Using Polybase and In-Database Python Runtime for Building SQL Server to Azure Data Lake Data Extraction Pipelines
Introduction
One of the projects I assisted with recently dictated that Parquet files staged in Azure Data Lake were to be consumed using a traditional ELT\ETL architecture i.e. using Databricks, Data Factory or a similar tool and loaded into SQL Server tables. However, given the heighten data sensitivity and security requirements, using additional vendors or tools for bringing these pipelines on-line would mean obtaining IRAP (Information Security Registered Assessors Program) assessment first, which in turn would result in protracted development timelines, thus higher cost. The solution turned out to be quite simple – use out-of-the-box SQL Server functionality and try to query/extract this data with the help of Polybase.
Polybase, mainly used for data virtualization and federation, enables your SQL Server instance to query data with T-SQL directly from SQL Server, Oracle, Teradata, MongoDB, Cosmos DB and other database engines without separately installing client connection software. While Polybase version 1 only supported Hadoop using Java, version 2 included a set of ODBC drivers and was released with MSSQL 2019. Version 3 (applicable to SQL Server 2022) is a modernized take on Polybase and includes REST (Representative State Transfer) as the interface for intra-software communication. REST APIs are service endpoints that support sets of HTTP operations (methods), which provide create, retrieve, update or delete access to service’s resources. The set up is quite simple and with SQL Server 2022, Polybase now also supports CSV, Parquet, and Delta files stored on Azure Storage Account v2, Azure Data Lake Storage Gen2, or any S3-compliant object storage. This meant that querying ADLS parquet files was just a few T-SQL commands away and the project could get underway without the need for yet another tool and bespoke set of integrations.
This got me thinking…I recently published a blog post on how SQL Server data can be moved into Snowflake and for that architecture I used bcp utility Python wrapper for data extraction and SSIS package for orchestration and data upload. The solution worked very well but this new-found interest in Polybase led me down the path of using it not only for data virtualization but also as a pseudo-ELT tool used for pushing data into ADLS for upstream consumption. This capability, coupled with a sprinkling of Python code for managing object storage and post-export data validation, allowed for a more streamlined approach to moving data out of SQL Server. It also gave way to a seamless blending of T-SQL and Python code in a single code base and the resulting pipeline handled container storage management, data extraction and data validation from a single stored procedure.
Let’s look at how Polybase and in-database SQL Server Python integration can be used to build a simple framework for managing “E” in the ELT.
Architecture Approach
This solution architecture takes advantage of both: Polybase v3 and in-database custom Python runtime and blends both into a mini-framework which can be used to automate data extraction into a series of flat files e.g. csv, text, parquet to allow other applications to further query or integrate with this data. Apache Parquet is a common file format used in many data integration and processing activities and this pattern allows for a native Parquet files extraction using out-of-the-box SQL Server functionality, with no additional libraries and plug-ins required. Outside of unsupported data type limitations (please see T-SQL code and exclusion defined in the script), it marries multiple, different programmatic paradigms together, resulting in Python and SQL engines running side-by-side and providing robust integration with a range of database vendors and cloud storage providers (including those compatible with S3 APIs).
As many times before, I will also use Wide World Importers OLAP database as my source data. WWI copy can be downloaded for free from HERE.
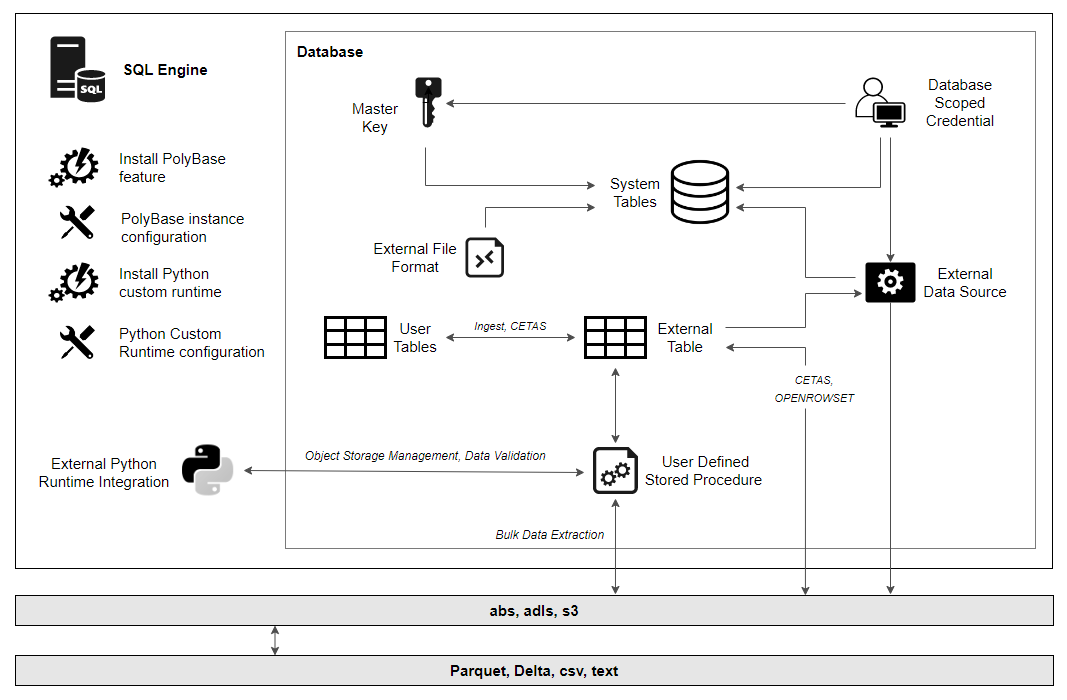
Polybase requires minimal effort to install and configure as it’s already a SQL Server native functionality. After installing Polybase Query Service, the remaining configuration activities can be done in SSMS. First, let’s ensure we have Azure Storage Account created (detailed instructions are in THIS link) and enable Polybase and allow export functionality on the target instance.
