If you an avid Microsoft SQL Server database user and/or had a chance to work with SQL Server 2012 version and its new indexing options, you’ve probably heard of columnstore index concept. Columnstore index, first introduced in SQL Server 2012, stores data in columnar fashion (unlike the traditional B-tree structures used for clustered and non-clustered rowstore indexes) to speed-up the processing time of common data warehousing queries. Typical data warehousing workloads involve summarizing large amounts of data. The techniques typically used in data warehousing and decision support systems to improve performance are pre-computed summary tables, indexed views or OLAP cubes. Although these can greatly speed up query processing, they can also prove inflexible, difficult to maintain, must be designed specifically for each query problem and require certain level of OLAP expertise. Leveraging their existing SQL skills, developers and DBAs can now achieve near OLAP-like performance by means of utilising columnstore indexes. A columnstore index organizes the data in individual columns that are joined together to form the index. This structure can offer significant performance gains for queries that summarize large quantities of data, the sort typically used for business intelligence (BI) and data warehousing.
Architecture and Performance Testing
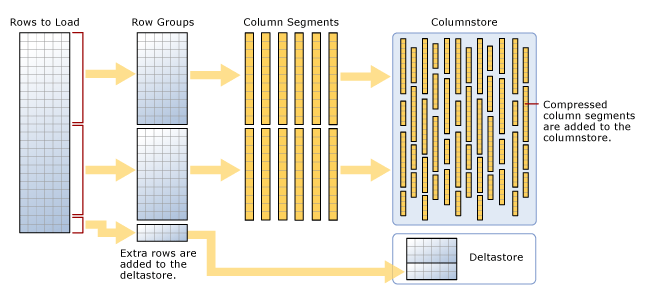
Just like a normal clustered index, a clustered columnstore index defines how the data is physically stored on the disc. A columnstore backed table is initially organized into segments known as row groups. Each rowgroup holds from 102,400 to 1,048,576 rows. Once a rowgroup is identified it is broken up into column segments, which are then compressed and inserted into the actual columnstore. When dealing with small amounts of data, small being defined as less than a hundred thousand rows, the data is staged in a section known as the deltastore. Once it reaches the minimum size the deltastore can be drained, its data being processed as a new rowgroup. This is depicted in the MSDN diagram below.
A deltastore will be closed while it is being converted. This, however, is not a blocking operation for the table as a whole. An additional deltastore can be created for a given table when the current deltastores are unavailable due to locking. And if the table is partitioned, then each partition gets its own set of deltastores.
Columnstore indexes are not the panacea for all potential performance issues. While it’s possible to build a system that stores all data in columnar format, row stores still have advantages in some situations. A B-tree is a very efficient data structure for looking up or modifying a single row of data. So if your workload entails many single row lookups and many updates and deletes, which is common for OLTP workloads, you will probably continue to use row store technology. Data warehouse workloads typically scan, aggregate, and join large amounts of data. In those scenarios, column stores really shine.
Let’s look at some performance gains which can be achieved by using columnstore index technology. For the purpose of this demonstration I used a couple of text files (all files and SQL queries for this presentation can be downloaded from HERE) holding the subset of data I intend to load into my tables. These files have been placed in a folder on my c:\ drive and their data loaded into a ‘sandbox’ database for performance testing. I also ‘stretched out’ one of the tables to take advantage of much larger volume of data to run a few test queries, comparing execution times between tables with ‘classic’ b-tree indexes vs. columnstore indexes. Again, all scripts used in this presentation as well as additional files can be downloaded from HERE.
The quick video footage below demonstrates the process of test environment preparation as well as all performance tests executed with their corresponding results. At the very last moment I also decided to include some rudimentary data I managed to collect regarding table compression efficiency (by the way, great achievement by SQL Server team at MSFT!) when implemented using a columnstore index. Enjoy and leave me a comment if you find it useful or otherwise!
In the FIRST installment to this series I briefly outlined the environment setup as well as Redshift data loading process. This was followed by my SECOND post where I analyzed performance findings when comparing query execution times on 4 different environments. In this post I would like to explore Redshift database connectivity options for data visualization applications – Tableau and Microsoft Excel – as well as provide a brief summary of my experience with Redshift up until this point.
Microsoft Excel
Let’s start with the venerable Excel. There is probably no tool on the market which can beat Excel for its popularity, functionality and number of users who have had some experience with it. It is the love child of many corporate departments and a staple, go-to application when impromptu analysis and visualisation is required. Furthermore, with the latest release of Excel 2013 it has an added benefit of creating fancy dashboards or geospatial mappings using plugins such as PowerMap and PowerView with relative ease.
