Kicking The Tires On Azure Functions – How To Build Simple Event-Driven Or Trigger-Based Data Pipelines Using Serverless Compute Workloads
Introduction
There are many ways to skin the cat when it comes to using public cloud services to solve business problems, so understanding pros and cons of each can often make a big difference. Container-based deployments have recently been all the rage for stateless applications but for small, cost-effective and short-lived workloads serverless (not a big fan of the buzzword BTW) may offer a better fit. For medium to large data volumes, I would refrain from using this paradigm due to architectural constraints e.g. limit on execution time. However, for anything lightweight e.g. data augmentation, file handling, real-time stream processing, API calls, essentially anything that is designed to be ‘chatty’ rather than ‘chunky’, functions may be a good alternative to running those processes in a dedicated environment. In this post I want to look at how Azure Functions can be used to augment relational database entries with Azure Cognitive Services and how flat files stored in Azure Blob Storage can be processed using trigger-based logic.
Both of those scenarios can be handled using many different compute styles but given the short-lived nature of these workloads, Azure Function may be the most cost-effective way of executing these pipelines. Additionally, these integrate well with other Azure services e.g. Data Factory, so for certain bespoke and targeted scenarios these may offer a good alternative to, for example, provisioning virtual machines or containers.
What are Azure Functions
Azure Functions is an event driven, compute-on-demand experience that extends the existing Azure application platform with capabilities to implement code triggered by events occurring in virtually any Azure or 3rd party service as well as on-premises systems. Azure Functions allows developers to take action by connecting to data sources or messaging solutions, thus making it easy to process and react to events. Additionally, as of March this year, Microsoft also announced Python support for Durable Functions – an extension to Azure Functions that lets developers orchestrate complex data processing and data science pipelines. Here is a quick, high-level video from Microsoft outlining the intended purpose and some of its functionality.
As Microsoft has a lot of good documentation outlining many possible scenarios where this type of compute paradigm can be useful, I won’t go into details on how to set up your environment, debug and monitor your Azure Functions; those topics are just a Google query away if you’d like to familiarize yourself with the overall development lifecycle. I will, however, go over a few details relating to some hurdles I encountered, as I found the overall development process straightforward, but not without a few little pitfalls.
Azure Functions Quick Development Guide
A function is the primary concept in Azure Functions. A function contains two important pieces – our code, which can be written in a variety of languages, and some config, the function.json file. For compiled languages, this config file is generated automatically from annotations in your code. For scripting languages, you must provide the config file yourself.
The function.json file defines the function’s trigger, bindings, and other configuration settings. Every function has one and only one trigger. The runtime uses this config file to determine the events to monitor and how to pass data into and return data from a function execution. The host.json file contains runtime-specific configurations and is in the root folder of the function app. A bin folder contains packages and other library files that the function app requires. This file does get published to Azure. The local.settings.json file is used to store app settings and connection strings when running locally. This file also doesn’t get published to Azure.
Azure Functions expects a function to be a stateless method in our Python script that processes input and produces output. By default, the runtime expects the method to be implemented as a global method called main() in the __init__.py file. Also, all functions in a function app must be authored in the same language.
A function app provides an execution context in Azure in which your functions run. As such, it is the unit of deployment and management for your functions. A function app is comprised of one or more individual functions that are managed, deployed, and scaled together. All of the functions in a function app share the same pricing plan, deployment method, and runtime version. Think of a function app as a way to organize and collectively manage your functions. The code for all the functions in a specific function app is located in a root project folder that contains a host configuration file and one or more sub-folders. Each sub-folder contains the code for a separate function. The recommended folder structure for a Python Functions project looks like the following example.
<project_root>/ | - .venv/ | - .vscode/ | - my_first_function/ | | - __init__.py | | - function.json | | - example.py | - my_second_function/ | | - __init__.py | | - function.json | - shared_code/ | | - __init__.py | | - my_first_helper_function.py | | - my_second_helper_function.py | - tests/ | | - test_my_second_function.py | - .funcignore | - host.json | - local.settings.json | - requirements.txt | - Dockerfile
Function apps can be authored and published using a variety of tools, including Visual Studio, Visual Studio Code, IntelliJ, Eclipse, and the Azure Functions Core Tools. All the solution artifacts are created automatically by the development environment (in my case VS Code) and even though Azure portal lets you update your code and your function.json file directly inline, best practice is to use a local development tool like VS Code.
