Kicking the Tires on Azure SQL Database External REST Endpoints – Sample Integration Solution Architecture
June 8th, 2023 / 4 Comments » / by admin
Introduction
SQL Server in-database REST API integration was always roll-your-own, bubble gum and duct tape type of affair – it was possible but never easy. Some may argue it’s for all the right reasons as imposing strict distinction between database and application layers created a well-defined separation of concerns and delegated the former to do one thing and one thing only – data storage and management. However, as vendors’ competition increased, more innovative features were added to and around these platforms to expand their capabilities and accessibility – new formats e.g. Apache Arrow, new Machine Learning features e.g. vector support or even new ways of merging applications and data storage paradigms e.g. WebAssembly-compiled (in-browser) RDBMS. As such, the word database, though synonymous with its primary function of data storage and management, has taken on a new meaning and with that, as set of new capabilities as partly discussed in the post.
Azure SQL Database external REST endpoint integration has not long ago come out of Public Preview and represents an improved way to natively (to Azure ecosystem) query REST API endpoints with little fuss. External REST Endpoint Invocation makes it possible for developers to call REST/GraphQL endpoints from other Azure Services from right within the Azure SQL Database. With a quick call to sp_invoke_external_rest_endpoint system stored procedure, you can have data processed via an Azure Function, update a PowerBI dashboard, or even talk to Cognitive Service or OpenAI.
For a full list of supported services, you can peruse Microsoft documentation but in order to explore real-world application of this functionality, let’s build a simple solution and see how easy or difficult it is to put it to work.
Example Architecture and Use Case Scenario
Let’s assume that we have a telephone conversations data arriving in Azure Blob Storage as a JSON file. Next, we’d like to persist it in our SQL database in near real time and enrich it with sentiment analysis data using Azure Cognitive Services. Additionally, if the sentiment is negative, perhaps indicating customer complaint or dissatisfaction, we would like an email sent to a member of a customer service team to triage and follow up on.
The following diagram (click on image to enlarge) represent a proposed solution architecture behind this requirement, with emphasis on activities number 3, 6 and 9 as these correspond to using SQL Server sp_invoke_external_rest_endpoint system stored procedure to communicate with external services. The idea here is that SQL Server engine can act a connecting tissue for most of integration work, allowing simple workflows to be built and executed directly from the underlying database. And, as you will see, most of this functionality can be achieved using vanilla T-SQL with a combination of stored procedures and triggers, something which was very difficult to solution before this feature was made available.