Connecting to Redshift via Excel is quite straightforward. As I do not want to repeat the step-by-step details on how to link your spreadsheet to Redshift data source – someone else has already done it for me – I will just post a link to the webpage where this information can be found. Under this LINK you will find comprehensive tutorial on how to achieve this. Alternatively, in case the link is no longer valid, head over to my SkyDrive folder HERE where among other files I saved a screen dump as an image file.
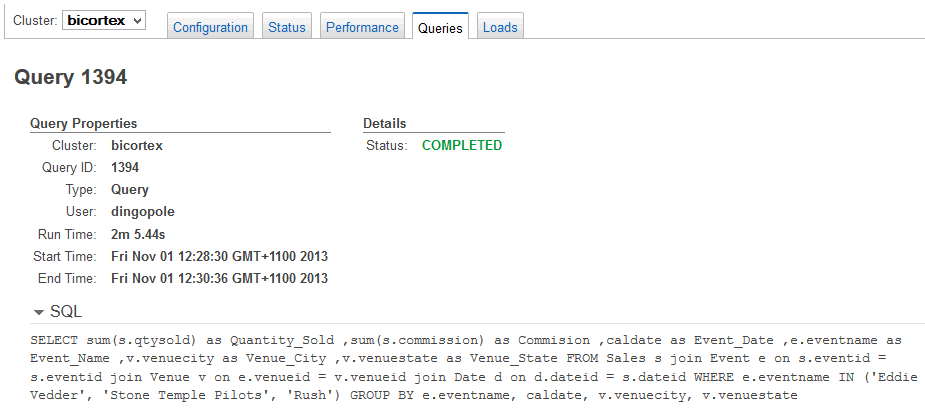
In order to visualize data stored in Redshift, I used the following two SQL queries returning aggregated results running on a multi-node deployment (2 nodes) on High Storage Extra Large (XL) DW instance.
SELECT
SUM(s.qtysold) as Quantity_Sold
,SUM(s.commission) as Commision
,caldate as Event_Date
,e.eventname as Event_Name
,v.venuecity as Venue_City
,v.venuestate as Venue_State
FROM Sales s
join Event e on s.eventid = s.eventid
join Venue v on e.venueid = v.venueid
join Date d on d.dateid = s.dateid
WHERE e.eventname IN ('Eddie Vedder', 'Stone Temple Pilots', 'Rush')
GROUP BY e.eventname, caldate,
v.venuecity, v.venuestate
SELECT
SUM(s.pricepaid) as Price_Paid,
d.day as Sales_Date,
e.eventname as Event_Name,
u1.city as City,
u1.state as State
FROM
sales s join users u1 on u1.userid = s.sellerid
join date d on d.dateid = s.dateid
join event e on s.eventid = e.eventid
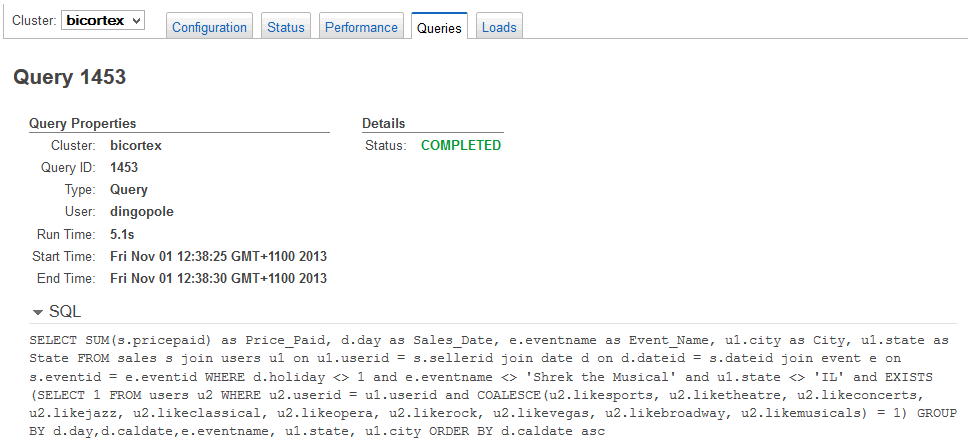
WHERE d.holiday <> 1 and e.eventname <> 'Shrek the Musical' and u1.state <> 'IL' and EXISTS
(SELECT 1
FROM users u2 WHERE u2.userid = u1.userid
and COALESCE(u2.likesports, u2.liketheatre, u2.likeconcerts, u2.likejazz, u2.likeclassical,
u2.likeopera, u2.likerock, u2.likevegas, u2.likebroadway, u2.likemusicals) = 1)
GROUP BY
d.day,d.caldate,e.eventname, u1.state, u1.city
ORDER BY d.caldate ASC
On connection imported data from two queries above into my worksheets to observe cluster’s performance during execution. I wasn’t looking for anything specific and no particular variables were taken into consideration. The aim was simply to determine how flexible and issue-free using Excel as visual output can be as the Redshift front end. During data import, Excel becomes pretty much unresponsive, which depending on the query execution time can be frustrating. The only indication that data is being sourced or waited on was this little message in the bottom pane of the spreadsheet.
