Twitter Sentiment Analysis – Part 2. Extracting and Mining Twitter Data Using Zapier, RapidMiner and Google/Microsoft Tools
In this post I would like to build on what was developed in first iteration to this two part series describing Twitter data extraction and sentiment analysis. In part one, I explained how anyone can extract Twitter data into Google Docs spread sheet and then transfer is into a local environment using two different methods. In this series-final post, I would like to show you how this data can be analyzed for sentiment i.e. whether a specific Twitter feed can be considered as negative or positive. To do this, I will employ free software called RapidMiner which can be downloaded from HERE as well as two separate data sets of already pre-classified tweets for model learning and Microsoft SQL Server for some data scrubbing and storage engine. Most of the files I am using in this project can be downloaded from HERE (including all the SQL code, YouTube video, sample data files etc.).
To get started, I created two tables which will house the data, one for reference data which already contains sentiment information and one for the data extracted from Twitter which hasn’t been analysed yet using the following code:
CREATE TABLE [dbo].[Twitter_Training_Data] ([ID] [int] IDENTITY(1,1) NOT NULL, [Feed] [varchar](max) NULL, [Sentiment] [varchar](50) NULL) ON [PRIMARY] GO CREATE TABLE [dbo].[Twitter_Test_Data] ([ID] [int] IDENTITY(1,1) NOT NULL, [Feed] [varchar](max) NULL) ON [PRIMARY] GO
Next, I downloaded two files containing already sentiment-tagged Twitter feeds. These are quite large in size and probably overkill for this project but, in theory, the more data we provide for model to learn to distinguish between NEGATIVE and POSITIVE categories, the better it should perform. I imported and percentage sampled (for smaller dataset) the data from the two pre-processed files using a small SSIS package into my local MS SQL Server database together with the file containing Twitter feeds created using Zapier (see previous post) which hasn’t been analysed yet. The records from the reference data went into ‘Twitter_Training_Data’ table whereas the feeds we will mine were inserted into ‘Twitter_Test_Data’ table. The whole SSIS solution is as per below (Control and Data Flow)
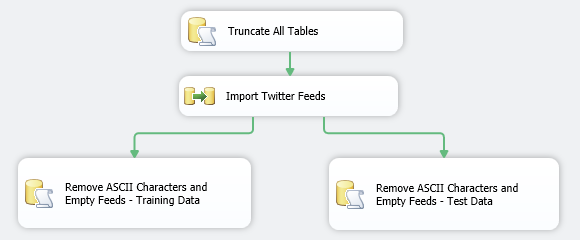

To be more flexible, I have also created two variables inside the package which hold the table names the package populates.
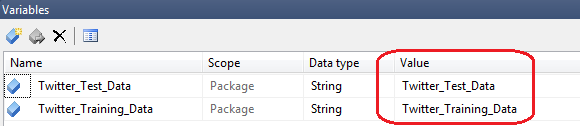
These variables get passed into the stored procedure which allows it to be applied to both tables. To pass the variables to the data cleansing stored procedure I assigned the variable name in ‘Parameters Mapping’ property of each of the two Execute SQL Tasks with its corresponding data type to a parameter as per below.

The reason for storing this information in a database rather than a file is simply because once in a table, the data can undergo further cleaning and formatting using the logic implemented in the SQL code. As I found out the hard way, a lot of the strings people put into their tweets contain tons of useless ACSII characters and shortened URL references which only pollute the test data and confuse the model. Also, reading data from a database can incur substantial performance increase. To further clean the data, I created two functions, one to weed out non-alphanumeric characters and one to remove references to URLs. As the classification mining model relies on words which are greater than 2 characters in length and web application generated URLs are mostly comprised of artificially created strings, these characters don not contribute to the overall outcome and in many cases can in fact skew the output. These two functions get used by the stored procedure which executes as the final step of the ETL package. The SQL code for those is as per below.
