Kicking the tires on BigQuery – Google’s Serverless Enterprise Data Warehouse (Part 1)
Note: Part 2 can be found HERE.
Introduction
As traditional, on-premise hosted data warehouse solutions are increasingly becoming harder to scale and manage, a new breed of vendors and products is starting to emerge, one which can easily accommodate exponentially growing data volumes with little up-front cost and very little operational overhead. More and more do we get to see cash-strapped IT departments or startups being pushed by their VC overlords to provide immediate ROI, not being able to take time and build up their analytical capability following the old-fashion, waterfall trajectory. Instead, the famous Facebook mantra of “move fast and break things” is gradually becoming a standard to live up to, with cloud-first, pay-for-what-you-use, ops-free services making inroads or displacing/replacing ‘old guard’ technologies. Data warehousing domain has successfully avoided being dragged into the relentless push for optimisation and efficiency for a very long time, with many venerable vendors (IBM, Oracle, Teradata) resting on their laurels, sometimes for decades. However, with the advent of the cloud computing, new juggernauts emerged and Google’s BigQuery is slowly becoming synonymous with petabyte-scale, ops-free, ultra-scalable and extremely fast data warehouse service. And while BigQuery has not (yet) become the go-to platform for large volumes of data storage and processing, big organisations such as New York Times and Spotify decided to adopt it, bucking the industry trend of selecting existing cloud data warehouse incumbents e.g. AWS Redshift or Microsoft SQL DW.
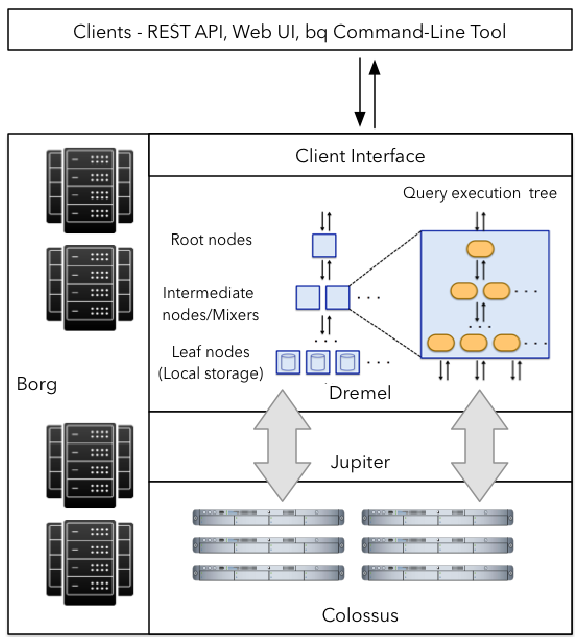
BigQuery traces its roots back to 2010, when Google released beta access to a new SQL processing system based on its distributed query engine technology, called Dremel, which was described in an influential paper released the same year. BigQuery and Dremel share the same underlying architecture and by incorporating columnar storage and tree architecture of Dremel, BigQuery manages to offer unprecedented performance. But, BigQuery is much more than Dremel which serves as the execution engine for the BigQuery. In fact, BigQuery service leverages Google’s innovative technologies like Borg – large-scale cluster management system, Colossus – Google’s latest generation distributed file system, Capacitor – columnar data storage format, and Jupiter – Google’s networking infrastructure. As illustrated below, a BigQuery client interact with Dremel engine via a client interface. Borg – Google’s large-scale cluster management system – allocates the compute capacity for the Dremel jobs. Dremel jobs read data from Google’s Colossus file systems using Jupiter network, perform various SQL operations and return results to the client.
Having previously worked with a number of other vendors which have successfully occupied this realm for a very long time, it was refreshing to see how different BigQuery is and what separates it from the rest of the competition. But before I get into the general observations and the actual conclusion, let’s look at how one can easily process, load and query large volumes of data (TPC-DS data in this example) using BigQuery and a few Python scripts for automation.
TPC-DS Schema Creation and Data Loading
BigQuery offers a number of ways one can interact with it and take advantage of its functionality. The most basic one is through the GCP Web UI but for repetitive tasks users will find themselves mainly utilising Google Cloud SDK or via Google BigQuery API. For the purpose of this example, I have generated two TPC-DS datasets – 100GB and 300GB – and staged them on the local machine’s folder. I have also created a TPC-DS schema JSON file which is used by the script to generate all dataset objects. All these resources, as well as the scripts used in this post can be found in my OneDrive folder HERE.
