SQL Server to Snowflake Solution Architecture and Implementation – How to Extract, Ingest and Model Wide World Importers Database using Snowflake Platform
July 2nd, 2024 / 4 Comments » / by admin
Introduction
Lately, I’ve been on a hunt for a simple yet comprehensive solution architecture using SQL Server as a source platform and Snowflake as a data warehouse. In spite the fact Snowflake has the most active and probably well-funded marketing department of any DW vendors, finding end-to-end architecture implementation for a typical solution seemed more difficult compared to less nascent providers such as Microsoft or Oracle. There are a lot of fragmented posts on how an isolated problem could be solved or literature on how to assemble a high-level architecture but unfortunately not a lot of resources on building an end-to-end solution. Snowflake claims that how clients get their data into into Snowflake platform isn’t their primary concern and the extensive catalog of 3rd party vendors and partners they support is enough to build a simple ingestion POC (Proof of Concept) with ease. I guess that’s a fair point until you consider Microsoft, Oracle, IBM and other stalwarts of this industry already provide this functionality (either as a free add-on or a paid option) natively in their platforms. Yes, there are Fivetrans, Airbytes and NiFis of the integration world and dbt seems to be the go-to platform for any post-acquisition data munging, but sometimes I miss the days where one could build an entire data processing platform on a single vendor, with very few compromises. Time will tell if, for example, Microsoft Fabric fills this void but for those of us who are set on using Snowflake as their Data Warehouse platform, having a view of a sample solution showcasing the entire process would go a long way.
As a result, this post is intended to explain a full, end-to-end implementation of a WWI (Wide World Importers) to WWIDW (Wide World Importers Data Warehouse) solution, including ELT and integration code, SSIS packages, dimensional schema built, data reconciliation process and any infrastructure-related artifacts required to turn WWI database into the Snowflake equivalent of WWIDW database.
Why WWI database you ask? Well, there are many publicly available databases on the internet but not a lot of examples showcasing a set of good practices when it comes to building a fully-fledged analytics solution based on a star schema model design, with all the ELT pipelines and code available for download, for free. And while the core premise of WWI sample database was to showcases the latest database design features, tools and techniques in Microsoft SQL Server platform e.g. in-memory OLTP, system-versioned tables etc., both WWI and WWIDW databases’ schemas can be easily ported to any relational engine, making this solution a great candidate for a foundational learning platform. Another words, using WWI and WWIDW databases to build a simple OLTP to OLAP solution is a great way to demonstrate how an end-to-end integration and transformation pipelines could look like if we were starting carte blanche. Both database can be downloaded from Microsoft’s GitHub repo HERE.
Also, you will notice that the solution architecture assumes source data in staged on an on-premises SQL Server instance. This is because most small to medium business running a Microsoft shop still heavily rely on IaaS deployments. This may be contrary to what cloud providers are willing to tell you or what the general impression in high-tech hot spots like Silicon Valley may be, but in my experience, most cloud migrations are still lift-and-shift and even if public cloud is the eventual promise land, we’re not there yet.
Solution Architecture
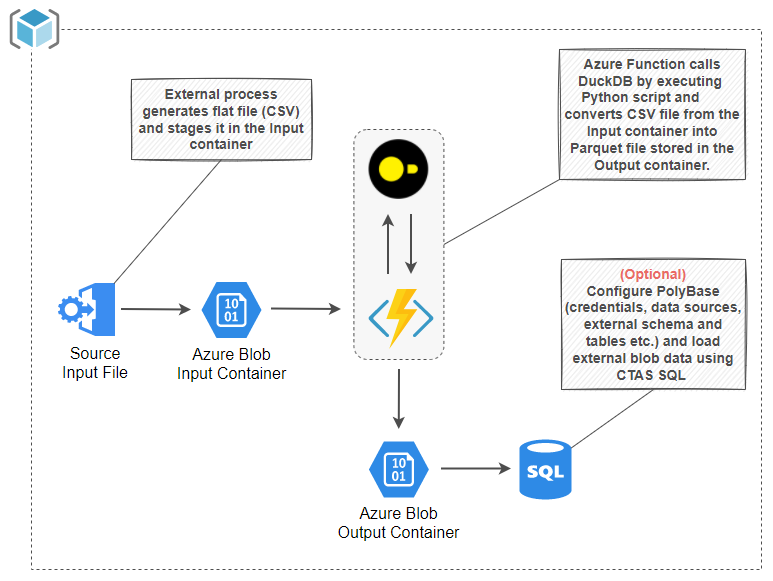
The following solution architecture depicts all stages of data ingestion and transformation process as further discussed in this post. As there are many different approaches to transforming WWI database (transactional view) to WWIDW database (analytics view), this solution (at least on the Snowflake side) was built with simplicity in mind – no Snowpark, no data catalogs, no MLOps or LLMs, just simple dimensional data model built on top of stage views. This is because, in my experience, most businesses initially struggle with the simplest tasks of getting data into Snowflake and structuring it in a way which facilitates reporting and analytics, which is what this architecture attempts to achieve in the simplest format (click on image to enlarge).
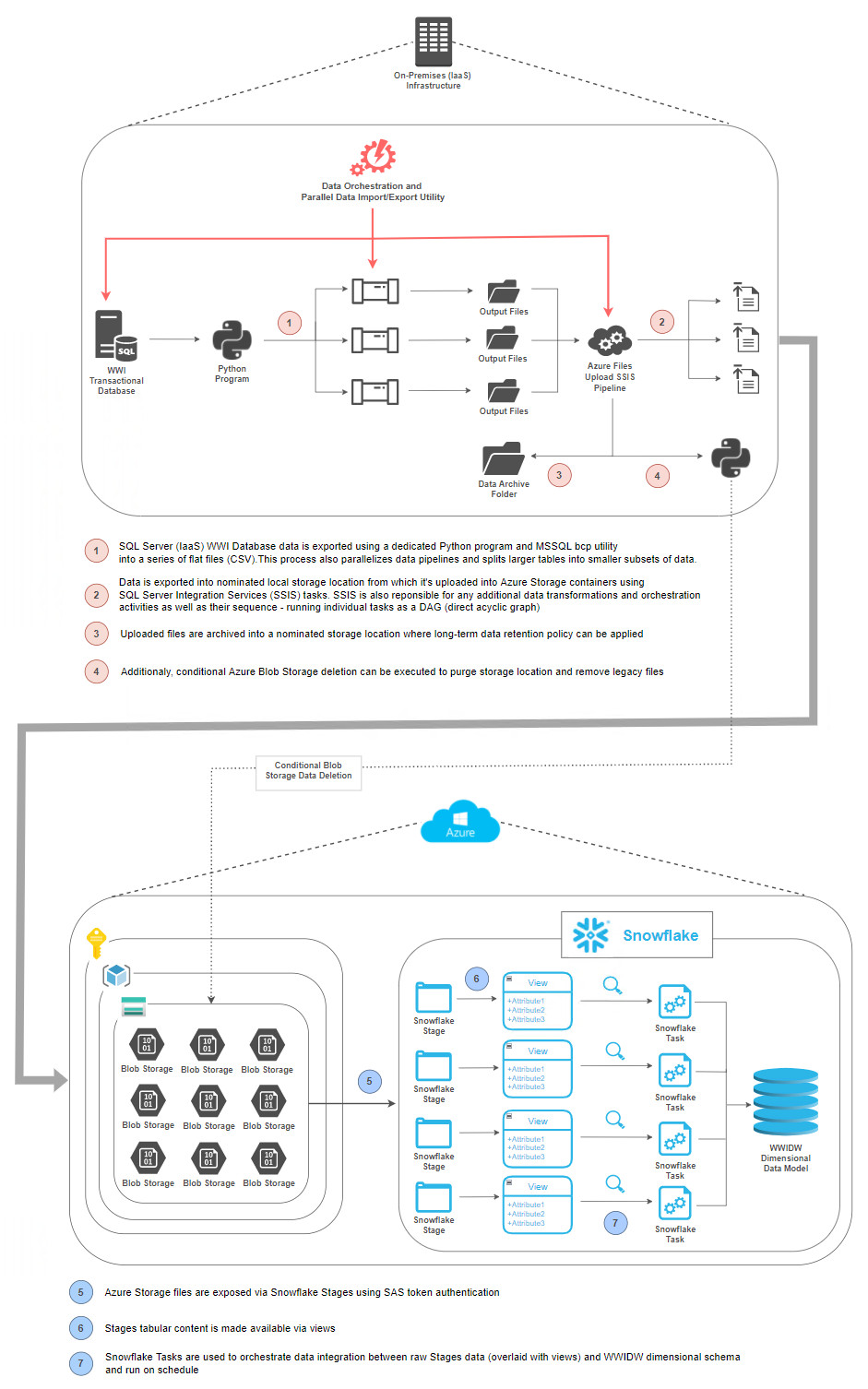
Assumptions
In order not to turn this post into a book-size manual, I made a few assumptions regarding the set-up and parts of the solution I will skip over as they have been documented by respective vendors in full extent e.g. how to restore WWI database onto an existing SQL Server deployment or how to create Snowflake account etc. To re-create this architecture in your own environment, the following artefacts are required in line with the above architecture depicting how data from WWI transactional database is ingested and transformed into a Snowflake equivalent of WWIDW database.
- WWI database restored on an existing or new SQL Server instance – it needs to be an on-premises (IaaS) deployment as we will require access to the underlying file system for staging flat files.
- Visual Studio installation (Community Edition is fine) in order to run SSIS package. In this scenario, the SSIS package is mostly responsible for orchestrating data extraction, however, Azure Blob upload is handled using Flexible File Task component.
- Azure Feature Pack for Integration Services installed with Visual Studio. SQL Server Integration Services (SSIS) Feature Pack for Azure is an extension that provides the components listed on this page for SSIS to connect to Azure services, transfer data between Azure and on-premises data sources, and process data stored in Azure. A copy of the latest version can be obtained from HERE.
- Python interpreter, along with the required Python libraries, installed on the same machine.
- Folder structure created in prescribed directories on the local file system.
- Microsoft Azure Storage account created to create the required containers and blobs.
- Snowflake trial account.
As a side note, as we go deeper into the nuts and bolts of this architecture, you will also notice that most of data extraction is done in Python. This is to enable future modifications and decoupling from SSIS (used mainly for Azure files upload activity). As such, most of this code can be run as a series of individual steps from the command line and alternative orchestration engines may be used as the SSIS replacement. Likewise, for the Snowflake part, most data engineers would be tempted to replace its native functionality of creating DAGs and schedules with alternative tools and services e.g. dbt, however, in the spirit of keeping it simple, Snowflake out-of-the-box functionality can easily accommodate these requirements.
Additionally, to simplify Snowflake development, only a portion of the WWIDW star schema will be generated in Snowflake. This includes Fact_Order table as well as the following dimension tables: Dim_Date, Dim_Customer, Dim_StockItem and Dim_Emplyee. Likewise, on the WWI database-end, this requires only the following tables’ data: cities, stateprovinces, countries, customers, buyinggroups, customercategories, people, orders, orderlines, packagetypes, stockitems and colors. I will not restrict the acquisition pipeline to these tables only but technically, only the aforementioned objects are required to construct Order dimensional data model in Snowflake.
Source Data Extraction and Azure ADLS Upload
Let’s begin the process with extracting WWI OLTP database information into a series of flat files before moving them into Azure ADLS containers. In order to create a repeatable and configurable process handling the “E” part of the ELT/ETL, I will first create a “metadata” table storing some key information describing our source datasets. This table will be refreshed every time data extraction process is executed to ensure our metadata is up-to-date and includes attributes such as object names, schema names, table size, row counts, primary key names, minimum and maximum values for primary keys and more. This metadata will also allow us to parallelize the extraction process in two ways:
- For tables nominated as large (in this context, any object with more than 1 million rows) we will be able to split their content into separate, discrete partitions which run in parallel and write to separate files.
- Every other table’s data extraction will be run in a separate process (using Python’s multiprocessing library), taking advantage of all available host cores and thus significantly increasing execution speed.
To populate the metadata table, the following stored procedure is created in the metadata schema on the WWI database.