EXEC sp_configure @configname = 'polybase enabled', @configvalue = 1;
RECONFIGURE;
GO
EXEC sp_configure 'allow polybase export', 1;
GO
SELECT SERVERPROPERTY ('IsPolyBaseInstalled') AS IsPolyBaseInstalled;
Next, we need to create encryption keys, database scoped credential, external data source and external file format.
USE WideWorldImporters
GO
-- create encryption key
IF EXISTS
(
SELECT *
FROM sys.symmetric_keys
WHERE [name] = '##MS_DatabaseMasterKey##'
)
BEGIN
DROP MASTER KEY;
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'Your_Complex_Pa$$word';
END;
-- create database scoped credential
USE WideWorldImporters
GO
IF EXISTS
(
SELECT *
FROM sys.database_scoped_credentials
WHERE name = 'azblobstore'
)
BEGIN
DROP DATABASE SCOPED CREDENTIAL azblobstore;
END
USE WideWorldImporters
GO
CREATE DATABASE SCOPED CREDENTIAL azblobstore
WITH IDENTITY = 'SHARED ACCESS SIGNATURE',
SECRET = 'Your_SAS_Key';
GO
-- create external data source pointing to the storage account location in Azure
IF EXISTS (SELECT * FROM sys.external_data_sources WHERE name ='azblob')
BEGIN
DROP EXTERNAL DATA SOURCE azblob;
END
CREATE EXTERNAL DATA SOURCE azblob
WITH (
LOCATION = 'abs://demostorageaccount.blob.core.windows.net/testcontainer/',
CREDENTIAL = azblobstore);
-- create external file format for Parquet file type
USE WideWorldImporters
GO
IF EXISTS (SELECT * FROM sys.external_file_formats WHERE name = 'ParquetFileFormat')
BEGIN
DROP EXTERNAL FILE FORMAT ParquetFileFormat;
END
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
Finally, we can test out our configuration and providing all the parameters have been configured correctly, we should be able to use CETAS (create external table as) functionality to copy table’s data into a parquet file in Azure blob.
USE WideWorldImporters
GO
IF OBJECT_ID('customertransactions', 'U') IS NOT NULL
BEGIN
DROP EXTERNAL TABLE customertransactions
END
GO
CREATE EXTERNAL TABLE customertransactions
WITH(
LOCATION = 'customertransactions/',
DATA_SOURCE = azblob,
FILE_FORMAT = ParquetFileFormat)
AS SELECT * FROM [Sales].[CustomerTransactions];
GO
When it comes to Python installation, Microsoft provides a detailed overview of all steps required to install Machine Learning Services (Python and R) on Windows in the following LINK, however, this documentation does not include Python v.3.10 (the required Python interpreter version for SQL Server 2022) download link. Beginning with SQL Server 2022 (16.x), runtimes for R, Python, and Java are no longer shipped or installed with SQL Server setup so anyone wishing to run in-database Python will need to download it and install it manually. To download Python 3.10.0 go to the following location and download the required binaries. Afterwards, follow the installation process and steps as outlined by Microsoft documentation. When concluded, we can run a short script to ensure running external scripts is enabled and Python SQL Server integration is working, and the returned value is as expected.