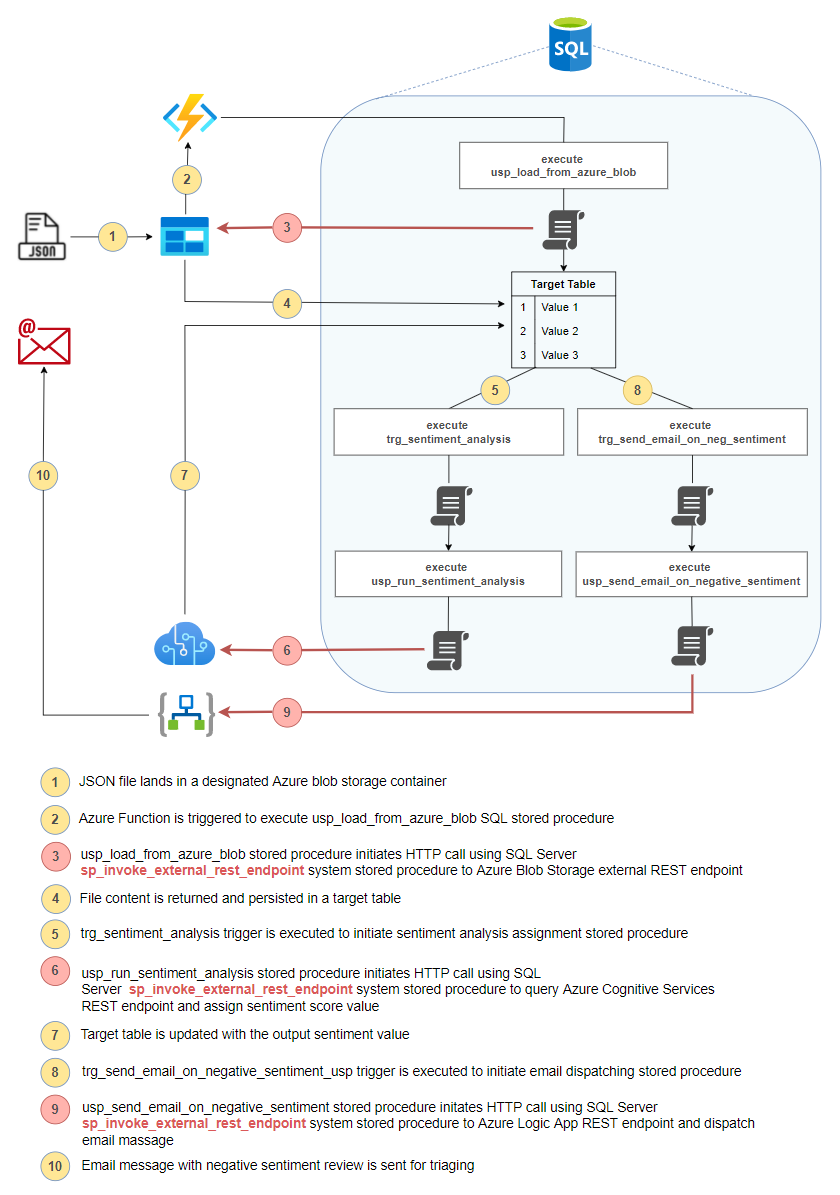
Also, please note that I do not advocate for building high-volume, high-velocity, real-time pipelines using database triggers and SQL Server system stored procedures. Microsoft clearly outlines limits imposed on throttling for the number of concurrent connections to external endpoints as well as limitations in the HTTP request and response payload supported media types and size, URL length, header size etc., so it’s clearly not a panacea for all your integration needs. However, for sporadic and limited use cases – think in-database Zapier – this can significantly cut development time and allow DBAs and database devs to reach into other corners of Azure ecosystem with little fuss.
Solution Implementation
To start with, we need Azure Storage Account with the input container to store our incoming JSON files. Once we have one created, we can develop a small Azure Function which executes on blob being persisted in the target location and executes Azure SQL Database stored procedure responsible for data acquisition. The following is a small Python script calling our first stored procedure – usp_load_from_azure_blob – every time a new blob is created. For simplicity’s sake, the code does not do any file schema validation or pre-processing and its sole role is to execute SQL Server stored procedure.
import logging
import pyodbc
import azure.functions as func
from os import path
# For demo only - any cryptographic keys should be stored in Secrets Store e.g. Azure Key Vault!
_SQL_SERVER = 'Your_Azure_Server_Name'
_SQL_DB = 'Your_Your_DB_Name'
_USERNAME = 'Your_DB_User_Name'
_PASSWORD = 'Your_DB_User_Name_Password'
_DRIVER = '{ODBC Driver 18 for SQL Server}'
_TARGET_TABLE_NAME = 'customer_interactions'
_TARGET_SCHEMA_NAME ='dbo'
_TARGET_STORED_PROC_NAME = 'usp_load_from_azure_blob'
def main(inputblob: func.InputStream):
logging.info('Python blob trigger function processed blob {blob_name}'.format(blob_name = inputblob.name))
try:
cnxn = pyodbc.connect('DRIVER='+_DRIVER+';SERVER='+_SQL_SERVER +
';PORT=1433;DATABASE='+_SQL_DB+';UID='+_USERNAME+';PWD='+_PASSWORD)
if cnxn:
logging.info('Connection to {mssql} SQL Server succeeded!'.format(mssql=SQL_SERVER))
except pyodbc.Error as e:
sqlstate = e.args[1]
logging.error(
sqlstate)
if cnxn:
logging.info('Executing {stored_proc} stored procedure...'.format(stored_proc=_TARGET_STORED_PROC_NAME))
cursor = cnxn.cursor()
sql = '''\
DECLARE @Return_Code INT;
EXEC @Return_Code = {stored_proc} ?,?,?;
SELECT @Return_Code AS rc;'''.format(stored_proc = _TARGET_STORED_PROC_NAME)
values = (path.basename(inputblob.name), _TARGET_SCHEMA_NAME, _TARGET_TABLE_NAME)
cursor.execute(sql, values)
rc = cursor.fetchval()
if rc == 0:
logging.info('Stored procedure {stored_proc} executed successfully!'.format(stored_proc=_TARGET_STORED_PROC_NAME))
cursor.commit()