USE [WideWorldImporters]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE OR ALTER PROCEDURE [metadata].[usp_create_tpcds_metadata]
(@Local_Database_Name NVARCHAR (256))
AS
BEGIN
SET NOCOUNT ON;
DROP TABLE IF EXISTS metadata.wwi_objects;
CREATE TABLE metadata.wwi_objects
(
[ID] [INT] IDENTITY(1, 1) NOT NULL,
[Application_Name] [VARCHAR](255) NOT NULL,
[Local_Object_Name] [VARCHAR](255) NOT NULL,
[Local_Schema_Name] [VARCHAR](55) NOT NULL,
[Local_DB_Name] [VARCHAR](255) NOT NULL,
[Tablesize_MB] [DECIMAL](18, 2) NOT NULL,
[Datasize_MB] [DECIMAL](18, 2) NOT NULL,
[Indexsize_MB] [DECIMAL](18, 2) NOT NULL,
[Is_Active] [BIT] NOT NULL,
[Is_Big] [BIT] NULL,
[Is_System_Versioned] BIT NOT NULL,
[ETL_Batch_No] [TINYINT] NULL,
[Rows_Count] BIGINT NULL,
[Min_PK_Value] BIGINT NULL,
[Max_PK_Value] BIGINT NULL,
[PK_Column_Name] VARCHAR(1024) NULL,
[Local_Primary_Key_Data_Type] VARCHAR (56) NULL
);
DECLARE @PageSize INT;
SELECT @PageSize = low / 1024.0
FROM master.dbo.spt_values
WHERE number = 1
AND type = 'E';
DECLARE @SQL NVARCHAR(MAX)
SET @SQL = '
INSERT INTO metadata.wwi_objects
(
[Application_Name],
[Local_DB_Name],
[Local_Schema_Name],
[Local_Object_Name],
[Tablesize_MB],
[Datasize_MB],
[Indexsize_MB],
[Is_Active],
[Is_Big],
[Is_System_Versioned],
[ETL_Batch_No],
[Rows_Count],
[Min_PK_Value],
[Max_PK_Value],
[PK_Column_Name],
[Local_Primary_Key_Data_Type]
)
SELECT ''WWI'' AS Application_Name,
'''+@Local_Database_Name+''' AS Local_DB_Name,
s.name AS Local_Schema_Name,
t.name AS Local_Object_Name,
CAST(ROUND(((SUM(a.used_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS Tablesize_MB,
CONVERT(NUMERIC(18, 2),
CONVERT(NUMERIC,
'+CAST(@PageSize AS VARCHAR(56))+' * SUM( a.used_pages - CASE
WHEN a.type <> 1 THEN
a.used_pages
WHEN p.index_id < 2 THEN
a.data_pages
ELSE
0
END
)
) / 1024
) AS Datasize_MB,
CONVERT(NUMERIC(18, 2),
CONVERT(NUMERIC(18, 3),
'+CAST(@PageSize AS VARCHAR(56))+' * SUM( CASE
WHEN a.type <> 1 THEN
a.used_pages
WHEN p.index_id < 2 THEN
a.data_pages
ELSE
0
END
)
) / 1024
) AS Indexsize_MB,
1 AS Is_Active,
NULL,
CASE WHEN t.temporal_type IN (1,2) THEN 1 ELSE 0 END,
NULL,
NULL,
NULL,
NULL,
NULL,
NULL
FROM '+@Local_Database_Name+'.sys.tables t
INNER JOIN '+@Local_Database_Name+'.sys.indexes i
ON t.object_id = i.object_id
INNER JOIN '+@Local_Database_Name+'.sys.partitions p
ON i.object_id = p.object_id
AND i.index_id = p.index_id
INNER JOIN '+@Local_Database_Name+'.sys.allocation_units a
ON p.partition_id = a.container_id
INNER JOIN '+@Local_Database_Name+'.sys.schemas s
ON t.schema_id = s.schema_id
WHERE t.is_ms_shipped = 0
AND i.object_id > 255 and t.temporal_type IN (0,2) AND t.name NOT IN (''wwi_objects'', ''SystemParameters'')
GROUP BY t.name,
s.name, t.temporal_type'
EXEC(@SQL)
SET @SQL = ''
SET @SQL = @SQL + 'WITH temp_local_data AS (SELECT * FROM (SELECT t.name as table_name, ss.name as schema_name, ' +CHAR(13)
SET @SQL = @SQL + 'c.name AS column_name, tp.name AS data_type,' +CHAR(13)
SET @SQL = @SQL + 'c.max_length AS character_maximum_length, CASE WHEN indx.object_id IS NULL ' +CHAR(13)
SET @SQL = @SQL + 'THEN 0 ELSE 1 END AS ''is_primary_key''' +CHAR(13)
SET @SQL = @SQL + 'FROM '+@Local_Database_Name+'.sys.tables t' +CHAR(13)
SET @SQL = @SQL + 'JOIN '+@Local_Database_Name+'.sys.columns c ON t.object_id = c.object_id ' +CHAR(13)
SET @SQL = @SQL + 'JOIN '+@Local_Database_Name+'.sys.types tp ON c.user_type_id = tp.user_type_id ' +CHAR(13)
SET @SQL = @SQL + 'JOIN '+@Local_Database_Name+'.sys.objects so ON so.object_id = t.object_id ' +CHAR(13)
SET @SQL = @SQL + 'JOIN '+@Local_Database_Name+'.sys.schemas ss ON so.schema_id = ss.schema_id ' +CHAR(13)
SET @SQL = @SQL + 'LEFT JOIN (SELECT ic.object_id, ic.column_id ' +CHAR(13)
SET @SQL = @SQL + 'FROM '+@Local_Database_Name+'.sys.indexes AS i ' +CHAR(13)
SET @SQL = @SQL + 'INNER JOIN '+@Local_Database_Name+'.sys.index_columns AS ic ON ' +CHAR(13)
SET @SQL = @SQL + 'i.OBJECT_ID = ic.OBJECT_ID AND i.index_id = ic.index_id ' +CHAR(13)
SET @SQL = @SQL + 'WHERE i.is_primary_key = 1) indx ON so.object_id = indx.object_id AND c.column_id = indx.column_id ' +CHAR(13)
SET @SQL = @SQL + 'WHERE t.type = ''u'' AND t.is_memory_optimized <> 1 AND tp.is_user_defined = 0)a)' +CHAR(13)
SET @SQL = @SQL + 'UPDATE metadata.wwi_objects SET PK_Column_Name = l.primary_keys,' +CHAR(13)
SET @SQL = @SQL + 'Local_Primary_Key_Data_Type = l.pk_data_type' +CHAR(13)
SET @SQL = @SQL + 'FROM metadata.wwi_objects t JOIN' +CHAR(13)
SET @SQL = @SQL + '(SELECT schema_name AS local_schema_name, table_name AS local_table_name, ' +CHAR(13)
SET @SQL = @SQL + 'STRING_AGG(column_name, '','') WITHIN GROUP (ORDER BY column_name ASC) AS primary_keys, ' +CHAR(13)
SET @SQL = @SQL + 'STRING_AGG(column_name + ''='' + data_type, '','') AS pk_data_type' +CHAR(13)
SET @SQL = @SQL + 'FROM temp_local_data WHERE is_primary_key = 1' +CHAR(13)
SET @SQL = @SQL + 'GROUP BY table_name, schema_name) l ' +CHAR(13)
SET @SQL = @SQL + 'ON t.Local_object_Name = l.local_table_name AND t.local_schema_name = l.local_schema_name' +CHAR(13)
EXEC(@SQL)
DECLARE @Table_Name VARCHAR(512);
DECLARE @Schema_Name VARCHAR(256);
DECLARE @Catalog_Name VARCHAR(256);
DECLARE @Primary_Key_Data_Type VARCHAR (1024);
DECLARE @Is_System_Versioned BIT;
IF CURSOR_STATUS('global', 'cur_db_object_output') >= -1
BEGIN
DEALLOCATE cur_db_object_output;
END;
DECLARE cur_db_object_output CURSOR FORWARD_ONLY FOR
SELECT DISTINCT
Local_Object_Name,
Local_Schema_Name,
Local_DB_Name,
Local_Primary_Key_Data_Type,
Is_System_Versioned
FROM WideWorldImporters.metadata.wwi_objects;
OPEN cur_db_object_output;
FETCH NEXT FROM cur_db_object_output
INTO @Table_Name,
@Schema_Name,
@Catalog_Name,
@Primary_Key_Data_Type,
@Is_System_Versioned;
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE @pk_collate VARCHAR(1024)
=
(
SELECT STRING_AGG(sql, ',')
FROM
(
SELECT CASE
WHEN RIGHT(value, CHARINDEX('=', REVERSE(value)) - 1) IN ( 'int', 'bigint', 'smallint',
'tinyint',
'uniqueidentifier',
'datetime', 'decimal'
) THEN
SUBSTRING(value, 0, CHARINDEX('=', value, 0))
ELSE
SUBSTRING(value, 0, CHARINDEX('=', value, 0)) + ' COLLATE DATABASE_DEFAULT AS '
+ SUBSTRING(value, 0, CHARINDEX('=', value, 0))
END AS sql
FROM STRING_SPLIT(@Primary_Key_Data_Type, ',')
) a
);
SET @SQL
= N'DECLARE @Min_Id BIGINT = (SELECT MIN(' + @pk_collate + N') FROM ' + @Catalog_Name + N'.' + @Schema_Name
+ N'.' + @Table_Name + N'' + CASE
WHEN @Is_System_Versioned = 1 THEN
' FOR SYSTEM_TIME ALL'
ELSE
''
END + N');';
SET @SQL
= @SQL + N'DECLARE @Max_Id BIGINT = (SELECT MAX(' + @pk_collate + N') FROM ' + @Catalog_Name + N'.'
+ @Schema_Name + N'.' + @Table_Name + N'' + CASE
WHEN @Is_System_Versioned = 1 THEN
' FOR SYSTEM_TIME ALL'
ELSE
''
END + N');';
SET @SQL
= @SQL + N'DECLARE @Rows_Count BIGINT = (SELECT COUNT(*) FROM ' + @Catalog_Name + N'.' + @Schema_Name + N'.'
+ @Table_Name + N'' + CASE
WHEN @Is_System_Versioned = 1 THEN
' FOR SYSTEM_TIME ALL'
ELSE
''
END + N');';
SET @SQL = @SQL + N'UPDATE metadata.wwi_objects SET Min_PK_Value = CAST (@Min_Id AS VARCHAR (100)), ';
SET @SQL
= @SQL
+ N'Max_PK_Value = CAST (@Max_Id AS VARCHAR (100)), Rows_Count = CAST (@Rows_Count AS VARCHAR (100)) WHERE Local_Object_Name = '''
+ @Table_Name + N'''';
EXEC (@SQL);
FETCH NEXT FROM cur_db_object_output
INTO @Table_Name,
@Schema_Name,
@Catalog_Name,
@Primary_Key_Data_Type,
@Is_System_Versioned;
END;
CLOSE cur_db_object_output;
DEALLOCATE cur_db_object_output;
UPDATE metadata.wwi_objects
SET ETL_Batch_No =
(
SELECT CASE
WHEN Rows_Count >= 1000000 THEN
FLOOR(Rows_Count / 1000000) + 1
ELSE
0
END
);
UPDATE metadata.wwi_objects
SET Is_Big = CASE
WHEN Rows_Count >= 1000000 THEN
1
ELSE
0
END;
END;
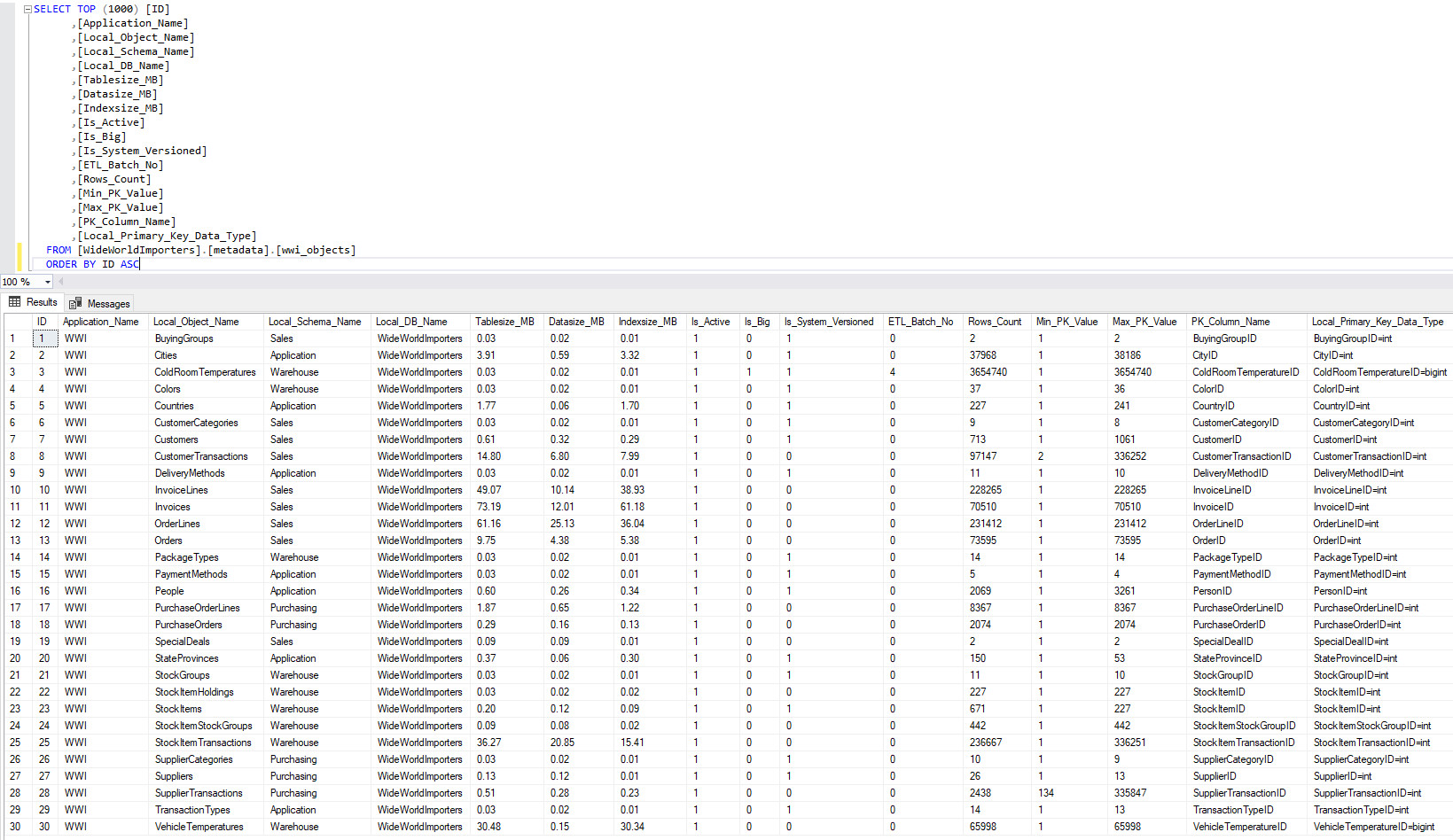
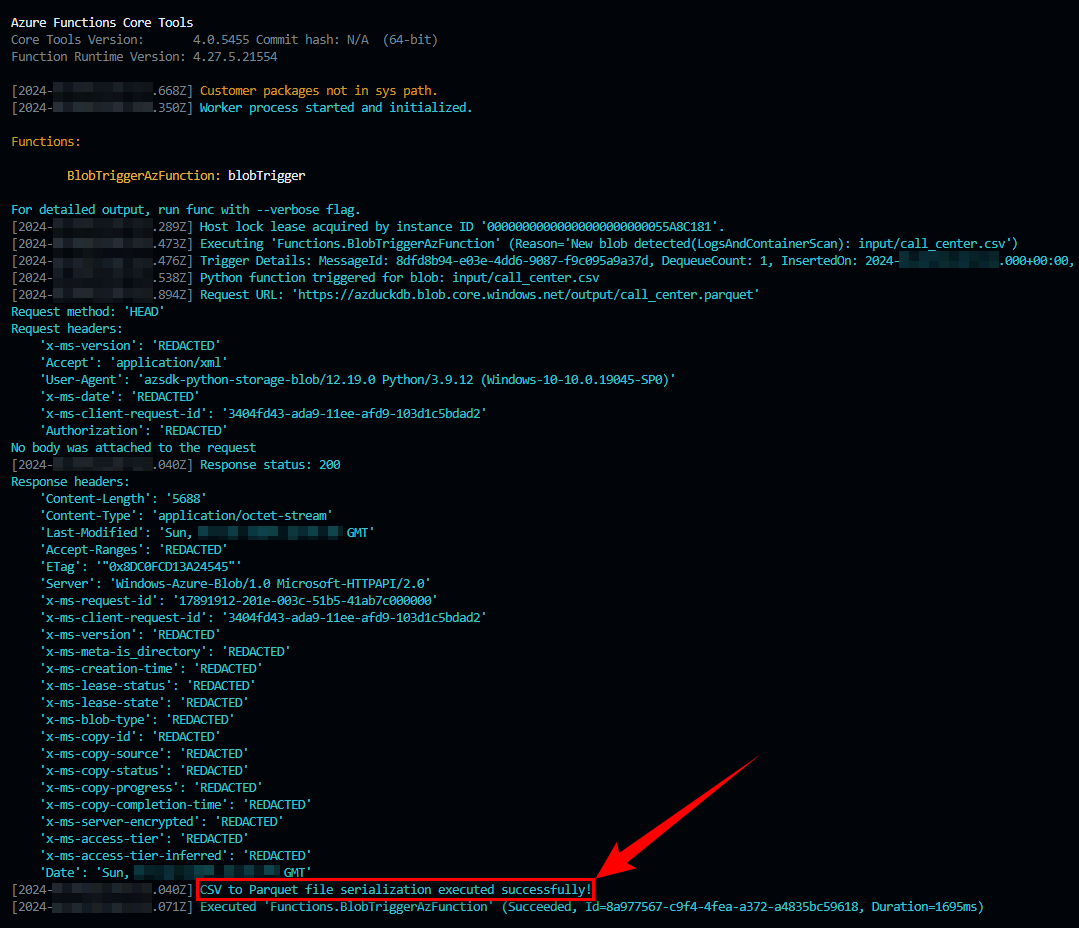
When executed, the stored procedure produces the following output (click on image to expand) in the metadata-storing target table. Notice that only ColdRoomTemperatures table has been defined as “large” (via the Is_Big = 1 flag field) and assigned 4 partitions (via the ETL_Batch_No = 4 field). This is a result of a simple logic where any table exceeding 1 million rows is automatically nominated as a large object – in a production environment, you’re more likely to use Tablesize_MB value which is a more accurate representation of how much data it holds and therefore whether it should be partitioned into smaller chunks.
