Lately I have been working on a project where a client requested a data to be returned in a sorted order with the flexibility of being able to select a column which they wanted the data to be sorted by. This option, using pure vanilla T-SQL is rather complex to achieve using T-SQL as writing a stored procedure that, for example, underpins the SSRS report in the following fashion will not work.
CREATE PROCEDURE dbo.Sort_Dynamically
@SortColumn NVARCHAR (100),
@SortDirection VARCHAR (4)
AS
BEGIN
... ORDER BY @SortColumn, @SortDirection
END
GO
There are few different approaches that could provide the flexible sorting functionality, so let’s start with putting together a sample data set we can execute the SQL code against.
USE MASTER
GO
IF (EXISTS(SELECT Name FROM SysDatabases WHERE name = 'SortDB' ))
BEGIN
ALTER DATABASE [SortDB] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [SortDB]
END
GO
CREATE DATABASE SortDB
GO
USE SortDB
GO
IF EXISTS
(SELECT * FROM SortDB.dbo.sysobjects o
WHERE o.xtype in ('U')
and o.id = object_id(N'sortdb..temp_Table'))
DROP TABLE Temp_Table
GO
SELECT TOP 1000
key_col = ROW_NUMBER() OVER (ORDER BY s1.[object_ID]),
object_id = s1.[object_id],
name = s1.name COLLATE DATABASE_DEFAULT,
object_tp_description = s1.type_desc COLLATE DATABASE_DEFAULT,
modify_date = s1.modify_date
INTO Temp_Table
FROM sys.all_objects AS s1
ORDER BY s1.[object_id];
Given that we now have five attributes to potentially order by, let’s assume that all these will participate in the user selection option. Additionally, the user will want to ensure that the sort order will be one of the inputs/parameters so all data can be sorted in either ascending or descending order. To accomplish this requirement I have two separate methods which can produce the required data sets – one using dynamic SQL and another using window function.
DYNAMIC SQL METHOD
CREATE PROCEDURE dbo.Sort_Dynamically_dSQL
@SortColumn NVARCHAR (128),
@SortDirection VARCHAR (4)
AS
BEGIN
SET NOCOUNT ON;
--ENSURE THAT CORRECT SORTING DIRECTION IS ENTERED
IF UPPER(@SortDirection) NOT IN ('ASC', 'DESC')
BEGIN
RAISERROR('Invalid entry for @SortDirection: %s', 11, 1, @SortDirection);
RETURN -1;
END
--ENSURE THAT CORRECT COLUMN NAME IS ENTERED
IF LOWER(@SortColumn) NOT IN ('key_col', 'object_id', 'name', 'object_tp_description', 'modify_date')
BEGIN
RAISERROR ('Invalid entry for @SortColumn: %s', 11, 1, @SortColumn);
RETURN -1;
END
SET @SortColumn = QUOTENAME(@SortColumn);
DECLARE @Sql NVARCHAR (MAX)
SET @Sql = 'SELECT key_col, object_id, name, object_tp_description, modify_date
FROM Temp_Table
ORDER BY' + @SortColumn + '' + @SortDirection + ';'
EXEC sp_executesql @Sql
END
This dynamic SQL encapsulated in a stored procedure with a few validation lines is pretty self-explanatory. It dynamically creates a SELECT statement based on the two variables entered as per below. Window function method, again encapsulated in a stored procedure, uses a different approach where sorting is done by means of ROW_NUMBER() function, whereas sort direction is the result of a simple multiplication to determine if the order should be ascending or descending as per the code below.
