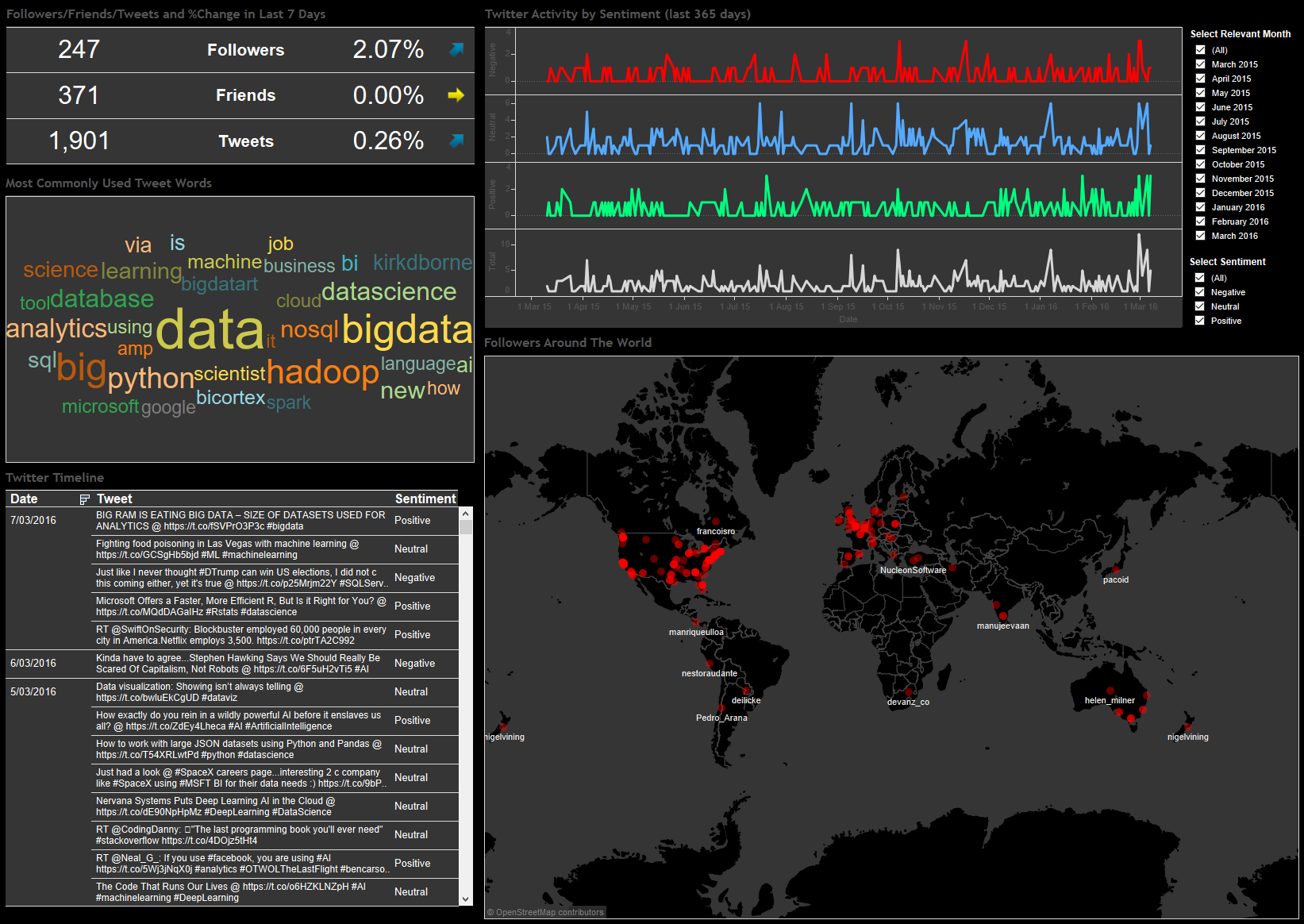
Using Python and Tableau to Scrape and Visualize Twitter User Data
March 8th, 2016 / No Comments » / by admin
Note: all the code and additional files for this post can be downloaded from my OneDrive folder HERE.
Introduction
What can I say…I like Twitter and I use it often to get interesting content links on data-related topics and find out what other people I follow are sharing. I covered Twitter-related stuff (sentiment analysis, Twitter timeline harvesting etc.) a number of times in the past, mainly HERE, HERE and HERE but since Twitter data is so rich and easy to work with (their API is pretty straightforward, especially coupled with Python wrappers such as Twython) and I have never gone down the path of visualising my findings I thought it would be a good idea to slap together a simple dashboard depicting some of the scraped data. To make it more fun and to make the dashboard look more polished I also analysed the sentiment of each tweet and geocoded my followers resulting in the Tableau dashboard as per below (click on image to expand).