Now that we have our function, let’s create a small JSON file called ‘customer12345.json’ (I used ChatGPT for this), target table the stored procedure used in our Python script. Also, given that some REST endpoints require authentication in order to be properly invoked, we will need to create Database Scoped Credentials (DSC) to securely store authentication data (like a Bearer token for example) to call a protected endpoint. The following code creates Scoped Credential ‘azblobstore’ with SAS access token, a table called customer_interactions where unparsed JSON data will be stored, and the main stored procedure used for data acquisition. Notice that in line 42, there is also a reference to a table value function called tvf_compare_json_docs which is there to allow JSON payload comparison in the odd case the same file (with the same file name) is submitted more than once and we’d like to update the original version and populated Update_DataTime field in the target table (the code behind this tvf and JSON file can be found in my OneDrive folder HERE).
-- create encryption key
IF NOT EXISTS
(
SELECT *
FROM sys.symmetric_keys
WHERE [name] = '##MS_DatabaseMasterKey##'
)
BEGIN
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '$trong_Pa$$word';
END;
-- create credential name
IF EXISTS
(
SELECT TOP (1)
1
FROM sys.database_credentials
WHERE name = 'azblobstore'
)
BEGIN
DROP DATABASE SCOPED CREDENTIAL azblobstore;
END;
-- create database scoped credential
CREATE DATABASE SCOPED CREDENTIAL [azblobstore]
WITH IDENTITY = 'SHARED ACCESS SIGNATURE',
SECRET = 'Your_Azure_Blob_Storage_SAS_Secret_Value';
GO
-- create target table
DROP TABLE IF EXISTS [dbo].[customer_interactions]
CREATE TABLE [dbo].[customer_interactions](
[file_id] [UNIQUEIDENTIFIER] NOT NULL,
[file_name] [NVARCHAR](1024) NULL,
[payload] [NVARCHAR](MAX) NULL,
[sentiment] [VARCHAR](20) NULL,
[insert_datetime] [DATETIME2](7) NULL,
[update_datetime] [DATETIME2](7) NULL,
CONSTRAINT [file_name] PRIMARY KEY CLUSTERED
(
[file_id] ASC
)WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
ALTER TABLE [dbo].[customer_interactions] ADD CONSTRAINT [df_file_id] DEFAULT (NEWSEQUENTIALID()) FOR [file_id]
GO
ALTER TABLE [dbo].[customer_interactions] ADD DEFAULT (NULL) FOR [update_datetime]
GO
-- create usp_load_from_azure_blob stored procedure
CREATE OR ALTER PROCEDURE [dbo].[usp_load_from_azure_blob]
(
@file_name VARCHAR(1024),
@schema_name sysname,
@table_name sysname,
@table_spec sysname = NULL
)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @has_identity_column INT;
DECLARE @new_json NVARCHAR(MAX);
DECLARE @old_json NVARCHAR(MAX);
DECLARE @new_json_file_name NVARCHAR(1024);
DECLARE @old_json_file_name NVARCHAR(1024);
DECLARE @error_message VARCHAR(MAX);
DECLARE @url NVARCHAR(MAX) = CONCAT('https://your_storage_account_name.blob.core.windows.net/input-json/', @file_name);
DECLARE @response NVARCHAR(MAX);
DECLARE @time_zone VARCHAR (128)
IF @table_name IS NULL
SELECT @table_name = PARSENAME(@table_spec, 1);
IF @schema_name IS NULL
SELECT @schema_name = PARSENAME(@table_spec, 2);
IF @table_name IS NULL
OR @schema_name IS NULL
BEGIN