Ok, let’s jump in into our first case scenario.
Augmenting Azure SQL DB data with Azure Cognitive Services Sentiment Analysis and Key Terms
Microsoft, just as any other major cloud vendor, provides as suite of text-mining AI services that uncover insights such as sentiment analysis, entities, relations and key phrases in unstructured and structured text. Working with a client in my past engagement, I used it to provide sentiment analysis and key terms extraction for Dynamics 365 emails. Both of those allowed the business to prioritise and respond to messages which had negative tone e.g. complains, dissatisfied clients, urgent issues that required immediate attention as well as looking at the most frequently occurring statements and phrases to discern most talked about issues and topics (these look really good when visualized as word clouds). In this scenario I will outline how with very little code (Python in this case) one can do the same and augment dummy feedback data with sentiment analysis and term extraction. Feedback data is stored in a SQL database and the function app runs on a 5 minute cadence (fully configurable). The architecture for this is pretty straightforward and as always, I will make all code required to replicate this solution in my OneDrive folder HERE.
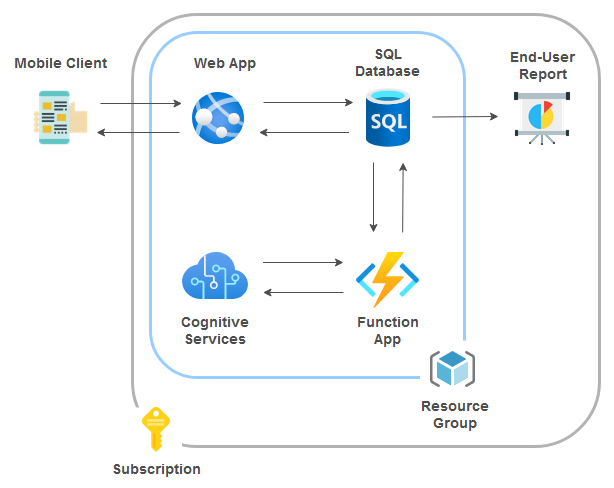
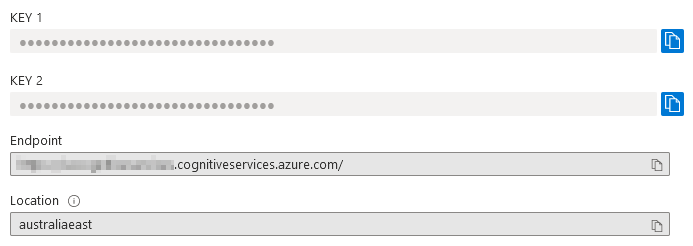
To simplify things, I will skip the App Service Web app and assume that that we already have feedback data stored inside the nominated database object, ready for further processing. Also, the code to deploy Azure SQL DB along with its objects and sample feedback data is very similar to the one from my previous blog post HERE so you can source it from there (alternatively there is a separate copy in my aforementioned OneDrive folder HERE). Finally, creating the Cognitive Services resource is very easy to spin up in the portal so in the interest of keeping this post concise, I will skip the details. The only piece of information required from the service is the pair of keys for API endpoint access.
Now, assuming we have Azure SQL DB and Cognitive Services resource up-and-running, we should be able to investigate how Azure Function is built and start augmenting the feedback entries with text analytics. The following code (__init__.py file) takes 6 records from our Azure SQL database containing feedback information (see DDL and DML code HERE) and passes those through the Azure Cognitive Service API to assign the following values: Feedback_Sentiment, Positive_Sentiment_Score, Negative_Sentiment_Score, Neutral_Sentiment_Score. It also extracts key phrases and stores those in the Key_Phrases field in the same table.