--CREATE STRING SPLITTING FUNCTION
CREATE FUNCTION [dbo].[Split] (@sep VARCHAR(32), @s VARCHAR(MAX))
RETURNS @t TABLE
(val VARCHAR(MAX))
AS
BEGIN
DECLARE @xml XML
SET @XML = N'' + REPLACE(@s, @sep, '') + ''
INSERT INTO @t(val)
SELECT r.value('.','VARCHAR(1000)') as Item
FROM @xml.nodes('//root/r') AS RECORDS(r)
RETURN
END
--CREATE FUNCTION TO REMOVE UNWANTED CHARACTERS
CREATE FUNCTION [dbo].[RemoveSpecialChars]
(@Input VARCHAR(MAX))
RETURNS VARCHAR(MAX)
BEGIN
DECLARE @Output VARCHAR(MAX)
IF (ISNULL(@Input,'')='')
SET @Output = @Input
ELSE
BEGIN
DECLARE @Len INT
DECLARE @Counter INT
DECLARE @CharCode INT
SET @Output = ''
SET @Len = LEN(@Input)
SET @Counter = 1
WHILE @Counter <= @Len
BEGIN
SET @CharCode = ASCII(SUBSTRING(@Input, @Counter, 1))
IF @CharCode=32 OR @CharCode BETWEEN 48 and 57 OR @CharCode BETWEEN 65 AND 90
OR @CharCode BETWEEN 97 AND 122
SET @Output = @Output + CHAR(@CharCode)
SET @Counter = @Counter + 1
END
END
RETURN @Output
END
--CREATE STRING CLEANING STORED PROCEDURE
CREATE PROCEDURE [dbo].[usp_Massage_Twitter_Data]
(@table_name NVARCHAR(100))
AS
BEGIN
BEGIN TRY
SET NOCOUNT ON
--CREATE CLUSTERED INDEX SQL
DECLARE @SQL_Drop_Index NVARCHAR(1000)
SET @SQL_Drop_Index =
'IF EXISTS (SELECT name FROM sys.indexes
WHERE name = N''IX_Feed_ID'')
DROP INDEX IX_Feed_ID ON ' + @table_name + '
CREATE CLUSTERED INDEX IX_Feed_ID
ON ' + @Table_Name + ' (ID)';
--REMOVE UNWANTED CHARACTERS SQL
DECLARE @SQL_Remove_Chars NVARCHAR(2000)
SET @SQL_Remove_Chars =
'UPDATE ' + @Table_Name + '
SET feed = (select dbo.RemoveSpecialChars(feed))
DECLARE @z int
DECLARE db_cursor CURSOR
FOR
SELECT id
FROM ' + @Table_Name + '
OPEN db_cursor
FETCH NEXT
FROM db_cursor INTO @z
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE @Combined_String VARCHAR(max);
WITH cte(id, val) AS (
SELECT a.id, fs.val
FROM ' + @Table_Name + ' a
CROSS APPLY dbo.split('' '', feed) AS fs
WHERE fs.val NOT LIKE ''%http%'' and a.id = @z)
SELECT @Combined_String =
COALESCE(@Combined_String + '' '', '''') + val
FROM cte
UPDATE ' + @Table_Name + '
SET feed = ltrim(rtrim(@Combined_String))
WHERE ' + @Table_Name + '.id = @z
SELECT @Combined_String = ''''
FETCH NEXT
FROM db_cursor INTO @z
END
CLOSE db_cursor
DEALLOCATE db_cursor'
--RESEED IDENTITY COLUMN & DELETE EMPTY RECORDS SQL
DECLARE @SQL_Reseed_Delete NVARCHAR(1000)
SET @SQL_Reseed_Delete =
'IF EXISTS (SELECT c.is_identity
FROM sys.tables t
JOIN sys.schemas s
ON t.schema_id = s.schema_id
JOIN sys.Columns c
ON c.object_id = t.object_id
JOIN sys.Types ty
ON ty.system_type_id = c.system_type_id
WHERE t.name = ''+ @Table_Name +''
AND s.Name = ''dbo''
AND c.is_identity=1)
SET IDENTITY_INSERT ' + @Table_Name + ' ON
DELETE FROM ' + @Table_Name + '
WHERE Feed IS NULL or Feed =''''
DBCC CHECKIDENT (' + @Table_Name + ', reseed, 1)
SET IDENTITY_INSERT ' + @Table_Name + ' OFF
ALTER INDEX IX_Feed_ID ON ' + @Table_Name + '
REORGANIZE'
EXECUTE sp_executesql @SQL_Drop_Index
EXECUTE sp_executesql @SQL_Remove_Chars
EXECUTE sp_executesql @SQL_Reseed_Delete
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION
END
DECLARE @ErrorMessage NVARCHAR(4000);
DECLARE @ErrorSeverity INT;
DECLARE @ErrorState INT;
SELECT @ErrorMessage = ERROR_MESSAGE(),
@ErrorSeverity = ERROR_SEVERITY(),
@ErrorState = ERROR_STATE();
RAISERROR (
@ErrorMessage
,-- Message text.
@ErrorSeverity
,-- Severity.
@ErrorState -- State.
);
END CATCH
IF @@TRANCOUNT > 0
BEGIN
COMMIT TRANSACTION
END
END
The package extracts Twitter feeds from each of the three CSV files (I downloaded them as XLSX and converted into CSV simply by opening them up in Excel and saving again as CSV as SSIS can be a bit temperamental using Excel as a data source), storing them in assigned tables and performing some data cleansing using the above SQL code.