EXEC sp_execute_external_script @language = N'Python', @script = N'OutputDataSet = InputDataSet;', @input_data_1 = N'SELECT 1 AS PythonValue' WITH RESULT SETS ((PValue int NOT NULL)); GO
In order to make the Parquet files extract and ingestion repeatable (beyond 1st run), we need to ensure the created files can be deleted first. This is due to the fact that defining file names is not an option, neither can they be overwritten (only file location can be specified) and as such, any subsequent run will result in a clash without files being purged first. Interacting with Azure Blob Storage and files can be done through a range of different technologies, but in order to “consolidate” the approach and ensure that we have one code base which can act on many different requirements, all within the confines of SQL Server and no external dependencies, it’s best to do it via Python (will run as part of the same stored procedure code) and pip-install the required libraries first. In SQL Server 2022, recommended Python interpreter location is in C:\Program Files\Python310 directory. To install additional libraries, we need to go down a level and access pip in C:\Program Files\Python310\Scripts directory as admin. I will also install additional libraries to conduct post-export data validation as per below.
pip install azure-storage-blob pip install pyarrow pip install pandas
Now that we have our storage account created and Polybase and Python runtime configured, all we need is our account key and account name in order to execute the following script directly from the SQL Server instance.
DECLARE @az_account_name VARCHAR(512) = 'demostorageaccount';
DECLARE @az_account_key VARCHAR(1024) = 'Your_Storage_Account_Key';
EXECUTE sp_execute_external_script @language = N'Python',
@script = N'
import azure.storage.blob as b
account_name = account_name
account_key = account_key
def delete_blobs(container):
try:
blobs = block_blob_service.list_blobs(container)
for blob in blobs:
if (blob.name.endswith(''.parquet'') or blob.name.endswith(''_'')):
block_blob_service.delete_blob(container, blob.name, snapshot=None)
except Exception as e:
print(e)
def delete_directories(container):
try:
blobs = block_blob_service.list_blobs(container, delimiter=''/'')
for blob in blobs:
if blob.name.endswith(''/''):
delete_sub_blobs(container, blob.name)
blobs_in_directory = list(block_blob_service.list_blobs(container, prefix=blob.name))
if not blobs_in_directory:
block_blob_service.delete_blob(container, blob.name[:-1], snapshot=None)
except Exception as e:
print(e)
def delete_sub_blobs(container, prefix):
try:
blobs = block_blob_service.list_blobs(container, prefix=prefix)
for blob in blobs:
block_blob_service.delete_blob(container, blob.name, snapshot=None)
except Exception as e:
print(e)
block_blob_service = b.BlockBlobService(
account_name=account_name, account_key=account_key
)
containers = block_blob_service.list_containers()
for c in containers:
delete_blobs(c.name)
delete_directories(c.name)',
@input_data_1 = N' ;',
@params = N' @account_name nvarchar (100), @account_key nvarchar (MAX)',
@account_name = @az_account_name,
@account_key = @az_account_key;
Using sp_execute_external_script system stored procedure with @language parameter set to ‘Python’, we can execute Python scripts and run workflows previously requiring additional service or tooling outside of in-database execution. The stored procedure also takes arguments, in this case these are account_name and account_key to authenticate to Azure Storage Account before additional logic is executed. The script simply deletes blobs (ending in .parquet extension and related directories), making space for new files – this will be our first task in a series of activities building up to a larger workflow as per below.
Next, we will loop over tables in a nominated schema and upload WWI data into Azure Blob Storage as a series of Parquet files. Polybase does not play well with certain data types so columns with ‘geography’, ‘geometry’, ‘hierarchyid’, ‘image’, ‘text’, ‘nText’, ‘xml’ will be excluded from this process (see script below). I will use table_name as a folder name in Azure blob storage so that every database object has a dedicated directory for its files. Note that the External Data Source and File Format need to be defined in advance (as per Polybase config script above).