Also, in terms of network activity, I recorded fairly minimal traffic, with most of the time spent on waiting for the data to process before the final output.
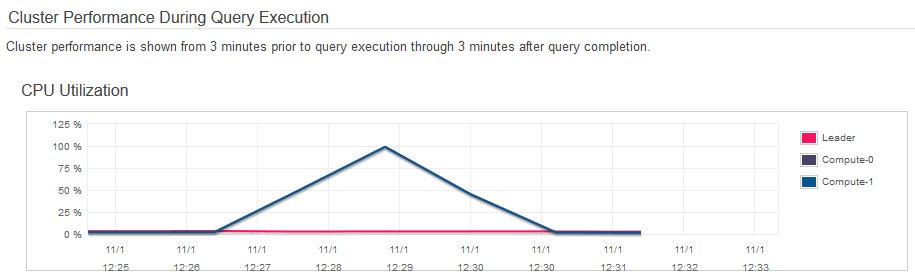
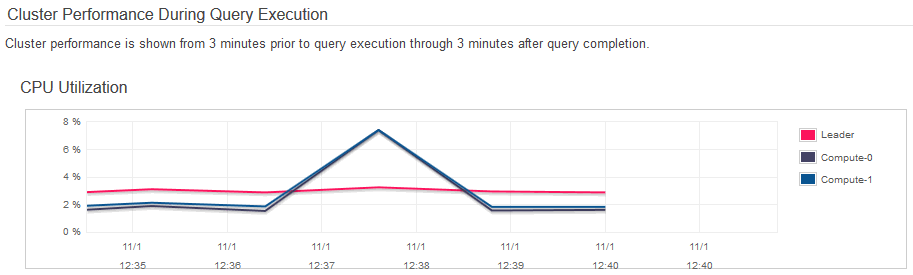
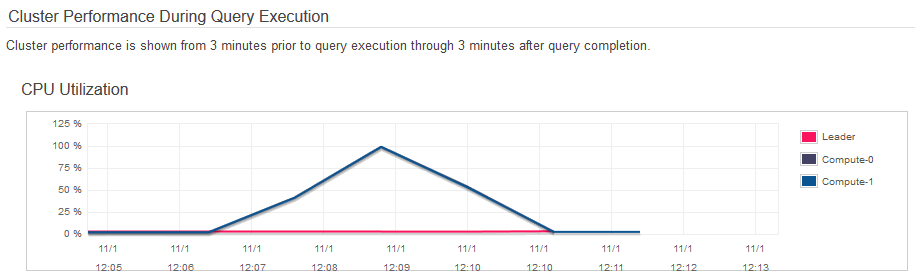
In the case of the first query , SQL code execution time, regardless of the application connecting to Redshift (Excel, SQL Manager, Tableau etc.), was quite long with just over 2 minutes to crunch my sales and commission data from the extended TICKIT database. Also, as you can see from the images below, CPU spiked to 100 percent for a short period of time during query 1 processing.
Things were much snappier with query 2 which took hardly any time to run and populate my worksheet. Also, CPU utilisation was kept below 10 percent for both nodes involved.