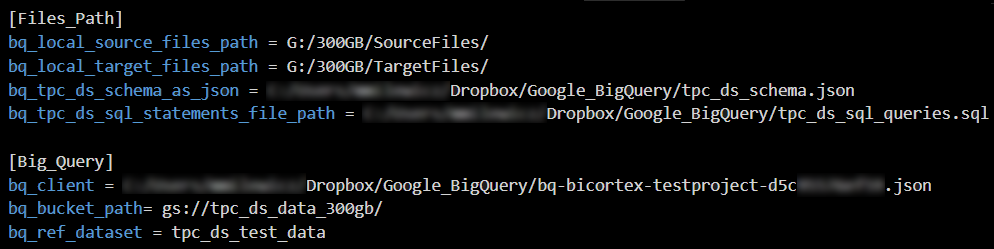
The following config file parameters and Python code are used to mainly clean up the flat files (TPC-DS delimits line ending with a “|” character which needs to be removed), break them up into smaller chunks and upload them to Google Cloud storage service (it assumes that gs://tpc_ds_data_100GB and gs://tpc_ds_data_300GB buckets has already been created). The schema structure used for this project is a direct translation of the PostgreSQL-specific TPC-DS schema used in one of my earlier projects where data types and their NULL-ability have been converted and standardized to conform to BigQuery standards.
import configparser
from tqdm import tqdm
from os import path, rename, listdir, remove, walk
from shutil import copy2, move
from google.cloud import storage
from csv import reader, writer
config = configparser.ConfigParser()
config.read("params.cfg")
bq_tpc_ds_schema_as_json = config.get(
"Files_Path", path.normpath("bq_tpc_ds_schema_as_json"))
bq_local_source_files_path = config.get(
"Files_Path", path.normpath("bq_local_source_files_path"))
bq_local_target_files_path = config.get(
"Files_Path", path.normpath("bq_local_target_files_path"))
storage_client = config.get("Big_Query", path.normpath("bq_client"))
bq_bucket_path = config.get("Big_Query", "bq_bucket_path")
bq_storage_client = storage.Client.from_service_account_json(storage_client)
keep_src_files = True
keep_headers = False
keep_src_csv_files = True
row_limit = 1000000
output_name_template = '_%s.csv'
delimiter = '|'
def RemoveFiles(DirPath):
filelist = [f for f in listdir(DirPath)]
for f in filelist:
remove(path.join(DirPath, f))
def SourceFilesRename(bq_local_source_files_path):
for file in listdir(bq_local_source_files_path):
if file.endswith(".dat"):
rename(path.join(bq_local_source_files_path, file),
path.join(bq_local_source_files_path, file[:-4]+'.csv'))
def SplitLargeFiles(file, row_count, bq_local_target_files_path, output_name_template, keep_headers=False):
"""
Split flat files into smaller chunks based on the comparison between row count
and 'row_limit' variable value. This creates file_row_count/row_limit number of files which can
facilitate upload speed if parallelized.
"""
file_handler = open(path.join(bq_local_target_files_path, file), 'r')
csv_reader = reader(file_handler, delimiter=delimiter)
current_piece = 1
current_out_path = path.join(bq_local_target_files_path, path.splitext(file)[
0]+output_name_template % current_piece)
current_out_writer = writer(
open(current_out_path, 'w', newline=''), delimiter=delimiter)
current_limit = row_limit
if keep_headers:
headers = next(csv_reader)
current_out_writer.writerow(headers)
pbar = tqdm(total=row_count)
for i, row in enumerate(csv_reader):
pbar.update()
if i + 1 > current_limit:
current_piece += 1
current_limit = row_limit * current_piece
current_out_path = path.join(bq_local_target_files_path, path.splitext(file)[
0]+output_name_template % current_piece)
current_out_writer = writer(
open(current_out_path, 'w', newline=''), delimiter=delimiter)
if keep_headers:
current_out_writer.writerow(headers)
current_out_writer.writerow(row)
pbar.close()
print("\n")
def ProcessLargeFiles(bq_local_source_files_path, bq_local_target_files_path, output_name_template, row_limit):
"""
Remove trailing '|' characters from the files generated by the TPC-DS utility
as they intefere with BQ load function. As BQ does not allow for denoting end-of-line
characters in the flat file, this breaks data load functionality. This function also calls
the 'SplitLargeFiles' function resulting in splitting files with the row count > 'row_limit'
variable value into smaller chunks/files.