In order to access Twitter data through a Python script first we will need to register a new Twitter app and download necessary Python libraries (assuming you already have Python installed). Registering the app can be done HERE, where upon filling out some details you should be issued with an API Key (Consumer Key) and API Secret (Consumer Secret). For this demo I will be authenticating into Twitter using OAuth2 i.e. application authentication. With application-only authentication you don’t have the context of an authenticated user and this means that any request to API for endpoints that require user context, such as posting tweets, will not work. However, the set of endpoints that will still be available can have a higher rate limit thus allowing for more frequent querying and data acquisitions (you can find more details on how app authentication works HERE). The API keys are stored in a configuration file, in this case called ‘params.cfg’, which is stored in the same directory as our SQLite database and Python script file. When it comes to Python libraries required, I have chosen the following for this demo, some of which go beyond ‘batteries included’ Python mantra so a quick ‘pip install…’ should do the job:
- Twython – Python wrapper for Twitter API
- Configparser – Python configuration file (storing API Secret and API Key values) parser
- Sqlite3 – relational database for data storage
- Requests – HTTP library (here used for sentiment querying)
- NLTK – natural language/text processing library
- tqdm – terminal progress meter
- Geopy – Python library for popular geocoding services
Python Code
Let’s go through the code (full script as well as all other files can be downloaded from my OneDrive folder HERE) and break it down into logical sections describing different functions. For this demo I wanted my script to do the following:
- Create SQLite database if it does not exist with all the underlying schema for storing user timeline, followers geo-located details and most commonly used words
- Acquire selected user timeline tweets (maximum number allowed by Twitter at this time is 3200) and insert them into the database table
- Assign sentiment value i.e. positive, negative or neutral by querying THIS API (maximum number of API calls allowed is 45,000/month) and update the table storing user timeline tweets with the returned values
- Using NLTK, ‘clean up’ tweets e.g. removing stop words, lemmitize words etc., remove some unwanted characters and hyper links and finally insert the most commonly occurring words into a table
- Acquire user followers’ data and where possible geocode their location using MapQuest API
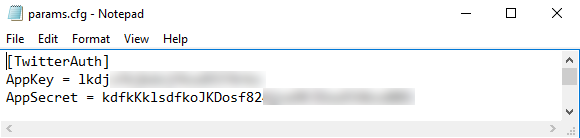
To do all this, firstly, let’s create our configuration file called ‘params.cfg’ which will store our API keys. Given that most commercially available APIs for sentiment analysis or geocoding are not free or at the very least require you to sign up to make the API key available, this would also be a good place to store those. For this demo we will be using free services so the only values saved in the config file are the secret key and consumer key as per below.
Now we can start building up our script, importing necessary Python modules, declaring variables and their values and referencing our configuration file data as per the snippet below (the highlighted line needs to be populated with the user name referencing the account timeline we’re trying to scrape).
#import relevant libraries and set up variables' values
import twython
import configparser
import sqlite3
import os
import platform
import re
import requests
import sys
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
import time
from collections import Counter
from tqdm import tqdm
from geopy.geocoders import GoogleV3
from geopy.exc import GeocoderQuotaExceeded
MaxTweetsAPI = 3200
StatusesCount = 200
WordCloudTweetNo = 40
IncludeRts = 1
ExcludeReplies = 0
SkipStatus = 1
ScreenName = 'user twitter handle' #e.g. @bicortex
SentimentURL = 'http://text-processing.com/api/sentiment/'
config = configparser.ConfigParser()
config.read('params.cfg')
AppKey = config.get('TwitterAuth','AppKey')
AppSecret = config.get('TwitterAuth','AppSecret')
Next, let’s set up our SQLite database and its schema. Depending on whether I’m at work or using my home computer I tend to move between Windows and Linux so you may want to adjust the first IF/ELSE statement to reflect your environment path and system (highlighted sections).
#Set up database objects' schema
if platform.system() == 'Windows':
db_location = os.path.normpath('Your_Windows_Directory_Path/twitterDB.db') #e.g. 'C:/Twitter_Scraping_Project/twitterDB.db'
else:
db_location = r'/Your_Linux_Directory_Path/twitterDB.db' #e.g. '/home/username/Twitter_Scraping_Project/twitterDB.db'
objectsCreate = {'UserTimeline':
'CREATE TABLE IF NOT EXISTS UserTimeline ('
'user_id int, '
'user_name text, '
'screen_name text, '
'user_description text, '
'user_location text, '
'user_url text, '
'user_created_datetime text,'
'user_language text ,'
'user_timezone text, '
'user_utc_offset real,'
'user_friends_count real,'
'user_followers_count real,'
'user_statuses_count real,'
'tweet_id int,'
'tweet_id_str text,'
'tweet_text text,'
'tweet_created_timestamp text,'
'tweet_probability_sentiment_positive real,'
'tweet_probability_sentiment_neutral real,'
'tweet_probability_sentiment_negative real,'
'tweet_sentiment text, '
'PRIMARY KEY(tweet_id, user_id))',
'FollowersGeoData':
'CREATE TABLE IF NOT EXISTS FollowersGeoData ('
'follower_id int,'
'follower_name text,'
'follower_location text,'
'location_latitude real,'
'location_longitude real,'
'PRIMARY KEY (follower_id))',
'WordsCount':
'CREATE TABLE IF NOT EXISTS WordsCount ('
'word text,'
'frequency int)'}
#create database file and schema using the scripts above
db_is_new = not os.path.exists(db_location)
with sqlite3.connect(db_location) as conn:
if db_is_new:
print("Creating database schema on " + db_location + " database...\n")
for t in objectsCreate.items():
try:
conn.executescript(t[1])
except sqlite3.OperationalError as e:
print (e)
conn.rollback()
sys.exit(1)
else:
conn.commit()
else:
print('Database already exists, bailing out...')