WINDOW FUNCTION METHOD
CREATE PROCEDURE dbo.Sort_Dynamically_RowNumber
@SortColumn NVARCHAR (128),
@SortDirection VARCHAR (4)
AS
BEGIN
SET NOCOUNT ON;
WITH x AS
(SELECT key_col, object_id, name, object_tp_description, modify_date,
rn = ROW_NUMBER() OVER(ORDER BY CASE @SortColumn
WHEN 'key_col' THEN RIGHT ('000000000000' + RTRIM (key_col),12)
WHEN 'object_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM(object_id),1),'-'),'0')
+ REPLICATE ('0',23) + RTRIM(object_ID),24)
WHEN 'key_col' THEN RIGHT (RTRIM (key_col),12)
WHEN 'object_id' THEN RIGHT(RTRIM(object_ID),24)
WHEN 'name' THEN name
WHEN 'object_tp_description' THEN object_tp_description
WHEN 'modify_date' THEN CONVERT (VARCHAR(25), modify_date, 120)
END) * CASE @SortDirection WHEN 'ASC' THEN 1 ELSE -1 END
FROM Temp_Table)
SELECT key_col, object_id, name, object_tp_description, modify_date
FROM x
ORDER BY rn
END
Now we can execute any of the two stored procedures with parameters assigned as per the column we wish to sort by and the sort order i.e. ascending or descending.
--SORT BY key_col column IN DESCENDING ORDER
--USING dbo.Sort_Dynamically_RowNumber STORED PROCEDURE
EXEC dbo.Sort_Dynamically_RowNumber 'key_col', 'desc'
--SORT BY modify_date column IN ASCENDING ORDER
--USING dbo.Sort_Dynamically_dSQL STORED PROCEDURE
EXEC dbo.Sort_Dynamically_dSQL 'modify_date', 'asc';
In this post I would like to build on what was developed in first iteration to this two part series describing Twitter data extraction and sentiment analysis. In part one, I explained how anyone can extract Twitter data into Google Docs spread sheet and then transfer is into a local environment using two different methods. In this series-final post, I would like to show you how this data can be analyzed for sentiment i.e. whether a specific Twitter feed can be considered as negative or positive. To do this, I will employ free software called RapidMiner which can be downloaded from HERE as well as two separate data sets of already pre-classified tweets for model learning and Microsoft SQL Server for some data scrubbing and storage engine. Most of the files I am using in this project can be downloaded from HERE (including all the SQL code, YouTube video, sample data files etc.).
To get started, I created two tables which will house the data, one for reference data which already contains sentiment information and one for the data extracted from Twitter which hasn’t been analysed yet using the following code:
CREATE TABLE [dbo].[Twitter_Training_Data]
([ID] [int] IDENTITY(1,1) NOT NULL,
[Feed] [varchar](max) NULL,
[Sentiment] [varchar](50) NULL) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Twitter_Test_Data]
([ID] [int] IDENTITY(1,1) NOT NULL,
[Feed] [varchar](max) NULL) ON [PRIMARY]
GO
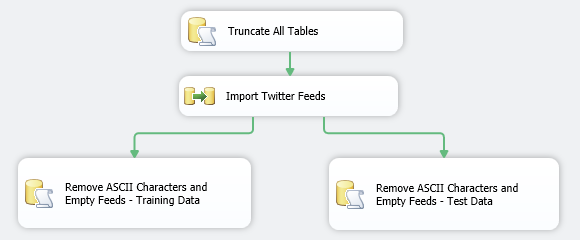
Next, I downloaded two files containing already sentiment-tagged Twitter feeds. These are quite large in size and probably overkill for this project but, in theory, the more data we provide for model to learn to distinguish between NEGATIVE and POSITIVE categories, the better it should perform. I imported and percentage sampled (for smaller dataset) the data from the two pre-processed files using a small SSIS package into my local MS SQL Server database together with the file containing Twitter feeds created using Zapier (see previous post) which hasn’t been analysed yet. The records from the reference data went into ‘Twitter_Training_Data’ table whereas the feeds we will mine were inserted into ‘Twitter_Test_Data’ table. The whole SSIS solution is as per below (Control and Data Flow)
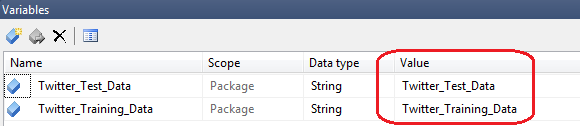
To be more flexible, I have also created two variables inside the package which hold the table names the package populates.