"""
RemoveFiles(bq_local_target_files_path)
fileRowCounts = []
for file in listdir(bq_local_source_files_path):
if file.endswith(".csv"):
fileRowCounts.append([file, sum(1 for line in open(
path.join(bq_local_source_files_path, file), newline=''))])
for file in fileRowCounts:
if file[1] > row_limit:
print(
"Removing trailing characters in {f} file...".format(f=file[0]))
RemoveTrailingChar(row_limit, path.join(
bq_local_source_files_path, file[0]), path.join(bq_local_target_files_path, file[0]))
print("\nSplitting file:", file[0],)
print("Measured row count:", file[1])
print("Progress...")
SplitLargeFiles(
file[0], file[1], bq_local_target_files_path, output_name_template)
remove(path.join(bq_local_target_files_path, file[0]))
else:
print(
"Removing trailing characters in {f} file...".format(f=file[0]))
RemoveTrailingChar(row_limit, path.join(
bq_local_source_files_path, file[0]), path.join(bq_local_target_files_path, file[0]))
RemoveFiles(bq_local_source_files_path)
def RemoveTrailingChar(row_limit, bq_local_source_files_path, bq_local_target_files_path):
"""
Remove trailing '|' characters from files' line ending.
"""
line_numer = row_limit
lines = []
with open(bq_local_source_files_path, "r") as r, open(bq_local_target_files_path, "w") as w:
for line in r:
if line.endswith('|\n'):
lines.append(line[:-2]+"\n")
if len(lines) == line_numer:
w.writelines(lines)
lines = []
w.writelines(lines)
def GcsUploadBlob(bq_storage_client, bq_local_target_files_path, bq_bucket_path):
"""
Upload files into the nominated GCP bucket if it does not exists.
"""
bucket_name = (bq_bucket_path.split("//"))[1].split("/")[0]
CHUNK_SIZE = 10485760
bucket = bq_storage_client.get_bucket(bucket_name)
print("\nCommencing files upload...")
for file in listdir(bq_local_target_files_path):
try:
blob = bucket.blob(file, chunk_size=CHUNK_SIZE)
file_exist = storage.Blob(bucket=bucket, name=file).exists(
bq_storage_client)
if not file_exist:
print("Uploading file {fname} into {bname} GCP bucket...".format(
fname=file, bname=bucket_name))
blob.upload_from_filename(
path.join(bq_local_target_files_path, file))
else:
print("Nominated file {fname} already exists in {bname} bucket. Moving on...".format(
fname=file, bname=bucket_name))
except Exception as e:
print(e)
if __name__ == "__main__":
SourceFilesRename(bq_local_source_files_path)
ProcessLargeFiles(bq_local_source_files_path,
bq_local_target_files_path, output_name_template, row_limit)
GcsUploadBlob(bq_storage_client,
bq_local_target_files_path, bq_bucket_path)
Once all the TPC-DS data has been moved across into GCP storage bucket, we can proceed with creating BigQuery dataset (synonymous with the schema name in a typical Microsoft SQL Server or PostgreSQL RDBMS hierarchy) and its corresponding tables. Dataset is associated with a project which forms the overarching container, somewhat equivalent to the database if you come from a traditional RDBMS experience. It is also worth pointing out that dataset names must be unique per project, all tables referenced in a query must be stored in datasets in the same location and finally, geographic location can be set at creation time only. The following is an excerpt from the JSON file used to create the dataset schema which can be downloaded from my OneDrive folder HERE.
{
"table_schema": [
{
"table_name": "dbgen_version",
"fields": [
{
"name": "dv_version",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "dv_create_date",
"type": "DATE",
"mode": "NULLABLE"
},
{
"name": "dv_create_time",
"type": "TIME",
"mode": "NULLABLE"
},
{
"name": "dv_cmdline_args",
"type": "STRING",
"mode": "NULLABLE"
}
]
}
]
}
Now that the dataset is in place, we can create the required tables and populate them with the flat files data which was moved across into Google cloud storage using the previous code snippet. The following Python script creates tpc_ds_test_data dataset, creates all tables based on the TPC-DS schema stored in the JSON file and finally populates them with text files data.