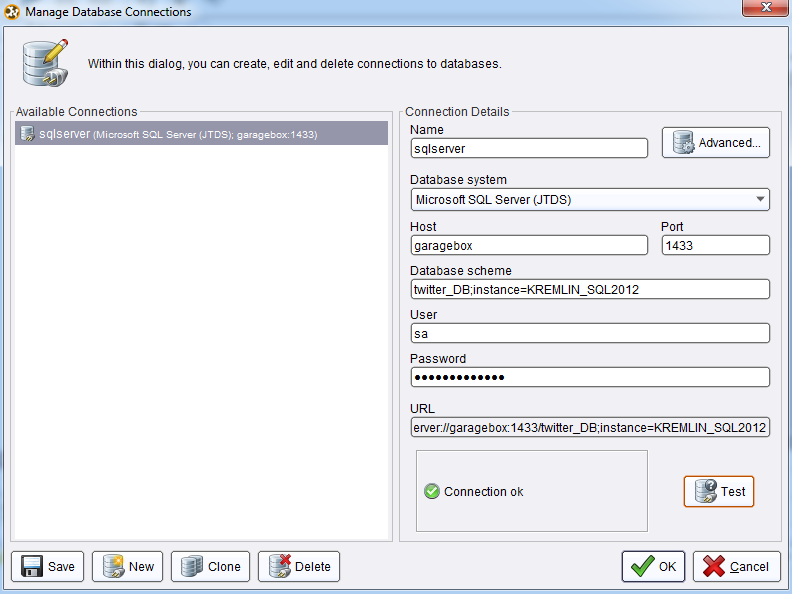
After both training data and new observations have been loaded into the database it is time to fire up RapidMiner. If you have any experience with ETL applications relying on drag-and-drop transformations functionally you should feel at home using RapidMiner. Using it is similar to building an SSIS routine on a development pane and linking individual transformations to create a logical data flow. To start, we need to create a database connection to read our tweets from SQL Server. There are numerous tutorials on the Internet and a few particularly useful ones on YouTube on how to install JTDE driver on the Windows box to read data from SQL Server instance so I won’t go into details on how to accomplish that. Below is a screen shot of the connection I set up in RapidMiner on my machine.
Finally, it is time to develop the model and the rest of the solution for Twitter data classification. As explaining it step by step with all supporting screen shots would require at least another post, I decided to provide this overview as a short footage hosted on YouTube – see below.
You can also download the original footage with all the complementary files e.g. SQL code, source data files etc. from HERE.
If you enjoyed this post please also check out my earlier version of Twitter sentiment analysis using pure SQL and SSIS which can be viewed from HERE. Finally, if you’re after a more adhoc/playful sentiment analysis tool for Twitter data and (optionally) have some basic knowledge of Python programming language, check out my post on using etcML web based tool under THIS link.
http://scuttle.org/bookmarks.php/pass?action=addThis entry was posted on Friday, March 29th, 2013 at 4:54 pm and is filed under SQL, SSIS. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.



admin September 16th, 2013 at 10:46 pm
Hi there. Thanks for reading my blog and your comments and questions. I tried to address your queries as per below. Please feel free to contact me if you require further clarification.
Question 1 – Yes, that’s correct. You could just use RepidMiner and import the files straight from a CSV file. The problem I encountered was that given the number of records in the sample files provided as well as my machine hardware limitations e.g. memory, CPU (I am only guessing here) I found the import process very painful and time consuming. RapidMiner would crash, become unresponsive or throw an error so given the fact I already had SQL Server database installed on my machine, it made sense to import the data into the database first. This decreased data retrieval time considerably even though it involves going through a few additional steps. In the end it was worthwhile as, pending your technical skills, you can always process your data even further e.g. cleanse it, remove certain strings or characters etc.
As far as the three files you mentioned, one contains feeds which have not been analysed – no sentiment attached, whereas the other two contain already pre-classified feeds. The simplest terms, in order to determine if something is ‘negative’ or ‘positive’ is to compare it to a similar entity which has already been tagged as such. For that purpose we are required to have two sample datasets with already pre-labelled feeds, otherwise RapidMiner and the algorithm applied would not be able to train/learn itself to distinguish between whether the sample we wish to analyse has positive connotations or negative ones. In my case, the dataset containing feeds which have already been tagged comes from the Internet, I downloaded it from a university’s website (cannot remember exactly which one). The dataset which contains feeds which have not been tagged comes from Twitter, I downloaded those feeds using the methods and services provided in the first post e.g. Zapier, SQL Server SSIS etc. Please also note that my sample feeds contained a lot of strings in foreign languages. If you were to do this analysis more thoroughly, I would recommend sticking to one language only – it would be much more accurate to have all three datasets with feeds in English only.
Question 2 – I am not an expert myself, actually far from it. RapidMiner was my second attempt in exploring data mining territory so knowledge wise we are probably on par if you you’re also just starting out. I wrote another post about mining Twitter data using pure SQL and a little bit of SSIS and .Net a while ago. If you’re interested it shouldn’t be hard to find on my blog.
Hope that helps………, Marcin!