Now onto the main data extraction code handled by Python. As previously mentioned, we will speed up this process by introducing parallel execution into the framework, however, the actual heavy lifting will be done using SQL Server’s built-in command line tool – the bcp utility. The bulk copy program utility (bcp) bulk copies data between an instance of Microsoft SQL Server and a data file in a user-specified format and in this scenario, we will use it to extract all WWI data into a series of CSV file located in the nominated directories.
from multiprocessing import Pool, cpu_count
from os import listdir, path, system, walk, remove, makedirs
import pyodbc
import csv
import time
_SQL_SERVER_NAME = "Your_server_Name_or_IP_Address"
_SQL_DB = "WideWorldImporters"
_SQL_USERNAME = "Your_User_Name"
_SQL_PASSWORD = "Your_Auth_Password"
_USE_WIN_AUTH = "False"
_CSV_EXPORT_FILES_PATH = path.normpath("Z:/CSV_Export/")
_METADATA_STORED_PROC = "usp_create_wwi_metadata"
_METADATA_STORED_PROC_SCHEMA = "metadata"
create_target_dirs = "Yes"
reconcile_record_counts = "Yes" # can be a long process for larger volumes of data
# define MSSQL connection string for pyodbc
def db_conn(_SQL_SERVER_NAME, _SQL_DB, _SQL_USERNAME, _SQL_PASSWORD, _USE_WIN_AUTH):
_SQL_DRIVER = "{ODBC Driver 17 for SQL Server}"
connection_string = (
"DRIVER="
+ _SQL_DRIVER
+ ";SERVER="
+ _SQL_SERVER_NAME
+ ";DATABASE="
+ _SQL_DB
+ ";encrypt="
"no"
";trust_server_certificate="
"yes"
"; autocommit="
"True; UID"
"=" + _SQL_USERNAME + ";PWD=" + _SQL_PASSWORD
)
if _USE_WIN_AUTH == True:
connection_string = connection_string + "Trusted_Connection=yes;"
try:
conn = pyodbc.connect(connection_string, timeout=1)
except pyodbc.Error as err:
conn = None
return conn
# algorythm used to break up large tables into specyfic 'chunks' - needs metadata table to be populated
def split_into_ranges(start, end, parts):
ranges = []
x = round((end - start) / parts)
for _ in range(parts):
ranges.append([start, start + x])
start = start + x + 1
if end - start <= x:
remainder = end - ranges[-1][-1]
ranges.append([ranges[-1][-1] + 1, ranges[-1][-1] + remainder])
break
return ranges
# run a few validation steps
def run_preload_validation_steps(DB_Conn, _SQL_DB, _CSV_EXPORT_FILES_PATH):
print(
"\nValidating '{db}' database connection...".format(db=_SQL_DB),
end="",
flush=True,
)
conn = DB_Conn(
_SQL_SERVER_NAME, _SQL_DB, _SQL_USERNAME, _SQL_PASSWORD, _USE_WIN_AUTH
)
if conn:
print("OK!")
else:
raise ValueError(
"Database connection was not successfull. Please troubleshoot!"
)
print(
"Validating {out_path}' directory paths exists...".format(
out_path=_CSV_EXPORT_FILES_PATH
),
end="",
flush=True,
)
if path.exists(_CSV_EXPORT_FILES_PATH):
print("OK!")
else:
raise ValueError(
"Input or output directory path does not exist or is melformed. Please troubleshoot!"
)
# Other validation steps
def run_postload_validation_steps(
metadata, reconcile_record_counts, _CSV_EXPORT_FILES_PATH
):
csv.field_size_limit(1000000000)
print(
"Validating required files in {out_path} have been generated...".format(
out_path=_CSV_EXPORT_FILES_PATH
),
end="",
flush=True,
)
f = files_found(_CSV_EXPORT_FILES_PATH)
if not f:
raise FileExistsError(
"Target export directory does not appear to have any files in it. Please troubleshoot!"
)
else:
print("OK!")
if reconcile_record_counts == "Yes":
print(
"Validating database and files record counts are matching...",
end="",
flush=True,
)
tables = [column[2] for column in metadata]
row_counts = [column[12] for column in metadata]
db_rows_counts = dict(zip(tables, row_counts))
csv_files_counts = {}
for root, dirs, files in walk(_CSV_EXPORT_FILES_PATH):
for file in files:
if file.endswith(".csv"):
file_path = path.join(root, file)
try:
with open(
file_path, "r", newline="", encoding="ISO-8859-1"
) as f:
reader = csv.reader(x.replace("\0", "") for x in f)
row_count = sum(
1 for row in reader
) # - 1 # Subtract 1 for the header row if present
except Exception as e:
print(f"Error reading {file_path}: {e}")
row_count = None
csv_files_counts.update({file: row_count})
csv_files_counts_added = {}
for key, value in csv_files_counts.items():
group_key = key.split("_")[0]
if group_key in csv_files_counts_added:
csv_files_counts_added[group_key] += value
else:
csv_files_counts_added[group_key] = value
if csv_files_counts_added != db_rows_counts:
raise ValueError(
"Record counts across source database tables and flat files are different. Please troubleshoot!"
)
else:
print("OK!")
# truncate target tables before the load is initated
def truncate_target_tables(_SQL_SERVER_NAME, _SQL_DB, _SQL_USERNAME, _SQL_PASSWORD):
try:
conn = db_conn(
_SQL_SERVER_NAME, _SQL_DB, _SQL_USERNAME, _SQL_PASSWORD, _USE_WIN_AUTH
)
with conn.cursor() as cursor:
sql = "SELECT table_name FROM {db}.INFORMATION_SCHEMA.TABLES ;".format(
db=_SQL_DB
)
cursor.execute(sql)
metadata = cursor.fetchall()
tables_to_truncate = [row[0] for row in metadata]
for table in tables_to_truncate:
sql_truncate = "TRUNCATE TABLE 'dbo.'{tbl};".format(tbl=table)
print("Truncating {tbl} table...".format(tbl=table), end="", flush=True)
cursor.execute("TRUNCATE TABLE dbo.{tbl}".format(tbl=table))
cursor.execute("SELECT TOP (1) 1 FROM dbo.{tbl}".format(tbl=table))
rows = cursor.fetchone()
if rows:
raise ValueError(
"Table truncation operation was not successfull. Please troubleshoot!"
)
else:
print("OK!")
except pyodbc.Error as ex:
sqlstate = ex.args[1]
print(sqlstate)
# export data
def export_data(
table_name,
schema_name,
pk_column_name,
is_system_versioned=None,
vals=None,
idx=None,
):
if create_target_dirs == "Yes" and not path.exists(
path.join(_CSV_EXPORT_FILES_PATH, table_name)
):
makedirs(path.join(_CSV_EXPORT_FILES_PATH, table_name))
if vals:
full_export_path = path.join(
_CSV_EXPORT_FILES_PATH,
table_name,
table_name + "_" + str(idx) + "_" + time.strftime("%Y%m%d-%H%M%S") + ".csv",
)
bcp = 'bcp "SELECT * FROM {db}.{schema}.{tbl} {sys_version_flag} WHERE {pk} BETWEEN {minv} AND {maxv}" queryout {path} -T -S {svr} -C 65001 -q -c -t "|" -r "\\n" 1>NUL'.format(
path=full_export_path,
db=_SQL_DB,
schema=schema_name,
tbl=table_name,
pk=pk_column_name,
svr=_SQL_SERVER_NAME,
sys_version_flag="FOR SYSTEM_TIME ALL" if is_system_versioned == 1 else "",
minv=str(int(vals[0])),
maxv=str(int(vals[1])),
)
else:
full_export_path = path.join(
_CSV_EXPORT_FILES_PATH,
table_name,
table_name + "_" + time.strftime("%Y%m%d-%H%M%S") + ".csv",
)
# bcp = 'bcp {db}.{schema}.{tbl} OUT "{path}" -a 65535 -h "TABLOCK" -T -S {svr} -q -c -t "|" -r "\\n" 1>NUL'.format(
bcp = 'bcp "SELECT * FROM {db}.{schema}.{tbl} {sys_version_flag}" queryout {path} -T -S {svr} -C 65001 -q -c -t "|" -r "\\n" 1>NUL'.format(
path=full_export_path,
db=_SQL_DB,
schema=schema_name,
tbl=table_name,
pk=pk_column_name,
sys_version_flag="FOR SYSTEM_TIME ALL" if is_system_versioned == 1 else "",
svr=_SQL_SERVER_NAME,
)
system(bcp)
# check for files
def files_found(_CSV_EXPORT_FILES_PATH):
files_found = False
for root, dirs, files in walk(_CSV_EXPORT_FILES_PATH):
if files:
files_found = True
return files_found
# export data in parallel - is very reasource intensive on MSSQL instance but a lot quicker compared to sequential approach
def main():
run_preload_validation_steps(db_conn, _SQL_DB, _CSV_EXPORT_FILES_PATH)
conn = db_conn(
_SQL_SERVER_NAME, _SQL_DB, _SQL_USERNAME, _SQL_PASSWORD, _USE_WIN_AUTH
)
print(
"Removing all {dir} export directory files...".format(
dir=_CSV_EXPORT_FILES_PATH
),
end="",
flush=True,
)
for root, dirs, files in walk(_CSV_EXPORT_FILES_PATH):
for file in files:
file_path = path.join(root, file)
if path.isfile(file_path):
remove(file_path)
f = files_found(_CSV_EXPORT_FILES_PATH)
if f:
raise FileExistsError(
"Target export directory could not be purged of existing files. Please troubleshoot!"
)
else:
print("OK!")
with conn.cursor() as cursor:
print(
"Creating target metadata in 'metadata.tpcds_objects object'...",
end="",
flush=True,
)
cursor = conn.cursor()
sql = """\
DECLARE @Return_Code INT;
EXEC @Return_Code = {schema}.{stored_proc} @Local_Database_Name = '{db}';
SELECT @Return_Code AS rc;""".format(
stored_proc=_METADATA_STORED_PROC,
schema=_METADATA_STORED_PROC_SCHEMA,
db=_SQL_DB,
)
cursor.execute(sql)
rc = cursor.fetchval()
if rc == 0:
print("OK!")
cursor.commit()
else:
raise ValueError(
"Stored proc failed to execute successfully. Please troubleshoot!"
)
sql = "SELECT * FROM metadata.wwi_objects;"
cursor.execute(sql)
metadata = cursor.fetchall()
print("Running export pipeline...")
with Pool(processes=2 * cpu_count()) as p3:
for row in metadata:
table_name = row[2]
schema_name = row[3]
is_big = int(row[9])
is_system_versioned = int(row[10])
etl_batch_no = int(row[11])
min_pk_value = int(row[13])
max_pk_value = int(row[14])
pk_column_name = row[15]
if is_big == 1:
ranges = split_into_ranges(min_pk_value, max_pk_value, etl_batch_no)
for idx, vals in enumerate(ranges):
p3.apply_async(
export_data,
[
table_name,
schema_name,
pk_column_name,
is_system_versioned,
vals,
idx,
],
)
else:
p3.apply_async(
export_data,
[
table_name,
schema_name,
pk_column_name,
is_system_versioned,
],
)
p3.close()
p3.join()
run_postload_validation_steps(
metadata, reconcile_record_counts, _CSV_EXPORT_FILES_PATH
)
if __name__ == "__main__":
main()
The above script also creates target directories in the root folder (each file storing WWI table data will reside in a separate directory) and run a series of validation tasks to ensure extracted data is as required. When executed, typically as part of a larger workflow, each unpartitioned table’s data is extracted to a CSV flat file with the following naming convention: TableName_YYYYMMDD-HHMMSS. For tables marked as containing larger volumes of data and therefore extracted into multiple, smaller files, sequence file number is also appended, creating the following files’ naming convention: TableName_SequenceNumber_YYYYMMDD-HHMMSS.
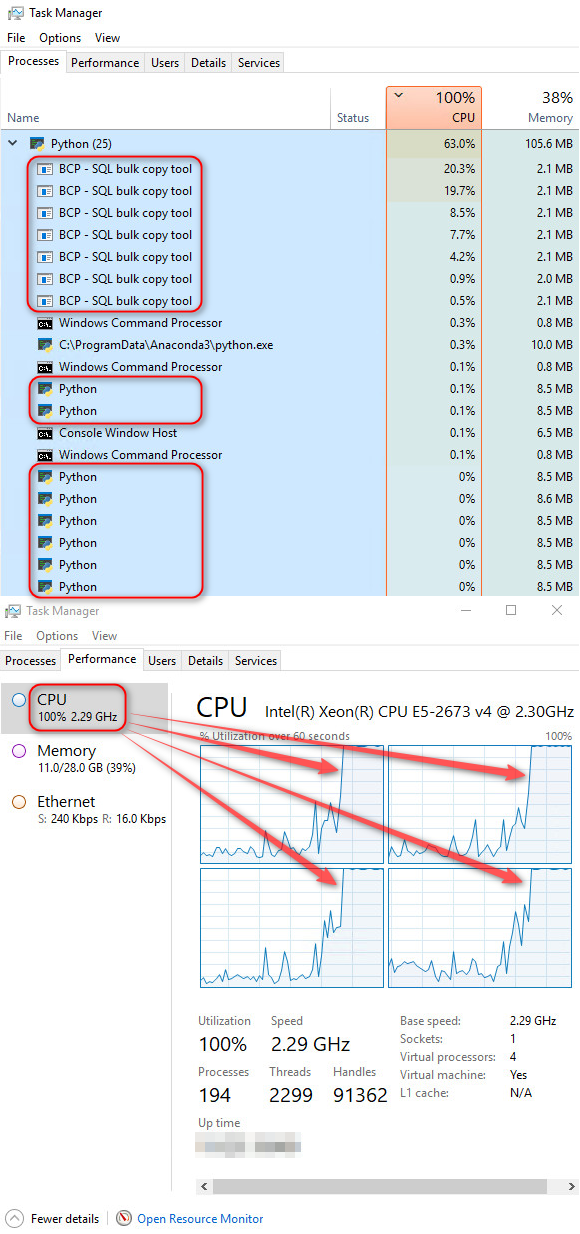
Looking at Windows Task Manager, you can notice that during script execution, multiple instance of bcp utility and Python process are spawned, maximizing CPU utilization through parallel workload execution.
Optionally (depending on the vDeleteTargetBlobs variable value), we can also delete all blobs in their corresponding containers – this feature should only be used for testing and vDeleteTargetBlobs variable set to “False” unless delta extracts are not implemented and we wish to extract the whole database content at every run. The following is a short snippet of Python code called to optionally purge Azure Storage containers.
from azure.storage.blob import BlockBlobService
account_name = "Your_Account_Name"
account_key = "Your_Account_Key"
def list_blobs(container):
try:
content = block_blob_service.list_blobs(container)
for blob in content:
print(
"Deleting blob '{blobname}' from '{container}' container...".format(
blobname=blob.name, container=container
),
end="",
flush=True,
)
block_blob_service.delete_blob(container, blob.name, snapshot=None)
blob_exists = block_blob_service.exists(
container_name=container, blob_name=blob
)
if blob_exists:
raise ValueError("Blob deletion failed. Please troubleshoot!")
else:
print("OK!")
except Exception as e:
print(e)
block_blob_service = BlockBlobService(
account_name=account_name, account_key=account_key
)
containers = block_blob_service.list_containers()
def main():
for c in containers:
list_blobs(c.name)
if __name__ == "__main__":
main()
Finally, a short mop-up batch script is run to move all uploaded files from CSV_Export folder and its subfolders into a CSV_Export_Old_Files archive directory.
for /r "Z:\CSV_Export\" %%x in (*.csv) do move "%%x" "Z:\CSV_Export_Old_Files\"
The following is a view of target directory after data extraction job successful execution (PowerShell directory view with “ColdRoomTemperatures” table data spread across multiple files) as well as Azure Storage Container created to store files in ADLS, ready for Snowflake consumption.