UserTimelineIDs = []
cur = 'SELECT DISTINCT tweet_ID from UserTimeline'
data = conn.execute(cur).fetchall()
for u in data:
UserTimelineIDs.extend(u)
UserFollowerIDs = []
cur = 'SELECT DISTINCT follower_id from FollowersGeoData'
data = conn.execute(cur).fetchall()
for f in data:
UserFollowerIDs.extend(f)
Next, we will define a simple function to check for Twitter API rate limit. Twitter limits the number of calls we can make to a specific API endpoint e.g. at the time of writing this post user timeline endpoint has a limit of 300 calls in a 15 minutes window when using with the application authentication and 180 calls when used with the user authentication. To allow our script to continue without Twython complaining of us exceeding the allowed threshold we want to make sure that once we reach this rate limit, the script will pause the execution for a predefined amount of time. Twitter’s ‘application/rate_limit_status’ API endpoint provides us with rate limits defined for each endpoint, the remaining number of calls available as well as the expiration time in epoch time. Using those three values we can allow for the script to sleep until the reset windows has been reset and resume scraping without completely stopping the process. Interestingly enough, ‘application/rate_limit_status’ API endpoint is also rate-limited to 180 calls/15 minute window so you will notice ‘appstatus’ variable also keeping this threshold in check.
#check Twitter API calls limit and pause execution to reset the limit if required
def checkRateLimit(limittypecheck):
appstatus = {'remaining':1}
while True:
if appstatus['remaining'] > 0:
twitter = twython.Twython(AppKey, AppSecret, oauth_version=2)
ACCESS_TOKEN = twitter.obtain_access_token()
twitter = twython.Twython(AppKey, access_token=ACCESS_TOKEN)
status = twitter.get_application_rate_limit_status(resources = ['statuses', 'application', 'followers'])
appstatus = status['resources']['application']['/application/rate_limit_status']
if limittypecheck=='usertimeline':
usertimelinestatus = status['resources']['statuses']['/statuses/user_timeline']
if usertimelinestatus['remaining'] == 0:
wait = max(usertimelinestatus['reset'] - time.time(), 0) + 1 # addding 1 second pad
time.sleep(wait)
else:
return
if limittypecheck=='followers':
userfollowersstatus = status['resources']['followers']['/followers/list']
if userfollowersstatus['remaining'] == 0:
wait = max(userfollowersstatus['reset'] - time.time(), 0) + 1 # addding 1 second pad
time.sleep(wait)
else:
return
else :
wait = max(appstatus['reset'] - time.time(), 0) + 1
time.sleep(wait)
Now that we have the above function in place we can start scraping Twitter feeds for particular user. The below function queries ‘get_user_timeline’ endpoint for a range of timeline attributes, most important being ‘text’ – the actual tweet string. As Twitter returns a single page of data with the number of tweets defined by the ‘StatusesCount’ variable and we require either the total count of tweets or 3200 of them if the user whose timeline we’re querying has posted more than the 3200 statuses rate limit, we will need to implement paging mechanism. By means of using an API parameter called ‘max_id’ which returns the results with an ID less than (that is, older than) or equal to the specified ID we can create a cursor to iterate through multiple pages, eventually getting to the total tweet count or the 3200 rate limit (whichever’s lower). Finally, we insert all tweets and corresponding attributes into the database.
#grab user timeline twitter feed for the profile selected and store them in a table
def getUserTimelineFeeds(StatusesCount, MaxTweetsAPI, ScreenName, IncludeRts, ExcludeReplies, AppKey, AppSecret):
#Pass Twitter API and database credentials/config parameters
twitter = twython.Twython(AppKey, AppSecret, oauth_version=2)
try:
ACCESS_TOKEN = twitter.obtain_access_token()
except twython.TwythonAuthError as e:
print (e)
sys.exit(1)
else:
try:
twitter = twython.Twython(AppKey, access_token=ACCESS_TOKEN)
print('Acquiring tweeter feed for user "{0}"...'.format(ScreenName))
params = {'count': StatusesCount, 'screen_name': ScreenName, 'include_rts': IncludeRts,'exclude_replies': ExcludeReplies}
AllTweets = []
checkRateLimit(limittypecheck='usertimeline')
NewTweets = twitter.get_user_timeline(**params)
if NewTweets is None:
print('No user timeline tweets found for "{0}" account, exiting now...'.format(ScreenName))
sys.exit()
else:
ProfileTotalTweets = [tweet['user']['statuses_count'] for tweet in NewTweets][0]
if ProfileTotalTweets > MaxTweetsAPI:
TweetsToProcess = MaxTweetsAPI
else:
TweetsToProcess = ProfileTotalTweets
oldest = NewTweets[0]['id']
progressbar = tqdm(total=TweetsToProcess, leave=1)
while len(NewTweets) > 0:
checkRateLimit(limittypecheck='usertimeline')
NewTweets = twitter.get_user_timeline(**params, max_id=oldest)
AllTweets.extend(NewTweets)
oldest = AllTweets[-1]['id'] - 1
if len(NewTweets)!=0:
progressbar.update(len(NewTweets))
progressbar.close()
AllTweets = [tweet for tweet in AllTweets if tweet['id'] not in UserTimelineIDs]
for tweet in AllTweets:
conn.execute("INSERT OR IGNORE INTO UserTimeline "
"(user_id,"
"user_name,"
"screen_name,"
"user_description,"
"user_location,"
"user_url,"