SET NOCOUNT ON;
DECLARE @az_account_name VARCHAR(128) = 'demostorageaccount';
DECLARE @az_account_key VARCHAR(1024) = 'Your_Storage_Account_Key';
DECLARE @external_data_source VARCHAR(128) = 'azblob';
DECLARE @external_file_format VARCHAR(128) = 'ParquetFileFormat';
DECLARE @local_database_name VARCHAR(128) = 'WideWorldImporters';
DECLARE @local_schema_name VARCHAR(128) = 'sales';
DECLARE @Error_Message NVARCHAR(MAX);
DECLARE @Is_Debug_Mode BIT = 1;
-- Run validation steps
IF @Is_Debug_Mode = 1
BEGIN
RAISERROR('Running validation steps...', 10, 1) WITH NOWAIT;
END;
DECLARE @Is_PolyBase_Installed SQL_VARIANT =
(
SELECT SERVERPROPERTY('IsPolyBaseInstalled') AS IsPolyBaseInstalled
);
IF @Is_PolyBase_Installed <> 1
BEGIN
SET @Error_Message = N'PolyBase is not installed on ' + @@SERVERNAME + N' SQL Server instance. Bailing out!';
RAISERROR(@Error_Message, 16, 1);
RETURN;
END;
IF NOT EXISTS
(
SELECT *
FROM sys.external_data_sources
WHERE name = @external_data_source
)
BEGIN
SET @Error_Message
= N'' + @external_data_source + N' external data source has not been registered on ' + @@SERVERNAME
+ N' SQL Server instance. Bailing out!';
RAISERROR(@Error_Message, 16, 1);
RETURN;
END;
IF NOT EXISTS
(
SELECT *
FROM sys.external_file_formats
WHERE name = @external_file_format
)
BEGIN
SET @Error_Message
= N'' + @external_file_format + N' file format has not been registered on ' + @@SERVERNAME
+ N' SQL Server instance. Bailing out!';
RAISERROR(@Error_Message, 16, 1);
RETURN;
END;
DROP TABLE IF EXISTS ##db_objects_metadata;
CREATE TABLE ##db_objects_metadata
(
Id INT IDENTITY(1, 1) NOT NULL,
Local_Column_Name VARCHAR(256) NOT NULL,
Local_Column_Data_Type VARCHAR(128) NOT NULL,
Local_Object_Name VARCHAR(512) NOT NULL,
Local_Schema_Name VARCHAR(128) NOT NULL,
Local_DB_Name VARCHAR(256) NOT NULL
);
DROP TABLE IF EXISTS ##db_objects_record_counts;
CREATE TABLE ##db_objects_record_counts -- this table will be used for record count comparison in subsequent script
(
Id INT IDENTITY(1, 1) NOT NULL,
Local_Object_Name VARCHAR(512) NOT NULL,
Record_Count BIGINT NULL
);
DECLARE @SQL NVARCHAR(MAX);
SET @SQL
= N'INSERT INTO ##db_objects_metadata
(Local_Column_Name, Local_Column_Data_Type, Local_Object_Name,
Local_Schema_Name,
Local_DB_Name)
SELECT column_name, data_type, table_name, table_schema, table_catalog
