January 4th, 2026 / 4 Comments » / by admin
Note: All code from supporting this architecture can be downloaded from my OneDrive folder HERE.
Introduction
Organizations looking to modernize and improve their data ingestion capabilities have traditionally relied on ETL/ELT tools for their data ingestion and transformation needs. This created a thriving tangential industry, with a wide ecosystem of tools fit for all possible scenarios, however, relying on a separate platform for ETL/ELT introduces additional costs and complexity. Specifically, external ETL tools demand extra licensing fees which are often tied to data ingress/egress volumes or API calls. They also create architectural complexity as developers need to become familiar with the functionality, creating more cognitive load and distracting from the main problem statement. This usually results is harder maintenance, slower development, and a lack of unified governance over the entire data lifecycle.
The rise of the modern Data Cloud, particularly Snowflake, offers a powerful alternative: building sophisticated ETL/ELT pipelines directly within the platform using native code. By leveraging key features like JDBC/ODBC connectivity for seamless data movement, User-Defined Functions (UDFs) for custom, reusable logic, and the scale-out power of Snowpark (which allows data engineers to write Python, Java, or Scala code), we can bypass proprietary external tools completely.
The following solution design offers a simple metadata-driven ingestion framework (baseline implementation) for loading data from Azure SQL Database or other JDBC-supported RDBMS engines into Snowflake with intelligent parallelization and cluster-aware scaling. Built as a single scalable process, the solution implements a work-stealing pattern where workers continuously pull tasks from a dynamic queue as they complete, ensuring optimal resource utilization across multi-cluster Snowflake warehouses. The framework operates entirely through centralized metadata tables that define source-to-target mappings, partitioning strategies, JDBC configurations, and column-level transformations, enabling automated schema introspection and dynamic query construction without hard-coded configurations. It features Snowflake secrets integration for secure connection, comprehensive error handling with task-level failure recovery, and linear scalability that automatically adapts to different warehouse configurations.
The following diagram depicts the framework’s high-level topology and how each of these components work in concert to ingest source data into Snowflake landing objects (click on image to enlarge).
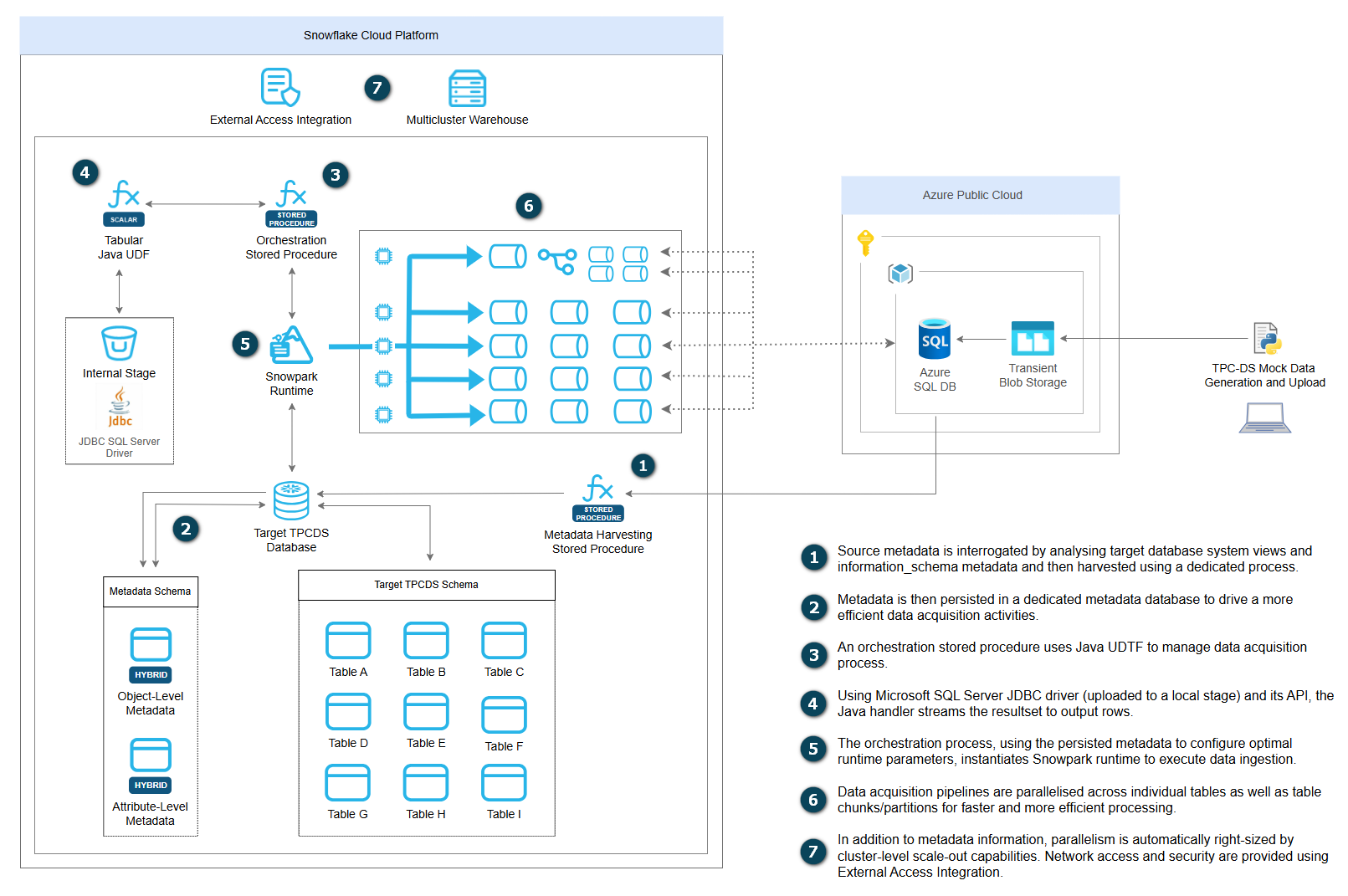
Source Data and Environment Prep
To demonstrate how this architecture works in practice, this demo utilizes a standard TPC-DS dataset (10GB volume) as a data source. The source data files (csv format) generated by TPC-DS utility were uploaded to a newly created Azure Blob container and then loaded into the Azure SQL Database. As TPC-DS utility does not generate headers which are useful for a range of subsequent data operations, a separate script was used to “merge” header files (also csv file format) with the TPC-DS output files.
On the Snowflake end (target environment) a dedicated database and metadata schema were created. The metadata schema is used to store two objects which govern data ingestion execution at a table and down to individual attributes level – etl_meta_object table is designed to hold all object-specific information e.g. row counts, source schema and table name, index size, data size, partition key whereas etl_meta_attribute table goes down to the individual field level, capturing information such as column name, data type, numeric precision and scale etc. This metadata-driven approach enables automated schema introspection, intelligent partition boundary calculations, and dynamic query construction without hard-coded configurations.
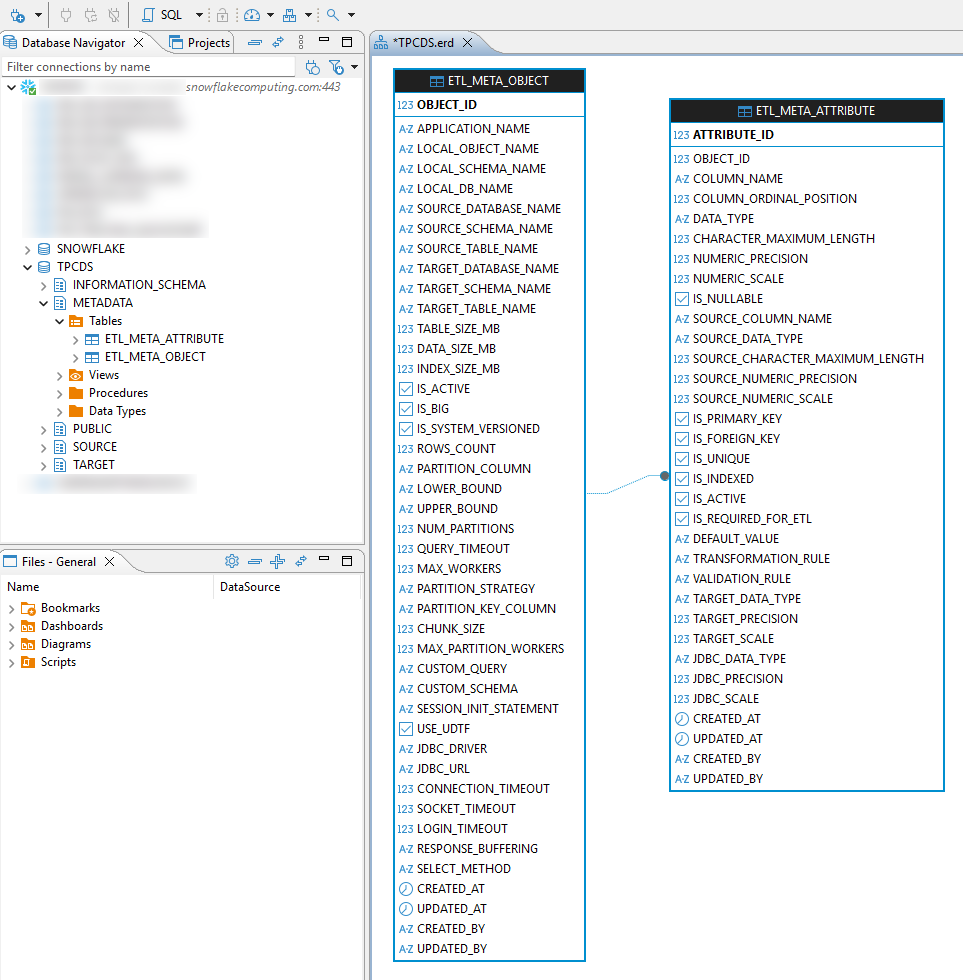
TPC-DS tables were replicated in the public schema, creating a like-for-like source-to-target mapping between the Azure SQL DB and Snowflake environments. The stage used for storing JDBC driver which provides the required API for interfacing Azure SQL DB with Snowflake was also created in the metadata schema. A dedicated script (utilizing Snow CLI) handles downloading, decompressing, and uploading JDBC driver from one of Microsoft’s repositories. The JDBC components provide encrypted connections, optimized connection pooling, and configurable timeout settings that ensure reliable data transfer across network boundaries.