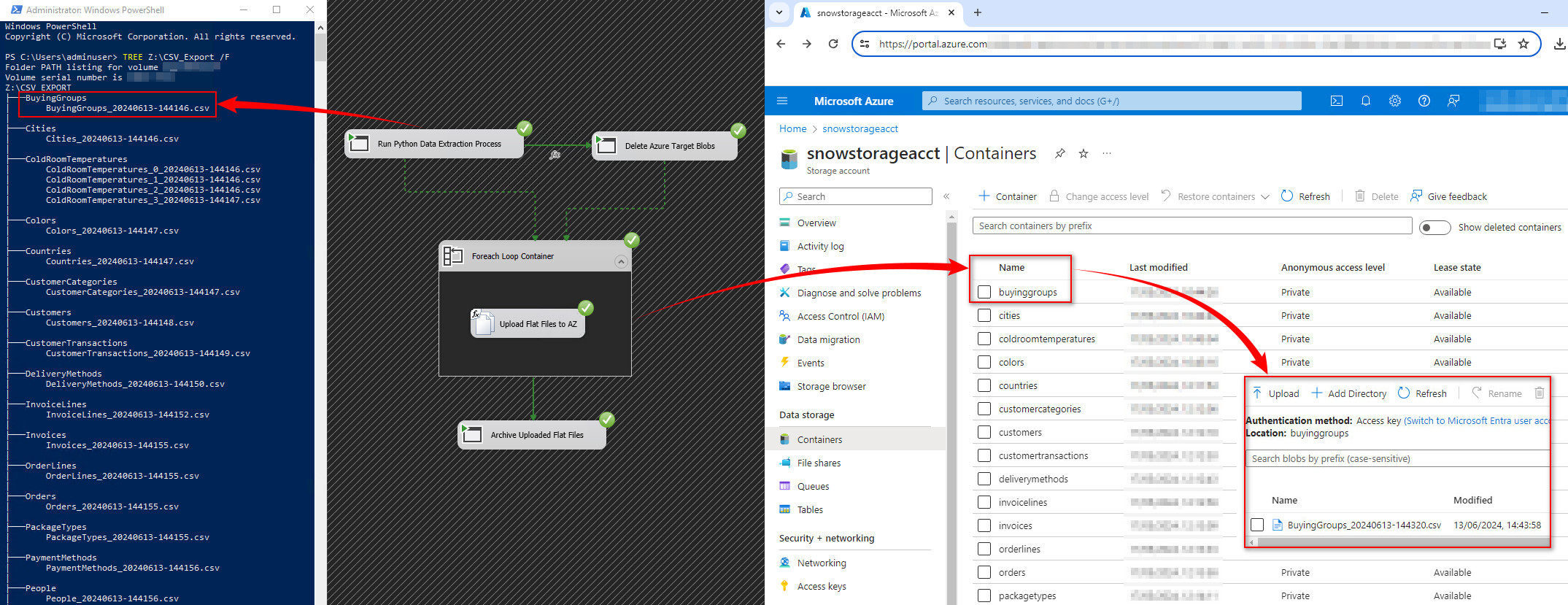
These scripts, coupled with Azure Blob upload activities are orchestrated using a dedicated SSIS package. Its sole purpose is to run required scripts in a specific order – data extraction, optional Azure Blob deletion, For Each Loop used for files upload and finally a small batch file script to archive files into a separate directory. Most of these activities are triggered using “Execute Process Task” and providing we have Python interpreter installed, these scripts run in a console mode. Additionally, a few expressions provide the flexibility of generating variables’ values dynamically, as per the image below. It’s a very simple workflow so I won’t go over each activity and its configuration details, just make sure you have Integration Services Feature Pack for Azure installed as an extension in your Visual Studio. This is because the flat files upload functionality relies on the Flexible File Task, which is only available in the aforementioned add-in. Alternatively, you can easily script it out in Python and integrate it a replacement for the Flexible File Task and ForEach Loop step.
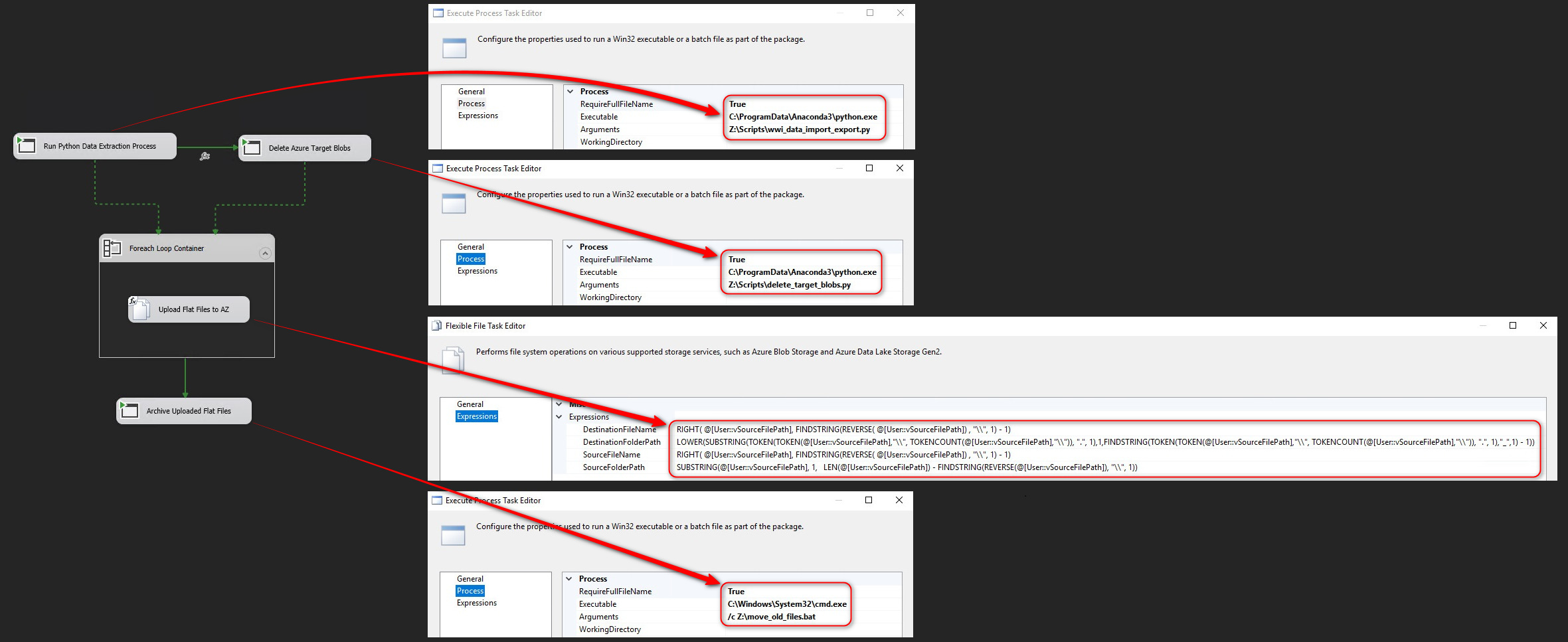
Executing the whole process takes around 30 seconds for all WWI tables and if successful, we should see a series of CSV files uploaded into our nominated ADLS containers. This takes us roughly halfway through the whole solution built and with data staged in Azure, we can turn our attention to the Snowflake platform.
Snowflake Dimensional Schema (WWIDW database) Load
Next we will recreate a cut-down version of the Wide World Importers Data Warehouse (WWIDW) star schema with five dimensions and one fact tables in Snowflake platform. The schema should look as per the ERD below. We will also create a new database as well as two database schemas to separate objects belonging to landing data into Snowflake environment and any integration/transformation work that needs to be done to structure our WWI data into a dimensional model.
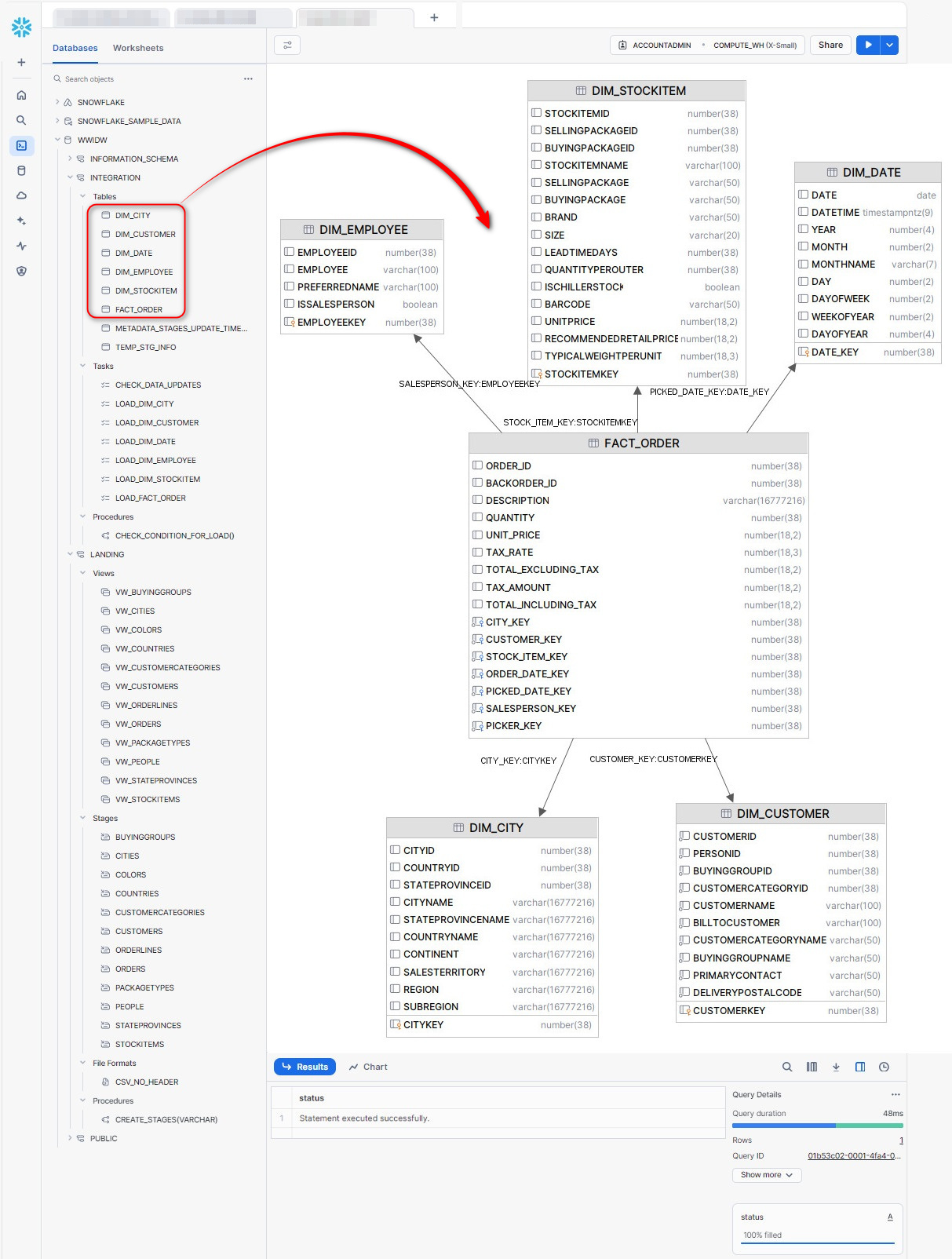
Now that we have our files neatly staged in Azure ADLS containers, let’s look at how we can expose their schema through Snowflake stage concept. Snowflake Stages are locations where data files are stored (staged) for loading and unloading data. They are used to move data from one place to another, and the locations for the stages could be internal or external to the Snowflake environment. Businesses can use a Snowflake stage to move their data from external data sources such as S3 buckets to internal Snowflake tables or vice-versa. Snowflake supports two different types of data stages: external stages and internal stages. An external stage is used to move data from external sources, such as S3 buckets, to internal Snowflake tables. On the other hand, an internal stage is used as an intermediate storage location for data files before they are loaded into a table or after they are unloaded from a table.
The following code is used to create the new database and schemas as well as a simple stored procedure used to loop over the required Azure storage tables and create Snowflake stages and is equivalent to executing ‘CREATE STAGE stage_name…’ for each required object.
CREATE
OR REPLACE DATABASE WWIDW;
CREATE
OR REPLACE SCHEMA Landing;
CREATE
OR REPLACE SCHEMA Integration;
USE WWIDW.Landing;
DROP TABLE IF EXISTS landing.temp_stages;
CREATE temporary TABLE landing.temp_stages (stg_name text);
INSERT INTO
landing.temp_stages (stg_name)
SELECT 'cities' UNION ALL SELECT 'stateprovinces' UNION ALL SELECT 'countries' UNION ALL
SELECT 'customers' UNION ALL SELECT 'buyinggroups' UNION ALL SELECT 'customercategories' UNION ALL
SELECT 'people' UNION ALL SELECT 'orders' UNION ALL SELECT 'orderlines' UNION ALL
SELECT 'packagetypes' UNION ALL SELECT 'stockitems' UNION ALL SELECT 'colors';
CREATE OR REPLACE PROCEDURE landing.create_stages(Azure_SAS_Token TEXT)
RETURNS TEXT
LANGUAGE SQL
AS $$
DECLARE
sql_drop_stage TEXT;
sql_create_stage TEXT;
c1 CURSOR FOR SELECT stg_name FROM temp_stages;
BEGIN
OPEN c1;
FOR rec IN c1 DO
-- Drop stage statement
sql_drop_stage := REPLACE('DROP STAGE IF EXISTS <stg_name>', '<stg_name>', rec.stg_name);
-- Execute drop stage
EXECUTE IMMEDIATE :sql_drop_stage;
-- Create stage statement
sql_create_stage := REPLACE(
'CREATE STAGE landing.<stg_name> URL = ''azure://your_storage_acct_name.blob.core.windows.net/<stg_name>'' ' ||
'CREDENTIALS = ( AZURE_SAS_TOKEN = ''' || Azure_SAS_Token || ''' ) ' ||
'DIRECTORY = ( ENABLE = true AUTO_REFRESH = false ) ' ||
'COMMENT = ''<stg_name> Stage''',
'<stg_name>', rec.stg_name
);
-- Execute create stage
EXECUTE IMMEDIATE :sql_create_stage;
END FOR;
CLOSE c1;
RETURN 'Stages processed successfully';
END;
$$;
CALL landing.create_stages('Your_SAS_Key');
With all relevant Stages created, next, we will create views which map to the stages to allow us to query flat files data as if they were tables. Snowflake capability allows view creation on top of stage files which in turn allows to query those as if they were native database objects. You can also notice that for each of the views I’ve included two metadata columns denoting the underlying file name and stage modification timestamp. This timestamp will come in handy when creating Snowflake Tasks functionality (for star schema refresh) and a conditional logic derived from timestamps comparison.