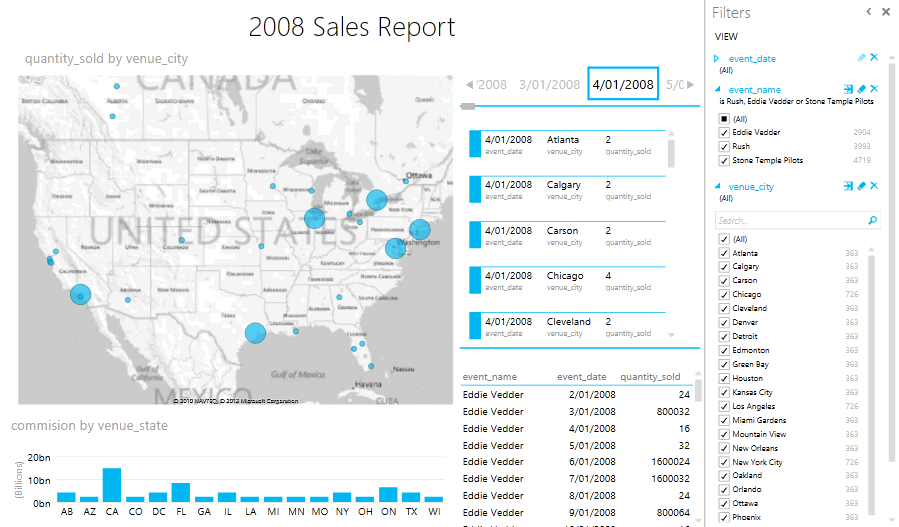
Overall ease of use and flexibility Excel comes with is very good and it literally took me 5 minutes from the moment I run the first query to putting a small Sales dashboard report together (click on image to enlarge).
Tableau
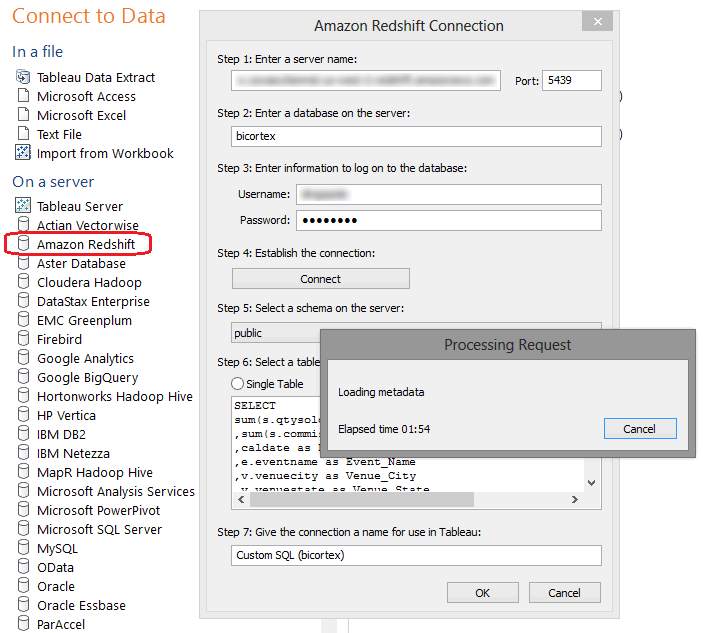
Tableau is quickly becoming the go-to application for rapid data analysis and I can see more and more businesses using it as a primary tool when it comes to visualisation and data exploration. It is also known for its vast connectivity options and Amazon Redshift is also included by default. Connecting to Redshift cluster is quite straightforward – given that Redshift integration is there out-of-the-box, all that’s required is filling in the blanks with authentication credentials and choosing between importing all database objects or running a selective query as per below.
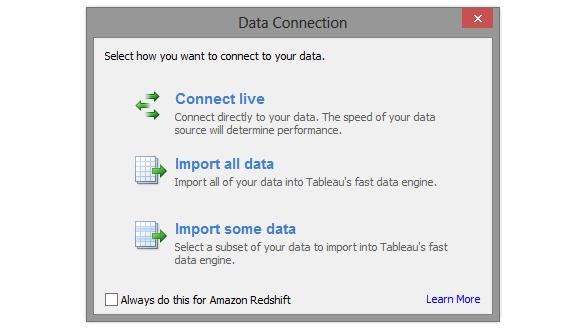
Next, Tableau imports database and objects metadata and provides 3 options for how the data interface between Redshift and the application should be managed – connect live, import all data or import some data.