Java Tabular function (READ_JDBC) is used to manage source connections, SQL execution and returning the results back to Snowflake. When invoked, it accepts a JDBC configuration OBJECT (driver class, connection URL, timeouts) and a SQL query string, establishes a JDBC connection to Azure SQL Server through the network rule, executes the query, and streams results as a TABLE of OBJECT rows. Each row is a map of column names to string values, which can be cast to specific types in SQL. This design allows Snowflake stored procedures to query external SQL Server databases and load data directly into Snowflake tables using INSERT…SELECT patterns, bypassing intermediate staging and enabling real-time data access through Snowflake’s secure egress framework. SQL connection authentication is managed via Snowflake-stored secret, network rule and access integration.
A dedicated stored procedure – sp_load_tpcds_data – is used to “harvest” all the required SQL Server metadata from its underlying system views and calculate additional parameters governing partitioning strategies and distribution across multiple partitions. To demonstrate its core concepts, its metadata-harvesting capability has been reduced to support only the most fundamental ingestion parameters across source objects and attributes levels, however, this can be expended with additional capabilities with no changes to this architecture.
Finally, the single-cluster and multi-cluster warehouse Snowpark ingestion stored procedures were developed to manage data acquisition across Azure SQL DB and Snowflake environments. It’s a metadata-driven orchestration engine designed for high-performance data ingestion from Azure SQL into Snowflake.
Architecture and Solution Design
Sequentially calling JDBC Java handler to stream data directly into Snowflake target tables might be a good idea for small scale, impromptu data interrogation activities. However, in order to take full advantage of Snowflake scale-out architecture and efficiently distribute data ingestion pipelines across multiple concurrent executing workers, a different approach is required.
The following architecture depicts how a single-node warehouse can be used to scale out and parallelize data acquisition, with no outside tooling, minimal queuing and without the need to rely on Snowflake tasks as an orchestration method.
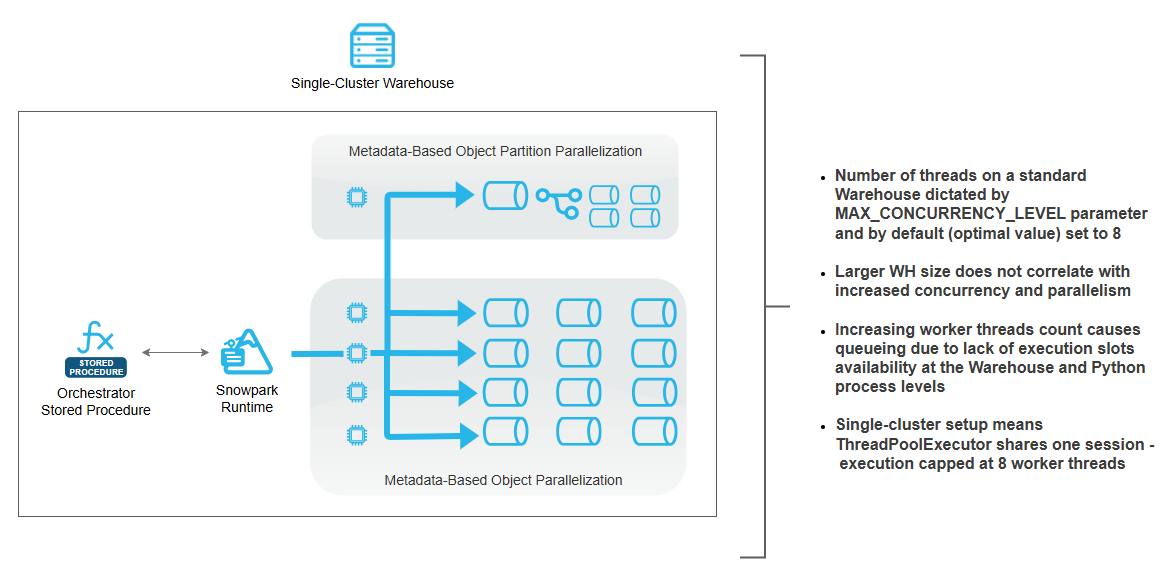
The solution implements parallel data loading framework that maximizes throughput within the constraints of a single warehouse cluster by leveraging multi-threaded concurrency patterns. At initialization, the framework performs dynamic warehouse introspection to determine the current cluster configuration, calculating theoretical worker capacity based on a fundamental assumption that each cluster node provides eight parallel execution slots. For single-node configuration, due to platform-level session constraints, the actual implementation enforces a practical concurrency ceiling of eight simultaneous operations per stored procedure invocation – this is due to default Snowflake concurrency level default cap of 8. While this threshold can be altered, Snowflake recommends caution, as this can create performance issues with memory allocation for larger queries and excessive queuing. The architecture employs a metadata-driven task generation strategy where it queries a centralized metadata repository containing table definitions, source-to-target mappings, and critically, partitioning specifications including partition columns, numeric boundary values, and desired partition counts. For large tables with defined partitioning strategies, the framework intelligently subdivides the data extraction workload into multiple independent tasks, each responsible for a specific numeric range of the partition key, enabling parallel extraction of disjoint data segments. Smaller tables without partitioning metadata are treated as atomic units requiring single-task processing. Each generated task encapsulates complete execution instructions including JDBC connection parameters, source query construction with column-level transformations (such as trimming string padding), target table specifications, and data type mapping rules that translate source database types to destination platform types. The execution engine utilizes a thread pool pattern where all tasks are submitted to a bounded worker pool that processes them asynchronously, with each worker thread independently establishing JDBC connections, executing parameterized SELECT queries with optional WHERE clause filters for partition ranges, streaming results through a custom external function that bridges the source database to the destination platform, and executing INSERT statements with explicit column mapping and type casting.
During the execution phase, we can clearly observe multiple workers processing either individual objects or objects’ partitions. By decoupling task definition from execution, the procedure ensures that all available compute resources remain fully utilized, eliminating the “long-tail” problem where a single large table blocks overall progress. Functionally, the procedure operates in two phases: orchestration and execution.
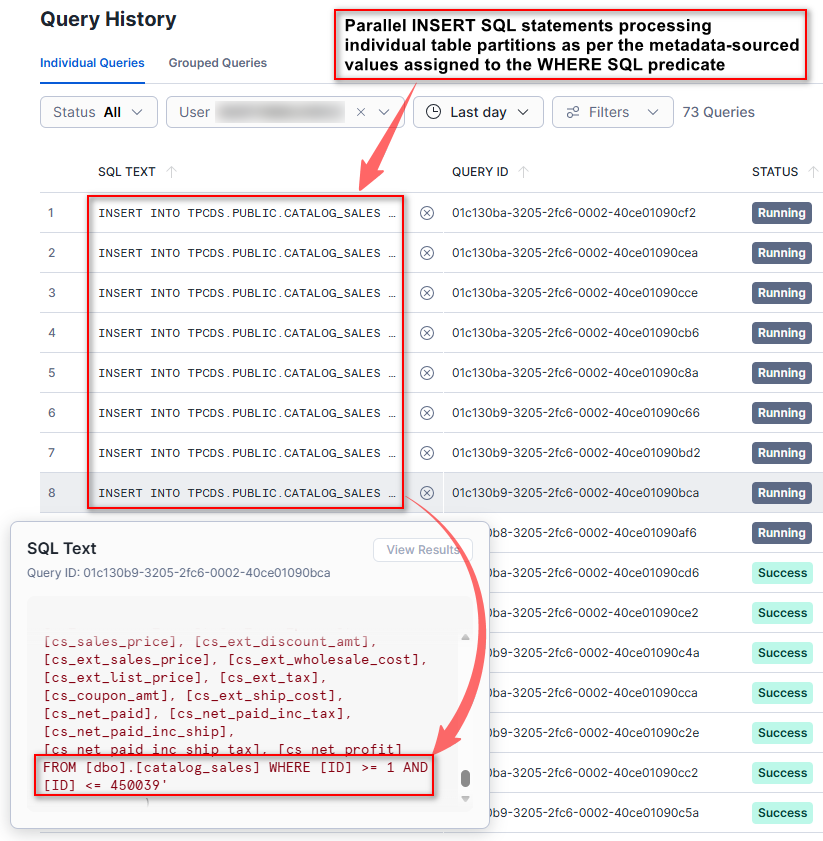
However, this approach, while maximizing warehouse resource utilization, comes with a couple of drawbacks. In a single-cluster warehouse, concurrency and parallelism are fundamentally constrained: the number of execution threads is capped by the MAX_CONCURRENCY_LEVEL parameter setting (8 by default), and increasing warehouse size has only marginal effect on the parallel execution. As a result, adding more worker threads simply leads to queuing due to limited execution slots at both the warehouse and Python process levels. Because all work shares a single session, constructs like ThreadPoolExecutor are effectively capped at the same limit, making it impossible to scale parallel workloads beyond eight concurrent workers.
To transcend single-session limitations and achieve horizontal scalability across multi-cluster warehouse configurations, the solution provides an orchestration layer that parallelizes the core loading logic across multiple independent execution contexts, each mapped to a distinct cluster node (click on image to enlarge).