import logging
import azure.functions as func
import pyodbc
from azure.ai.textanalytics import TextAnalyticsClient
from azure.core.credentials import AzureKeyCredential
RESOURCE_GROUP = 'YourResourceGroupName'
LOCATION = 'australiasoutheast'
SQL_SERVER = 'yourservername.database.windows.net'
SQL_DB = 'yourdatabasename'
USERNAME = 'yourusername'
PASSWORD = 'YourTopS3cretPa$$word'
DRIVER = '{ODBC Driver 17 for SQL Server}'
resource_key = 'YourResourceKey'
resource_endpoint = 'https://yoururl.cognitiveservices.azure.com/'
def authenticate_client():
ta_credential = AzureKeyCredential(resource_key)
text_analytics_client = TextAnalyticsClient(
endpoint=resource_endpoint,
credential=ta_credential,
api_version="v3.1-preview.3")
return text_analytics_client
def main(mytimer: func.TimerRequest) -> None:
client = authenticate_client()
logging.info(
'Attempting {mssql} SQL Server connection...'.format(mssql=SQL_SERVER))
try:
cnxn = pyodbc.connect('DRIVER='+DRIVER+';SERVER='+SQL_SERVER +
';PORT=1433;DATABASE='+SQL_DB+';UID='+USERNAME+';PWD=' + PASSWORD)
except pyodbc.Error as e:
sqlstate = e.args[1]
logging.error(
sqlstate)
if cnxn:
cursor = cnxn.cursor()
# Get all Feedback field entries from the table skipping where Feedback_Sentiment values have already been assigned
# Also filter any values which exceed maximum allowed length i.e. 5120 characters
rows = cursor.execute(
"""SELECT a.ID,
a.Feedback
FROM
(
SELECT
ID,
REPLACE(REPLACE(REPLACE(REPLACE(feedback, CHAR(13), ' '), CHAR(10), ' '), CHAR(160), ' '), CHAR(9), ' ') AS Feedback
FROM dbo.feedback
WHERE Feedback_Sentiment IS NULL
) a
WHERE LEN(a.Feedback) <= 5120""")
rows = cursor.fetchall()
if rows:
for row in rows:
try:
# for each row returned get sentiment value and update Feedback table
response = client.analyze_sentiment(
documents=[row[1]])[0]
if not response.is_error:
cursor.execute("""UPDATE dbo.feedback
SET Feedback_Sentiment = ?,
Positive_Sentiment_Score = ?,
Negative_Sentiment_Score = ?,
Neutral_Sentiment_Score = ?
WHERE ID = ?""", response.sentiment.title(), response.confidence_scores.positive, response.confidence_scores.negative, response.confidence_scores.neutral, row[0])
cursor.commit()
except pyodbc.Error as e:
sqlstate = e.args[1]
logging.error(sqlstate)
# Get all description field entries from the table skipping where Key_Phrases values have already been assigned
# Also filter any values which exceed maximum allowed length i.e. 5120 characters
else:
logging.info(
'No records with matching update criteria for Feedback_Sentiment fields found in the Feedback table.')
rows = cursor.execute("""SELECT a.ID,
a.Feedback
FROM
(
SELECT ID,
REPLACE(REPLACE(REPLACE(REPLACE(Feedback, CHAR(13), ' '), CHAR(10), ' '), CHAR(160), ' '), CHAR(9), ' ') AS Feedback
FROM dbo.feedback
WHERE Key_Phrases IS NULL
) a
WHERE LEN(a.Feedback) <= 5120""")
rows = cursor.fetchall()
if rows:
for row in rows:
try:
# for each row returned get key phrases value and update Feedback table
response = client.extract_key_phrases(
documents=[row[1]])[0]
if not response.is_error:
cursor.execute("""UPDATE dbo.Feedback
SET Key_Phrases = ?
WHERE ID = ?""", ', '.join(response.key_phrases), row[0])
cursor.commit()
except pyodbc.Error as e:
sqlstate = e.args[1]
logging.error(sqlstate)
else:
logging.info(
'No records with matching update criteria for Key_Phrases field found in the Feedback table')
cursor.execute("""UPDATE dbo.feedback
SET Key_Phrases = CASE WHEN LEN(Feedback) > 5120
THEN 'Content Deemed Too Long For Terms Extraction' ELSE 'Unknown' END
WHERE Key_Phrases IS NULL
""")
cursor.commit()
cursor.execute("""UPDATE dbo.Feedback
SET Feedback_Sentiment = CASE WHEN LEN(Feedback) > 5120
THEN 'Content Deemed Too Long For Sentiment Extraction' ELSE 'Unknown' END
WHERE Feedback_Sentiment IS NULL
""")
cursor.commit()
The function is executed in 5-minute intervals (using timer trigger). Schedule value is a six-field CRON expression – by providing */5 * * * * value, the function will run every 5 minutes from the first run. We can also notice that even though none of the entries used for sentiment analysis or term extraction were longer than 5120 characters, due to API limitation on the maximum length of string allowed, there is a SQL predicate used to only account for those entries which fall under this threshold.