FROM ' + @local_database_name + N'.INFORMATION_SCHEMA.COLUMNS
WHERE table_schema = ''' + @local_schema_name
+ N'''
GROUP BY
column_name, data_type,
table_name,
table_schema,
table_catalog';
EXEC (@SQL);
IF @Is_Debug_Mode = 1
BEGIN
RAISERROR('Uploading database tables content as parquet files into Azure...', 10, 1) WITH NOWAIT;
END;
DECLARE @Table_Name NVARCHAR(512);
DECLARE @Schema_Name NVARCHAR(512);
DECLARE @Col_Names NVARCHAR(512);
IF CURSOR_STATUS('global', 'cur_db_objects') >= 1
BEGIN
DEALLOCATE cur_db_objects;
END;
DECLARE cur_db_objects CURSOR FORWARD_ONLY FOR
SELECT Local_Object_Name,
Local_Schema_Name,
STRING_AGG(Local_Column_Name, ',') AS col_names
FROM ##db_objects_metadata
WHERE Local_Column_Data_Type NOT IN ( 'geography', 'geometry', 'hierarchyid', 'image', 'text', 'nText', 'xml' ) -- exclude data types not compatible with PolyBase external tables
GROUP BY Local_Object_Name,
Local_Schema_Name;
OPEN cur_db_objects;
FETCH NEXT FROM cur_db_objects
INTO @Table_Name,
@Schema_Name,
@Col_Names;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @SQL = N'IF OBJECT_ID(''' + @Table_Name + N''', ''U'') IS NOT NULL ';
SET @SQL = @SQL + N'BEGIN DROP EXTERNAL TABLE ' + @Table_Name + N' END; ';
SET @SQL = @SQL + N'CREATE EXTERNAL TABLE ' + @Table_Name + N' ';
SET @SQL = @SQL + N'WITH(';
SET @SQL = @SQL + N'LOCATION = ''' + CONCAT(@Table_Name, '/') + N''',';
SET @SQL = @SQL + N'DATA_SOURCE = ' + @external_data_source + N', ';
SET @SQL = @SQL + N'FILE_FORMAT = ' + @external_file_format + N') ';
SET @SQL = @SQL + N'AS SELECT ' + @Col_Names + N' ';
SET @SQL = @SQL + N'FROM [' + @Schema_Name + N'].[' + @Table_Name + N'];';
IF @Is_Debug_Mode = 1
BEGIN
SET @Error_Message = N' --> Processing ' + @Table_Name + N' table...';
RAISERROR(@Error_Message, 10, 1) WITH NOWAIT;
END;
EXEC (@SQL);
SET @SQL = N'INSERT INTO ##db_objects_record_counts (Local_Object_Name, Record_Count) ';
SET @SQL
= @SQL + N'SELECT ''' + @Table_Name + N''', (SELECT COUNT(1) FROM ' + @Schema_Name + N'.' + @Table_Name + N') ';
EXEC (@SQL);
FETCH NEXT FROM cur_db_objects
INTO @Table_Name,
@Schema_Name,
@Col_Names;
END;
CLOSE cur_db_objects;
DEALLOCATE cur_db_objects;
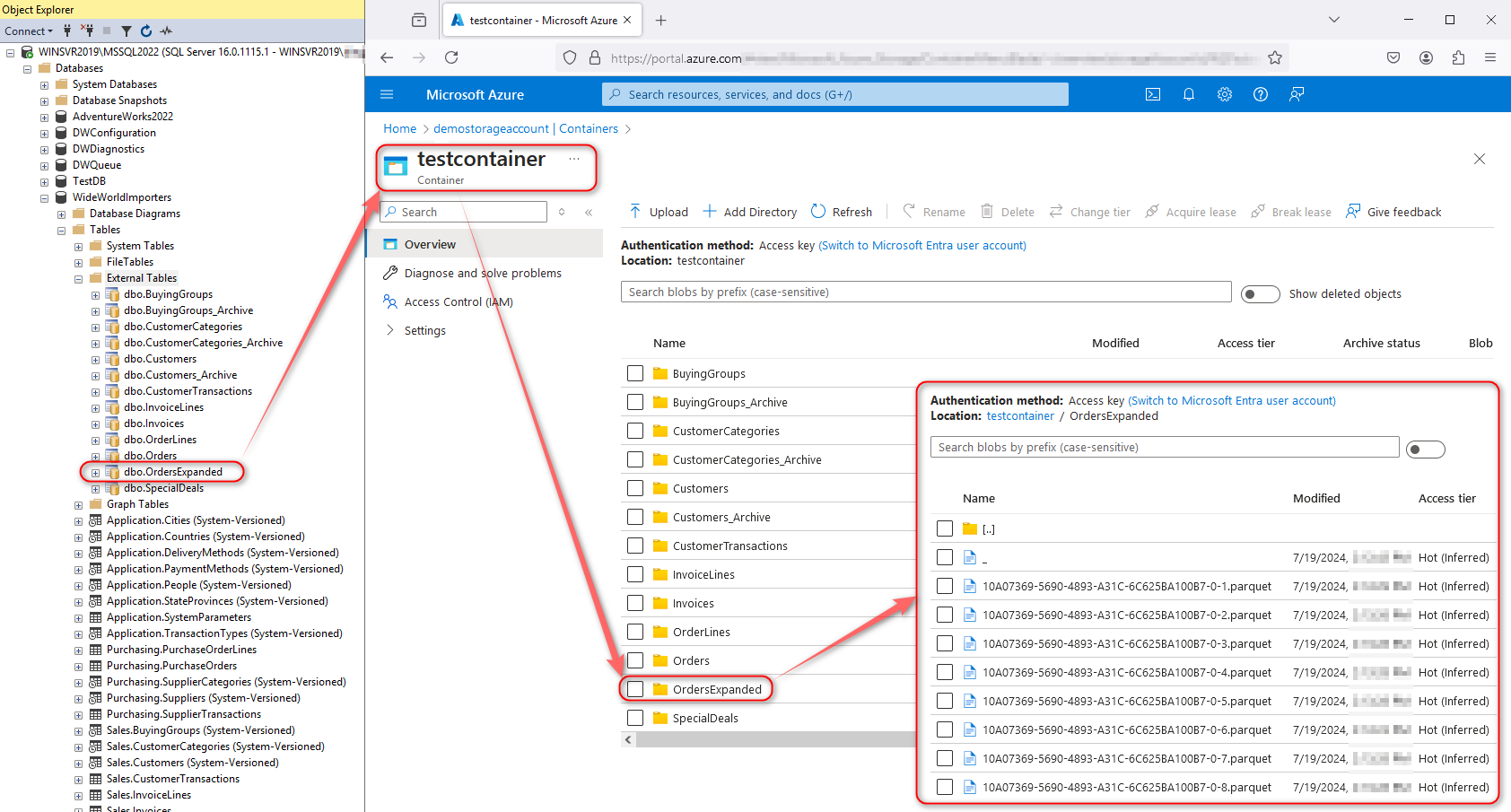
This should create all the required External Tables on the SQL Server instance as well as parquet files in the nominated Azure Storage location (click on image to enlarge).