SET @error_message = 'Target DB, schema or table name was not provided. Bailing out!';
RAISERROR( @error_message,
16,
1
);
RETURN;
END;
IF NOT EXISTS
(
SELECT current_utc_offset
FROM sys.time_zone_info
WHERE name = 'AUS Eastern Standard Time'
)
BEGIN
SET @time_zone = 'UTC';
END
ELSE
BEGIN
SET @time_zone = 'AUS Eastern Standard Time';
END;
EXEC sp_invoke_external_rest_endpoint @url = @url,
@method = 'GET',
@headers = '{"Accept":"application/json"}',
@credential = azblobstore,
@response = @response OUTPUT;
IF TRIM(JSON_VALUE(@response, '$.response.status.http.code')) <> '200'
AND TRIM(JSON_VALUE(@response, '$.response.status.http.description')) <> 'OK'
BEGIN
SET @error_message = 'Rest call response was unsuccessfull. Bailing out!';
RAISERROR( @error_message,
16,
1
);
RETURN;
END;
SET @new_json =
(
SELECT JSON_QUERY(@response, '$.result')
);
SET @old_json =
(
SELECT payload FROM dbo.customer_interactions WHERE file_name = @file_name
);
SET @new_json_file_name = @file_name;
SET @old_json_file_name =
(
SELECT file_name FROM dbo.customer_interactions WHERE file_name = @file_name
);
IF (ISJSON(@new_json) < 1)
BEGIN
SET @error_message
= 'Provided source JSON payload is not properly formatted or the file does not exist. Bailing out!';
RAISERROR( @error_message,
16,
1
);
RETURN;
END;
DROP TABLE IF EXISTS #returntable;
SELECT *
INTO #returntable
FROM dbo.tvf_compare_json_docs(@new_json, @old_json);
DECLARE @select_sql NVARCHAR(200) =
(
SELECT 'SELECT * FROM ' + QUOTENAME(@schema_name) + '.' + QUOTENAME(@table_name)
);
SELECT @has_identity_column = MAX(CONVERT(INT, is_identity_column))
FROM sys.dm_exec_describe_first_result_set(@select_sql, NULL, 1) AS f;
DECLARE @delete_cmd VARCHAR(MAX)
= 'DELETE FROM ' + QUOTENAME(@schema_name) + '.' + QUOTENAME(@table_name) + ' WHERE file_name = ''' + @file_name
+ ''';';
DECLARE @update_cmd VARCHAR(MAX)
= 'UPDATE ' + QUOTENAME(@schema_name) + '.' + QUOTENAME(@table_name) + ' SET payload = ''' + @new_json
+ ''', sentiment = NULL, update_datetime = SYSDATETIME() AT TIME ZONE ''UTC'' AT TIME ZONE '''+@time_zone+''' WHERE file_name = ''' + @file_name + ''';';
DECLARE @insert_cmd VARCHAR(MAX)
= 'INSERT INTO ' + QUOTENAME(@schema_name) + '.' + QUOTENAME(@table_name) + ' (file_name, payload, insert_datetime)
SELECT ''' + @file_name + ''', ''' + @new_json + ''', SYSDATETIME() AT TIME ZONE ''UTC'' AT TIME ZONE '''+@time_zone+''';';
DECLARE @command NVARCHAR(MAX)
=
(
SELECT CASE
WHEN @old_json IS NOT NULL AND @old_json_file_name IS NOT NULL AND @old_json_file_name = @new_json_file_name
AND EXISTS
(
SELECT TOP (1) 1 FROM #returntable WHERE SideIndicator = '<>'
) THEN
@update_cmd
WHEN @old_json IS NOT NULL AND @old_json_file_name IS NOT NULL AND @old_json_file_name = @new_json_file_name
AND NOT EXISTS
(
SELECT TOP (1) 1 FROM #returntable WHERE SideIndicator = '<>'
) THEN ''
ELSE
CASE
WHEN @old_json IS NOT NULL AND @old_json_file_name IS NOT NULL AND @old_json_file_name = @new_json_file_name THEN
@delete_cmd
ELSE
''
END
+ CASE
WHEN @has_identity_column > 0 THEN
' SET IDENTITY_INSERT ' + QUOTENAME(@schema_name) + '.'