In addition to this we will also create a named file format that describes a set of staged data to access or load into Snowflake tables.
USE WWIDW.Landing;
CREATE
OR REPLACE FILE FORMAT csv_no_header TYPE = 'CSV' FIELD_DELIMITER = '|' SKIP_HEADER = 0 NULL_IF = ('NULL');
CREATE
OR REPLACE VIEW WWIDW.Landing.vw_cities
AS
SELECT
t.$1 as CityID,
t.$2 as CityName,
t.$3 as StateProvinceID,
metadata$filename as FileName,
metadata$file_last_modified StgModifiedTS
FROM
@Cities (file_format => 'csv_no_header') t;
CREATE
OR REPLACE VIEW WWIDW.Landing.vw_stateprovinces AS
SELECT
t.$1 as StateProvinceID,
t.$2 as StateProvinceCode,
t.$3 as StateProvinceName,
t.$4 as CountryID,
t.$5 as SalesTerritory,
metadata$filename as FileName,
metadata$file_last_modified StgModifiedTS
FROM
@stateprovinces (file_format => 'csv_no_header') t;
CREATE
OR REPLACE VIEW WWIDW.Landing.vw_countries as
SELECT
t.$1 as CountryID,
t.$2 as CountryName,
t.$3 as FormalName,
t.$4 as IsoAlpha3Code,
t.$5 as IsoNumericCode,
t.$6 as CountryType,
t.$8 as Continent,
t.$9 as Region,
t.$10 as Subregion,
metadata$filename as FileName,
metadata$file_last_modified StgModifiedTS
FROM
@countries (file_format => 'csv_no_header') t;
CREATE
OR REPLACE VIEW WWIDW.Landing.vw_customers as
SELECT
t.$1 as CustomerID,
t.$2 as CustomerName,
t.$3 as BillToCustomerID,
t.$4 as CustomerCategoryID,
t.$5 as BuyingGroupID,
t.$6 as PrimaryContactPersonID,
t.$7 as AlternateContactPersonID,
t.$8 as DeliveryMethodID,
t.$9 as DeliveryCityID,
t.$10 as PostalCityID,
t.$11 as CreditLimit,
t.$12 as AccountOpenedDate,
t.$13 as StandardDiscountPercentage,
t.$14 as IsStatementSent,
t.$15 as IsOnCreditHold,
t.$16 as PaymentDays,
t.$17 as PhoneNumber,
t.$18 as FaxNumber,
t.$19 as DeliveryRun,
t.$20 as RunPosition,
t.$21 as WebsiteURL,
t.$22 as DeliveryAddressLine1,
t.$23 as DeliveryAddressLine2,
t.$24 as DeliveryPostalCode,
t.$25 as DeliveryLocation,
t.$26 as PostalAddressLine1,
t.$27 as PostalAddressLine2,
t.$28 as PostalPostalCode,
metadata$filename as FileName,
metadata$file_last_modified StgModifiedTS
FROM
@customers (file_format => 'csv_no_header') t;
CREATE
OR REPLACE VIEW WWIDW.Landing.vw_buyinggroups as
SELECT
t.$1 as BuyingGroupID,
t.$2 as BuyingGroupName,
metadata$filename as FileName,
metadata$file_last_modified StgModifiedTS
FROM
@buyinggroups (file_format => 'csv_no_header') t;
CREATE
OR REPLACE VIEW WWIDW.Landing.vw_customercategories AS
SELECT
t.$1 as CustomerCategoryID,
t.$2 as CustomerCategoryName,
metadata$filename as FileName,
metadata$file_last_modified StgModifiedTS
FROM
@customercategories (file_format => 'csv_no_header') t;
CREATE
OR REPLACE VIEW WWIDW.Landing.vw_customers as
SELECT
t.$1 as CustomerID,
t.$2 as CustomerName,
t.$3 as BillToCustomerID,
t.$4 as CustomerCategoryID,
t.$5 as BuyingGroupID,
t.$6 as PrimaryContactPersonID,
t.$7 as AlternateContactPersonID,
t.$8 as DeliveryMethodID,
t.$9 as DeliveryCityID,
t.$10 as PostalCityID,
t.$11 as CreditLimit,
t.$12 as AccountOpenedDate,
t.$13 as StandardDiscountPercentage,
t.$14 as IsStatementSent,
t.$15 as IsOnCreditHold,
t.$16 as PaymentDays,
t.$17 as PhoneNumber,
t.$18 as FaxNumber,
t.$19 as DeliveryRun,
t.$20 as RunPosition,
t.$21 as WebsiteURL,
t.$22 as DeliveryAddressLine1,
t.$23 as DeliveryAddressLine2,
t.$24 as DeliveryPostalCode,
t.$25 as DeliveryLocation,
t.$26 as PostalAddressLine1,
t.$27 as PostalAddressLine2,
t.$28 as PostalPostalCode,
metadata$filename as FileName,
metadata$file_last_modified StgModifiedTS
FROM
@customers (file_format => 'csv_no_header') t;
CREATE
OR REPLACE VIEW WWIDW.Landing.vw_people as
SELECT
t.$1 as PersonID,
t.$2 as FullName,
t.$3 as PreferredName,
t.$4 as SearchName,
t.$5 as IsPermittedToLogon,
t.$6 as LogonName,
t.$7 as IsExternalLogonProvider,
t.$8 as HashedPassword,
t.$9 as IsSystemUser,
t.$10 as IsEmployee,
t.$11 as IsSalesperson,
t.$12 as UserPreferences,
t.$13 as PhoneNumber,
t.$14 as FaxNumber,
t.$15 as EmailAddress,
t.$16 as Photo,
t.$17 as CustomFields,
t.$18 as OtherLanguages,
metadata$filename as FileName,
metadata$file_last_modified StgModifiedTS
FROM
@people (file_format => 'csv_no_header') t;
CREATE
OR REPLACE VIEW WWIDW.Landing.vw_stockitems as
SELECT
t.$1 as StockItemID,
t.$2 as StockItemName,
t.$3 as SupplierID,
t.$4 as ColorID,
t.$5 as UnitPackageID,
t.$6 as OuterPackageID,
t.$7 as Brand,
t.$8 as Size,
t.$9 as LeadTimeDays,
t.$10 as QuantityPerOuter,
t.$11 as IsChillerStock,
t.$12 as Barcode,
t.$13 as TaxRate,
t.$14 as UnitPrice,
t.$15 as RecommendedRetailPrice,
t.$16 as TypicalWeightPerUnit,
t.$17 as MarketingComments,
t.$18 as InternalComments,
t.$19 as Photo,
t.$20 as CustomFields,
t.$21 as Tags,
t.$22 as SearchDetails,
metadata$filename as FileName,
metadata$file_last_modified StgModifiedTS
FROM
@stockitems (file_format => 'csv_no_header') t;
CREATE
OR REPLACE VIEW WWIDW.Landing.vw_orders as
SELECT
t.$1 as OrderID,
t.$2 as CustomerID,
t.$3 as SalespersonPersonID,
t.$4 as PickedByPersonID,
t.$5 as ContactPersonID,
t.$6 as BackorderOrderID,
t.$7 as OrderDate,
t.$8 as ExpectedDeliveryDate,
t.$9 as CustomerPurchaseOrderNumber,
t.$10 as IsUndersupplyBackordered,
t.$11 as Comments,
t.$12 as DeliveryInstructions,
t.$13 as InternalComments,
t.$14 as PickingCompletedWhen,
metadata$filename as FileName,
metadata$file_last_modified StgModifiedTS
FROM
@orders (file_format => 'csv_no_header') t;
CREATE
OR REPLACE VIEW WWIDW.Landing.vw_orderlines as
SELECT
t.$1 as OrderLineID,
t.$2 as OrderID,
t.$3 as StockItemID,
t.$4 as Description,
t.$5 as PackageTypeID,
t.$6 as Quantity,
t.$7 as UnitPrice,
t.$8 as TaxRate,
t.$9 as PickedQuantity,
t.$10 as PickingCompletedWhen,
metadata$filename as FileName,
metadata$file_last_modified StgModifiedTS
FROM
@orderlines (file_format => 'csv_no_header') t;
CREATE
OR REPLACE VIEW WWIDW.Landing.vw_colors as
SELECT
t.$1 as ColorID,
t.$2 as ColorName,
t.$3 as LastEditedBy,
metadata$filename as FileName,
metadata$file_last_modified StgModifiedTS
FROM
@colors (file_format => 'csv_no_header') t;
CREATE
OR REPLACE VIEW WWIDW.Landing.vw_packagetypes as
SELECT
t.$1 as PackageTypeID,
t.$2 as PackageTypeName,
metadata$filename as FileName,
metadata$file_last_modified StgModifiedTS
FROM
@orders (file_format => 'csv_no_header') t;
Now we are ready to create our dimensional schema. The following code creates our simplified star schema objects and populates them with placeholder values used to denote missing values e.g. -1 for INT-like values, ‘Unknown’ for character-based values etc. This creates a skeleton schema which holds attributes and values sourced from transactional database by way of querying our already created views or by applying business logic to source data to create new measures and dimension fields.
USE WWIDW.Integration;
DROP TABLE IF EXISTS Integration.Dim_City;
CREATE
OR REPLACE TABLE Integration.Dim_City (
CityKey INT autoincrement start 1 increment 1,
CityID INT NULL,
CountryID INT NULL,
StateProvinceID INT NULL,
CityName STRING NULL,
StateProvinceName STRING NULL,
CountryName STRING NULL,
Continent STRING NULL,
SalesTerritory STRING NULL,
Region STRING NULL,
Subregion STRING NULL
);
INSERT INTO
Integration.Dim_City (
CityKey,
CityID,
CountryID,
StateProvinceID,
CityName,
StateProvinceName,
CountryName,
Continent,
SalesTerritory,
Region,
Subregion
)
VALUES
(
-1,
-1,
-1,
-1,
'Unknown',
'Unknown',
'Unknown',
'Unknown',
'Unknown',
'Unknown',
'Unknown'
);
DROP TABLE IF EXISTS Integration.Dim_Customer;
CREATE
OR REPLACE TABLE Integration.Dim_Customer (
CustomerKey INT autoincrement start 1 increment 1,
CustomerID INT NOT NULL,
PersonID INT NOT NULL,
BuyingGroupID INT NOT NULL,
CustomerCategoryID INT NOT NULL,
CustomerName VARCHAR(100) NOT NULL,
BillToCustomer VARCHAR(100) NOT NULL,
CustomerCategoryName VARCHAR(50) NOT NULL,
BuyingGroupName VARCHAR(50) NOT NULL,
PrimaryContact VARCHAR(50) NOT NULL,
DeliveryPostalCode VARCHAR(50) NOT NULL
);
INSERT INTO
Integration.Dim_Customer (
CustomerKey,
CustomerID,
PersonID,
BuyingGroupID,
CustomerCategoryID,
CustomerName,
BillToCustomer,
CustomerCategoryName,
BuyingGroupName,
PrimaryContact,
DeliveryPostalCode
)
VALUES
(
-1,
-1,
-1,
-1,
-1,
'Unknown',
'Unknown',
'Unknown',
'Unknown',
'Unknown',
'Unknown'
);
DROP TABLE IF EXISTS Integration.Dim_Employee;
CREATE
OR REPLACE TABLE Integration.Dim_Employee (
EmployeeKey INT autoincrement start 1 increment 1,
EmployeeId INT,
Employee varchar (100),
PreferredName varchar (100),
IsSalesPerson boolean
);
INSERT INTO
Integration.Dim_Employee (
EmployeeKey,
EmployeeId,
Employee,
PreferredName,
IsSalesPerson
)
VALUES(-1, -1, 'Unknown', 'Unknown', NULL);
DROP TABLE IF EXISTS Integration.Dim_StockItem;
CREATE
OR REPLACE TABLE Integration.Dim_StockItem (
StockItemKey INT autoincrement start 1 increment 1,
StockItemID INT NULL,
SellingPackageId INT NULL,
BuyingPackageId INT NULL,
StockItemName STRING(100) NULL,
SellingPackage STRING(50) NULL,
BuyingPackage STRING(50) NULL,
Brand STRING(50) NULL,
Size STRING(20) NULL,
LeadTimeDays INT NULL,
QuantityPerOuter INT NULL,
IsChillerStock BOOLEAN NULL,
Barcode STRING(50) NULL,
UnitPrice DECIMAL(18, 2) NULL,
RecommendedRetailPrice DECIMAL(18, 2) NULL,
TypicalWeightPerUnit DECIMAL(18, 3) NULL
);
INSERT INTO
Integration.Dim_StockItem (
StockItemKey,
StockItemID,
SellingPackageId,
BuyingPackageId,
StockItemName,
SellingPackage,
BuyingPackage,
Brand,
Size,
LeadTimeDays,
QuantityPerOuter,
IsChillerStock,
Barcode,
UnitPrice,
RecommendedRetailPrice,
TypicalWeightPerUnit
)
VALUES(
-1,
-1,
-1,
-1,
'Unknown',
'Unknown',
'Unknown',
'Unknown',
'Unknown',
-1,
-1,
NULL,
'Unknown',
-1,
-1,
-1
);
DROP TABLE IF EXISTS Integration.Fact_Order;
CREATE
OR REPLACE TABLE Integration.Fact_Order (
Order_ID INT NULL,
Backorder_ID INT NULL,
Description STRING NULL,
Quantity INT NULL,
Unit_Price DECIMAL(18, 2) NULL,
Tax_Rate DECIMAL(18, 3) NULL,
Total_Excluding_Tax DECIMAL(18, 2) NULL,
Tax_Amount DECIMAL(18, 2) NULL,
Total_Including_Tax DECIMAL(18, 2) NULL,
City_Key INT NOT NULL,
Customer_Key INT NOT NULL,
Stock_Item_Key INT NOT NULL,
Order_Date_Key NUMBER(38, 0) NOT NULL,
Picked_Date_Key NUMBER(38, 0) NOT NULL,
Salesperson_Key INT NOT NULL,
Picker_Key INT NOT NULL
);
You can also notice that Date dimension table is not listed in the code below. This is due to the fact we will use CTAS (Create Table AS) loading pattern for this particular table (meaning its content will be generated by an output from a recursive SELECT query) when we define data loading process.
With all the required “core” objects in place, let’s look at the mechanism these can be loaded with transactional data from our staged files and views. There are many different ways to load tables in Snowflake and a few different approaches to have this process automated. In this scenario, I’d like to create an end-to-end pipeline where a dedicated process checks for underlying source data changes and if any detected, load all dimension tables first, followed by loading fact tables next. This data orchestration can be achieved out of the box with Snowflake feature called Tasks. Snowflake introduced Tasks for scheduling and orchestrating data pipelines and workflows in late 2019. The first release of Tasks only offered the option to schedule SQL statements, e.g. for loading and unloading data. At this point in time Snowflake customers were not able to create data pipeline DAGs or workflows. However, over the last couple of years the company has added a significant number of enterprise features:
- Task Chaining – Snowflake added the ability to chain tasks together, allowing the output of one task to trigger the execution of subsequent tasks, enabling complex workflows.
- Multiple Schedules – Snowflake introduced the capability to define multiple schedules for a single task, allowing greater flexibility in task execution planning.
- External Functions and External Network Support – Support for invoking external functions within tasks was added to access external services and APIs.
- Stream Integration – Snowflake enhanced tasks to work more seamlessly with streams, enabling tasks to trigger based on changes captured by Snowflake streams, thus supporting real-time data processing workflows.