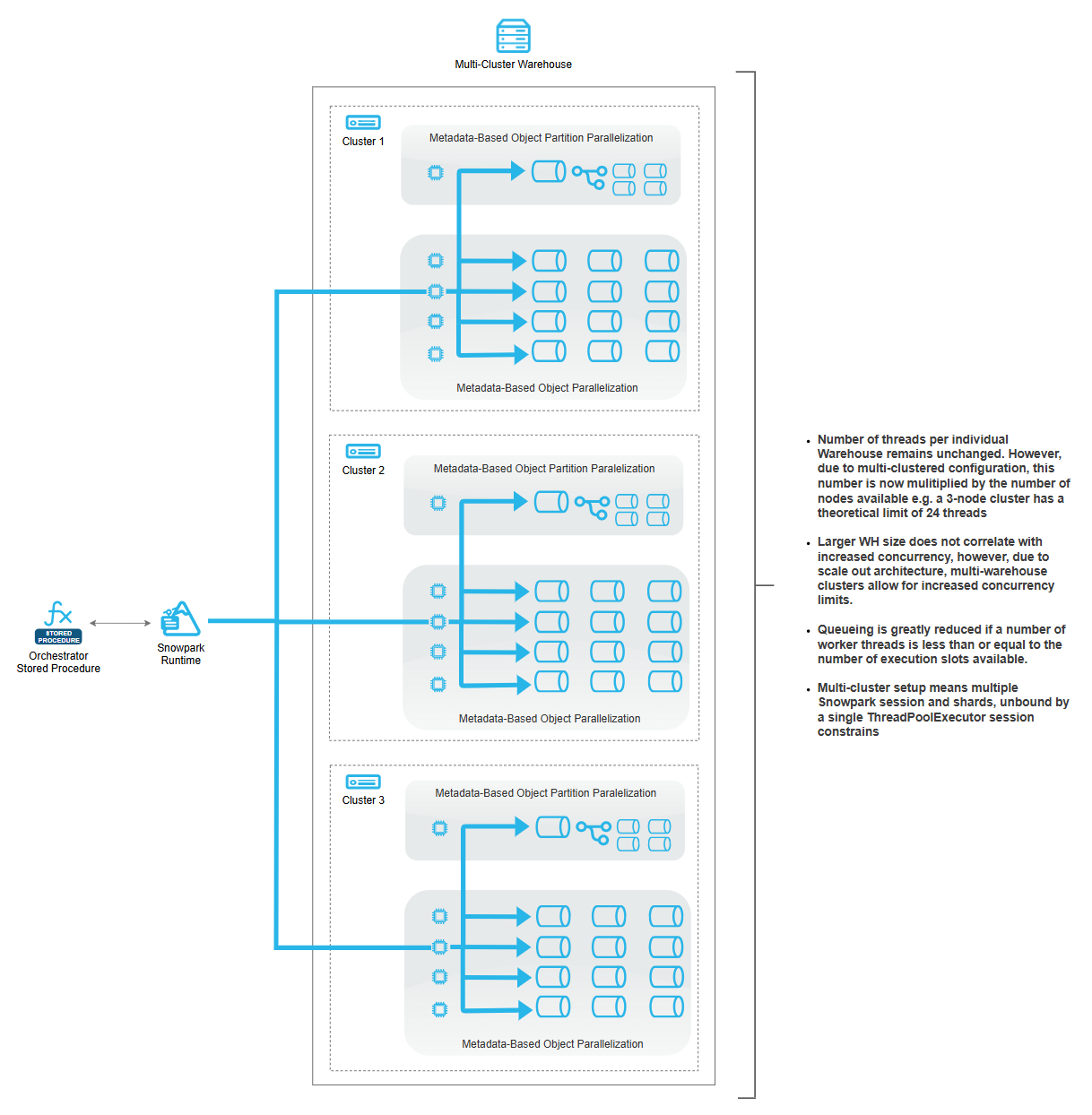
This orchestrator layer performs warehouse introspection to determine active cluster node count and spawns an equivalent number of concurrent stored procedure invocations using multi-threaded execution patterns, effectively multiplying available parallelism by the cluster multiplier. The orchestrator implements workload distribution algorithms that vary based on the loading scenario: for single-table operations with partitioned data, it calculates partition-per-cluster allocations and assigns non-overlapping partition ranges to each parallel invocation, ensuring complete coverage without duplication; for multi-table workloads, it employs table-level distribution where each cluster node receives a subset of tables to process sequentially with internal parallelism. This cluster-aware architecture enables near-linear horizontal scaling where doubling cluster count approximately doubles aggregate throughput, transforming the solution from a session-constrained single-node system into a distributed computing framework capable of leveraging the full computational capacity of multi-cluster warehouse configurations.
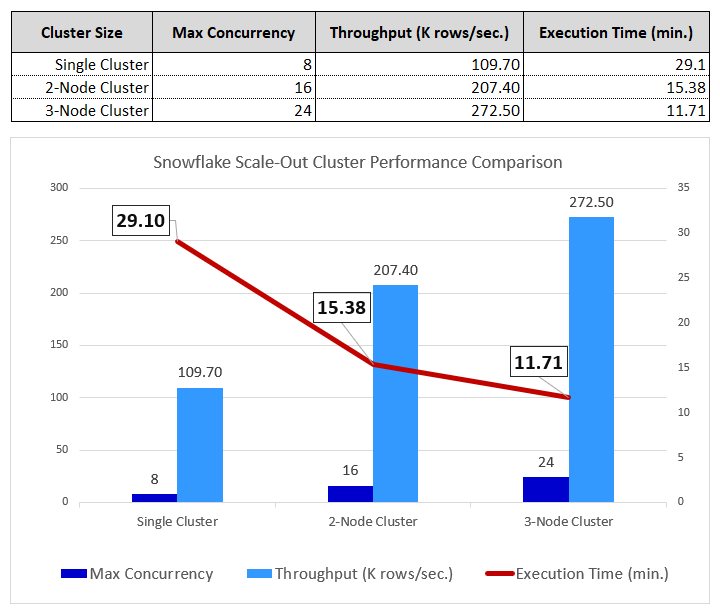
Anecdotal Performance Testing
The scale-out architecture’s effectiveness is validated by actual cluster utilization metrics. The concurrency per cluster averaged 24 concurrent queries (in a 3-node cluster setup), demonstrating that each node was effectively utilizing allocated resources, with no extensive disk spills and queues. This architecture maintains perfect data integrity through deterministic sharding (all three tests loaded exactly 191,496,628 rows with no duplicates or losses), while the efficiency scores of 94.5% for 2-cluster and 83% for 3-cluster deployments reflect typical diminishing returns in parallel systems due to coordination overhead and workload imbalances. The external orchestration pattern is the key innovation that breaks through Snowflake’s single-session concurrency ceiling, enabling true horizontal scalability limited only by the multi-cluster warehouse configuration and the available table count for sharding distribution.
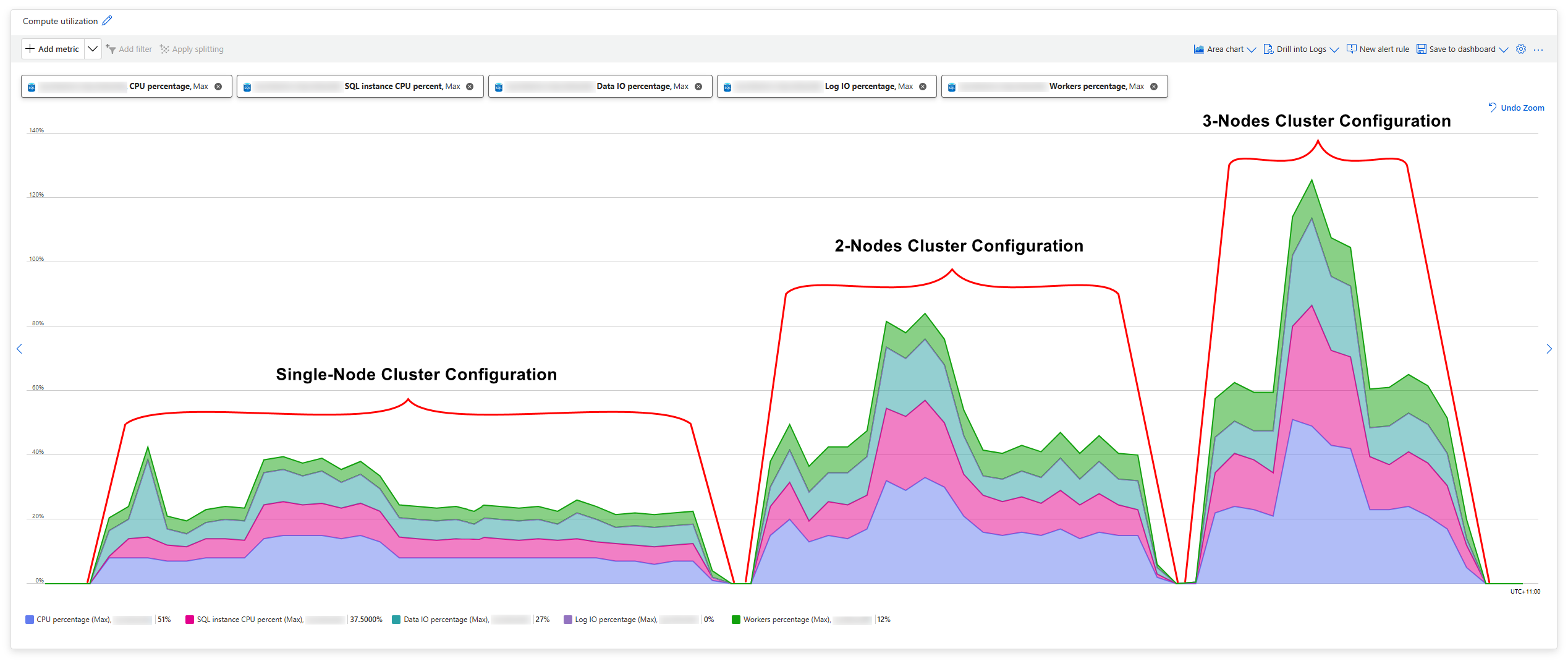
Finally, looking at the SQL Server instance resource consumption, we clearly see the correlation between the increased Snowflake cluster size, higher Azure SQL DB IO and CPU utilization and the reduced ingestion time (click on image to enlarge).