"user_created_datetime,"
"user_language,"
"user_timezone,"
"user_utc_offset,"
"user_friends_count,"
"user_followers_count,"
"user_statuses_count,"
"tweet_id,"
"tweet_id_str,"
"tweet_text,"
"tweet_created_timestamp) VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)",(
tweet['user']['id'],
tweet['user']['name'],
tweet['user']['screen_name'],
tweet['user']['description'],
tweet['user']['location'],
tweet['user']['url'],
time.strftime('%Y-%m-%d %H:%M:%S', time.strptime(tweet['user']['created_at'],'%a %b %d %H:%M:%S +0000 %Y')),
tweet['user']['lang'],
tweet['user']['time_zone'],
tweet['user']['utc_offset'],
tweet['user']['friends_count'],
tweet['user']['followers_count'],
tweet['user']['statuses_count'],
tweet['id'],
tweet['id_str'],
str(tweet['text'].replace("\n","")),
time.strftime('%Y-%m-%d %H:%M:%S', time.strptime(tweet['created_at'],'%a %b %d %H:%M:%S +0000 %Y'))))
conn.commit()
except Exception as e:
print(e)
sys.exit(1)
Great! Now that we have the user timeline table populated we can proceed with assigning sentiment to each individual record. I used a free service which allows for 45,000 API calls a month. Since there are no batch POST requests available and every single record has to be queried individually we also exclude the ones which have already been assigned the sentiment. Also, the function below takes care of removing certain characters and hyper links as these can interfere with the classification process.
#assign sentiment to individual tweets
def getSentiment(SentimentURL):
cur = ''' SELECT tweet_id, tweet_text, count(*) as NoSentimentRecCount
FROM UserTimeline
WHERE tweet_sentiment IS NULL
GROUP BY tweet_id, tweet_text '''
data = conn.execute(cur).fetchone()
if data is None:
print('Sentiment already assigned to relevant records or table is empty, bailing out...')
else:
print('Assigning sentiment to selected tweets...')
data = conn.execute(cur)
payload = {'text':'tweet'}
for t in tqdm(data.fetchall(),leave=1):
id = t[0]
payload['text'] = t[1]
#concatnate if tweet is on multiple lines
payload['text'] = str(payload['text'].replace("\n", ""))
#remove http:// URL shortening links
payload['text'] = re.sub(r'http://[\w.]+/+[\w.]+', "", payload['text'], re.IGNORECASE)
#remove https:// URL shortening links
payload['text'] = re.sub(r'https://[\w.]+/+[\w.]+', "", payload['text'], re.IGNORECASE)
#remove certain characters
payload['text'] = re.sub('[@#\[\]\'"$.;{}~`<>:%&^*()-?_!,+=]', "", payload['text'])
#print(payload['text'])
try:
post=requests.post(SentimentURL, data=payload)
response = post.json()
conn.execute("UPDATE UserTimeline "
"SET tweet_probability_sentiment_positive = ?, "
"tweet_probability_sentiment_neutral = ?, "
"tweet_probability_sentiment_negative = ?, "
"tweet_sentiment = ? WHERE tweet_id = ?",
(response['probability']['neg'],
response['probability']['neutral'],
response['probability']['pos'],
response['label'], id))
conn.commit()
except Exception as e:
print (e)
sys.exit(1)
Next, we can look at the word count function. This code takes advantage of the NLTK library to tokenize the tweets, remove certain stop words, lemmatize the tweets, remove unwanted characters and finally work out the top counts for individual words. The output gets inserted into the separate table in the same database simply as the top occurring word and frequency attributes.
#get most commonly occurring (40) words in all stored tweets
def getWordCounts(WordCloudTweetNo):
print('Fetching the most commonly used {0} words in the "{1}" feed...'.format(WordCloudTweetNo, ScreenName))
cur = "DELETE FROM WordsCount;"
conn.execute(cur)
conn.commit()
cur = 'SELECT tweet_text FROM UserTimeline'
data = conn.execute(cur)
StopList = stopwords.words('english')
Lem = WordNetLemmatizer()
AllWords = ''
for w in tqdm(data.fetchall(),leave=1):
try:
#remove certain characters and strings
CleanWordList = re.sub(r'http://[\w.]+/+[\w.]+', "", w[0], re.IGNORECASE)
CleanWordList = re.sub(r'https://[\w.]+/+[\w.]+', "", CleanWordList, re.IGNORECASE)
CleanWordList = re.sub(r'[@#\[\]\'"$.;{}~`<>:%&^*()-?_!,+=]', "", CleanWordList)
#tokenize and convert to lower case
CleanWordList = [words.lower() for words in word_tokenize(CleanWordList) if words not in StopList]
#lemmatize words
CleanWordList = [Lem.lemmatize(word) for word in CleanWordList]
#join words
CleanWordList =' '.join(CleanWordList)
AllWords += CleanWordList
except Exception as e:
print (e)
sys.exit(e)
if AllWords is not None:
words = [word for word in AllWords.split()]
c = Counter(words)
for word, count in c.most_common(WordCloudTweetNo):
conn.execute("INSERT INTO WordsCount (word, frequency) VALUES (?,?)", (word, count))
conn.commit()
Next, we will source the data on the user’s followers, again using the cursor to iterate through each page (excluding the ones who did not list their location), insert it into the database and finally geo-code their location using Google API which will attempt assigning latitude and longitude values where possible and update the database table accordingly. Caution though, since Google Geo API is limited to processing 2500 calls free of charge, if you have run up more than this limit of geo-located followers you may either want to pay to have this limit expanded or geocode the data in daily batches.