Snowflake Tasks are organised as DAGs (Directed Acyclic Graphs) which represent a sequence of operations or tasks where each task is a node in the graph, and dependencies between these tasks are directed edges. The “acyclic” nature means that there are no loops, ensuring that the workflow progresses from start to finish without revisiting any task. This structure is pivotal for designing data pipelines that are complex, yet deterministic and predictable. Snowflake Task refers to a single operational unit that performs a specific function. This could be a SQL statement for data transformation, a procedure call, or an action to trigger external services. Tasks are the actionable components that, when chained together, form a comprehensive data pipeline. Snowflake Tasks can have a maximum of 1,000 tasks. The maximum number of upstream and downstream tasks is 100 each. You can chain together multiple DAGs to get around the limit.
Finally, there is a separation of Tasks and Jobs where Tasks act as containers for a Task Job. They define the Task Jobs that need to be run. Task Jobs, on the other hand, are the actual workloads, e.g. DML statements that perform the work. They are defined inside the Task. These are similar to Airflow’s Operators.
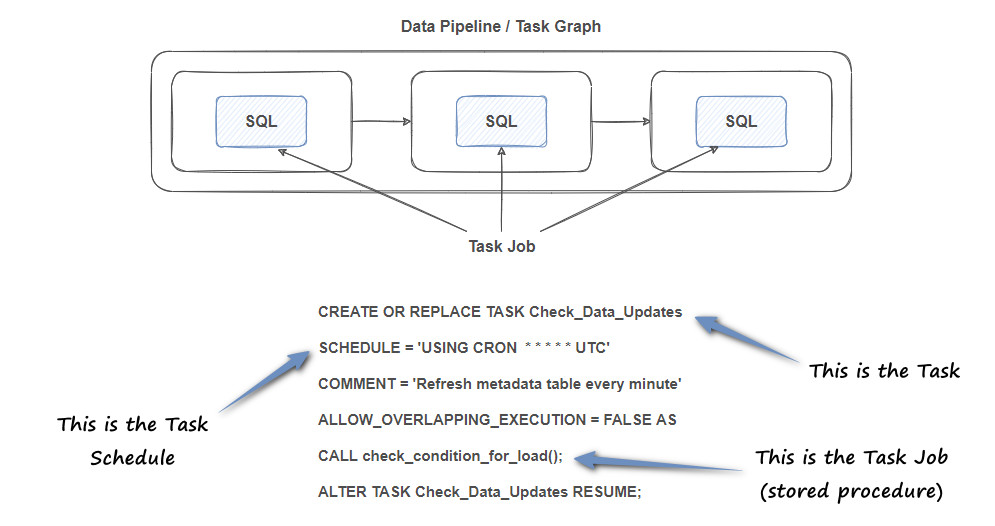
Tasks can then be triggered on schedule or responding to an event, with Snowflake offering different mechanisms for their execution.
- Frequency-Based Scheduling – Schedule tasks at regular intervals, like every few hours or daily, to meet your operational needs.
- Cron-Style Scheduling – Use cron expressions for precise timing, such as at 8:45 PM on the first day of the month, or every 15 minutes during work hours on weekdays.
- Event-Based Scheduling – This method activates tasks based on certain events rather than at scheduled times. It automatically triggers tasks either when previous tasks complete or when data changes are detected.
We can use Snowflake Tasks to “stitch together” a series of units of work or jobs with surprisingly little amount of SQL. However, in this scenario, rather than running each Tasks on a predefined schedule, I’d like to create a workflow where only the first Task runs on a predefined cadence and based on its execution output, the remaining pipeline Tasks are run or are halted. Also, as mentioned before, I will run Dimension tables load first, followed by Fact table load in a fan-out fashion (see image below).
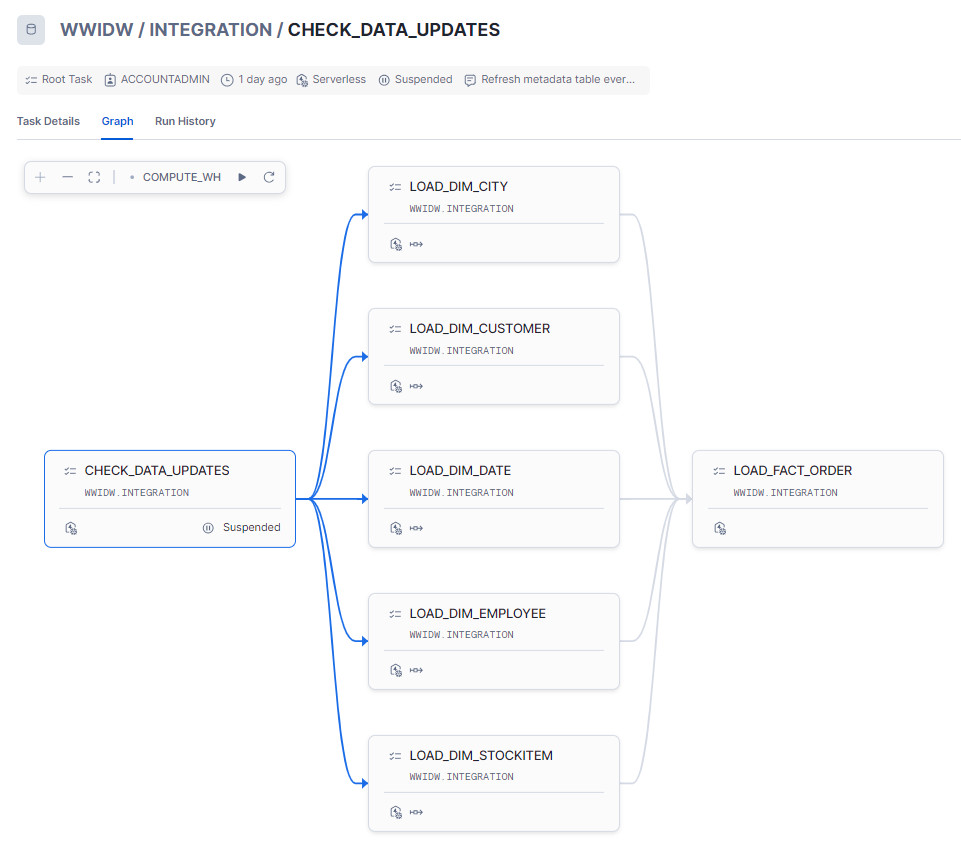
In this example, “Check_Data_Updates” Tasks is run every minute (using CRON-based scheduler) and its main role is to detect any Snowflake Stage changes based on Update timestamp metadata. If any modifications are detected (timestamps, stage names and other attributes are stored in a metadata table), a return value parameter is passed into subsequent Tasks and depending on this value, these are executed or paused. The output parameter is defined by SYSTEM$SET_RETURN_VALUE() function which to set a return value of 1 or 0 – 1 denoting stage metadata change has been detected (therefore run all the remaining Tasks) and 0 meaning no change was detected.
The following code defines metadata table schema and small stored procedure which runs as part of Check_Data_Updates Task.
USE WWIDW.Integration;
CREATE
OR REPLACE TABLE integration.metadata_stages_update_timestamps (
Id INT IDENTITY,
stage_name TEXT,
stage_modified_ts TIMESTAMP_NTZ,
ts_mins_timediff INT,
is_diff_flag BOOLEAN
);
CREATE OR REPLACE PROCEDURE Integration.check_condition_for_load()
RETURNS BOOLEAN
LANGUAGE SQL
EXECUTE AS CALLER
AS $$
DECLARE
snow_sql TEXT;
is_diff_flag BOOLEAN;
c1 CURSOR FOR
SELECT Stage_Name
FROM INFORMATION_SCHEMA.stages
WHERE Stage_Schema = 'LANDING';
c2 CURSOR FOR
SELECT stg_name, stg_modified_ts
FROM temp_stg_info;
BEGIN
-- Drop and recreate the table
snow_sql := 'DROP TABLE IF EXISTS Integration.temp_stg_info;';
EXECUTE IMMEDIATE snow_sql;
snow_sql := 'CREATE TABLE Integration.temp_stg_info (
stg_name TEXT,
stg_modified_ts TIMESTAMP_NTZ,
ts_mins_timediff INT
);';
EXECUTE IMMEDIATE snow_sql;
-- Populate temp_stg_info table
FOR rec IN c1 DO
snow_sql := 'INSERT INTO Integration.temp_stg_info (stg_name, stg_modified_ts, ts_mins_timediff) ' ||
'SELECT ''' || rec.Stage_Name || ''', ' ||
'(SELECT CONVERT_TIMEZONE(''UTC'', ''Australia/Melbourne'', MAX(metadata$file_last_modified)) ' ||
'FROM @Landing."' || rec.Stage_Name || '"), NULL;';
EXECUTE IMMEDIATE snow_sql;
END FOR;
FOR rec IN c2 DO
snow_sql := REPLACE('ALTER STAGE Landing.<stg_name> REFRESH', '<stg_name>', rec.stg_name);
EXECUTE IMMEDIATE snow_sql;
snow_sql := 'UPDATE temp_stg_info SET ts_mins_timediff = ' ||
'DATEDIFF(minute, ''' || rec.stg_modified_ts || ''', ' ||
'CONVERT_TIMEZONE(''UTC'', ''Australia/Melbourne'', SYSDATE())) ' ||
'WHERE stg_name = ''' || rec.stg_name || '''';
EXECUTE IMMEDIATE snow_sql;
END FOR;
-- Merge into metadata_stages_update_timestamps
snow_sql := 'MERGE INTO integration.metadata_stages_update_timestamps tgt USING (
SELECT DISTINCT stg_name AS stage_name,
stg_modified_ts AS stage_modified_ts,
ts_mins_timediff
FROM temp_stg_info
) src
ON tgt.stage_name = src.stage_name
WHEN MATCHED AND (tgt.stage_modified_ts <> src.stage_modified_ts) THEN
UPDATE SET tgt.stage_modified_ts = src.stage_modified_ts,
tgt.ts_mins_timediff = src.ts_mins_timediff,
tgt.is_diff_flag = 1
WHEN MATCHED AND (tgt.stage_modified_ts = src.stage_modified_ts) THEN
UPDATE SET tgt.is_diff_flag = 0
WHEN NOT MATCHED THEN
INSERT (stage_name, stage_modified_ts, ts_mins_timediff, is_diff_flag)
VALUES (src.stage_name, src.stage_modified_ts, src.ts_mins_timediff, 1);';
EXECUTE IMMEDIATE snow_sql;
-- Check for differences
SELECT COUNT(*) INTO :is_diff_flag
FROM (
SELECT stage_name
FROM integration.metadata_stages_update_timestamps
WHERE is_diff_flag = 1
GROUP BY stage_name
);
IF (is_diff_flag > 0) THEN
CALL system$set_return_value('1');
ELSE
CALL system$set_return_value('0');
END IF;
END;
$$;
CALL Integration.check_condition_for_load();
To turn this into a Tasks and run it on schedule we can execute the following SQL:
CREATE OR REPLACE TASK Check_Data_Updates SCHEDULE = 'USING CRON * * * * * UTC' COMMENT = 'Refresh metadata table every minute' ALLOW_OVERLAPPING_EXECUTION = FALSE AS CALL check_condition_for_load(); ALTER TASK Check_Data_Updates RESUME;
Now we can create the remainder of the star schema loading Tasks and SQL, including the Dim_Date table load process. The following code creates Tasks and their supporting logic for all Fact and Dimension tables. Notice the inclusion of WHEN SYSTEM$GET_PREDECESSOR_RETURN_VALUE(‘CHECK_DATA_UPDATES’) = 1 clause in the Task definition. The SYSTEM$GET_PREDECESSOR_RETURN_VALUE() function is used to validate the predecessor Task execution return value output and determine subsequent pipeline Task state. Also, the last few lines of code defining pimary keys and foreign key constraints between the fact table and all the dimension tables are optional.