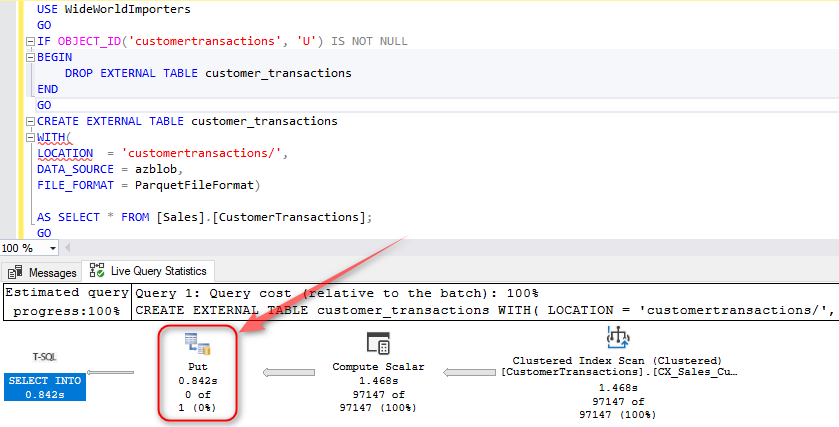
Running CETAS export for a single table, we can also see the execution plan used with he PUT operator, highlighting RESTful data egress capability.
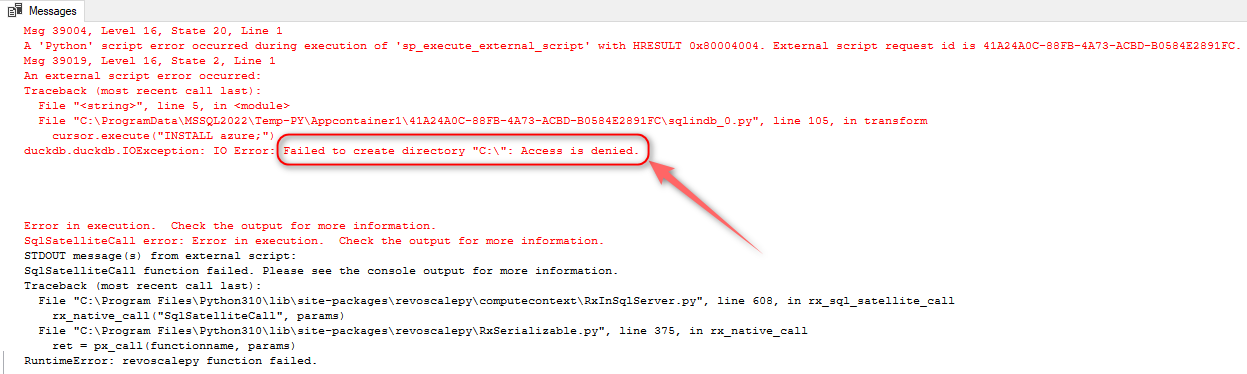
Finally, we can run a data validation test to ensure the record counts across Azure and MSSQL are a match. My initial approach was to take advantage of DuckDB native parquet integration and simply pip-install DuckDB and do a row count for each parquet file. However, as well as this worked as an isolated script, it did not play well with MSSQL Python integration due to SQL Server constraints around accessing and creating (temporary) file system data. As DuckDB requires transient storage workspace to serialize data and access to it is restricted, the implementation worked well in a terminal but would not execute as part of SQL workload.
Instead, using pandas and pyarrow, seemed like a good workaround and the following script can be used to match row counts across Azure parquet files (converted to Pandas data frames) and database tables.
DECLARE @az_account_name VARCHAR(512) = 'demostorageaccount';
DECLARE @az_account_key VARCHAR(1024) = 'Your_Storage_Account_Key';
EXECUTE sp_execute_external_script @language = N'Python',
@script = N'
import azure.storage.blob as b
import pyarrow.parquet as pq
import pandas as pd
import io
account_name = account_name
account_key = account_key
az_record_counts = {}
def compare_record_counts(df1, df2):
merged_df = pd.merge(df1, df2, on=''Object_Name'', suffixes=(''_df1'', ''_df2''), how=''outer'', indicator=True)
differences = merged_df[merged_df[''Record_Count_df1''] != merged_df[''Record_Count_df2'']]
if differences.empty:
print("Success! All record counts match.")