#geocode followers where geolocation data stored as part of followers' profiles
def GetFollowersGeoData(StatusesCount, ScreenName, SkipStatus, AppKey, AppSecret):
print('Acquiring followers for Twitter handle "{0}"...'.format(ScreenName))
twitter = twython.Twython(AppKey, AppSecret, oauth_version=2)
ACCESS_TOKEN = twitter.obtain_access_token()
twitter = twython.Twython(AppKey, access_token=ACCESS_TOKEN)
params = {'count': StatusesCount, 'screen_name': ScreenName, 'skip_status':1}
checkRateLimit(limittypecheck='usertimeline')
TotalFollowersCount = twitter.get_user_timeline(**params)
TotalFollowersCount = [tweet['user']['followers_count'] for tweet in TotalFollowersCount][0]
progressbar=tqdm(total=TotalFollowersCount, leave=1)
Cursor = -1
while Cursor != 0:
checkRateLimit(limittypecheck='followers')
NewGeoEnabledUsers = twitter.get_followers_list(**params, cursor=Cursor)
Cursor = NewGeoEnabledUsers['next_cursor']
progressbar.update(len(NewGeoEnabledUsers['users']))
NewGeoEnabledUsers = [[user['id'], user['screen_name'], user['location']] for user in NewGeoEnabledUsers['users'] if user['location'] != '']
#AllGeoEnabledUsers.extend(NewGeoEnabledUsers)
for user in NewGeoEnabledUsers:
if user[0] not in UserFollowerIDs:
conn.execute("INSERT OR IGNORE INTO FollowersGeoData ("
"follower_id,"
"follower_name,"
"follower_location)"
"VALUES (?,?,?)",
(user[0], user[1], user[2]))
conn.commit()
progressbar.close()
print('')
print('Geo-coding followers location where location variable provided in the user profile...')
geo = GoogleV3(timeout=5)
cur = 'SELECT follower_id, follower_location FROM FollowersGeoData WHERE location_latitude IS NULL OR location_longitude IS NULL'
data = conn.execute(cur)
for location in tqdm(data.fetchall(), leave=1):
try:
try:
followerid = location[0]
#print(location[1])
geoparams = geo.geocode(location[1])
except GeocoderQuotaExceeded as e:
print(e)
return
#print(geoparams)
else:
if geoparams is None:
pass
else:
latitude = geoparams.latitude
longitude = geoparams.longitude
conn.execute("UPDATE FollowersGeoData "
"SET location_latitude = ?,"
"location_longitude = ?"
"WHERE follower_id = ?",
(latitude,longitude,followerid))
conn.commit()
except Exception as e:
print("Error: geocode failed on input %s with message %s"%(location[2], e))
continue
Finally, running the ‘main’ function will execute the above in a sequential order, displaying progress bar for all API related calls as per below.
#run all functions
def main():
getUserTimelineFeeds(StatusesCount, MaxTweetsAPI, ScreenName, IncludeRts, ExcludeReplies, AppKey, AppSecret)
getSentiment(SentimentURL)
getWordCounts(WordCloudTweetNo)
GetFollowersGeoData(StatusesCount, ScreenName, SkipStatus, AppKey, AppSecret)
conn.close()
if __name__ == "__main__":
main()

Visualizing Data in Tableau
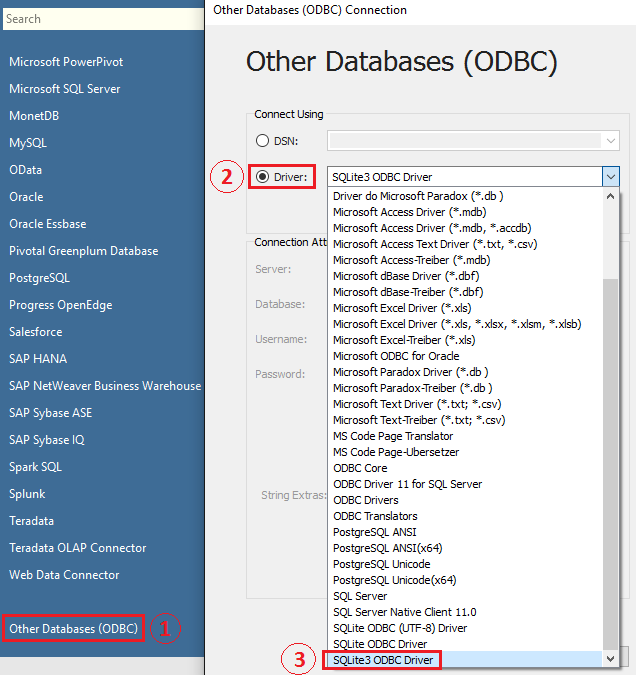
Now that we have our three database tables populated, let create a simple dashboard in Tableau. Since we implemented our data storage layer in SQLite, first we need to download SQLite driver to enable it to talk to Tableau. Once installed (I downloaded mine from HERE), you should able to select it from options available under ‘Other Databases (ODBC)’ data sources.