CREATE
OR REPLACE TASK Load_Dim_Date
AFTER
Check_Data_Updates
WHEN SYSTEM$GET_PREDECESSOR_RETURN_VALUE('CHECK_DATA_UPDATES') = 1 AS CREATE
OR REPLACE TABLE integration.dim_date AS WITH CTE_MY_DATE AS (
SELECT
row_number() over (
order by
seq8()
) -1 as rn,
dateadd('day', rn, '2010-01-01'::date) as MY_DATE
from
table(generator(rowcount => 5000))
)
SELECT
'99991231' as Date_Key,
TO_DATE('9999-12-31') as Date,
TO_TIMESTAMP('9999-12-31') as DateTime,
-1 as Year,
-1 as Month,
'Unknown' as MonthName,
-1 as Day,
-1 as DayOfWeek,
-1 as WeekOfYear,
-1 as DayOfYear
UNION ALL
SELECT
CAST(
TO_VARCHAR(DATE_TRUNC('DAY', MY_DATE), 'YYYYMMDD') AS INTEGER
) AS Date_Key,
TO_DATE(MY_DATE) as date,
TO_TIMESTAMP(MY_DATE) as datetime,
YEAR(MY_DATE) as year,
MONTH(MY_DATE) as month,
MONTHNAME(MY_DATE) as monthname,
DAY(MY_DATE) as day,
DAYOFWEEK(MY_DATE) as dayofweek,
WEEKOFYEAR(MY_DATE) as weekofyear,
DAYOFYEAR(MY_DATE) as dayofyear,
FROM
CTE_MY_DATE;
ALTER TASK Load_Dim_Date RESUME;
//ALTER TASK Load_Dim_Date SUSPEND;
CREATE
OR REPLACE TASK Load_Dim_City
AFTER
Check_Data_Updates
WHEN SYSTEM$GET_PREDECESSOR_RETURN_VALUE('CHECK_DATA_UPDATES') = 1 AS MERGE INTO Integration.Dim_City tgt USING(
SELECT
DISTINCT c.CityID,
c.CityName,
sp.StateProvinceName,
co.CountryName,
co.Continent,
sp.SalesTerritory,
co.Region,
co.Subregion,
sp.StateProvinceID,
co.CountryID
FROM
Landing.vw_cities AS c
INNER JOIN Landing.vw_stateprovinces AS sp ON c.StateProvinceID = sp.StateProvinceID
INNER JOIN Landing.vw_countries AS co ON sp.CountryID = co.CountryID
) src ON tgt.CityID = src.CityID
AND tgt.StateProvinceID = src.StateProvinceID
AND tgt.CountryID = src.CountryID
WHEN MATCHED
AND (
tgt.CityName <> src.CityName
OR tgt.StateProvinceName <> src.StateProvinceName
OR tgt.CountryName <> src.CountryName
OR tgt.Continent <> src.Continent
OR tgt.SalesTerritory <> src.SalesTerritory
OR tgt.Region <> src.Region
OR tgt.Subregion <> src.Subregion
) THEN
UPDATE
SET
tgt.CityID = src.CityID,
tgt.CountryID = src.CountryID,
tgt.StateProvinceID = src.StateProvinceID,
tgt.CityName = src.CityName,
tgt.StateProvinceName = src.StateProvinceName,
tgt.CountryName = src.CountryName,
tgt.Continent = src.Continent,
tgt.SalesTerritory = src.SalesTerritory,
tgt.Region = src.Region,
tgt.Subregion = src.Subregion
WHEN NOT MATCHED THEN
INSERT
(
CityID,
CountryID,
StateProvinceID,
CityName,
StateProvinceName,
CountryName,
Continent,
SalesTerritory,
Region,
Subregion
)
VALUES
(
src.CityID,
src.CountryID,
src.StateProvinceID,
src.CityName,
src.StateProvinceName,
src.CountryName,
src.Continent,
src.SalesTerritory,
src.Region,
src.Subregion
);
ALTER TASK Load_Dim_City RESUME;
//ALTER TASK Load_Dim_City SUSPEND;
CREATE
OR REPLACE TASK Load_Dim_Customer
AFTER
Check_Data_Updates
WHEN SYSTEM$GET_PREDECESSOR_RETURN_VALUE('CHECK_DATA_UPDATES') = 1 AS MERGE INTO Integration.Dim_Customer tgt USING(
SELECT
DISTINCT c.CustomerID,
c.CustomerName,
c.DeliveryPostalCode,
bt.CustomerName as BillToCustomer,
cc.CustomerCategoryName,
bg.BuyingGroupName,
p.FullName as PrimaryContact,
bg.buyinggroupid,
cc.customercategoryid,
p.personid
FROM
Landing.vw_customers AS c
INNER JOIN Landing.vw_buyinggroups AS bg ON c.BuyingGroupID = bg.BuyingGroupID
INNER JOIN Landing.vw_customercategories AS cc ON c.CustomerCategoryID = cc.CustomerCategoryID
INNER JOIN Landing.vw_customers AS bt ON c.BillToCustomerID = bt.CustomerID
INNER JOIN Landing.vw_people AS p ON c.PrimaryContactPersonID = p.PersonID
) src ON tgt.CustomerID = src.CustomerID
and tgt.PersonID = src.PersonID
and tgt.BuyingGroupID = src.BuyingGroupID
and tgt.CustomerCategoryID = src.CustomerCategoryID
WHEN MATCHED
AND (
tgt.CustomerName <> src.CustomerName
OR tgt.BillToCustomer <> src.BillToCustomer
OR tgt.CustomerCategoryName <> src.CustomerCategoryName
OR tgt.BuyingGroupName <> src.BuyingGroupName
OR tgt.PrimaryContact <> src.PrimaryContact
OR tgt.DeliveryPostalCode = src.DeliveryPostalCode
) THEN
UPDATE
SET
tgt.CustomerID = src.CustomerID,
tgt.PersonID = src.PersonID,
tgt.BuyingGroupID = src.BuyingGroupID,
tgt.CustomerCategoryID = src.CustomerCategoryID,
tgt.CustomerName = src.CustomerName,
tgt.BillToCustomer = src.BillToCustomer,
tgt.CustomerCategoryName = src.CustomerCategoryName,
tgt.BuyingGroupName = src.BuyingGroupName,
tgt.PrimaryContact = src.PrimaryContact,
tgt.DeliveryPostalCode = src.DeliveryPostalCode
WHEN NOT MATCHED THEN
INSERT
(
CustomerID,
PersonID,
BuyingGroupID,
CustomerCategoryID,
CustomerName,
BillToCustomer,
CustomerCategoryName,
BuyingGroupName,
PrimaryContact,
DeliveryPostalCode
)
VALUES
(
src.CustomerID,
src.PersonID,
src.BuyingGroupID,
src.CustomerCategoryID,
src.CustomerName,
src.BillToCustomer,
src.CustomerCategoryName,
src.BuyingGroupName,
src.PrimaryContact,
src.DeliveryPostalCode
);
ALTER TASK Load_Dim_Customer RESUME;
//ALTER TASK Load_Dim_Customer SUSPEND;
CREATE
OR REPLACE TASK Load_Dim_Employee
AFTER
Check_Data_Updates
WHEN SYSTEM$GET_PREDECESSOR_RETURN_VALUE('CHECK_DATA_UPDATES') = 1 AS MERGE INTO Integration.Dim_Employee tgt USING(
SELECT
DISTINCT p.personid,
p.fullname,
p.preferredname,
p.issalesperson
FROM
Landing.vw_people AS p
WHERE
IsEmployee != 0
) src ON tgt.EmployeeID = src.personid
WHEN MATCHED
AND (
tgt.preferredname <> src.preferredname
OR tgt.IsSalesPerson <> src.IsSalesPerson
OR tgt.Employee <> src.FullName
) THEN
UPDATE
SET
tgt.preferredname = src.preferredname,
tgt.IsSalesPerson = src.IsSalesPerson,
tgt.Employee = src.FullName
WHEN NOT MATCHED THEN
INSERT
(
EmployeeId,
Employee,
PreferredName,
IsSalesPerson
)
VALUES
(
src.personid,
src.fullname,
src.preferredname,
src.issalesperson
);
ALTER TASK Load_Dim_Employee RESUME;
//ALTER TASK Load_Dim_Employee SUSPEND;
CREATE
OR REPLACE TASK Load_Dim_StockItem
AFTER
Check_Data_Updates
WHEN SYSTEM$GET_PREDECESSOR_RETURN_VALUE('CHECK_DATA_UPDATES') = 1 AS MERGE INTO Integration.Dim_StockItem tgt USING(
SELECT
distinct si.StockItemID,
spt.PackageTypeId AS SellingPackageID,
bpt.PackageTypeId AS BuyingPackageId,
si.StockItemName,
spt.PackageTypeName as SellingPackage,
bpt.PackageTypeName as BuyingPackage,
COALESCE(si.Brand, 'N/A') as Brand,
COALESCE(si.Size, 'N/A') as Size,
si.QuantityPerOuter,
si.IsChillerStock,
COALESCE(si.Barcode, 'N/A') as BarCode,
si.LeadTimeDays,
si.UnitPrice,
si.RecommendedRetailPrice,
si.TypicalWeightPerUnit //c.colorid
FROM
Landing.vw_StockItems AS si
INNER JOIN Landing.vw_PackageTypes AS spt ON si.UnitPackageID = spt.PackageTypeID
INNER JOIN Landing.vw_PackageTypes AS bpt ON si.OuterPackageID = bpt.PackageTypeID //LEFT OUTER JOIN Landing.vw_Colors AS c ON si.ColorID = c.ColorID
) src ON tgt.StockItemID = src.StockItemID
AND tgt.SellingPackageId = src.SellingPackageId
AND tgt.BuyingPackageId = src.BuyingPackageId
WHEN MATCHED
AND (
tgt.StockItemName <> src.StockItemName
OR tgt.SellingPackage <> src.SellingPackage
OR tgt.BuyingPackage <> src.BuyingPackage
OR tgt.Brand <> src.Brand
OR tgt.Size <> src.Size
OR tgt.LeadTimeDays <> src.LeadTimeDays
OR tgt.QuantityPerOuter <> src.QuantityPerOuter
OR tgt.IsChillerStock <> src.IsChillerStock
OR tgt.Barcode <> src.Barcode
OR tgt.RecommendedRetailPrice <> src.RecommendedRetailPrice
OR tgt.TypicalWeightPerUnit <> src.TypicalWeightPerUnit
OR tgt.UnitPrice <> src.UnitPrice
) THEN
UPDATE
SET
tgt.StockItemID = src.StockItemID,
tgt.StockItemName = src.StockItemName,
tgt.SellingPackage = src.SellingPackage,
tgt.BuyingPackage = src.BuyingPackage,
tgt.Brand = src.Brand,
tgt.Size = src.Size,
tgt.LeadTimeDays = src.LeadTimeDays,
tgt.QuantityPerOuter = src.QuantityPerOuter,
tgt.IsChillerStock = src.IsChillerStock,
tgt.Barcode = src.Barcode,
tgt.UnitPrice = src.UnitPrice,
tgt.RecommendedRetailPrice = src.RecommendedRetailPrice,
tgt.TypicalWeightPerUnit = src.TypicalWeightPerUnit
WHEN NOT MATCHED THEN
INSERT
(
StockItemID,
SellingPackageId,
BuyingPackageId,
StockItemName,
SellingPackage,
BuyingPackage,
Brand,
Size,
LeadTimeDays,
QuantityPerOuter,
IsChillerStock,
Barcode,
UnitPrice,
RecommendedRetailPrice,
TypicalWeightPerUnit
)
VALUES
(
src.StockItemID,
src.SellingPackageId,
src.BuyingPackageId,
src.StockItemName,
src.SellingPackage,
src.BuyingPackage,
src.Brand,
src.Size,
src.LeadTimeDays,
src.QuantityPerOuter,
src.IsChillerStock,
src.Barcode,
src.UnitPrice,
src.RecommendedRetailPrice,
src.TypicalWeightPerUnit
);
ALTER TASK Load_Dim_StockItem RESUME;
//ALTER TASK Load_Dim_StockItem SUSPEND;
CREATE
OR REPLACE TASK Load_Fact_Order
AFTER
Load_Dim_Date,
Load_Dim_StockItem,
Load_Dim_City,
Load_Dim_Customer,
Load_Dim_Employee AS
INSERT INTO
Integration.Fact_Order(
Order_ID,
Backorder_ID,
Description,
Quantity,
Unit_Price,
Tax_Rate,
Total_Excluding_Tax,
Tax_Amount,
Total_Including_Tax,
City_Key,
Customer_Key,
Stock_Item_Key,
Order_Date_Key,
Picked_Date_Key,
Salesperson_Key,
Picker_Key
)
SELECT
o.OrderID AS OrderID,
o.BackorderOrderID AS BackorderID,
ol.Description,
ol.Quantity AS Quantity,
ol.UnitPrice AS UnitPrice,
ol.TaxRate AS TaxRate,
ROUND(ol.Quantity * ol.UnitPrice, 2) AS TotalExcludingTax,
ROUND(
ol.Quantity * ol.UnitPrice * ol.TaxRate / 100.0,
2
) AS TaxAmount,
ROUND(ol.Quantity * ol.UnitPrice, 2) + ROUND(
ol.Quantity * ol.UnitPrice * ol.TaxRate / 100.0,
2
) AS TotalIncludingTax,
dci.citykey as CityKey,
COALESCE(dcu.customerkey, -1) as CustomerKey,
si.stockitemkey as StockItemKey,
dt1.date_key AS OrderDateKey,
dt2.date_key AS PickedDateKey,
de1.employeekey as SalesPersonKey,
de2.employeekey as Picker_Key
FROM
Landing.vw_Orders AS o
INNER JOIN Landing.vw_OrderLines AS ol ON o.OrderID = ol.OrderID
INNER JOIN Landing.vw_customers c ON o.customerid = c.customerid
INNER JOIN Integration.Dim_Date dt1 ON COALESCE(
CAST(
TO_VARCHAR(DATE_TRUNC('DAY', o.orderdate::date), 'YYYYMMDD') AS INTEGER
),
99991231
) = dt1.date_key
INNER JOIN Integration.Dim_Date dt2 ON COALESCE(
CAST(
TO_VARCHAR(
DATE_TRUNC('DAY', ol.pickingcompletedwhen::date),
'YYYYMMDD'
) AS INTEGER
),
99991231
) = dt2.date_key
LEFT JOIN Integration.Dim_Customer dcu on COALESCE(c.customerid, -1) = dcu.customerid
LEFT JOIN Integration.Dim_City dci on COALESCE(c.deliverycityid, -1) = dci.cityid
LEFT JOIN Integration.Dim_Employee de1 on COALESCE(o.salespersonpersonid, -1) = de1.employeeid
LEFT JOIN Integration.Dim_Employee de2 on COALESCE(o.pickedbypersonid, -1) = de2.employeeid
LEFT JOIN Integration.Dim_StockItem si on COALESCE(ol.stockitemid, -1) = si.stockitemid
WHERE
NOT EXISTS (
SELECT
1
FROM
Integration.Fact_Order f
WHERE
f.Order_ID = o.OrderID
);
ALTER TASK Load_Fact_Order RESUME;
//ALTER TASK Load_Fact_Order SUSPEND;
ALTER TABLE WWIDW.Integration.DIM_CITY
ADD CONSTRAINT pk_dim_city_city_key PRIMARY KEY(CITYKEY);
ALTER TABLE WWIDW.Integration.Fact_Order
ADD CONSTRAINT FK_Fact_Order_City_Key_Dimension_City FOREIGN KEY(City_Key)
REFERENCES Dim_City (CityKey) NOT ENFORCED;
ALTER TABLE WWIDW.Integration.DIM_CUSTOMER
ADD CONSTRAINT pk_dim_customer_customer_key PRIMARY KEY(CUSTOMERKEY);
ALTER TABLE WWIDW.Integration.Fact_Order
ADD CONSTRAINT FK_Fact_Order_Customer_Key_Dimension_Customer FOREIGN KEY(Customer_Key)
REFERENCES Dim_Customer (CustomerKey) NOT ENFORCED;
ALTER TABLE WWIDW.Integration.DIM_STOCKITEM
ADD CONSTRAINT pk_dim_stockitem_stock_item_key PRIMARY KEY(STOCKITEMKEY);
ALTER TABLE WWIDW.Integration.Fact_Order
ADD CONSTRAINT FK_Fact_Order_Stock_Item_Key_Dimension_Stock_Item FOREIGN KEY(Stock_Item_Key)
REFERENCES Dim_StockItem (StockItemKey) NOT ENFORCED;
ALTER TABLE WWIDW.Integration.DIM_EMPLOYEE
ADD CONSTRAINT pk_dim_employee_employee_key PRIMARY KEY(EMPLOYEEKEY);
ALTER TABLE WWIDW.Integration.Fact_Order
ADD CONSTRAINT FK_Fact_Order_Salesperson_Key_Dimension_Employee_Employee_Key FOREIGN KEY(SALESPERSON_KEY)
REFERENCES Dim_Employee (EmployeeKey) NOT ENFORCED;
ALTER TABLE WWIDW.Integration.Fact_Order
ADD CONSTRAINT FK_Fact_Order_Picker_Key_Dimension_Employee_Employee_Key FOREIGN KEY(PICKER_KEY)
REFERENCES Dim_Employee (EmployeeKey) NOT ENFORCED;
ALTER TABLE WWIDW.Integration.DIM_DATE
ADD CONSTRAINT pk_dim_date_date_key PRIMARY KEY(DATE_KEY);
ALTER TABLE WWIDW.Integration.Fact_Order
ADD CONSTRAINT FK_Fact_Order_Picked_Date_Dimension_Date_Key FOREIGN KEY(PICKED_DATE_KEY)
REFERENCES Dim_Date (Date_Key) NOT ENFORCED;
ALTER TABLE WWIDW.Integration.Fact_Order
ADD CONSTRAINT FK_Fact_Order_Order_Date_Dimension_Date_Key FOREIGN KEY(ORDER_DATE_KEY)
REFERENCES Dim_Date (Date_Key) NOT ENFORCED;
When this pipeline is run, the following execution log gets generated and visualized. We can see that the initial data changes validation Task is set to run every minute, and when source data was refreshed at around 9.17am, the condition logic determining the rest of pipeline execution was triggered by the return value change (from 0 to 1), thus initiating the rest of the pipeline execution.