from google.cloud import bigquery
from google.cloud.exceptions import NotFound
from google.cloud import storage
from os import path
import configparser
import json
import re
config = configparser.ConfigParser()
config.read("params.cfg")
bq_tpc_ds_schema_as_json = config.get(
"Files_Path", path.normpath("bq_tpc_ds_schema_as_json"))
bq_client = config.get("Big_Query", path.normpath("bq_client"))
bq_client = bigquery.Client.from_service_account_json(bq_client)
storage_client = config.get("Big_Query", path.normpath("bq_client"))
bq_bucket_path = config.get("Big_Query", "bq_bucket_path")
bq_storage_client = storage.Client.from_service_account_json(storage_client)
bq_ref_dataset = config.get("Big_Query", "bq_ref_dataset")
def dataset_bq_exists(bq_client, bq_ref_dataset):
try:
bq_client.get_dataset(bq_ref_dataset)
return True
except NotFound as e:
return False
def bq_create_dataset(bq_client, bq_ref_dataset):
"""
Create BigQuery dataset if it does not exists in the
Australian location
"""
if not dataset_bq_exists(bq_client, bq_ref_dataset):
print("Creating {d} dataset...".format(d=bq_ref_dataset))
dataset = bq_client.dataset(bq_ref_dataset)
dataset = bigquery.Dataset(dataset)
dataset.location = 'australia-southeast1'
dataset = bq_client.create_dataset(dataset)
else:
print("Nominated dataset already exists. Moving on...")
def table_bq_exists(bq_client, ref_table):
try:
bq_client.get_table(ref_table)
return True
except NotFound as e:
return False
def bq_drop_create_table(bq_client, bq_ref_dataset, bq_tpc_ds_schema_as_json):
"""
Drop (if exists) and create schema tables on the nominated BigQuery dataset.
Schema details are stored inside 'tpc_ds_schema.json' file.
"""
dataset = bq_client.dataset(bq_ref_dataset)
with open(bq_tpc_ds_schema_as_json) as schema_file:
data = json.load(schema_file)
for t in data['table_schema']:
table_name = t['table_name']
ref_table = dataset.table(t['table_name'])
table = bigquery.Table(ref_table)
if table_bq_exists(bq_client, ref_table):
print("Table '{tname}' already exists in the '{dname}' dataset. Dropping table '{tname}'...".format(
tname=table_name, dname=bq_ref_dataset))
bq_client.delete_table(table)
for f in t['fields']:
table.schema += (
bigquery.SchemaField(f['name'], f['type'], mode=f['mode']),)
print("Creating table {tname} in the '{dname}' dataset...".format(
tname=table_name, dname=bq_ref_dataset))
table = bq_client.create_table(table)
def bq_load_data_from_file(bq_client, bq_ref_dataset, bq_bucket_path, bq_storage_client):
"""
Load data stored on the nominated GCP bucket into dataset tables
"""
bucket_name = (bq_bucket_path.split("//"))[1].split("/")[0]
bucket = bq_storage_client.get_bucket(bucket_name)
blobs = bucket.list_blobs()
dataset = bq_client.dataset(bq_ref_dataset)
for blob in blobs:
file_name = blob.name
rem_char = re.findall("_\d+", file_name)
if len(rem_char) == 0:
ref_table = dataset.table(file_name[:file_name.index(".")])
table_name = file_name[:file_name.index(".")]