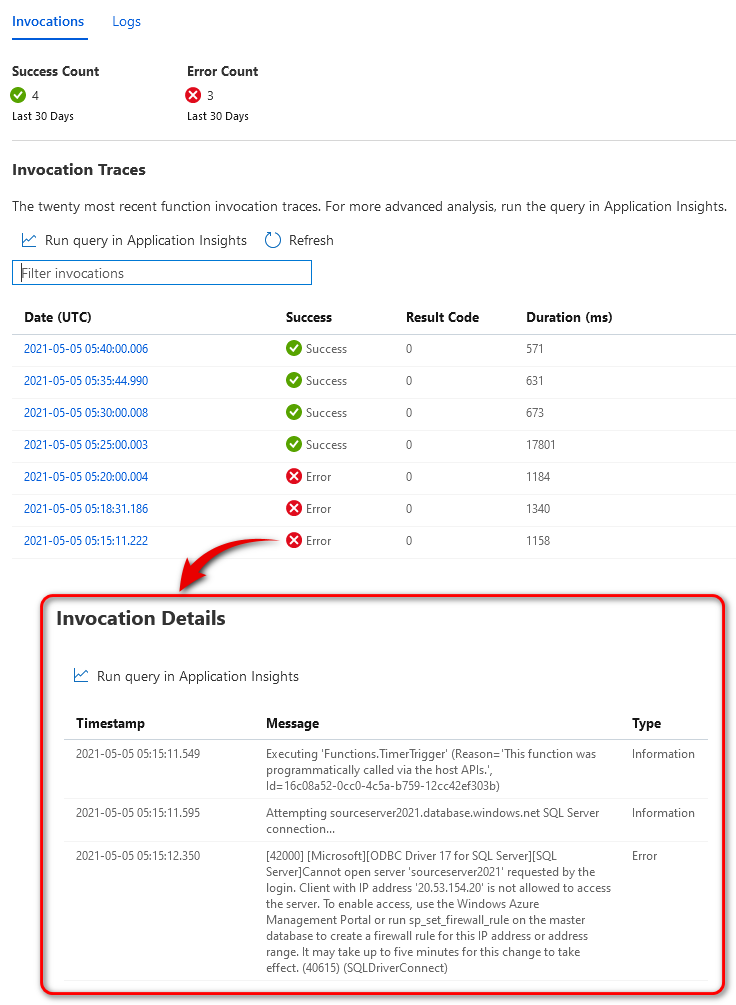
Looking at the Azure portal in the dedicated resource created by the deployment process we can notice the first 3 function invocations failing. This is where logs become very helpful and with a quick glance at the execution details, we can see the issue was caused by the function app not being whitelisted for access to Azure SQL database, where the feedback data was stored. Once the function environment IP address was added to the firewall rule, it all run smoothly.
 Finally, looking at the feedback data we can see that all required attributes were updated as per the above script (click on image to enlarge).
Finally, looking at the feedback data we can see that all required attributes were updated as per the above script (click on image to enlarge).
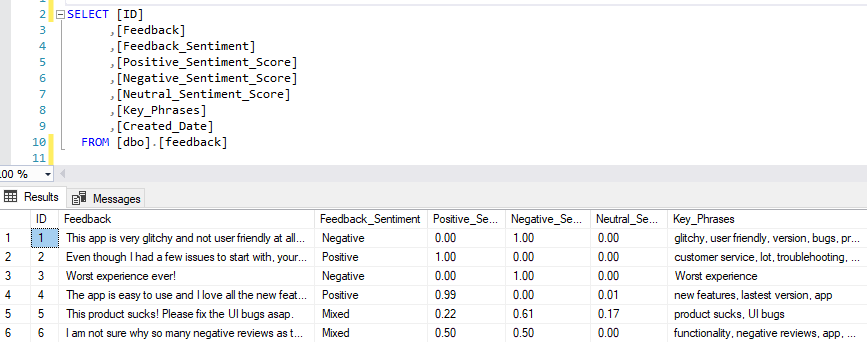
Updating Azure SQL Database based on Blob Storage File Input Trigger
Next up, we will be looking at another scenario where a number of JSON files have been generated using the sample Python code and the task is to extract specific data out of those entries and log it in the already per-provisioned database and table.
