In-Memory Natively Compiled vs Interpreted Stored Procedures Performance Comparison in SQL Server 2014
Introduction
Whilst the past couple of pre-2014 SQL Server releases have had a strong focus on business intelligence (BI), 2014 edition focuses largely on relational database features and support. Amongst few compelling new additions presented in SQL Server 2014 release is In-Memory OLTP engine, which promises some big performance improvements for OLTP applications.
In the majority of relational databases query runtime cost is typically comprised of latching/locking, disk I/O as well as the overhead associated with the engine interpreting the code thus increasing the number of CPU cycles required to produce the desired output. As most of those roadblocks are mitigated by means of storing the data in memory and taking advantage of ‘bypassing’ SQL Server interpretive engine in favor of complied code, In-Memory OLTP is claimed to have the ability to improve performance by the factor of 20 or more (depending on the workload, data, transaction type and hardware used).
Performance Testing
In this short post I’d like to perform a rudimentary analysis of the performance improvements achieved through utilizing In-Memory OLTP with compiled stored procedure versus disk-based/interpreted code implementation. My test bed is my old trusty Lenovo laptop (X230 series) with quad-core Intel i5-3320M CPU (2.60GHz), 16 gigabytes of RAM and Samsung 840 PRO SSD running Windows 8.1 and SQL Server 2014 Developers Edition installed. I will be comparing execution times for INSERT and UPDATE statements in in-memory database for both: natively compiled stored procedures and standard, ‘interpreted’ T-SQL code.
Let’s start with creating a sample database, a memory optimized table and four stored procedures used for this demonstration. Notice that the code difference between the first CREATE STORED PROCEDURE SQL statements and the second one is the fact that ‘usp_insert_data_compiled’ stored procedure, creates functionally equivalent construct to its non-compiled counterpart with the distinction of compiling the code into processor instructions which can be executed directly by the CPU, without the need for further compilation or interpretation thus invoking fewer CPU instructions then the equivalent interpreted T-SQL.
--CREATE InMemoryDemo SAMPLE DATABASE
USE master
GO
IF DB_ID('InMemoryDBSample') IS NOT NULL
BEGIN
DROP DATABASE InMemoryDBSample
END
CREATE DATABASE InMemoryDBSample ON PRIMARY
(NAME = N'InMemoryDemo_Data',
FILENAME = N'c:\DBSample\InMemoryDemo.mdf'), FILEGROUP InMemoryDemo_fg
CONTAINS MEMORY_OPTIMIZED_DATA
(NAME = N'InMemoryDemo_Dir',
FILENAME = N'c:\DBSample\InMemoryDemo_Mod') LOG ON (NAME = 'InMemoryDemo_Log',
FILENAME = N'c:\DBSample\InMemoryDemo.ldf')
GO
--create table
USE InMemoryDBSample
CREATE TABLE SampleTable
(
ID INT IDENTITY(1, 1)
NOT NULL ,
Value1 INT NOT NULL ,
Value2 INT NOT NULL ,
Value3 DECIMAL(10, 2) NOT NULL ,
Value4 DATETIME NOT NULL ,
Value5 DATETIME NOT NULL ,
CONSTRAINT PK_ID PRIMARY KEY NONCLUSTERED ( ID ASC )
)
WITH (
MEMORY_OPTIMIZED =
ON,
DURABILITY =
SCHEMA_ONLY)
--CREATE In-Memory TABLE WITH PRIMARY KEY ON IDENTITY COLUMN
USE InMemoryDBSample
CREATE TABLE SampleTable
(
ID INT IDENTITY(1, 1)
NOT NULL ,
Value1 INT NOT NULL ,
Value2 INT NOT NULL ,
Value3 DECIMAL(10, 2) NOT NULL ,
Value4 DATETIME NOT NULL ,
Value5 DATETIME NOT NULL ,
CONSTRAINT PK_ID PRIMARY KEY NONCLUSTERED ( ID ASC )
)
WITH (
MEMORY_OPTIMIZED =
ON,
DURABILITY =
SCHEMA_ONLY)
--CREATE NON-COMPILED 'INSERT' STORED PROCEDURE
CREATE PROCEDURE usp_insert_data_noncompiled
(
@records_to_insert int
)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @var INT = 0
WHILE @var < @records_to_insert
BEGIN
INSERT INTO dbo.SampleTable
( Value1 ,
Value2 ,
Value3 ,
Value4 ,
Value5
)
SELECT 10 * RAND() ,
20 * RAND() ,
10000 * RAND() / 100 ,
DATEADD(ss, @var, SYSDATETIME()) ,
CURRENT_TIMESTAMP;
SET @var = @var + 1
END
END