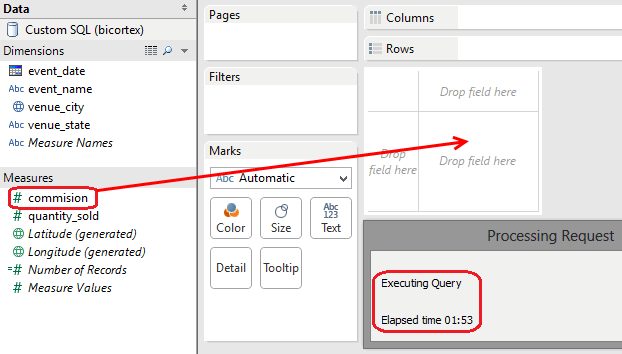
Unfortunately, working with the ‘active connection’ turned out to be quite problematic and only highlights why remotely hosted data warehouse can potentially be a big issue, at least when using Tableau in ‘always connected’ mode. Network latency is not a problem here as only a small subset of data is being returned to the client. Also, I could live with the fact that query execution time can, in some cases, be longer than anticipated thus adding to the increasing frustration. However, I would not be able to put up with a setup which provides the flexibility of real-time data interrogation for the price of great inconvenience and deficiency in how the current architecture is resolved. What I am referring to here is the way Tableau works with data, aggregating, sorting, and manipulating it when conducting the analysis. It appeared to me that, for query 1, for example, which as I have already mentioned took around 2 minutes to process, not only did I have to wait 2 minutes just for the metadata to be returned to the client but each time the application was required to reference the source dataset, additional 2 minutes were wasted for further execution due to lack of adequate optimisation. To explain further, let’s look at the image below outlining creating the initial data analysis sheet.
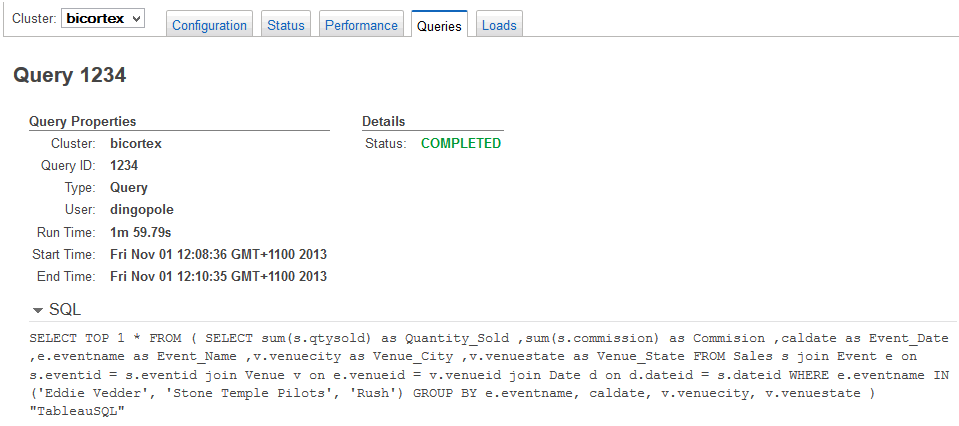
Nearly the same query was executed when attempting to drag ‘commission’ measure onto the summary field as we saw in the case of metadata fetching, which means that every time a new aggregation is created in Tableau, additional 2 minutes were added (read: wasted) for the query to hit Redshift’s processing engine, crunch the data and return it over the network. This means that utilizing live connection to the data source was virtually prohibitive and could severely impact the ‘what was intended as the quick analysis project’ to the point of time-unaffordable lag. Looking at the query which was passed to Redshift from Tableau when trying to summarize ‘commission’ figures I could tell that there’s literally zero optimization done (server catching, local memory staging etc.) to prevent from this inefficient, repetitive ‘SELECT OUT OF SELECT’ execution (see image below).
I can hear you saying that I could always mitigate all those problems by importing all or some data into my local environment. I concur. Given that the datasets are quite small I tried to import all the records and everything worked really well, however, given that Redshift’s primary market is high volume data deployments, I would not be able to stage millions or billions of records on my machine, I wouldn’t even want to. This conundrum proves that even though cloud data warehousing is making strides towards wider audience and higher adoption, there are still some big issues that can render it useless for some specyfic applications.
Working in off-line mode, with all data imported and staged on my local machine the experience was much more rewarding and Tableau was a pleasure to work with.