To make things a bit more interactive and closer to what the real-world scenario might look like, let’s assume that we need to source the RSS feeds data from Microsoft’s Tech Community blogs dealing with three topics: Azure DevOps, Azure Data Factory and Azure SQL. Each one of those feeds has been associated with a URL and, using the below script, I downloaded 5 entries for each channel, parsed the output and serialized data into 3 different JSON files (each corresponding to the dedicated RSS feed) and finally staged those in the Azure Blob storage.
import xml.etree.ElementTree as ET
import json
import requests
from datetime import datetime
from azure.storage.blob import BlobServiceClient, ContainerClient
from azure.common.client_factory import get_client_from_cli_profile
urls = {'Azure Data Factory': 'https://techcommunity.microsoft.com/plugins/custom/microsoft/o365/custom-blog-rss?tid=5653966150464677274&board=AzureDataFactoryBlog&label=&messages=&size=5',
'Azure DevOps': 'https://techcommunity.microsoft.com/plugins/custom/microsoft/o365/custom-blog-rss?tid=5653966150464677274&board=AzureDevOps&label=&messages=&size=5',
'Azure SQL': 'https://techcommunity.microsoft.com/plugins/custom/microsoft/o365/custom-blog-rss?tid=5653966150464677274&board=AzureSQLBlog&label=&messages=&size=5'
}
az_storage_connection_string = 'YourAzureStorageConnectionString'
container_name = 'rssfiles'
def parse_rss_feed(content):
articles = []
root = ET.fromstring(content)
articles_collection = root.findall("./channel/item")
for article in articles_collection:
article_dict = {}
for elem in article.iter():
article_dict[elem.tag] = elem.text.strip()
articles.append(article_dict)
return articles
def main(urls, az_storage_connection_string, container_name):
for k, v in urls.items():
articles = []
response = requests.get(url=v)
if response.ok:
articles_parsed = parse_rss_feed(content=response.content)
if articles_parsed:
articles = articles + articles_parsed
for element in articles:
if 'item' in element:
del element['item']
filename = "Microsoft_RSS_Feed_{blog}_{ts}.json".format(blog=k.replace(' ', '_'),
ts=datetime.now().strftime("%Y%m%d_%I%M%S%p")
)
container_client = ContainerClient.from_connection_string(
conn_str=az_storage_connection_string, container_name=container_name)
blob_service_client = BlobServiceClient(
account_url=az_storage_connection_string)
all_containers = blob_service_client.list_containers(
name_starts_with='rss')
container_client.upload_blob(
name=filename,
data=json.dumps(obj=articles, indent=4)
)
if __name__ == "__main__":
main(urls, az_storage_connection_string, container_name)
When executed, the following three files were created in the nominated destination.
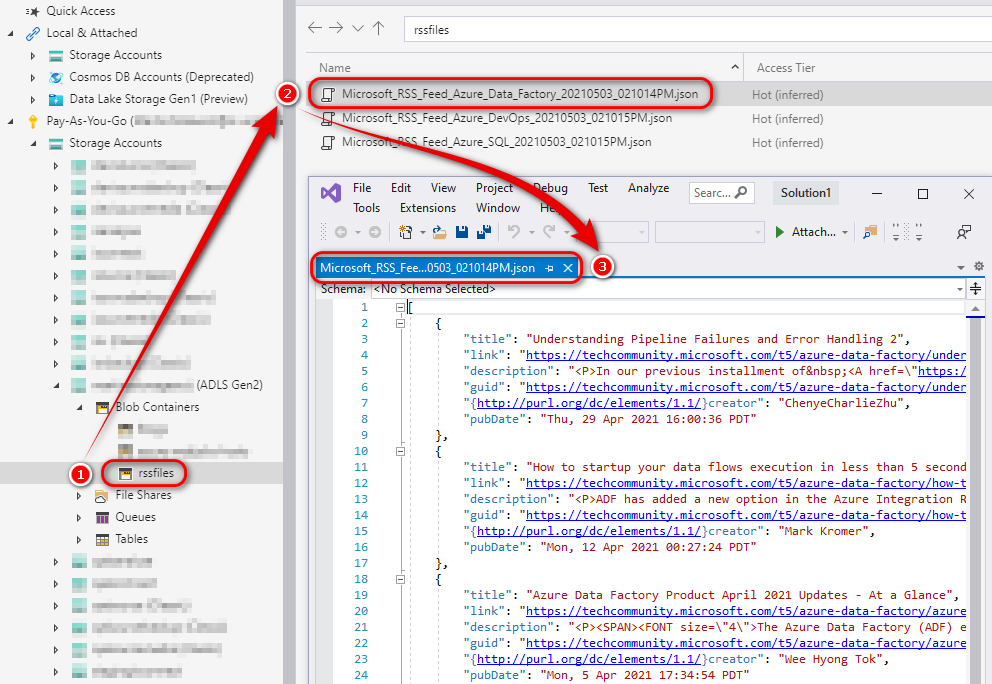
Next, let’s assume we would like to extract File Name, Title, Link and Description attributes and insert those into a table as soon as the files have been created in the Azure Blob storage. This is where another type of Azure function, one that can react to changes in the blob storage, can be used. The Blob storage trigger starts a function when a new or updated blob is detected. Polling works as a hybrid between inspecting logs and running periodic container scans and blobs are scanned in groups of 10,000 at a time with a continuation token used between intervals. Once the new file has been discovered, the function is invoked, and the process simply reads the file content and inserts the selected data into the rss_feeds table as per the diagram below.