+ QUOTENAME(@table_name) + ' OFF; '
ELSE
''
END + @insert_cmd
+ CASE
WHEN @has_identity_column > 0 THEN
' SET IDENTITY_INSERT ' + QUOTENAME(@schema_name) + '.'
+ QUOTENAME(@table_name) + ' ON '
ELSE
''
END
END
);
EXEC (@command);
END;
The main part is as per lines 100-104 where SQL Server sp_invoke_external_rest_endpoint system stored procedure is used for data acquisition. We’re using GET HTTP method (must be one of the following values: GET, POST, PUT, PATCH, DELETE, HEAD), passing the previously created Database Scoped Credentials in the @credential parameter and using concatenated blob URL and file name as the @url parameter. All going well, execution will return 0 if the HTTPS call was done, the HTTP code received is of 2xx status (Success) and the returned JSON in the @response parameter can be further parsed (if required) using SQL Server JSON-specific syntax.
We now have our JSON file content in the target table but, as per the original requirement, we also need to ascertain client’s conversation sentiment which can help us get the overall gauge on how our customers’ cohort is tracking with respect to the service satisfaction. Again, previously, that would have been a laborious, if not challenging task for someone who doesn’t have a lot of experience in applications integration and Azure ecosystem of services. However, now it’s just a matter of provisioning Azure Cognitive Service account (something we can be easily done from Azure portal) and creating a database trigger used to execute Cognitive Services API call using the same system stored procedure we used before.
Let’s go ahead and save our Azure Cognitive Services authentication key as a DSC, and wrap the sp_invoke_external_rest_endpoint call in a separate stored procedure which also parses JSON payload to extract sentiment value. We will also create a database trigger to automated procedure execution and invoke it every time a record is inserted or updated.
-- create database scoped credential
IF EXISTS
(
SELECT TOP (1)
1
FROM sys.database_credentials
WHERE name = 'Your_Cognitive_Services_Endpoint_URL'
)
BEGIN
DROP DATABASE SCOPED CREDENTIAL [Your_Cognitive_Services_Endpoint_URL];