Conclusion
In summary, the Snowflake Metadata-Driven Ingestion Framework (all of the solution code can be downloaded from HERE) shows how ingestion pipelines can be simplified and hardened by pushing orchestration, transformation logic, and execution directly into Snowflake using Snowpark, JDBC, and Python. By driving ingestion behavior entirely from metadata, the framework enables new sources, tables, and ingestion patterns to be onboarded with minimal code changes, reducing operational complexity and long-term maintenance effort. Just as importantly, this approach aligns naturally with Snowflake’s elastic compute model: lightweight or low-concurrency workloads can be efficiently handled using single-node warehouses, while higher-volume or highly parallel ingestion jobs can seamlessly scale out using multi-node warehouses to increase throughput without redesigning the pipeline. This ability to scale compute independently of logic ensures consistent performance as data volumes grow, while avoiding over-provisioning for smaller workloads. Overall, the framework provides a flexible, scalable, and cloud-native foundation for building robust ingestion architectures that evolve alongside both data demands and Snowflake warehouse configurations.
Posted in: Snowflake
Tags: ETL, Python, Snowflake, Snowpark, SQL, SQL Server
December 28th, 2024 / 11 Comments » / by admin
Introduction
Many of the popular data warehouses vendors utilize Object Storage services provided by major cloud providers e.g. ADLS, S3 as their intermediate or persistent data store. S3 (Simple Storage Service) especially has gained a lot of traction in the data community due to its virtually unlimited scalability at very low costs, along with its industry-leading durability, availability and performance – S3 has become the new SFTP. As a result, more Data Warehouse vendors are integrating S3 as their primary, transient or secondary storage mechanism e.g. Vertica Eon, Snowflake, not to mention countless data lake vendors.
However, pushing data into S3 is half the battle and in-house-built S3 data ingestion pipelines oftentimes turn out to be more complex than initially thought or required. In addition to this, there’s already a sea of solutions, architectures and approaches which solve this simple problem in a very roundabout way, so it’s easy to get lost or over-engineer.
In this post, I’d like to look at how DuckDB in – a small footprint, in-process OLAP RDBMS – can alleviate some of these challenges by providing native S3 integration with a few extra “quality of life” features thrown in. Let’s look at how DuckDB, with a little bit of SQL and/or Python, can serialize, transform, augment and integrate data into S3 with little effort using a few different patterns and approaches. I’ll be using Synthea synthetic hospital data and SQL Server engine as my source in all the below examples, but the same methodology can be applied to any data or RDBMS. Also, in case you’d like to replicate these exact scenarios, additional code used for CSV to Parquet files serialization as well as DuckDB and SQL Server import (Python and T-SQL) can be found HERE.
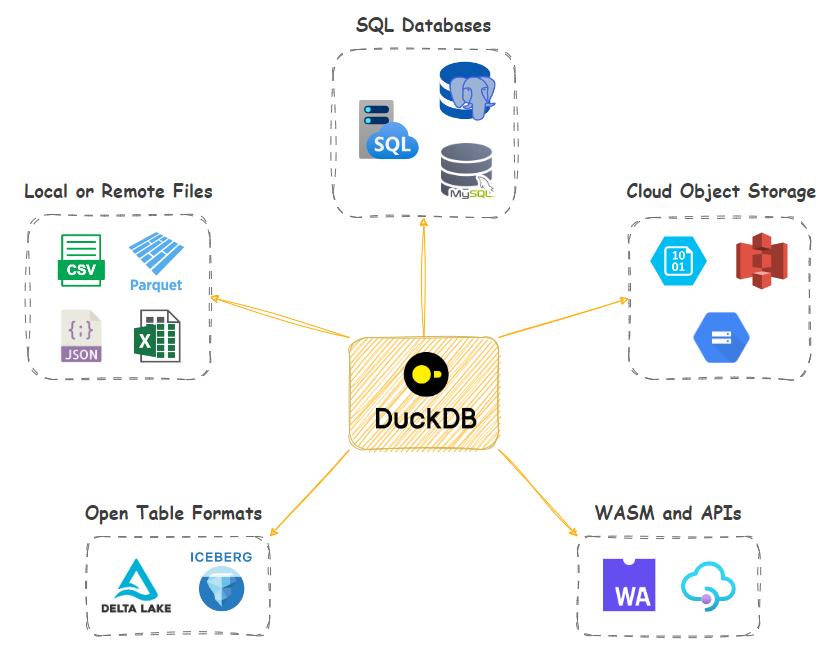
Data Export, Serialization and S3 Ingestion
Let’s start with a simple example of using DuckDB and its httpfs extension which supports reading/writing/globbing files on object storage servers to convert source data into Parquet columnar storage format and upload it into an S3 bucket. DuckDB conforms to the S3 API out-of-the-box and httpfs filesystem is tested with AWS S3, Minio, Google Cloud, and lakeFS. Other services that implement the S3 API (such as Cloudflare R2) should also work, but not all features may be supported.
While using DuckDB may seem a bit odd at first glance as it involves utilizing another OLAP engine, the small footprint (it runs in-process) and its rich ecosystem of features means that we can leverage its potential for a small to medium data serialization and transformations without significant investments in other services and tooling. And because it’s a library, there’s no need for a dedicated client-server architecture and many operations can run in-memory.
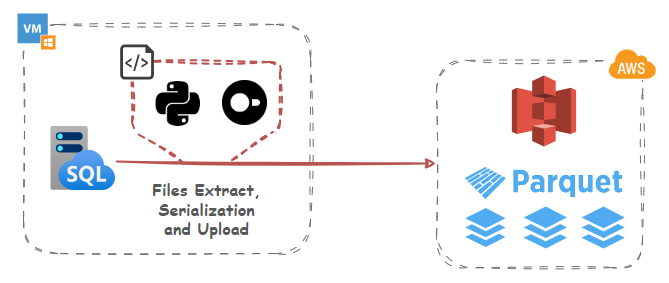
Polars library is used as an intermediate data structure to load, transform, and validate data before converting it to Arrow. Arrow Tables provide a columnar in-memory format that is highly efficient for data analytics and serialization. This minimizes the overhead of converting data from a database query to a Parquet file. By leveraging Arrow, we benefit from its optimized data pipelines, reducing processing and serialization overhead.
This Python script also assumes S3 bucket has already been created. In a production environment, for S3 access, you’re better off using Amazon IAM service to create a set of keys that only has permission to perform the tasks that you require for your script. For SQL Server access, use Windows Auth or SQL Server login with limited access privileges. Notice how secrets are used to authenticate to AWS S3 endpoints (credential chain from AWS SDK provider is also supported) in line 45. In DuckDB, the Secrets manager provides a unified user interface for secrets across all backends that use them. Secrets can also be persisted, so that they do not need to be specified every time DuckDB is launched.
import pyodbc
import polars as pl
import duckdb
import boto3
from humanfriendly import format_timespan
from time import perf_counter
_SQL_DRIVER = "{ODBC Driver 17 for SQL Server}"
_SQL_SERVER_NAME = "WINSVR2019\\MSSQL2022"
_SQL_USERNAME = "Your_MSSQL_UserName"
_SQL_PASSWORD = "Your_MSSQL_Password"
_SQL_DB = "Synthea"
_AWS_S3_KEY_ID = "Your_AWS_Key"
_AWS_S3_SECRET = "Your_AWS_Secret"
_AWS_S3_REGION = "ap-southeast-2"
_AWS_S3_BUCKET_NAME = "s3bicortex"
def mssql_db_conn(_SQL_SERVER_NAME, _SQL_DB, _SQL_USERNAME, _SQL_PASSWORD):
connection_string = (
"DRIVER="
+ _SQL_DRIVER
+ ";SERVER="
+ _SQL_SERVER_NAME
+ ";PORT=1433;DATABASE="
+ _SQL_DB
+ ";UID="
+ _SQL_USERNAME
+ ";PWD="
+ _SQL_PASSWORD
)
try:
conn = pyodbc.connect(connection_string, timeout=1)
except pyodbc.Error as err:
conn = None
return conn
def load_duckdb_tables(
_SQL_SERVER_NAME, _SQL_DB, _SQL_USERNAME, _SQL_PASSWORD, duckdb_conn, mssql_conn
):
try:
duckdb_cursor = duckdb_conn.cursor()
duckdb_cursor.execute(
f'CREATE SECRET (TYPE S3,KEY_ID "{_AWS_S3_KEY_ID}",SECRET "{_AWS_S3_SECRET}",REGION "{_AWS_S3_REGION}");'
)
duckdb_cursor.execute("INSTALL httpfs;")
duckdb_cursor.execute("LOAD httpfs;")
with mssql_conn.cursor() as cursor:
sql = f"SELECT table_name FROM {_SQL_DB}.INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'dbo';"
cursor.execute(sql)
metadata = cursor.fetchall()
tables_to_load = [row[0] for row in metadata]
for table in tables_to_load:
extract_query = (
f"SELECT * FROM {table}" # Modify your SQL query as needed
)
row_count_query = f"SELECT COUNT(1) FROM {table}"
print(
f"Serializing MSSQL '{table}' table content into a duckdb schema...",
end="",
flush=True,
)
cursor = mssql_conn.cursor()
cursor.execute(row_count_query)
records = cursor.fetchone()
mssql_row_count = records[0]
cursor.execute(extract_query)
columns = [column[0] for column in cursor.description]
rows = cursor.fetchall()
rows = [tuple(row) for row in rows]
df = pl.DataFrame(
rows, schema=columns, orient="row", infer_schema_length=1000
)
duckdb_conn.register("polars_df", df)
duckdb_conn.execute(
f"CREATE TABLE IF NOT EXISTS {table} AS SELECT * FROM polars_df"
)
duckdb_cursor.execute(f"SELECT COUNT(1) FROM {table}")
records = duckdb_cursor.fetchone()
duckdb_row_count = records[0]
if duckdb_row_count != mssql_row_count:
raise Exception(
f"Table {table} failed to load correctly as record counts do not match: mssql {table} table: {mssql_row_count} vs duckdb {table} table: {duckdb_row_count}.\
Please troubleshoot!"