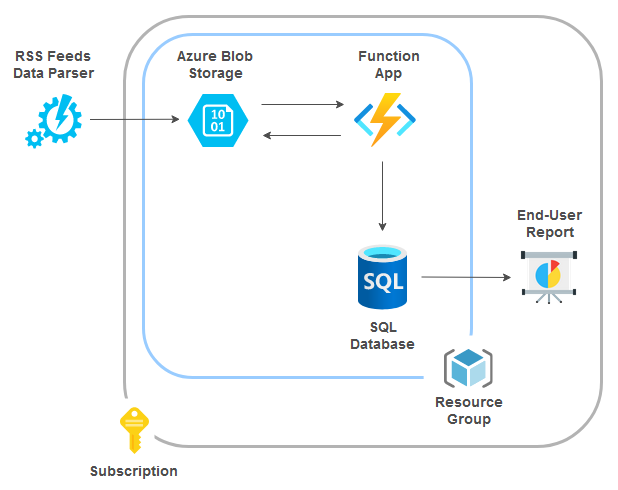
The following short Python snippet was used to construct the Blob Trigger function responsible for reading the RSS feed from one or many JSON files, extract relevant attributes and finally insert the required data into the table.
import logging
import json
import azure.functions as func
import pyodbc
from azure.storage.blob import BlobServiceClient, ContainerClient
SQL_SERVER = 'yourservername.database.windows.net'
SQL_DB = 'yourdatabasename'
USERNAME = 'yourusername'
PASSWORD = 'YourTopS3cretPa$$word'
DRIVER = '{ODBC Driver 17 for SQL Server}'
az_storage_connection_string = 'YourAzureStorageConnectionString'
container_name = 'rssfiles'
def main(myblob: func.InputStream):
blob_service_client = BlobServiceClient.from_connection_string(
az_storage_connection_string)
container = ContainerClient.from_connection_string(
conn_str=az_storage_connection_string, container_name=container_name)
blob_list = container.list_blobs()
if blob_list:
for blob in blob_list:
blob_client = blob_service_client.get_blob_client(
container=container_name, blob=blob.name)
streamdownloader = blob_client.download_blob()
file_content = json.loads(streamdownloader.readall())
if file_content:
for col in file_content:
logging.info(
'Attempting {mssql} SQL Server connection...'.format(mssql=SQL_SERVER))
cnxn = pyodbc.connect('DRIVER='+DRIVER+';SERVER='+SQL_SERVER +
';PORT=1433;DATABASE='+SQL_DB+';UID='+USERNAME+';PWD=' + PASSWORD)
if cnxn:
cursor = cnxn.cursor()
cursor.execute("""INSERT INTO dbo.rss_feeds (RSS_Filename, RSS_Title, RSS_Link, RSS_Description)
SELECT ?,?,?,?""", blob.name, col['title'], col['link'], col['description'])
cursor.commit()
else:
logging.warning(
'Could not establish connection to ''{mssql}'' server.'.format(mssql=SQL_SERVER))
else:
logging.warning(
'No data found in file ''{file}''.'.format(file=blob.name))
Finally, after function’s first invocation we can query the rss_feeds table to ensure the data has been extracted successfully (click on image to enlarge).