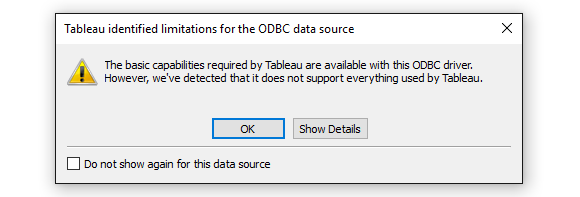
Once the connection has been established we can finally commence building out our dashboard but before we begin, a quick word of caution – if you want to turn this demo into a more robust solution, SQLite database back-end, even though good enough for this proof of concept, may not play well with Tableau. I came across a few issues with data types support and since SQLite has not been designed with a server/client architecture in mind, chances are that Tableau has a better out-of-the-box compatibility when coupled with RDBMSs which it natively supports e.g. MySQL, PostgeSQL, MSSQL etc. Below is a notification pop-up warning of the lack of support for some features when using SQLite ODBC connection.
Continuing on, in Tableau, I have created four different sheets, two of them pointing to the same data source (as they rely on the same UserTimeline table) and the remaining two pointing to two other tables i.e. WordsCount and FollowersGeoData. The SQL queries used are mostly just straightforward SELECT statements out of their respective tables, with the one driving followers/tweets/friends counts structured to account for changes captured in the last seven days as per the code below.
SELECT
friends_count as counts,
((friends_count - last_weeks_friends_count)/last_weeks_friends_count) as percentage_change, 'Friends' as category
FROM
(SELECT
MAX(user_friends_count) as friends_count,
MAX(user_followers_count) as followers_count,
MAX(user_statuses_count) as statuses_count,
(SELECT user_friends_count FROM UserTimeLine
WHERE tweet_created_timestamp < date('now','-7 days')
ORDER BY ROWID ASC LIMIT 1
) as last_weeks_friends_count,
(SELECT user_followers_count FROM UserTimeLine
WHERE tweet_created_timestamp < date('now','-7 days')
ORDER BY ROWID ASC LIMIT 1
) as last_weeks_followers_count,
(SELECT user_statuses_count FROM UserTimeLine
WHERE tweet_created_timestamp < date('now','-7 days')
ORDER BY ROWID ASC LIMIT 1
) as last_weeks_statuses_count
FROM UserTimeLine)
UNION ALL
SELECT
followers_count as counts,
((followers_count - last_weeks_followers_count)/last_weeks_followers_count) as percentage_change, 'Followers' as category
FROM
(SELECT
MAX(user_friends_count) as friends_count,
MAX(user_followers_count) as followers_count,
MAX(user_statuses_count) as statuses_count,
(SELECT user_friends_count FROM UserTimeLine
WHERE tweet_created_timestamp < date('now','-7 days')
ORDER BY ROWID ASC LIMIT 1
) as last_weeks_friends_count,
(SELECT user_followers_count FROM UserTimeLine
WHERE tweet_created_timestamp < date('now','-7 days')
ORDER BY ROWID ASC LIMIT 1
) as last_weeks_followers_count,
(SELECT user_statuses_count FROM UserTimeLine
WHERE tweet_created_timestamp < date('now','-7 days')
ORDER BY ROWID ASC LIMIT 1
) as last_weeks_statuses_count
FROM UserTimeLine) UNION ALL
SELECT
statuses_count as counts,
((statuses_count - last_weeks_statuses_count)/last_weeks_statuses_count) as percentage_change, 'Tweets' as category
FROM
(SELECT
MAX(user_friends_count) as friends_count,
MAX(user_followers_count) as followers_count,
MAX(user_statuses_count) as statuses_count,
(SELECT user_friends_count FROM UserTimeLine
WHERE tweet_created_timestamp < date('now','-7 days')
ORDER BY ROWID ASC LIMIT 1
) as last_weeks_friends_count,
(SELECT user_followers_count FROM UserTimeLine
WHERE tweet_created_timestamp < date('now','-7 days')
ORDER BY ROWID ASC LIMIT 1
) as last_weeks_followers_count,
(SELECT user_statuses_count FROM UserTimeLine
WHERE tweet_created_timestamp < date('now','-7 days')
ORDER BY ROWID ASC LIMIT 1
) as last_weeks_statuses_count
FROM UserTimeLine)
All there is left to do is to position each sheets’ visualisation on the dashboard and vuala…the complete dashboard looks like this (click on image to expand).