--CREATE NATIVELY COMPILED 'INSERT' STORED PROCEDURE
CREATE PROCEDURE usp_insert_data_compiled
(
@records_to_insert INT
)
WITH NATIVE_COMPILATION,
SCHEMABINDING,
EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH ( TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE =
N'us_english' )
DECLARE @var INT = 0
WHILE @var < @records_to_insert
BEGIN
INSERT INTO dbo.SampleTable
( Value1 ,
Value2 ,
Value3 ,
Value4 ,
Value5
)
SELECT 10 * RAND() ,
20 * RAND() ,
10000 * RAND() / 100 ,
DATEADD(ss, @var, SYSDATETIME()) ,
CURRENT_TIMESTAMP;
SET @var = @var + 1
END
END
--CREATE NON-COMPILED 'UPDATE' STORED PROCEDURE
CREATE PROCEDURE usp_update_data_noncompiled
AS
BEGIN
SET NOCOUNT ON;
DECLARE @var INT = 0
DECLARE @record_ct INT
SELECT @record_ct = MAX(ID)
FROM dbo.SampleTable
WHILE @var < @record_ct
BEGIN
UPDATE dbo.SampleTable
SET Value1 = 20 * RAND() ,
Value2 = 10 * RAND() ,
Value3 = 10000 * RAND() / 1000 ,
Value4 = DATEADD(ss, -@var, Value4) ,
Value5 = DATEADD(ss, -@var, Value4)
WHERE ID = @var;
SET @var = @var + 1
END
END
--CREATE NATIVELY COMPILED 'UPDATE' STORED PROCEDURE
CREATE PROCEDURE usp_update_data_compiled
WITH NATIVE_COMPILATION,
SCHEMABINDING,
EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH ( TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE =
N'us_english' )
DECLARE @var INT = 0
DECLARE @record_ct INT
SELECT @record_ct = MAX(ID)
FROM dbo.SampleTable
WHILE @var < @record_ct
BEGIN
UPDATE dbo.SampleTable
SET Value1 = 20 * RAND() ,
Value2 = 10 * RAND() ,
Value3 = 10000 * RAND() / 1000 ,
Value4 = DATEADD(ss, -@var, Value4) ,
Value5 = DATEADD(ss, -@var, Value4)
WHERE ID = @var;
SET @var = @var + 1
END
END
Before I run the code to put the performance of In-Memory OLTP to test, there are few other things in the above code which are worth noting. The SCHEMA_ONLY clause (on compiled code snippet) indicates that SQL Server will log table creation so that the table schema will be durable but will not log any data manipulation on the table, so the data will not be durable. These type of tables do not require any I/O operations during transaction processing and the data is only available in-memory while SQL Server is running. In the event of SQL Server shutdown the data stored in these tables is purged and will not be persisted on restart, however, all operations on this data meet ACID requirements i.e. are atomic, consistent, isolated and durable. Another important functional aspect to highlight is that apart from WITH_NATIVE_COMPILATION clause added (which as the name implies compiles the SQL code for faster execution) the use of WITH SCHEMABINDING and BEGIN ATOMIC clauses is a requirement.
Let’s look at the execution results for both, non-compiled and compiled ‘Insert’ stored procedures.
--EXECUTE COMPILED 'Insert' STORED PROCEDURE EXEC dbo.usp_insert_data_compiled @records_to_insert = 1000000 GO --EXECUTE NON-COMPILED 'Insert' STORED PROCEDURE EXEC dbo.usp_insert_data_noncompiled @records_to_insert = 1000000 GO
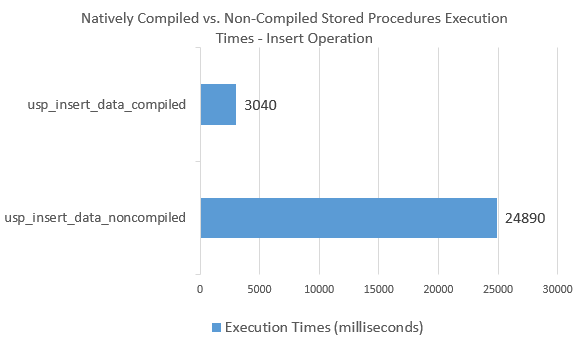
As we can see, ‘Insert’ operation on natively compiled stored procedure yielded a performance increase of over 800 percent, which is a substantial improvement. Likewise, the results from ‘Update’ statement show similar improvements as per the image below.
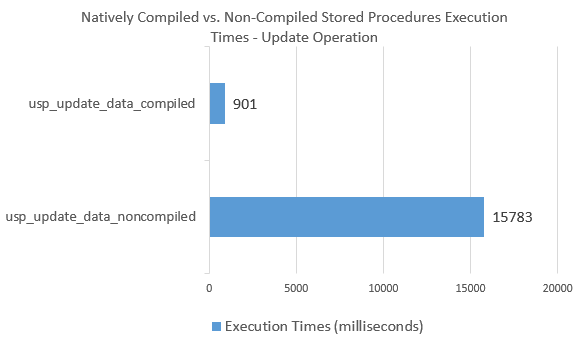
Conclusion
As we can see from this rudimentary exercise, natively compiled stored procedure execution is a lot more efficient, generating far fewer CPU instructions for the SQL Server engine thus improving performance by a considerable margin. Compiling stored procedure’s code creates a highly efficient data access path, allowing for much faster data operations which, in most cases, outperform a non-compiled stored procedure that uses an In-Memory table.
http://scuttle.org/bookmarks.php/pass?action=addThis entry was posted on Monday, January 12th, 2015 at 3:32 am and is filed under SQL. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.