END;
CREATE DATABASE SCOPED CREDENTIAL [Your_Cognitive_Services_Endpoint_URL]
WITH IDENTITY = 'HTTPEndpointHeaders',
SECRET = '{"Ocp-Apim-Subscription-Key":"Your_Key_Value"}';
GO
-- create usp_run_sentiment_analysis stored procedure
CREATE OR ALTER PROCEDURE [dbo].[usp_run_sentiment_analysis]
(@file_id UNIQUEIDENTIFIER)
AS
BEGIN
DECLARE @error_message VARCHAR(MAX);
DECLARE @url NVARCHAR(2000) = N'https://Your_Cognitive_Services_Endpoint_URL/text/analytics/v3.0/sentiment';
DECLARE @response NVARCHAR(MAX);
DECLARE @json NVARCHAR(MAX) =
(
SELECT payload FROM [dbo].[customer_interactions] WHERE file_id = @file_id
);
DECLARE @customer_text NVARCHAR(MAX) =
(
SELECT STRING_AGG(message, ' ') AS customer_text
FROM
OPENJSON(@json, '$.conversation')
WITH
(
speaker NVARCHAR(100),
message NVARCHAR(MAX) '$.message'
)
WHERE speaker = 'Customer'
);
DECLARE @payload NVARCHAR(MAX)
= N'{"documents": [{"id": "1", "language": "en", "text": "' + @customer_text + N'"}]}';
DECLARE @headers NVARCHAR(102) = N'{"Content-Type": "application/json"}';
EXEC sp_invoke_external_rest_endpoint @url = @url,
@method = 'POST',
@headers = @headers,
@payload = @payload,
@credential = [Your_Cognitive_Services_Endpoint_URL],
@response = @response OUTPUT;
IF TRIM(JSON_VALUE(@response, '$.response.status.http.code')) <> '200'
BEGIN
SET @error_message = 'Rest call response was unsuccessful. Bailing out!';
RAISERROR( @error_message,
16,
1
);
RETURN;
END;
ELSE
BEGIN
UPDATE [dbo].[customer_interactions]
SET sentiment =
(
SELECT TOP (1) JSON_VALUE(@response, '$.result.documents[0].sentiment')
)
WHERE file_id = @file_id;
END;
END;
GO
-- create trigger_sentiment_analysis database trigger
CREATE OR ALTER TRIGGER [dbo].[trigger_sentiment_analysis]
ON [dbo].[customer_interactions]
AFTER INSERT, UPDATE
AS
BEGIN
SET NOCOUNT ON;
DECLARE @file_id VARCHAR(128);
SELECT @file_id = inserted.file_id
FROM inserted;
EXEC usp_run_sentiment_analysis @file_id = @file_id;
END;
GO
ALTER TABLE [dbo].[customer_interactions] ENABLE TRIGGER [trigger_sentiment_analysis];
GO