else:
rem_char = str("".join(rem_char))
ref_table = dataset.table(file_name[:file_name.index(rem_char)])
table_name = file_name[:file_name.index(rem_char)]
print("Loading file {f} into {t} table...".format(
f=file_name, t=table_name))
job_config = bigquery.LoadJobConfig()
job_config.source_format = "CSV"
job_config.skip_leading_rows = 0
job_config.field_delimiter = "|"
job_config.write_disposition = bigquery.WriteDisposition.WRITE_APPEND
job = bq_client.load_table_from_uri(
path.join(bq_bucket_path, file_name), ref_table, job_config=job_config)
result = job.result()
print(result.state)
if __name__ == "__main__":
bq_create_dataset(bq_client, bq_ref_dataset)
bq_drop_create_table(bq_client, bq_ref_dataset, bq_tpc_ds_schema_as_json)
bq_load_data_from_file(bq_client, bq_ref_dataset,
bq_bucket_path, bq_storage_client)
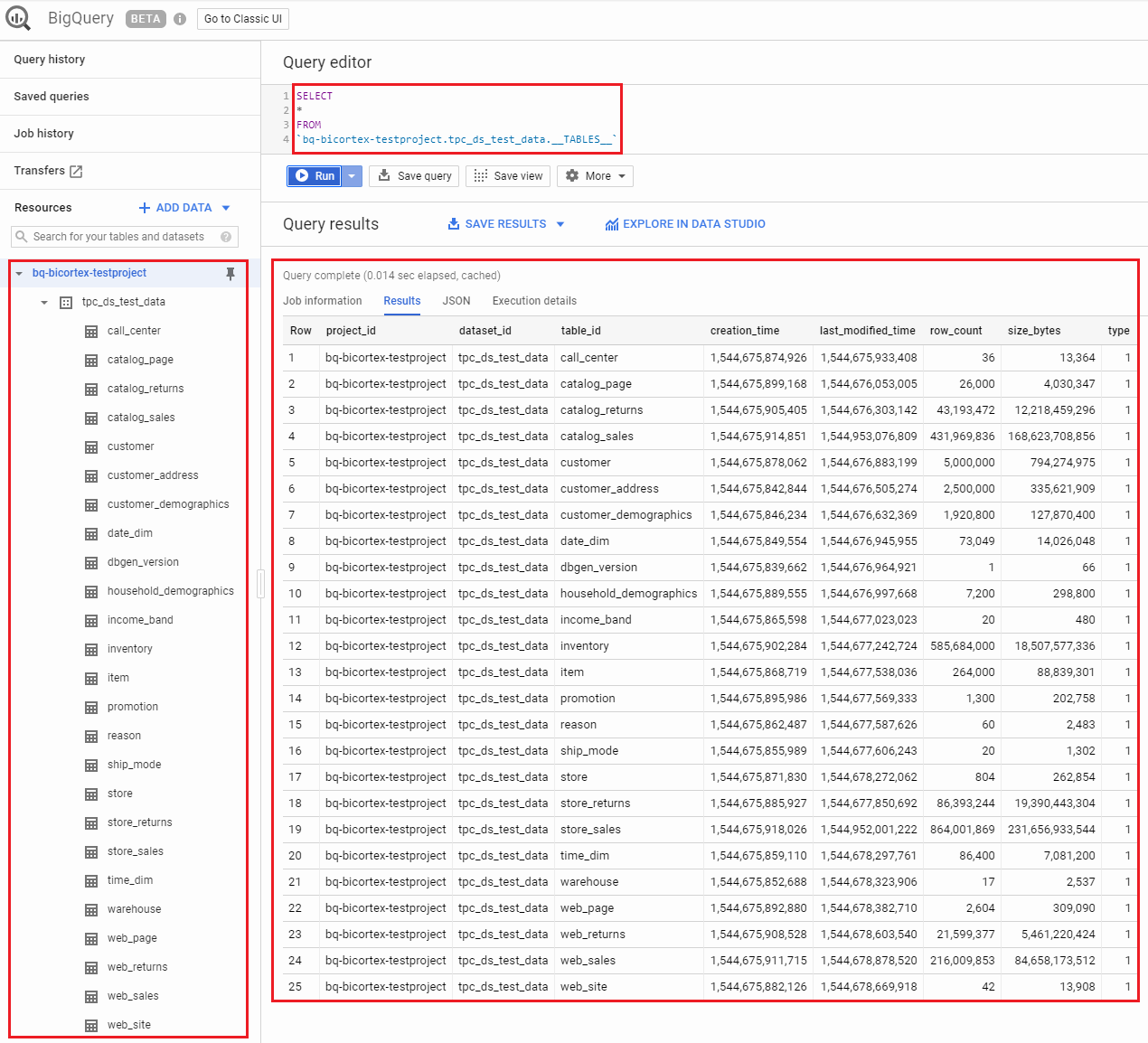
BigQuery offers some special tables whose contents represent metadata, such as the list of tables and views in a dataset. To confirm all objects have been created in the correct dataset, we can interrogate the __TABLES__ or __TABLES_SUMMARY__ meta-tables as per the query below.
In the next post I will go over some of TPC-DS queries execution performance on BigQuery, BigQuery ML – Google’s take on in-database machine learning as well as some basic interactive dashboard building in Tableau.
http://scuttle.org/bookmarks.php/pass?action=addThis entry was posted on Friday, September 21st, 2018 at 2:36 am and is filed under Cloud Computing, Programming. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.



Never thought Polybase could be used in this capacity and don't think Microsoft advertised this feature (off-loading DB data as…