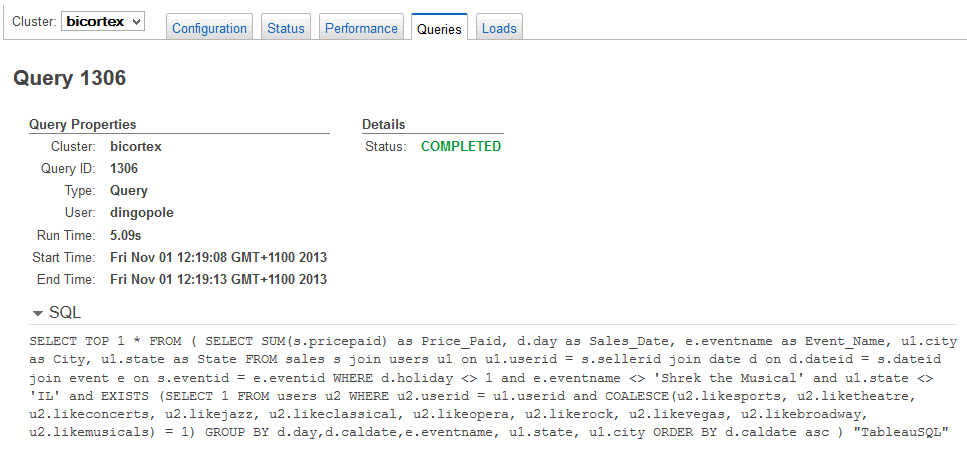
Below are the queries’ CPU performance metrics as well as SQL statements passed for execution. Notice how Tableau formats SQL code with prefixing it with ‘SELECT TOP 1 * FROM…’ statement.
Final Conclusion
So what is the overall verdict on Amazon Redshift? In my books, even though the product is still rough around the edges and a bit more polish and finesse needs to be applied here and there, Redshift is a real deal. It performs very well, is easy to provision and manage, it has good connectivity options and the price is competitive. I would never though that I could deploy such a powerful architecture on an impromptu basis, perform my analysis and scrap it – all within less than one hour with the price paid cheaper than a cup of coffee. On one hand, this is a welcomed development as it has never been so easy and inexpensive to process huge volumes of data with minimal input. No longer does one need to pay for exorbitant licensing costs, employ legions of DBAs and system administrators or have a very good handle on the esoteric subjects or database programming and administration. Such deployment takes away most of the cost, human input and associated complexities thus empowering end users and making such technologies accessible to a wider audience. At the same time, it’s not the elusive real life unicorn of the data warehousing world and it won’t solve all your BI problems. With all its benefits and advantages revolving primarily around speed and cost, it does not support many common database features, your data is stored in the cloud (encrypted or not) which can pose security issues for some, more tightly regulated workshops and finally, its management flexibility is still on the “I wish I could do such and such…” side. Throw in data latency issues with many businesses still operating on barely adequate internet speed and somewhat inferior analytical applications support when working with ‘live’ data and the whole concepts can lose its shine pretty quickly. Moreover, I can anticipate that some IT professionals will be reluctant to recommend such solution to their managers in fear of falling into obsolescence. Quoting my unenthusiastic friend, ‘the fond years of database administrators being the center of all business activities are slowly getting reduced to documentation management, mostly taking away the mental challenge and hard-core problem solving opportunities’. I would imagine that many professionals who can slowly feel the ‘cloud pinch’ will boycott (at least initially) the business transition to such technology, foreseeing their demise if no skills adjustments are made on their part. I may be overdramatising here but regardless of what your attitude is, cloud data warehousing is here to stay and Amazon Redshift is a perfect example of how fast, cheap, scalable and manageable such technology could be. From my point of view, given you have a problem which definition can fit into its capabilities, Redshift is a force to be reckoned for other vendors and a powerful and cost effective solution for those who manage and use it.
My name is Martin and this site is a random collection of recipes and reflections about various topics covering information management, data engineering, machine learning, business intelligence and visualisation plus everything else that I fancy to categorise under the 'analytics' umbrella. I'm a native of Poland but since my university days I have lived in Melbourne, Australia and worked as a DBA, developer, data architect, technical lead and team manager. My main interests lie in both, helping clients in technical aspects of information management e.g. data modelling, systems architecture, cloud deployments as well as business-oriented strategies e.g. enterprise data solutions project management, data governance and stewardship, data security and privacy or data monetisation. On the whole, I am very fond of anything closely or remotely related to data and as long as it can be represented as a string of ones and zeros and then analysed and visualised, you've got my attention!
Outside sporadic updates to this site I typically find myself fiddling with data, spending time with my kids or a good book, the gym or watching a good movie while eating Polish sausage with Zubrowka (best served on rocks with apple juice and a lime twist). Please read on and if you find these posts of any interests, don't hesitate to leave me a comment!







Never thought Polybase could be used in this capacity and don't think Microsoft advertised this feature (off-loading DB data as…