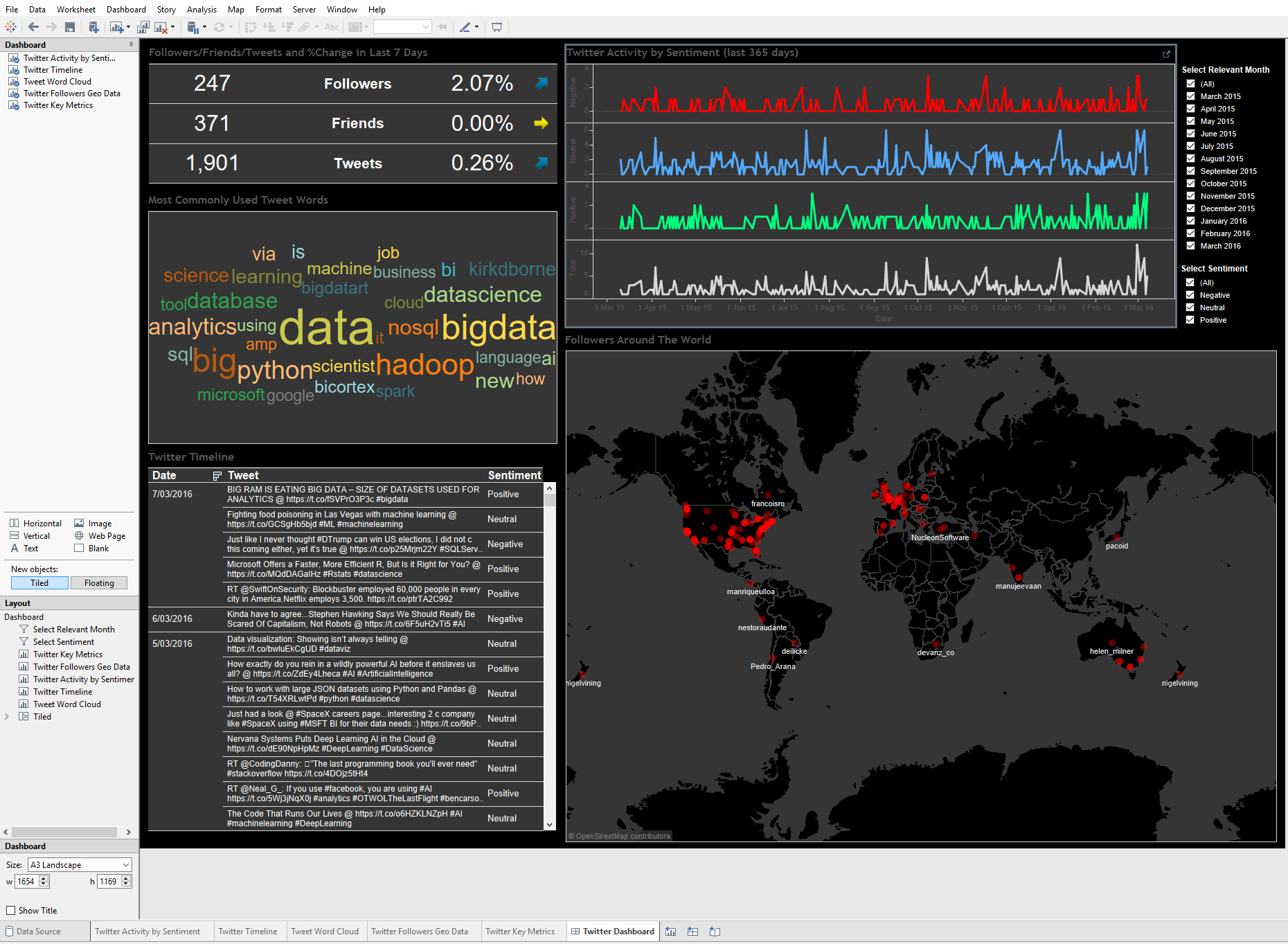
Again, all the code, database and Tableau solution files can be downloaded from my OneDrive folder HERE. Since I have removed the database connection details from all data sources, if you’re thinking of replicating this solution on your own machine, all you need to do is point each data source to SQLite database location as per the video below.
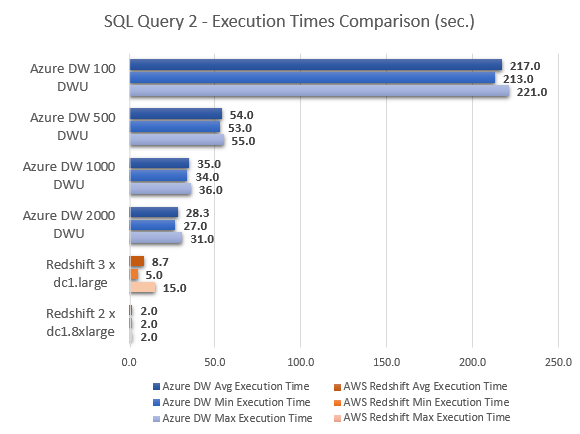