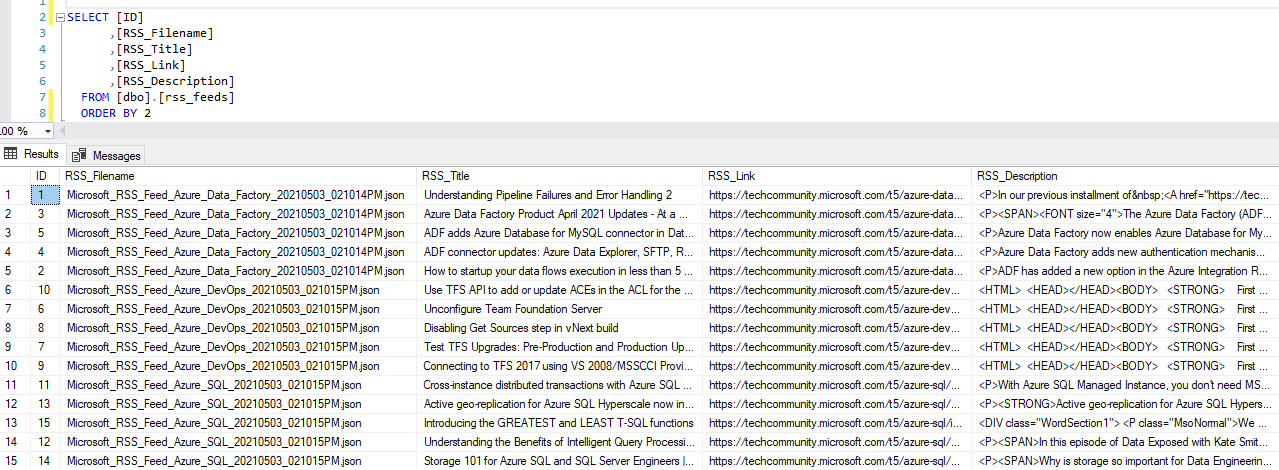
While I have not developed a dedicated logic to handle files which were already read from, one can easily archive those into a separate blob container or delete them altogether. Likewise, the first Python snippet of code responsible for JSON file creation can be easily tuned into a function itself thus fully automating the process lifecycle. As you can see, there are many different ways in which robust pipelines can be provisioned, even going as far as using orchestrator function (part of durable functions) to manage state, checkpoints and restarts.
Conclusion
So there you go, a quick overview of some of the capabilities that Azure Functions provide without having to explicitly provision or manage infrastructure.
Azure also offers other integration and automation services which define inputs, actions, conditions, and outputs e.g. Web Jobs, Logic Apps etc. and sometimes it difficult to discern which one of those options is the right one for the given scenario. There are many factors to consider e.g. from development point of view, Azure Functions offer more control and fewer limitations when faced with complex scenarios due to its code-first development model (Logic Apps offer designer-first approach). However, Logic Apps offer better out-of-the-box connectivity with extensive suite of options, ranging from Azure Service to popular SaaS solutions. As Azure Functions do not have connectors, they rely on triggers and input and output bindings for Storage, Event Hubs, Service Bus, and Cosmos DB services. From my perspective, Logic Apps are better suited when building integration solutions due to the very extensive list of connectors that should reduce the time-to-market, and when rich visual tools to build and manage are preferred. On the flip side, Azure Functions are a better fit if you require or prefer to have all the power and flexibility of a robust programming language, or need more portability, and the available bindings and logging capabilities are sufficient.
Azure Functions is designed to accelerate the process of application development and make it quick and simple. Through Azure Functions serverless architecture, it is possible to stop worrying about all the infrastructure considerations, and just focus on creating and managing proper code defining triggers and events. The highlight of Azure Functions is that you can write the code in the easy-to-use web interfaces and build and debug them locally on your machine of choice. Additionally, the pay-per-execution model is a good way to build scalable, enterprise-grade applications and pipelines without having to pay upfront and oftentimes through the nose. For anything that can be modeled as an event or trigger e.g. processing individual files, HTTP-triggers, handling API calls, managing queue messages etc. Azure Functions offer a cheap (micro-pay), no-ops (fully managed), scalable compute option.
http://scuttle.org/bookmarks.php/pass?action=addThis entry was posted on Tuesday, May 11th, 2021 at 5:23 pm and is filed under Azure, Cloud Computing, SQL, SQL Server. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.



Ross Jenkins May 31st, 2021 at 1:58 pm
Great post man!