)
else:
print("OK!")
print(
f"Serializing DUCKDB '{table}' table content into parquet schema and uploading to '{_AWS_S3_BUCKET_NAME}' S3 bucket...",
end="",
flush=True,
)
duckdb_cursor.execute(
f'COPY {table} TO "s3://{_AWS_S3_BUCKET_NAME}/{table}.parquet";'
)
s3 = boto3.client(
"s3",
aws_access_key_id=_AWS_S3_KEY_ID,
aws_secret_access_key=_AWS_S3_SECRET,
region_name=_AWS_S3_REGION,
)
file_exists = s3.head_object(
Bucket=_AWS_S3_BUCKET_NAME, Key=".".join([table, "parquet"])
)
duckdb_cursor.execute(
f'SELECT COUNT(*) FROM read_parquet("s3://{_AWS_S3_BUCKET_NAME}/{table}.parquet");'
)
records = duckdb_cursor.fetchone()
parquet_row_count = records[0]
if file_exists and parquet_row_count == mssql_row_count:
print("OK!")
duckdb_conn.execute(f"DROP TABLE IF EXISTS {table}")
duckdb_conn.close()
except Exception as err:
print(err)
if __name__ == "__main__":
duckdb_conn = duckdb.connect(database=":memory:")
mssql_conn = mssql_db_conn(_SQL_SERVER_NAME, _SQL_DB, _SQL_USERNAME, _SQL_PASSWORD)
if mssql_conn and duckdb_conn:
start_time = perf_counter()
load_duckdb_tables(
_SQL_SERVER_NAME,
_SQL_DB,
_SQL_USERNAME,
_SQL_PASSWORD,
duckdb_conn,
mssql_conn,
)
end_time = perf_counter()
time = format_timespan(end_time - start_time)
print(f"All records loaded successfully in {time}!")
It’s a straightforward example where most of the heavy lifting logic is tied to a single line of code – the COPY command in line 95. The COPY…TO function can be called specifying either a table name, or a query. When a table name is specified, the contents of the entire table will be written into the resulting file. When a query is specified, it is executed, and the result of the query is written to the resulting file.
Datasets Row Diff Detection and Data Reconciliation
Now, let’s look at how DuckDB can be used for more than just data serialization and S3 upload. Suppose we’d like to do a diff on our parquet files staged in S3 and our local MSSQL database. This requirement can be useful for a number of reasons e.g.
- Data Versioning: In a versioned database, comparing tables allows for tracking changes between different versions of a dataset. This is crucial for maintaining data lineage and understanding how information has evolved over time.
- Data Migration Validation: When migrating data between systems or databases, ensuring that the integrity of the data is maintained is paramount. Table comparisons help verify that the transferred data aligns with the source.
- Quality Assurance: For datasets subject to frequent updates or manual interventions, comparing tables becomes a quality assurance measure. It ensures that modifications adhere to predefined standards and do not introduce unintended discrepancies.
- Detecting Anomalies: Identifying unexpected changes in a dataset is simplified through table comparisons. Sudden spikes or drops in data values can be promptly spotted, triggering further investigation.
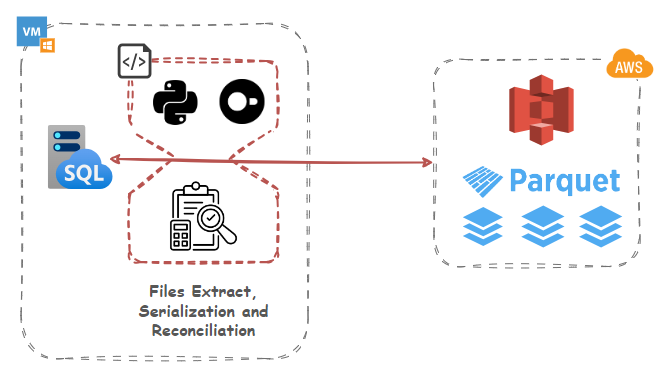
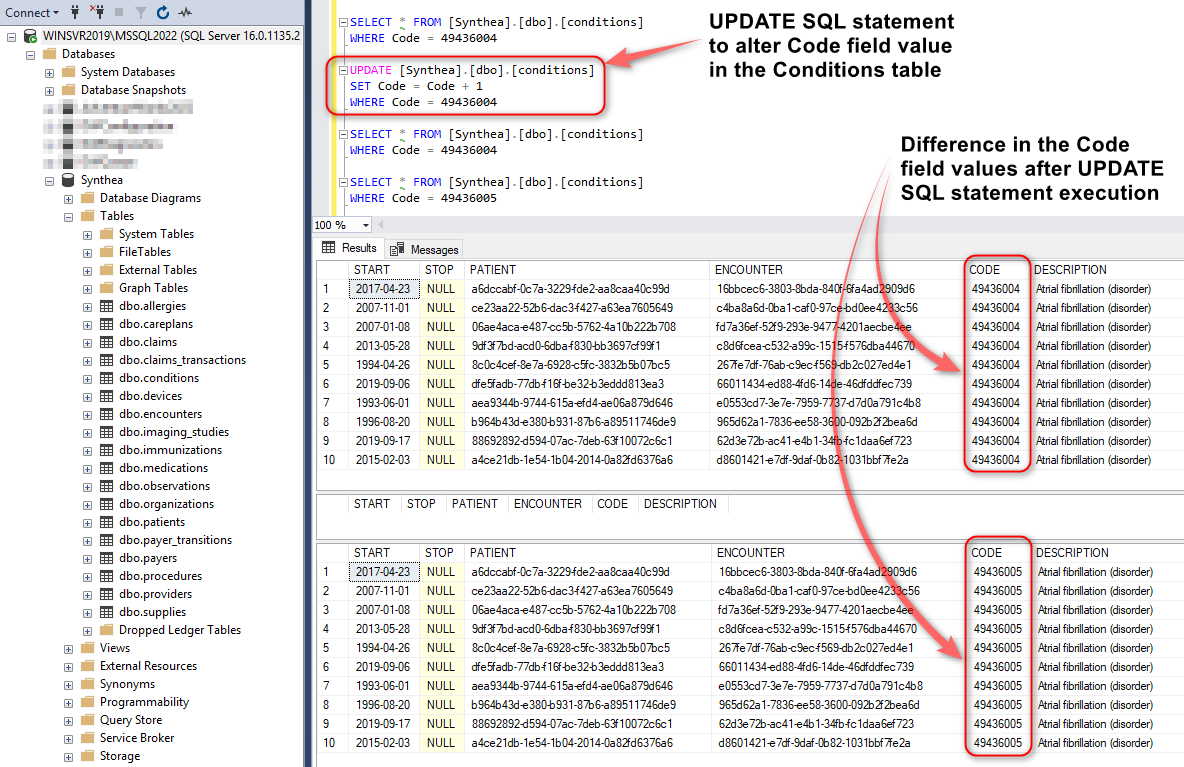
Normally, comparing Parquet file and database table content, would be difficult to achieve for a few reasons e.g. data structure, storage mechanism etc. not to mention the fact these are not co-located i.e. Parquet files are stored in S3 and DuckDB data on premises. However, DuckDB makes it relatively easy to query both, hash the entire file/table content and detect any discrepancies. To see how this may work in practice, let create a scenario where ten rows in the source database (MSSQL) are altered, running the following SQL statement:
SELECT * FROM [Synthea].[dbo].[conditions]
WHERE Code = 49436004
UPDATE [Synthea].[dbo].[conditions]
SET Code = Code + 1
WHERE Code = 49436004
SELECT * FROM [Synthea].[dbo].[conditions]
WHERE Code = 49436004
SELECT * FROM [Synthea].[dbo].[conditions]
WHERE Code = 49436005
Next, let’s run the following script where “Conditions” database table is compared against its Parquet file counterpart and all ten updated records are surfaced as a discrepancy. Notice how compare_sql variable is creating a SHA256 hashmap value for all the data coming from a particular object to determine if any difference was recorded after which diff_detect_sql variable is used to handle difference output.
import pyodbc
import polars as pl
import duckdb
from humanfriendly import format_timespan
from time import perf_counter
_SQL_DRIVER = "{ODBC Driver 17 for SQL Server}"
_SQL_SERVER_NAME = "WINSVR2019\\MSSQL2022"
_SQL_USERNAME = "Your_MSSQL_UserName"
_SQL_PASSWORD = "Your_MSSQL_Password"
_SQL_DB = "Synthea"
_AWS_S3_KEY_ID = "Your_AWS_Key"
_AWS_S3_SECRET = "Your_AWS_Secret"
_AWS_S3_REGION = "ap-southeast-2"
_AWS_S3_BUCKET_NAME = "s3bicortex"
def mssql_db_conn(_SQL_SERVER_NAME, _SQL_DB, _SQL_USERNAME, _SQL_PASSWORD):
connection_string = (
"DRIVER="
+ _SQL_DRIVER
+ ";SERVER="
+ _SQL_SERVER_NAME
+ ";PORT=1433;DATABASE="
+ _SQL_DB
+ ";UID="
+ _SQL_USERNAME
+ ";PWD="
+ _SQL_PASSWORD
)
try:
conn = pyodbc.connect(connection_string, timeout=1)
except pyodbc.Error as err:
conn = None
return conn
def load_duckdb_tables(duckdb_conn, mssql_conn):
try:
duckdb_cursor = duckdb_conn.cursor()
duckdb_cursor.execute(
f'CREATE SECRET (TYPE S3,KEY_ID "{_AWS_S3_KEY_ID}",SECRET "{_AWS_S3_SECRET}",REGION "{_AWS_S3_REGION}");'
)
duckdb_cursor.execute("INSTALL httpfs;")
duckdb_cursor.execute("LOAD httpfs;")
with mssql_conn.cursor() as cursor:
sql = f"SELECT table_name FROM {_SQL_DB}.INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'dbo' and table_name = 'conditions';"
cursor.execute(sql)
metadata = cursor.fetchall()
tables_to_load = [row[0] for row in metadata]
for table in tables_to_load:
extract_query = f"SELECT * FROM {table}"
cursor = mssql_conn.cursor()
cursor.execute(extract_query)
columns = [column[0] for column in cursor.description]
rows = cursor.fetchall()
rows = [tuple(row) for row in rows]
df = pl.DataFrame(
rows, schema=columns, orient="row", infer_schema_length=1000
)
duckdb_conn.register("polars_df", df)
duckdb_conn.execute(
f"CREATE TABLE IF NOT EXISTS {table}_source AS SELECT * FROM polars_df"
)
duckdb_conn.execute(
f'CREATE TABLE IF NOT EXISTS {table}_target AS SELECT * FROM read_parquet("s3://{_AWS_S3_BUCKET_NAME}/{table}.parquet");'
)
columns_result = duckdb_conn.execute(
f"SELECT column_name FROM information_schema.columns WHERE table_name = '{table}_source'"
).fetchall()
columns = [col[0] for col in columns_result]
cols_str = ", ".join(columns)
coalesce_columns = ", ".join(
[
f"COALESCE(table_a.{col}, table_b.{col}) AS {col}"
for col in columns
]
)
compare_sql = duckdb_conn.execute(
f"SELECT (SELECT sha256(list({table}_source)::text) \
FROM {table}_source) = \
(SELECT sha256(list({table}_target)::text) \
FROM {table}_target) AS is_identical"
).fetchone()
if compare_sql[0] is False:
diff_detect_sql = f"""
CREATE TABLE {table}_diff AS
WITH
table_a AS (
SELECT 's3' AS table_origin,
sha256(CAST({table}_target AS TEXT)) AS sha256_key,
{cols_str}
FROM {table}_target
),
table_b AS (
SELECT 'dbms' AS table_origin,
sha256(CAST({table}_source AS TEXT)) AS sha256_key,
{cols_str}
FROM {table}_source
)
SELECT
COALESCE(table_a.sha256_key, table_b.sha256_key) AS sha256_key,
COALESCE(table_a.table_origin, table_b.table_origin) AS table_origin,
{coalesce_columns}
FROM
table_a
FULL JOIN
table_b
ON
table_a.sha256_key = table_b.sha256_key
WHERE {" OR ".join([f"table_a.{col} IS DISTINCT FROM table_b.{col}" for col in columns])};
"""
duckdb_conn.execute(diff_detect_sql)
result = duckdb_conn.execute(
f"SELECT * FROM {table}_diff LIMIT 100"
).fetchall()
full_columns = ["sha256_key", "table_origin"] + columns
with pl.Config(
tbl_formatting="MARKDOWN",
tbl_hide_column_data_types=True,
tbl_hide_dataframe_shape=True,
tbl_cols=11,
):
df = pl.DataFrame(result, schema=full_columns, orient="row")
print(df.sort('table_origin', 'sha256_key'))
else:
print("No changes detected, bailing out!")