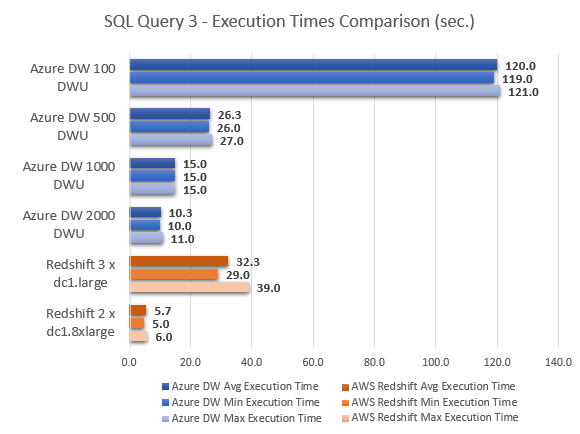
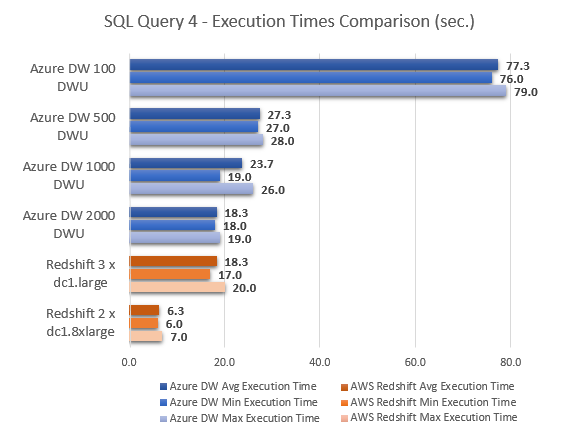
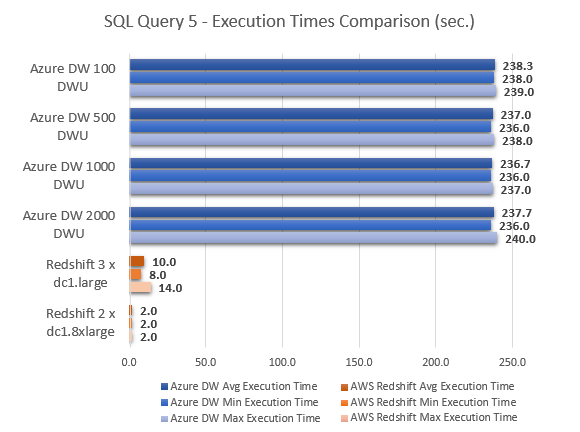
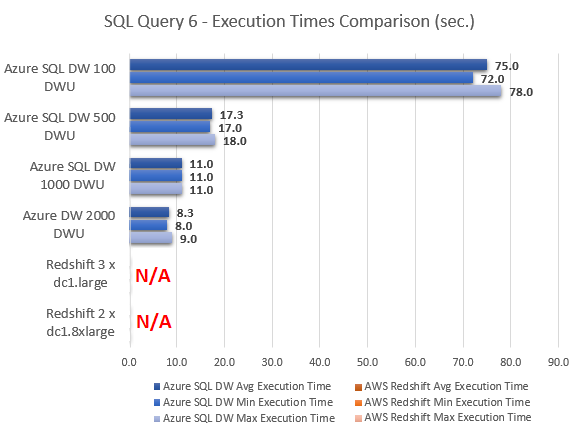
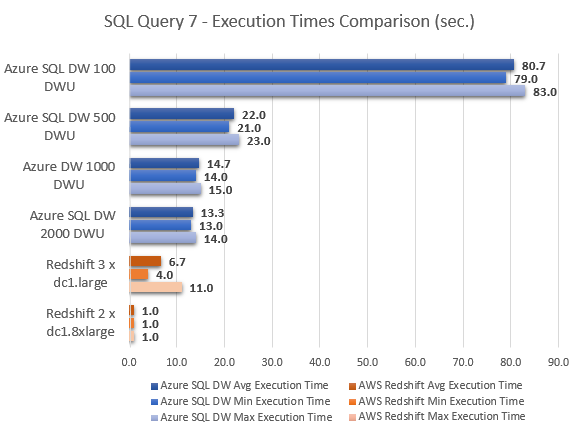
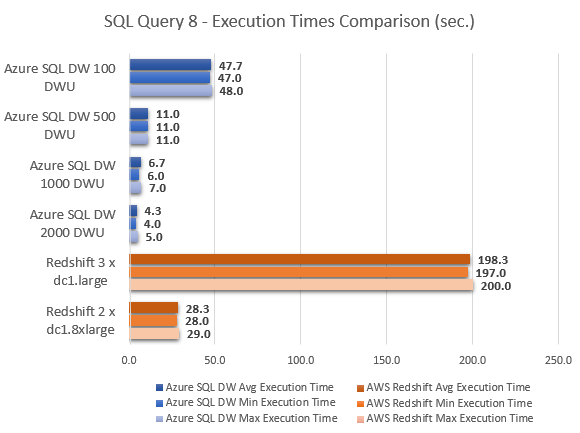
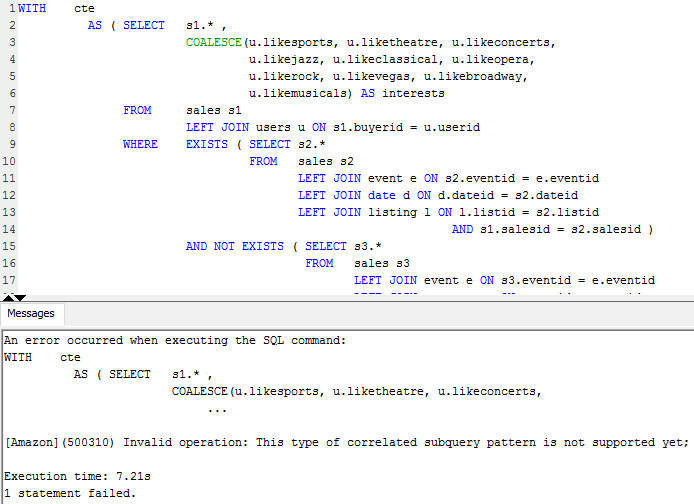






Never thought Polybase could be used in this capacity and don't think Microsoft advertised this feature (off-loading DB data as…