The 3-stage logic in the above stored procedure dictates that we extract customer’s text from our JSON entry, omitting everything that relates to speaker dialog, call our sentiment analysis API with this data to determine sentiment value and finally, persist it in the target table against the file_id in question. All there’s left to do is to create another database trigger which activates only if the sentiment value is negative and, you guessed it, calls a stored procedure responsible for running Azure Logic App.
This is our third Azure services integration using REST endpoint in SQL DB and it just goes to show how versatile this functionality is and how it opens a world of possibilities, all within the confines of the database and with little to no development required outside of T-SQL.
For this part let’s create a small Logic App which triggers ‘Send an email (V2)’ task when a HTTP request is received, the final stored procedure calling this workflow and a database trigger to automate execution process. Also, to make it more interesting, we’ll pass customer’s feedback text and date/time this file was created at to our email content so that whoever receives this correspondence does not have to wonder what text triggered this workflow.
Our Logic App and the final piece of SQL code will look like this:
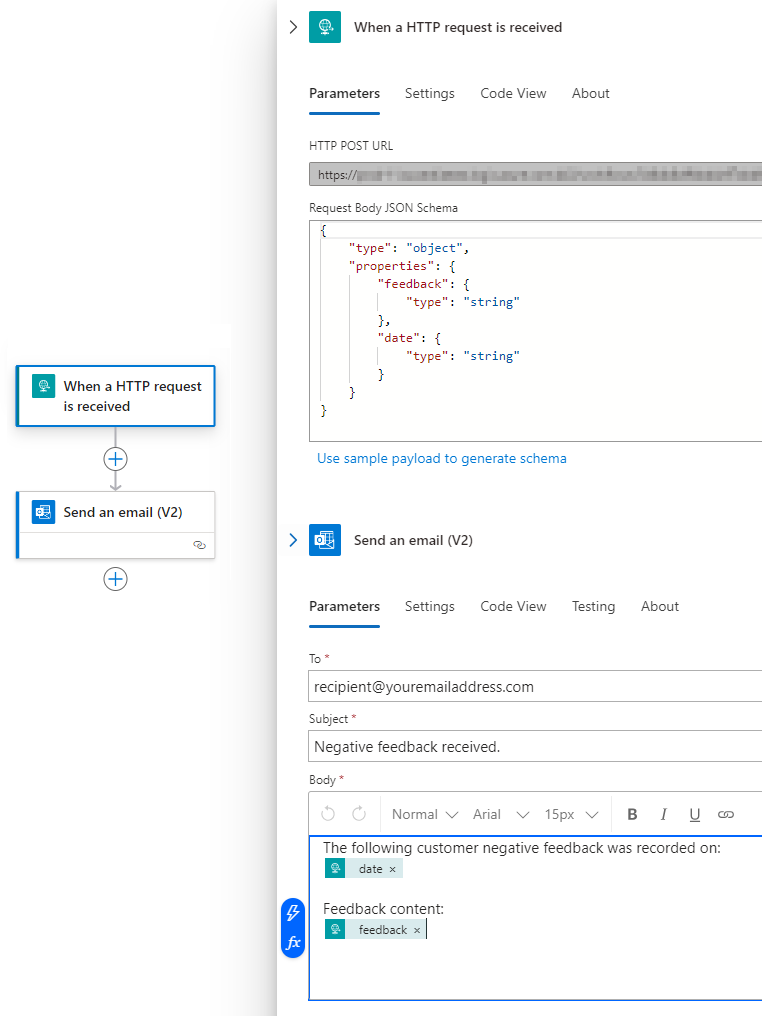
-- create usp_send_email_on_negative_sentiment stored procedure
CREATE OR ALTER PROCEDURE [dbo].[usp_send_email_on_negative_sentiment]
(
@insert_date DATETIME2,
@customer_feedback NVARCHAR(MAX)
)
AS
BEGIN
DECLARE @url NVARCHAR(MAX)
= N'Your_Logic_App_URL';
DECLARE @response NVARCHAR(MAX);
DECLARE @payload NVARCHAR(MAX) = N'{
"feedback": "' + @customer_feedback + N'",
"date": "' + CONVERT(VARCHAR, @insert_date, 0) + N'"
}';
DECLARE @headers NVARCHAR(102) = N'{"Content-Type": "application/json"}';
EXEC sp_invoke_external_rest_endpoint @url = @url,
@method = 'POST',
@headers = @headers,
@payload = @payload,
@response = @response OUTPUT;
END;
GO
-- create trigger_send_email_on_negative_sentiment database trigger
CREATE OR ALTER TRIGGER [dbo].[trigger_send_email_on_negative_sentiment]
ON [dbo].[customer_interactions]
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
DECLARE @JSON NVARCHAR(MAX);
SELECT @JSON = inserted.payload
FROM Inserted;
DECLARE @customer_feedback NVARCHAR(MAX);