duckdb_conn.close()
except Exception as err:
print(err)
if __name__ == "__main__":
duckdb_conn = duckdb.connect(database=":memory:")
mssql_conn = mssql_db_conn(_SQL_SERVER_NAME, _SQL_DB, _SQL_USERNAME, _SQL_PASSWORD)
if mssql_conn and duckdb_conn:
start_time = perf_counter()
load_duckdb_tables(
duckdb_conn,
mssql_conn,
)
end_time = perf_counter()
time = format_timespan(end_time - start_time)
print(f"All records loaded successfully in {time}!")
When executed, the following output is generated in terminal which can be persisted and acted on as a upstream workflow.

In-Process SQL-Based Data Augmentation using Public APIs
But wait, there’s more! Let’s take it further and explore how DuckDB can be used for augmenting existing data “in-flight” using public API data. In addition to native parquet file format integration, DuckDB can also query and consume API request JSON output, which than can be used to augment or enrich source data before loading it into the destination table or file. Normally, this would require additional logic and Python libraries e.g. requests module, but with DuckDB, one can stitch together a simple workflow to query, parse, transform and enrich data in pure SQL.
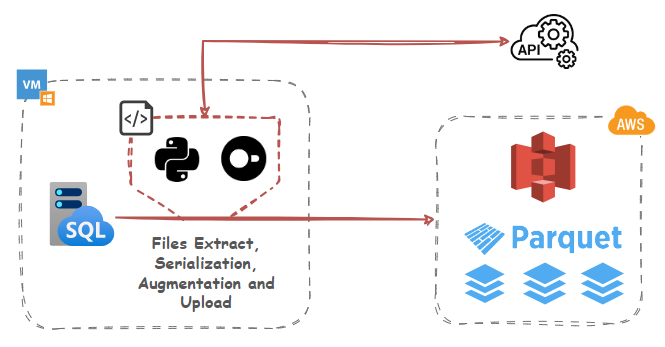
For this example, I’ll query and enrich Synthea data with converted currency rate data from a Frankfurter API. Frankfurter is a free, open-source API for current and historical foreign exchange rates based on data published by the European Central Bank. Their API is well documented on their website HERE.
Looking at the Medications table in MSSQL source database, the field TOTALCOST is expressed in USD which we now wish to convert to AUD. The conversion rate needs to correspond to the START field value which denotes when the medication was issued so that the correct rate is sourced, associated with the date value and applied to the dataset. Querying Frankfurter API endpoint for a particular timeline (as per start and end dates) returns a valid JSON payload as per the image below.

However, there are a couple of issues with this approach. Firstly, when a larger time frame is considered e.g. a period over one year, the API is hard-coded to sample weekly averages. To circumvent this, we will loop over each year in the dataset by deriving start year and end year dates for each calendar year and querying the API for each year with the exception of the current year where today’s date will mark the end period. For example, when querying data for 2023-01-01 until today i.e. 25/12/2024, the following time frames will be looped over: 2023-01-01 – 2023-12-31 and 2024-01-01 – 25/12/2024. Secondly, the API does not return data for weekends and public holidays. To fix this, we will apply previous non-NULL value to all the dates which are missing. This will be done exclusively in SQL by creating a full date table, merging it with the API unnested JSON data and then filling in missing dates using SQL functions such as LEAD and LAG in a newly created AUD_Rate_New field. This shows the power of DuckDB’s engine which is capable of not only sourcing data from public API endpoints, but also shredding the output JSON and performing additional transformations (in-memory) as required. Here’s a sample SQL statement implemented as a CTE with a corresponding output.
WITH gen_date AS (
SELECT
CAST(RANGE AS DATE) AS date_key
FROM
RANGE(DATE '2024-11-01',
date '2024-11-10' +1,
INTERVAL 1 DAY)
) ,
api_data AS (
SELECT
UNNEST(json_keys(response.rates,
'$')) AS rate_date,
response.base AS Base_Rate,
json_extract(response.rates,
CONCAT('$.',
rate_date,
'.AUD'))::DOUBLE AS AUD_Rate
FROM
read_json_auto('https://api.frankfurter.app/2024-11-01..2024-11-18?base=USD&symbols=AUD') AS response ORDER BY 1 asc)
SELECT
COALESCE (gen_date.date_key,
API_Data.rate_date::date),
API_Data.Base_Rate,
API_Data.AUD_Rate,
CASE
WHEN API_Data.AUD_Rate IS NULL THEN
COALESCE (
LAG(API_Data.AUD_Rate IGNORE NULLS) OVER (
ORDER BY gen_date.date_key),
LEAD(API_Data.AUD_Rate IGNORE NULLS) OVER (
ORDER BY gen_date.date_key))
ELSE API_Data.AUD_Rate
END AS 'AUD_Rate_New'
FROM
gen_date
LEFT JOIN api_data ON
gen_date.date_key = api_data.rate_date
ORDER BY
COALESCE (gen_date.date_key,
API_Data.rate_date::date) ASC
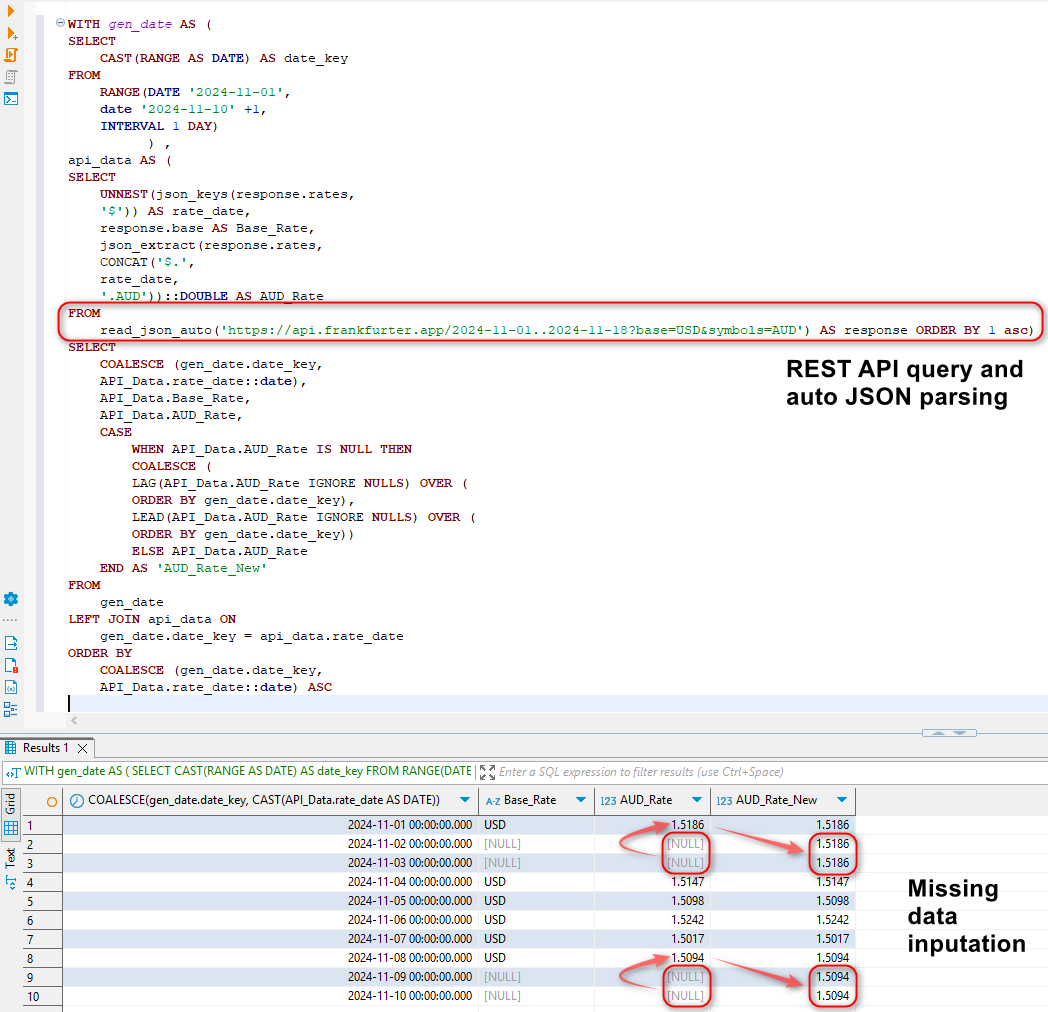
Now that we have a way of extracting a complete set of records and “massaging” the output into a tabular format which lend itself to additional manipulations and transformations, let’s incorporate this into a small Python script.