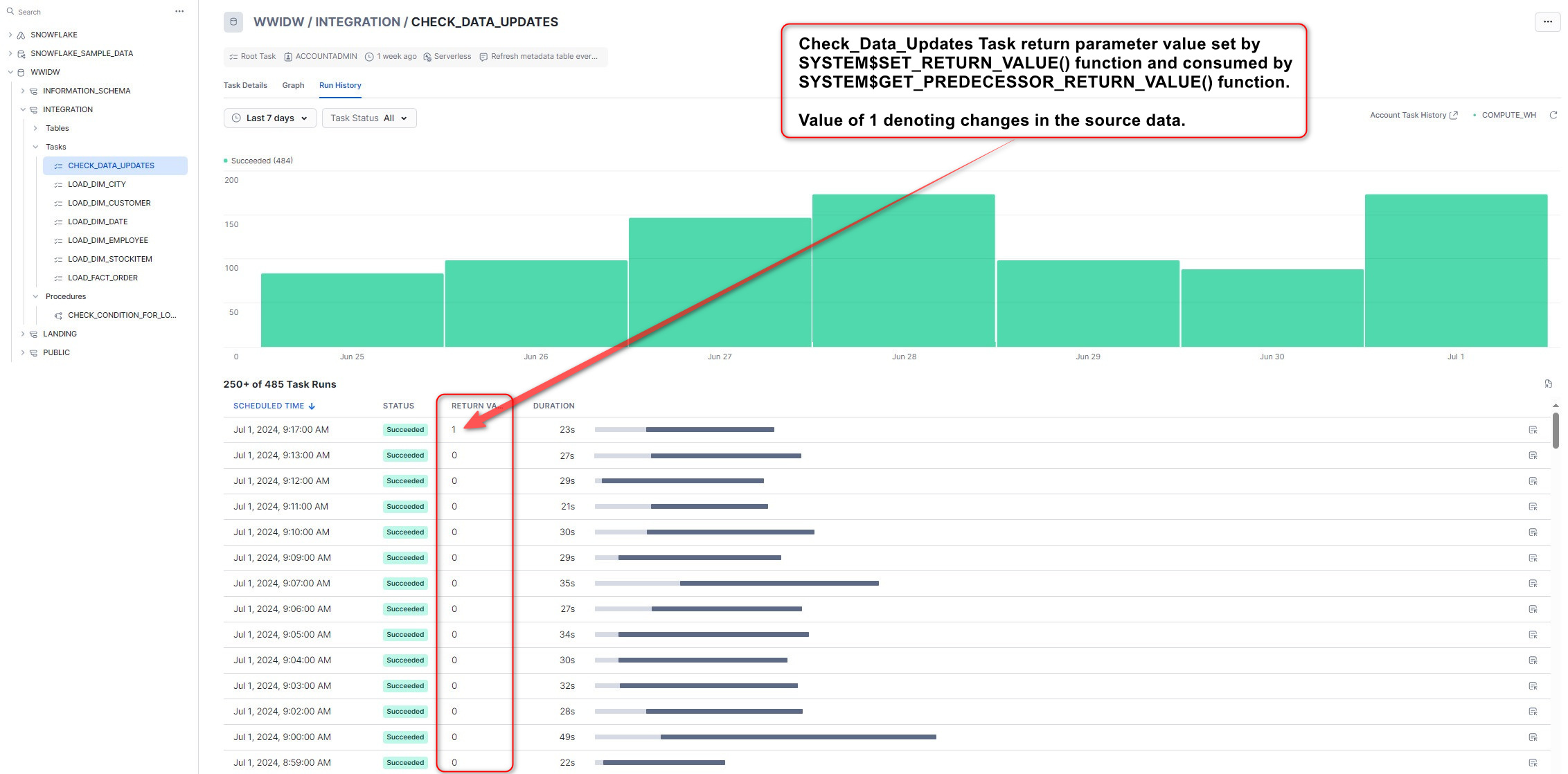
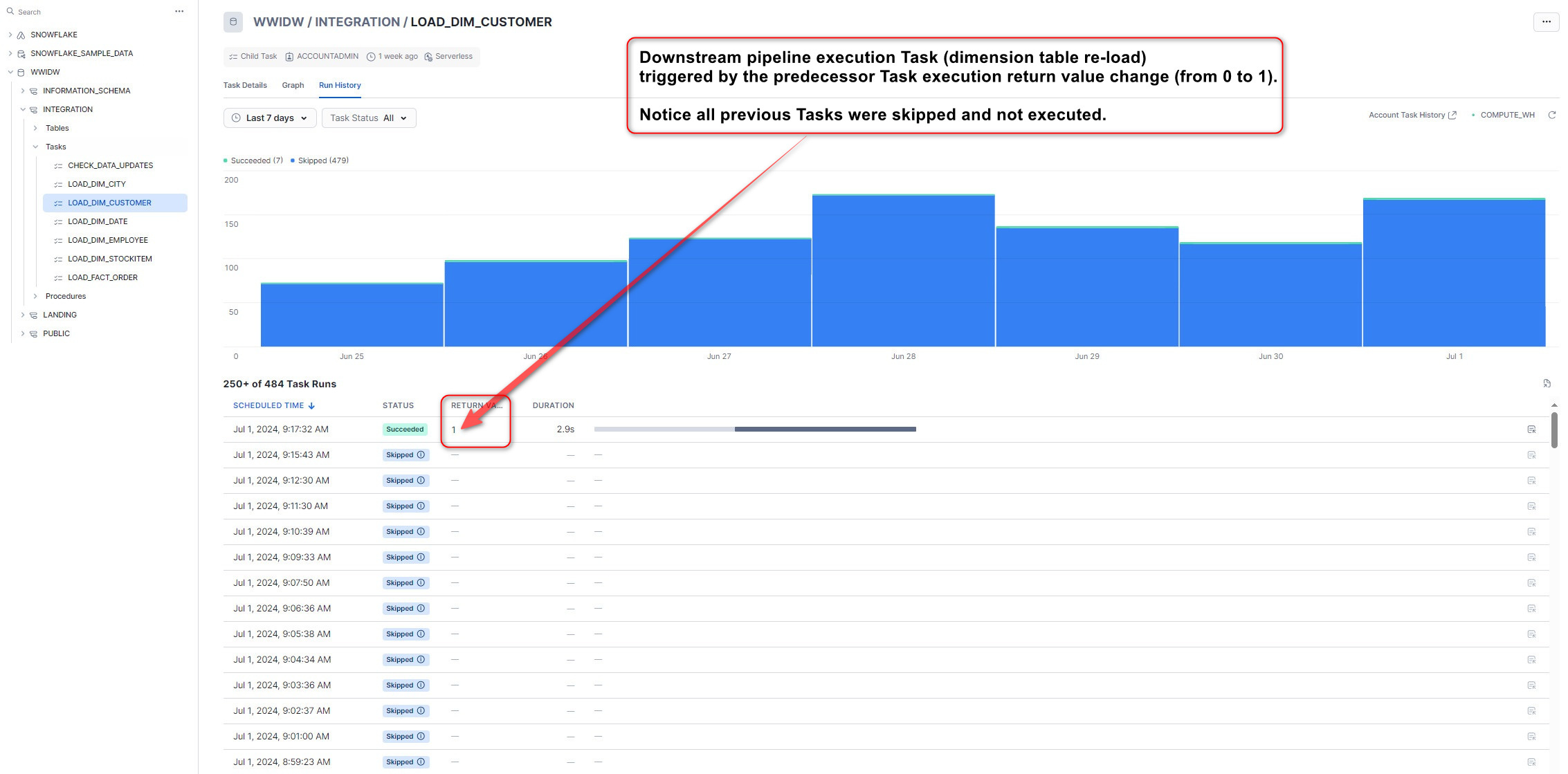
Data Reconciliation and Testing
Snowflake maintains task history for 7 days in system views which can be accessed from the information_management schema or using a number of table-valued functions. In the event of a failure, SYSTEM$SEND_EMAIL() system function can be used to send out altert emails to notify operators of potential issues. However, if this information is required to be exposed in SQL Server e.g. to reconcile ingested data sets in Snowflake metadata against file system files generated as part of the extract and upload process, it’s also possible to link Snowflake account to SQL Server via Linked Server connection and source system DSN entry using Snowflake-provided ODBC driver. The process of creating Linked Server connection has previously been documented HERE and once provisioned and active, all Snowflake’s metadata can be exposed using OPENQUERY SQL statements directly from SQL Server instance. The following two statements query data in Snowflake and WWI local SQL database, comparing their content (using EXCEPT SQL statement) as well as query Snowflake metadata to extract Task executions history.
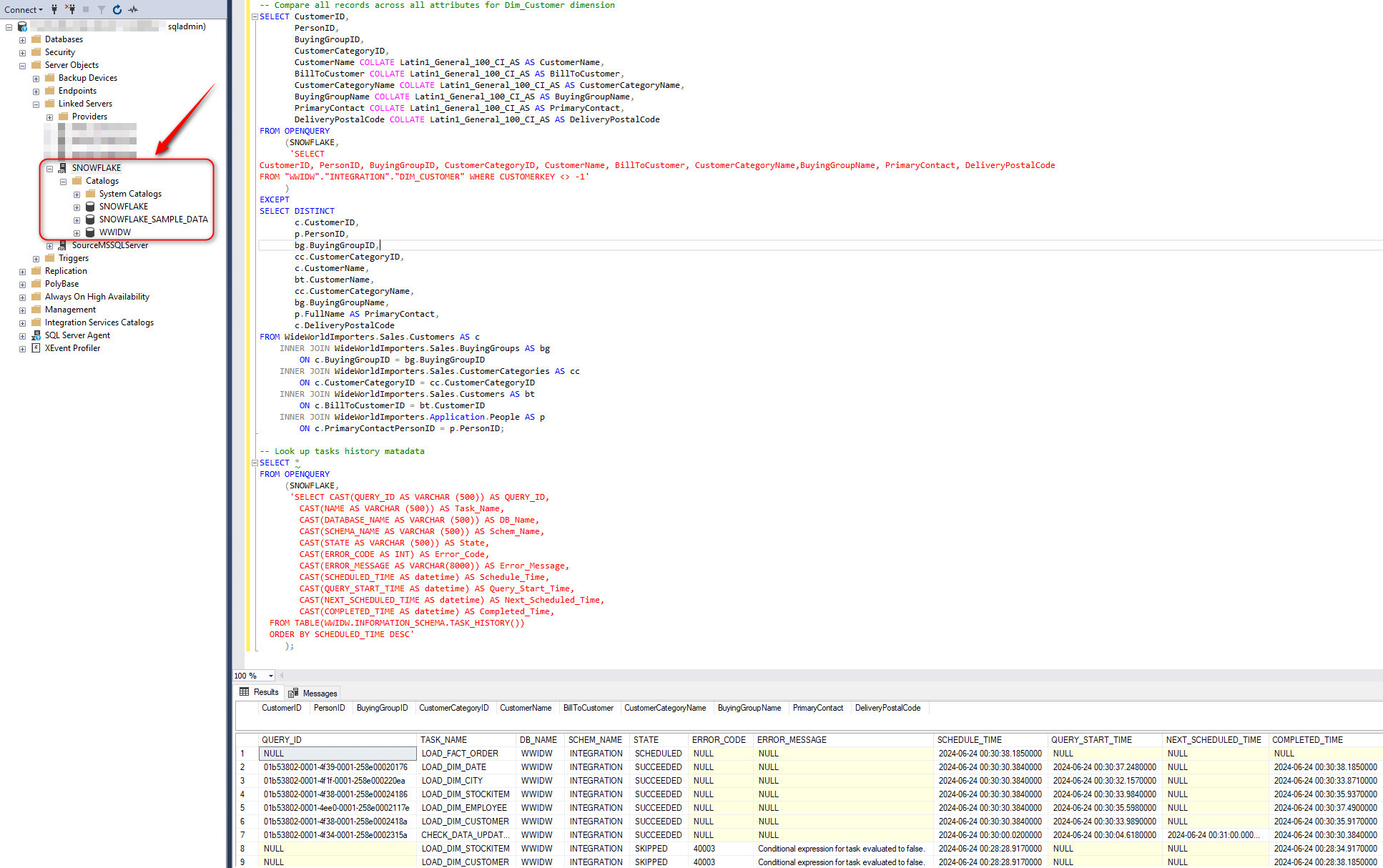
Conclusion
So there you go, we’ve built a complete data acqusition and processing pipeline using SQL Server WWI database as a source and Snowflake WWIDW database as a sink, including Azure ADLS as a flat files staging layer. There are many different ways to approach architecting and developing a solution like this e.g. one could look into using Data Factory for data extraction or Snowflake dynamics tables for more streamlined loading process so feel free to experiment and change things around. Aftearall, this is just a blueprint and both Microsoft and Snowflake offer a multitude of different architecture patterns for any scope and requirements. It just goes to show we live in exciting times and information management on many of these platforms is full of opportunities and exciting discoveries.


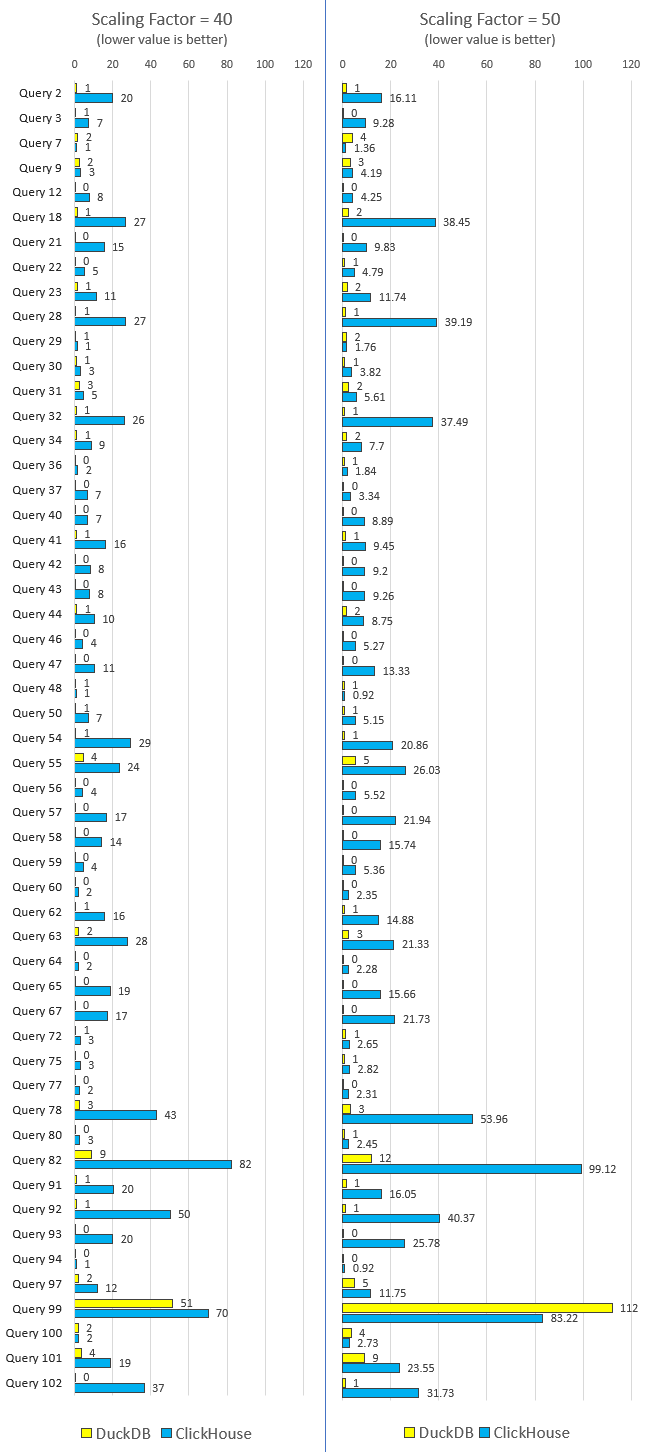



Not sure about Polars but I did take ClickHouse (chDB) and DuckDB for a quick test drive - you can…