SET @customer_feedback =
(
SELECT STRING_AGG(message, ' ') AS customer_text
FROM
OPENJSON(@JSON, '$.conversation')
WITH
(
speaker NVARCHAR(100),
message NVARCHAR(MAX) '$.message'
)
WHERE speaker = 'Customer'
);
DECLARE @insert_date DATETIME2;
SELECT @insert_date = inserted.insert_datetime
FROM inserted;
DECLARE @sentiment VARCHAR(20);
SELECT @sentiment = inserted.sentiment
FROM inserted;
IF @sentiment = 'negative'
BEGIN
EXEC usp_send_email_on_negative_sentiment @insert_date = @insert_date,
@customer_feedback = @customer_feedback;
END;
END;
GO
ALTER TABLE [dbo].[customer_interactions] ENABLE TRIGGER [trigger_send_email_on_negative_sentiment];
GO
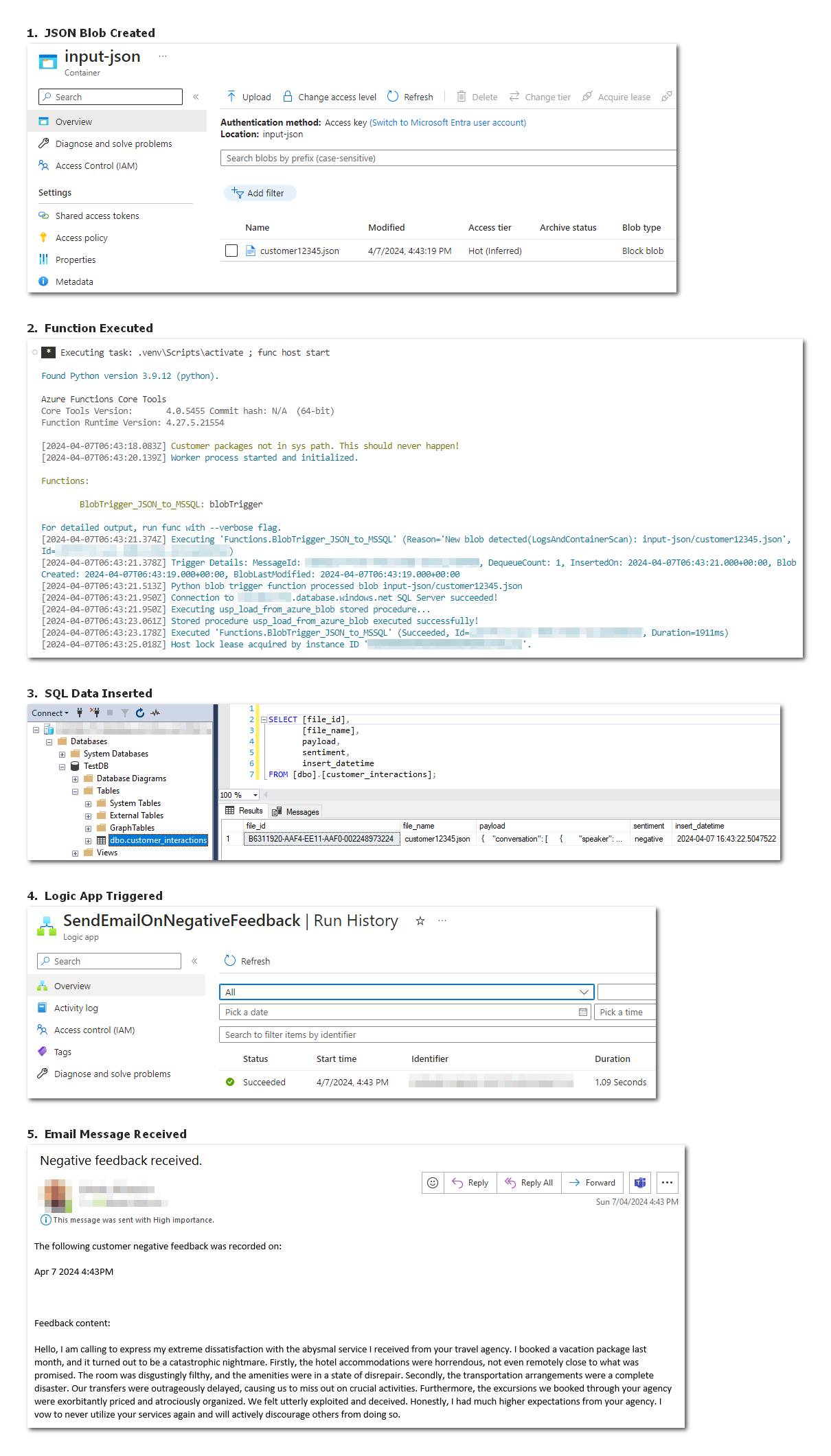
We can run this workflow, end-to-end by uploading our sample JSON conversation file into Azure storage container and, providing we have the Logic App and Azure function running (either in Azure or locally with Azure Functions Core Tools), the whole process should only take a few seconds to complete (you can confirm it by looking at time stamps) and result in an email notification being received – see screenshots as per below (click on it to enlarge).
Conclusion
Using Azure SQL DB REST endpoint integration, a large number of Azure services can be interfaced with Azure SQL DB, further expanding and extending platform’s capability. These workflows allow SQL database to act as the connecting tissue for data interoperability across API-enabled interfaces. In addition to workflow activation e.g. triggering Logic Apps or Azure functions as demonstrated above, additional use cases can include further integration with event-based architectures e.g. Azure Event Hub, creating data streams for fraud detection via Stream Analytics, websites updates using broadcasting SignalR messages or cache invalidation using Azure Functions. As long as you don’t think of the feature as a MuleSoft or Boomi replacement and understand the limitations of this approach, querying REST Endpoints with Azure SQL Database opens up a lot of possibilities.




Never thought Polybase could be used in this capacity and don't think Microsoft advertised this feature (off-loading DB data as…