import pyodbc
import polars as pl
import duckdb
import boto3
from datetime import datetime
from humanfriendly import format_timespan
from time import perf_counter
_SQL_DRIVER = "{ODBC Driver 17 for SQL Server}"
_SQL_SERVER_NAME = "WINSVR2019\\MSSQL2022"
_SQL_USERNAME = "Your_MSSQL_UserName"
_SQL_PASSWORD = "Your_MSSQL_Password"
_SQL_DB = "Synthea"
_AWS_S3_KEY_ID = "Your_AWS_Key"
_AWS_S3_SECRET = "Your_AWS_Secret"
_AWS_S3_REGION = "ap-southeast-2"
_AWS_S3_BUCKET_NAME = "s3bicortex"
def mssql_db_conn(_SQL_SERVER_NAME, _SQL_DB, _SQL_USERNAME, _SQL_PASSWORD):
connection_string = (
"DRIVER="
+ _SQL_DRIVER
+ ";SERVER="
+ _SQL_SERVER_NAME
+ ";PORT=1433;DATABASE="
+ _SQL_DB
+ ";UID="
+ _SQL_USERNAME
+ ";PWD="
+ _SQL_PASSWORD
)
try:
conn = pyodbc.connect(connection_string, timeout=1)
except pyodbc.Error as err:
conn = None
return conn
def year_boundaries_with_days(low_date_tuple, high_date_tuple):
low = (
low_date_tuple[0]
if isinstance(low_date_tuple, tuple) and isinstance(low_date_tuple[0], datetime)
else None
)
high = (
high_date_tuple[0]
if isinstance(high_date_tuple, tuple)
and isinstance(high_date_tuple[0], datetime)
else None
)
if low is None or high is None:
raise ValueError(
"Invalid date input: Both dates must be datetime tuples containing datetime objects."
)
today = datetime.now()
year_boundaries_dict = {}
def days_in_year(year):
if year == today.year:
return (today - datetime(year, 1, 1)).days + 1
else:
start_of_year = datetime(year, 1, 1)
end_of_year = datetime(year, 12, 31)
return (end_of_year - start_of_year).days + 1
for year in range(low.year, high.year + 1):
start_of_year = datetime(year, 1, 1)
end_of_year = datetime(year, 12, 31)
if year == today.year and end_of_year > today:
end_of_year = today
if start_of_year >= low and end_of_year <= high:
year_boundaries_dict[year] = {
"start_of_year": start_of_year.strftime("%Y-%m-%d"),
"end_of_year": end_of_year.strftime("%Y-%m-%d"),
"days_in_year": days_in_year(year),
}
elif start_of_year < low and end_of_year >= low and end_of_year <= high:
year_boundaries_dict[year] = {
"start_of_year": low.strftime("%Y-%m-%d"),
"end_of_year": end_of_year.strftime("%Y-%m-%d"),
"days_in_year": days_in_year(year),
}
elif start_of_year >= low and start_of_year <= high and end_of_year > high:
year_boundaries_dict[year] = {
"start_of_year": start_of_year.strftime("%Y-%m-%d"),
"end_of_year": high.strftime("%Y-%m-%d"),
"days_in_year": days_in_year(year),
}
return year_boundaries_dict
def load_duckdb_tables(_SQL_DB, duckdb_conn, mssql_conn):
try:
duckdb_cursor = duckdb_conn.cursor()
duckdb_cursor.execute(
f'CREATE SECRET (TYPE S3,KEY_ID "{_AWS_S3_KEY_ID}",SECRET "{_AWS_S3_SECRET}",REGION "{_AWS_S3_REGION}");'
)
duckdb_cursor.execute("INSTALL httpfs;")
duckdb_cursor.execute("LOAD httpfs;")
with mssql_conn.cursor() as cursor:
sql = f"SELECT table_name FROM {_SQL_DB}.INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'dbo';"
cursor.execute(sql)
metadata = cursor.fetchall()
tables_to_load = [row[0] for row in metadata]
for table in tables_to_load:
extract_query = (
f"SELECT * FROM {table}" # Modify your SQL query as needed
)
row_count_query = f"SELECT COUNT(1) FROM {table}"
print(
f"Serializing MSSQL '{table}' table content into a duckdb schema...",
end="",
flush=True,
)
cursor = mssql_conn.cursor()
cursor.execute(row_count_query)
records = cursor.fetchone()
mssql_row_count = records[0]
cursor.execute(extract_query)
columns = [column[0] for column in cursor.description]
rows = cursor.fetchall()
rows = [tuple(row) for row in rows]
df = pl.DataFrame(
rows, schema=columns, orient="row", infer_schema_length=1000
)
duckdb_conn.register("polars_df", df)
duckdb_conn.execute(
f"CREATE TABLE IF NOT EXISTS {table} AS SELECT * FROM polars_df"
)
duckdb_row_count = duckdb_conn.execute(
f"SELECT COUNT(*) FROM {table};"
).fetchone()
if table == "medications":
min_date = duckdb_conn.execute(
f"SELECT MIN(START) FROM {table} WHERE START>= '2020-01-01';"
).fetchone()
max_date = duckdb_cursor.execute(
"SELECT CAST(current_date AS TIMESTAMP);"
).fetchone()
duckdb_conn.execute(
f"ALTER TABLE {table} ADD COLUMN TOTALCOST_AUD DOUBLE;"
)
years = year_boundaries_with_days(min_date, max_date)
for k, v in years.items():
start_of_year = v["start_of_year"]
end_of_year = v["end_of_year"]
number_of_days = v["days_in_year"]
duckdb_conn.execute(
f"""
CREATE OR REPLACE TEMP TABLE api_rate_data AS
WITH gen_date AS (
SELECT
CAST(RANGE AS DATE) AS date_key
FROM
RANGE(DATE '{start_of_year}',
DATE '{end_of_year}' + 1,
INTERVAL 1 DAY)
) ,
api_data AS (
SELECT
UNNEST(json_keys(response.rates,
'$')) AS rate_date,
response.base AS Base_Rate,
json_extract(response.rates,
CONCAT('$.',
rate_date,
'.AUD'))::DOUBLE AS AUD_Rate
FROM
read_json_auto('https://api.frankfurter.app/{start_of_year}..{end_of_year}?base=USD&symbols=AUD') response)
SELECT
COALESCE (gen_date.date_key,
API_Data.rate_date::date) AS 'Rate_Date',
API_Data.Base_Rate,
API_Data.AUD_Rate,
CASE
WHEN API_Data.AUD_Rate IS NULL THEN
COALESCE (
LAG(API_Data.AUD_Rate IGNORE NULLS) OVER (
ORDER BY gen_date.date_key),
LEAD(API_Data.AUD_Rate IGNORE NULLS) OVER (
ORDER BY gen_date.date_key))
ELSE API_Data.AUD_Rate
END AS 'AUD_Rate_New'
FROM
gen_date
LEFT JOIN api_data ON
gen_date.date_key = api_data.rate_date
ORDER BY
COALESCE (gen_date.date_key,
API_Data.rate_date::date) ASC;
UPDATE medications
SET TOTALCOST_AUD = TOTALCOST * api_rate_data.AUD_Rate_New
FROM api_rate_data
WHERE medications.start::date = api_rate_data.Rate_Date::date;
"""
).fetchall()
api_data = duckdb_conn.execute(
"SELECT COUNT(*) FROM api_rate_data"
).fetchone()
if api_data[0] != int(number_of_days):
raise Exception(
"Number of records returned from api.frankfurter.app is incorrect. Please troubleshoot!"
)
duckdb_conn.execute("""UPDATE medications
SET TOTALCOST_AUD = TOTALCOST * api_rate_data.AUD_Rate_New
FROM api_rate_data
WHERE medications.start::date = api_rate_data.Rate_Date::date;
""")
if duckdb_row_count[0] != mssql_row_count:
raise Exception(
f"Table {table} failed to load correctly as record counts do not match: mssql {table} table: {mssql_row_count} vs duckdb {table} table: {duckdb_row_count}.\
Please troubleshoot!"
)
else:
print("OK!")
print(
f"Serializing DUCKDB '{table}' table content into parquet schema and uploading to '{_AWS_S3_BUCKET_NAME}' S3 bucket...",
end="",
flush=True,
)
duckdb_cursor.execute(
f'COPY {table} TO "s3://{_AWS_S3_BUCKET_NAME}/{table}.parquet";'
)
s3 = boto3.client(
"s3",
aws_access_key_id=_AWS_S3_KEY_ID,
aws_secret_access_key=_AWS_S3_SECRET,
region_name=_AWS_S3_REGION,
)
file_exists = s3.head_object(
Bucket=_AWS_S3_BUCKET_NAME, Key=".".join([table, "parquet"])
)
duckdb_cursor.execute(
f'SELECT COUNT(*) FROM read_parquet("s3://{_AWS_S3_BUCKET_NAME}/{table}.parquet");'
)
records = duckdb_cursor.fetchone()
parquet_row_count = records[0]
if file_exists and parquet_row_count == mssql_row_count:
print("OK!")
duckdb_conn.execute(f"DROP TABLE IF EXISTS {table}")
duckdb_conn.close()
except Exception as err:
print(err)
if __name__ == "__main__":
duckdb_conn = duckdb.connect(database=":memory:")
mssql_conn = mssql_db_conn(_SQL_SERVER_NAME, _SQL_DB, _SQL_USERNAME, _SQL_PASSWORD)
if mssql_conn and duckdb_conn:
start_time = perf_counter()
load_duckdb_tables(
_SQL_DB,
duckdb_conn,
mssql_conn,
)
end_time = perf_counter()
time = format_timespan(end_time - start_time)
print(f"All records loaded successfully in {time}!")