else:
print("Record count mismatches found. Please troubleshoot:")
print(differences[[''Object_Name'', ''Record_Count_df1'', ''Record_Count_df2'']])
return differences
def collect_az_files_record_counts(container):
try:
blobs = block_blob_service.list_blobs(container)
for blob in blobs:
if blob.name.endswith(".parquet"):
blob_data = block_blob_service.get_blob_to_bytes(container, blob.name)
data = blob_data.content
with io.BytesIO(data) as file:
parquet_file = pq.ParquetFile(file)
row_counts = parquet_file.metadata.num_rows
az_record_counts.update({blob.name: row_counts})
except Exception as e:
print(e)
block_blob_service = b.BlockBlobService(account_name=account_name, account_key=account_key)
containers = block_blob_service.list_containers()
for container in containers:
collect_az_files_record_counts(container.name)
directory_sums = {}
for filepath, record_count in az_record_counts.items():
directory = filepath.split("/")[0]
if directory in directory_sums:
directory_sums[directory] += record_count
else:
directory_sums[directory] = record_count
target_df = pd.DataFrame(
[(directory, int(record_count)) for directory, record_count in directory_sums.items()],
columns=["Object_Name", "Record_Count"])
source_df = source_record_counts
df = compare_record_counts(source_df, target_df);
OutputDataSet = df[[''Object_Name'', ''Record_Count_df1'', ''Record_Count_df2'']];',
@input_data_1 = N'SELECT Local_Object_Name as Object_Name, CAST(Record_Count AS INT) AS Record_Count FROM ##db_objects_record_counts WHERE Record_Count <> 0',
@input_data_1_name = N'source_record_counts',
@params = N' @account_name nvarchar (100), @account_key nvarchar (MAX)',
@account_name = @az_account_name,
@account_key = @az_account_key
WITH RESULT SETS
(
(
[object_name] VARCHAR(256) NOT NULL,
Source_Record_Count INT,
Target_Record_Count INT
)
);
When completed, the following output should be displayed on the screen.
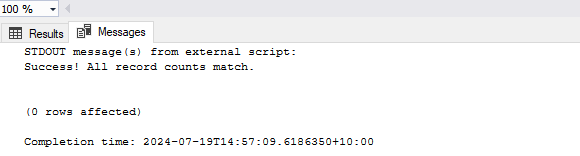
On the other hand, if record count does not match e.g. we deleted one record in the source table, the process should correctly recognized data discrepancies and alert end user/administrator, as per below:
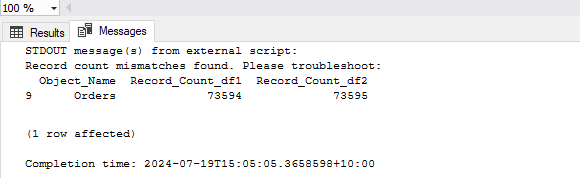
Putting all these pieces together into a single, all-encompassing stored procedure allows us to manage Azure storage, perform data extraction and execute data quality checks from a single code base. A copy of the stored procedure can be found in my OneDrive folder HERE.
Anecdotal Performance Test
Looking at Polybase performance for one specific database object, I multiplied Orders table record count (original count was 73,595) by a factor of 10, 50, 100, 150 and 200 into a new table called OrderExpanded and run the same process to ascertain the following:
- Data compression ratio for both: in-database data volume/size as well as flat file (Parquet format) columnar storage in Azure Blob. For in-database data size, two scenarios were explored: no compression and columnstore compression applied to the Orders object.
- CPU and elapsed processing times.
These tests were run in a small Virtual Machine with 8 cores (Intel Core i5-10500T CPU, running at 2.30GHz) allocated to the 2022 Developer Edition instance, 32GB 2667MHz RAM and a single Samsung SSD QVO 1TB volume on a 100/20 Mbps WAN network. The following performance characteristics were observed when running Polybase ETL workloads across columnstore-compressed and uncompressed data across different data sizes.
