = 'Microsoft' #searches Twitter feeds with this keyword
file_location = r'c:\Twitter_Test_Data_Folder\Twitter_Test_Data.txt'
exec_times = 100 #number of times Twitter feeds will be fetched
pause_for = 15 #sleep for 30 seconds between intervals
#define database table and database dropping query
create_schema = "CREATE TABLE twitter_feeds \
(id integer primary key autoincrement not null,\
twitter_feed text)"
drop_schema = "DROP TABLE twitter_feeds"
#create database file and schema using the scripts above
db_is_new = not os.path.exists(db_filename)
with sqlite3.connect(db_filename) as conn:
if db_is_new:
print("Creating temp database schema on " + db_filename + " database ...\n")
conn.executescript(create_schema)
else:
print("Database schema may already exist. Dropping database schema on " + db_filename + "...")
#os.remove(db_filename)
conn.executescript(drop_schema)
print("Creating temporary database schema...\n")
conn.executescript(create_schema)
#fetch Twitter feeds and format them, removing unwanted characters/strings
def fetch_twitter_feeds():
twitter = Twython(consumer_key, consumer_secret, access_token, access_token_secret)
search_results = twitter.search(q=harvest_keyword, rpp="100")
for tweet in search_results['statuses']:
try:
#the following can be enabled to see Twitter feeds content being fetched
#print("-" * 250)
#print("Tweet from @%s -->" % (tweet['user']['screen_name']))
#print(" ", tweet['text'], "\n")
#print("-" * 250)
feed = tweet['text']
feed = str(feed.replace("\n", "")) #concatnate if tweet is on multiple lines
feed = re.sub(r'http://[\w.]+/+[\w.]+', "", feed, re.IGNORECASE) #remove http:// URL shortening links
feed = re.sub(r'https://[\w.]+/+[\w.]+',"", feed, re.IGNORECASE) #remove https:// URL shortening links
feed = re.sub('[@#$<>:%&]', '', feed) #remove certain characters
cursor = conn.cursor()
cursor.execute("INSERT INTO twitter_feeds (twitter_feed) SELECT (?)", [feed]) #populate database table with the feeds collected
except:
print("Unexpected error:", sys.exc_info()[0])
conn.rollback()
finally:
conn.commit()
#delete duplicated, too short or empty records from 'twitter_feeds' table
def drop_dups_and_short_strs():
try:
cursor = conn.cursor()
cursor.execute("DELETE FROM twitter_feeds WHERE id NOT IN(\
SELECT MIN(id) FROM twitter_feeds GROUP BY twitter_feed)")
cursor.execute("DELETE FROM twitter_feeds WHERE LENGTH(twitter_feed) < 10")
cursor.execute("DELETE FROM twitter_feeds WHERE twitter_feed IS NULL OR twitter_feed = ''")
except:
print("Unexpected error:", sys.exc_info()[0])
conn.rollback()
finally:
conn.commit()
#display progress bar in a console
def progressbar(it, prefix = "", size = 60):
count = len(it)
def _show(_i):
x = int(size*_i/count)
print("%s[%s%s] %i/%i\r" % (prefix, "#"*x, "."*(size-x), _i, count), end='')
sys.stdout.flush()
_show(0)
for i, item in enumerate(it):
yield item
_show(i+1)
print()
if __name__ == '__main__':
try:
for i, z in zip(range(exec_times+1), progressbar(range(exec_times), "Fetching Twitter Feeds: ", 100)):
fetch_twitter_feeds()
time.sleep(pause_for)
drop_dups_and_short_strs()
cursor = conn.cursor()
tweets = cursor.execute("SELECT twitter_feed tw FROM twitter_feeds")
f = open(file_location, 'w', encoding='utf-8')
for row in tweets:
row = ''.join(row)
f.write(row)
f.write("\n")
except:
print("Unexpected error:", sys.exc_info()[0])
finally:
conn.close()
f.close()
os.remove(db_filename)
http://scuttle.org/bookmarks.php/pass?action=add
This entry was posted on Sunday, January 5th, 2014 at 6:23 am and is filed under Data Mining, How To's. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.



admin May 1st, 2014 at 11:15 am
Hi there and thanks for your kind comments. I’m more of a holistic BI guy who occasionally dabbles in data mining and advanced analytics so I’m not an expert you’re probably looking for. Saying that, I enjoy it more and more and from what I see, read and hear from other professionals out there is that as far as sentiment analysis is concerned I would definitely go with Python and/or R (Python over R in my books). There is a plethora of different applications, services, languages etc out there so you’re really spoiled for choices but given your 4 months time frame and familiarity with programming paradigms I would go with Python as a Swiss army knife for all activities you outlined above i.e. web scraping, database connectivity and further analysis. I tried using .NET (either C#, VB or F#) for a while but quickly got discouraged as most of my applications are in the realm of short, single-purpose scripts and Python fits the bill beautifully in that regard without the unnecessary verbosity. Python also has an advantage over R as it’s an a multipurpose language i.e. if you ever need to use it for something other then data analysis/scientific programming e.g. GUIs, simple games, Web develpment etc. you can easily do it without having to learn another language. In the nutshell – go with Python for what you’re trying to achieve (alternatively I would also recommend RapidMiner for a nicely simplified but powerful environment if you’re pressed for time)……cheers, Marcin