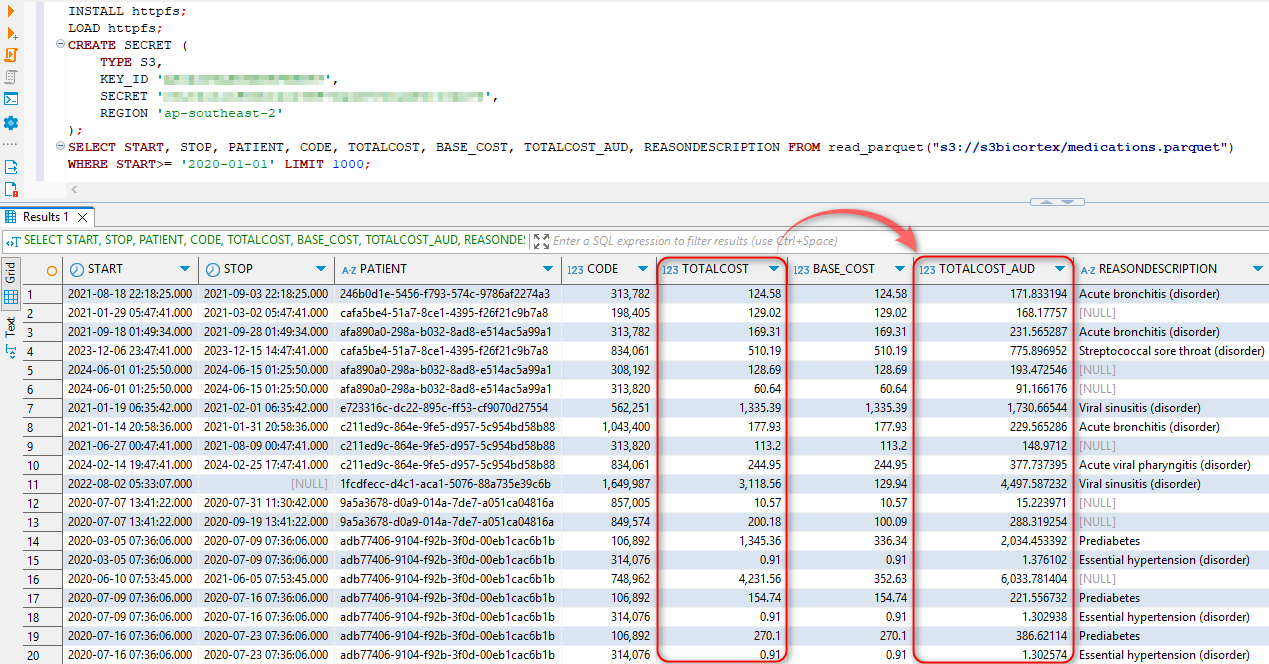
Once executed, we can run a SELECT directly on our parquet file in S3, confirming that the added column with converted currency rate has been persisted in the target file.
DuckDB Extensions for Intermediary Data Transformation and Augmentation
Up until this point, we’ve used DuckDB to serialize, transform, reconcile, enrich and upload our datasets but since Large Language Models are all the rage now, how about interfacing it with OpenAI’s GPT models to provide additional context and augment it with some useful information via extensions.
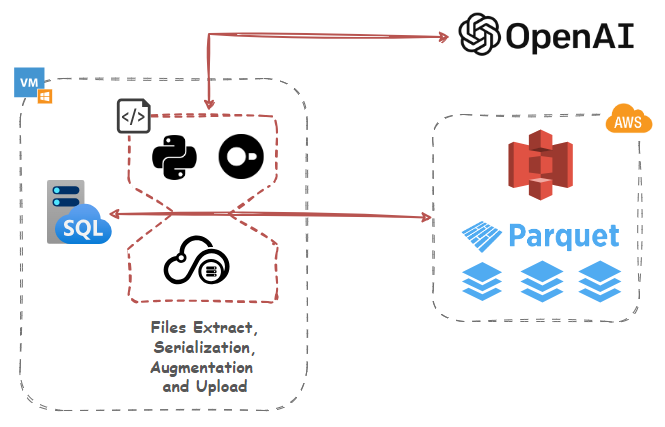
DuckDB has a flexible extension mechanism that allows for dynamically loading additional functionality using extensions. These may extend DuckDB’s functionality by providing support for additional file formats, introducing new types, and domain-specific functionality. To make the DuckDB distribution lightweight, only a few essential extensions are built-in, varying slightly per distribution. Which extension is built-in on which platform is documented in the list of core extensions as well as community extensions.
To get a list of extensions, we can query duckdb_extension function, like so:
SELECT extension_name, installed, description
FROM duckdb_extensions();
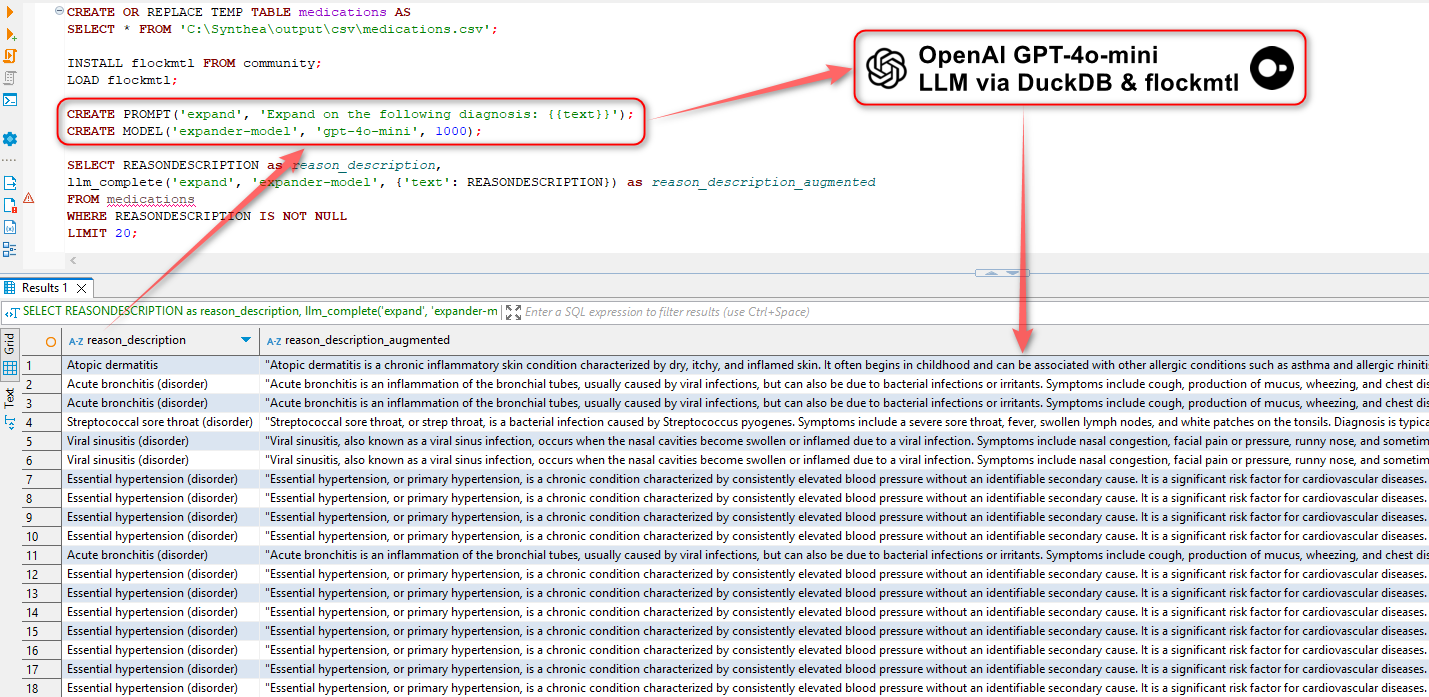
This presents us with some interesting possibilities, for example, we could use flockmtl extension to augment our data with Large Language Models before we push it into S3 with just a little bit of SQL. For example, the following is used to create a “medications” table (part of Synthia dataset) from a CSV file, install flockmtl extension, create a prompt and model objects and augment our data using OpenAI models. In this example, we can use gpt-4o-mini model (OpenAI API key needs to be saved as an environment variable) to provide more context based on the text saved in REASONDESCRIPTION field.
CREATE OR REPLACE TEMP TABLE medications AS
SELECT * FROM 'C:\Synthea\output\csv\medications.csv';
INSTALL flockmtl FROM community;
LOAD flockmtl;
CREATE PROMPT('expand', 'Expand on the following diagnosis: {{text}}');
CREATE MODEL('expander-model', 'gpt-4o-mini', 1000);
SELECT REASONDESCRIPTION as reason_description,
llm_complete('expand', 'expander-model', {'text': REASONDESCRIPTION}) as reason_description_augmented
FROM medications
WHERE REASONDESCRIPTION IS NOT NULL
LIMIT 20;
While the idea of querying LLMs in pure SQL is not new and every database vendor is outdoing itself trying to incorporate GenAI capabilities to their product, it’s still impressive that one can wield such powerful technology with just a few lines of SQL.
Conclusion
This post is only scratching the surface on the versatility and expressiveness of DuckDB and how it can be utilized for a multitude of different applications, in an on-premises and cloud architectures, with little effort or overhead e.g. in this post, I also described how it can be incorporated into an Azure Function for data serialization. Tools like DuckDB prove that being a small project in the sea of big vendors can also have its advantages – small footprint, narrow focus, ease of development and management and good interoperability with major cloud providers. In addition, as demonstrated in this post, many tasks requiring intermediate data processing, serialization and integration can mostly be done in standard SQL, with no complex setup involved and with speed and efficiency which is very refreshing in the world of expensive and bloated software.
Posted in: Programming, SQL
Tags: AWS, DuckDB, OLAP, Python, SQL



Great post Martin and I found that the source code worked well. My company was about procure and deploy an…