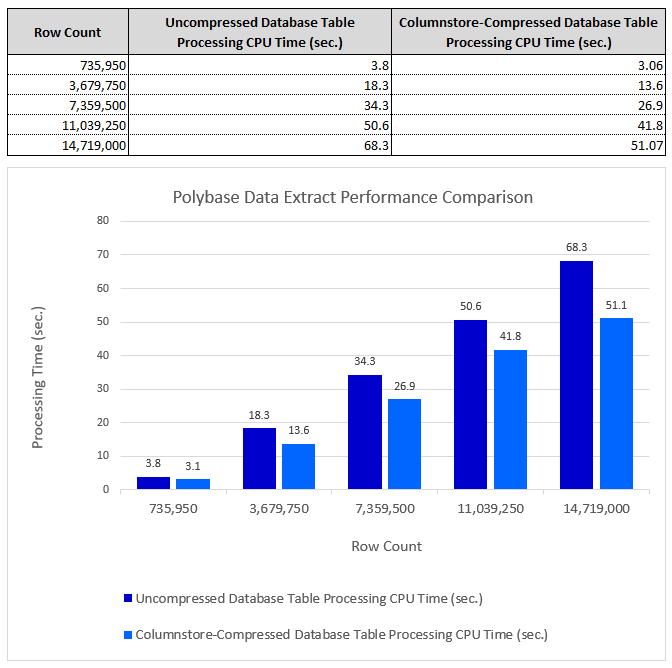
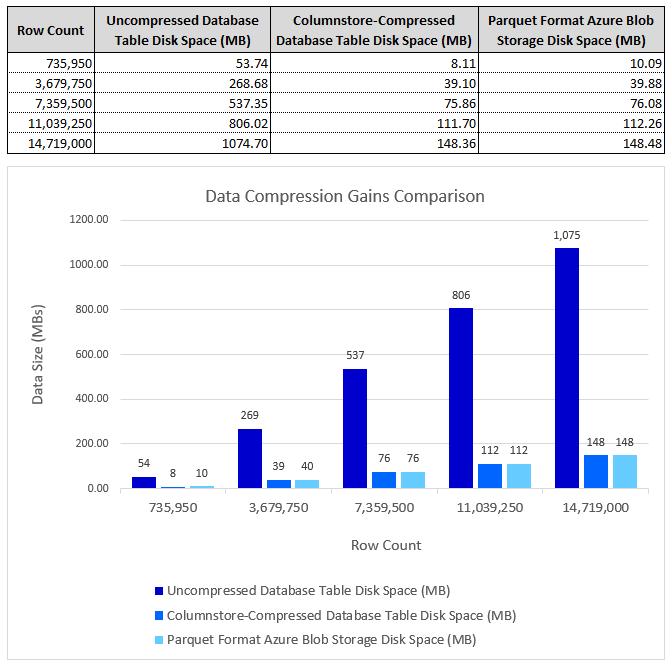
Data egress performance appeared to be linear, corresponding to the volume of data across the ranges tested. There was a noticeable improvement to tables with a columnstore index applied to it, not only in terms of data size on disk, but also upload speeds. This is in spite of the fact columnstore compression typically results in a higher CPU utilization during the read phase. Another interesting (but expected) finding is that data compression gains resulting from storing data in Parquet file format (in Azure Blob Storage) as well as in a columnstore-compressed table (in-database) were significant, sometimes resulting in more than 7x improvement (reduction) in data compression rate and data volume/size. The compression rate achieved, and the subsequent data egress performance improvements significantly outweigh decompression compute overhead (higher CPU utilization). As with any approach, these will need to be analyzed on their own merits and in the context of a particular architecture and use case (will not apply uniformly across all workloads), however, providing CPU resources have not been identified as a potential choke-point, applying columnstore compression to database objects provides a good tradeoff between higher resources utilization and performance gains.
Another benefit of using Polybase for data extraction is that it natively supports Parquet and Delta table format. There’s no need for 3rd party libraries in order to serialize SQL Server data into columnar storage format with metadata appended to it – Polybase can do it out-of-the-box.
Conclusion
Until now, I never had a chance or a good reason to play around with Polybase and I’ve always assumed that rolling out a dedicated tool for batch data extraction workloads is a better option. Likewise, I never thought that beyond Machine Learning applications, in-database Python code running side-by-side T-SQL is something I’d use outside of a Jupyter notebook, POC-like scenario. However, I was presently surprised how easy it was to blend these two technologies together and even though improvements could be made to both e.g. it would be nice to see Polybase native integration with other popular database engines or Python and T-SQL coalescing into other areas of data management, it was surprisingly straightforward to stand up a simple solution like this. With other RDBMS vendors betting on Python becoming a first class citizen on their platforms e.g. Snowflake, and lines between multi-cloud, single-cloud and hybrid blurring even more, Microsoft should double-down on these paradigms and keep innovating (Fabric does not work for everyone and everything!). I guess we will just have to cross our fingers and toes and wait for the 2025 version to arrive!
http://scuttle.org/bookmarks.php/pass?action=addThis entry was posted on Monday, July 22nd, 2024 at 3:32 pm and is filed under Cloud Computing, Programming, SQL. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.



Kunal Mij August 1st, 2024 at 12:30 am
Hi sir
Good post but what are the good points for using python in SQL Server when you can use it without issues or restrictions by just calling whatever interpreter you have installed on your machine. I can use batch script and call it that way or you can even do it in SSIS. Or you can use pyodbc and connect to your database to do any modifications and return your data that way.
Python in SQL Server is not flexible and has many issues so I would stay away from this way of using it.