These variables get passed into the stored procedure which allows it to be applied to both tables. To pass the variables to the data cleansing stored procedure I assigned the variable name in ‘Parameters Mapping’ property of each of the two Execute SQL Tasks with its corresponding data type to a parameter as per below.
The reason for storing this information in a database rather than a file is simply because once in a table, the data can undergo further cleaning and formatting using the logic implemented in the SQL code. As I found out the hard way, a lot of the strings people put into their tweets contain tons of useless ACSII characters and shortened URL references which only pollute the test data and confuse the model. Also, reading data from a database can incur substantial performance increase. To further clean the data, I created two functions, one to weed out non-alphanumeric characters and one to remove references to URLs. As the classification mining model relies on words which are greater than 2 characters in length and web application generated URLs are mostly comprised of artificially created strings, these characters don not contribute to the overall outcome and in many cases can in fact skew the output. These two functions get used by the stored procedure which executes as the final step of the ETL package. The SQL code for those is as per below.
--CREATE STRING SPLITTING FUNCTION
CREATE FUNCTION [dbo].[Split] (@sep VARCHAR(32), @s VARCHAR(MAX))
RETURNS @t TABLE
(val VARCHAR(MAX))
AS
BEGIN
DECLARE @xml XML
SET @XML = N'' + REPLACE(@s, @sep, '') + ''
INSERT INTO @t(val)
SELECT r.value('.','VARCHAR(1000)') as Item
FROM @xml.nodes('//root/r') AS RECORDS(r)
RETURN
END
--CREATE FUNCTION TO REMOVE UNWANTED CHARACTERS
CREATE FUNCTION [dbo].[RemoveSpecialChars]
(@Input VARCHAR(MAX))
RETURNS VARCHAR(MAX)
BEGIN
DECLARE @Output VARCHAR(MAX)
IF (ISNULL(@Input,'')='')
SET @Output = @Input
ELSE
BEGIN
DECLARE @Len INT
DECLARE @Counter INT
DECLARE @CharCode INT
SET @Output = ''
SET @Len = LEN(@Input)
SET @Counter = 1
WHILE @Counter <= @Len
BEGIN
SET @CharCode = ASCII(SUBSTRING(@Input, @Counter, 1))
IF @CharCode=32 OR @CharCode BETWEEN 48 and 57 OR @CharCode BETWEEN 65 AND 90
OR @CharCode BETWEEN 97 AND 122
SET @Output = @Output + CHAR(@CharCode)
SET @Counter = @Counter + 1
END
END
RETURN @Output
END
--CREATE STRING CLEANING STORED PROCEDURE
CREATE PROCEDURE [dbo].[usp_Massage_Twitter_Data]
(@table_name NVARCHAR(100))
AS
BEGIN
BEGIN TRY
SET NOCOUNT ON
--CREATE CLUSTERED INDEX SQL
DECLARE @SQL_Drop_Index NVARCHAR(1000)
SET @SQL_Drop_Index =
'IF EXISTS (SELECT name FROM sys.indexes
WHERE name = N''IX_Feed_ID'')
DROP INDEX IX_Feed_ID ON ' + @table_name + '
CREATE CLUSTERED INDEX IX_Feed_ID
ON ' + @Table_Name + ' (ID)';
--REMOVE UNWANTED CHARACTERS SQL
DECLARE @SQL_Remove_Chars NVARCHAR(2000)
SET @SQL_Remove_Chars =
'UPDATE ' + @Table_Name + '
SET feed = (select dbo.RemoveSpecialChars(feed))
DECLARE @z int
DECLARE db_cursor CURSOR
FOR
SELECT id
FROM ' + @Table_Name + '
OPEN db_cursor
FETCH NEXT
FROM db_cursor INTO @z
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE @Combined_String VARCHAR(max);
WITH cte(id, val) AS (
SELECT a.id, fs.val
FROM ' + @Table_Name + ' a
CROSS APPLY dbo.split('' '', feed) AS fs
WHERE fs.val NOT LIKE ''%http%'' and a.id = @z)
SELECT @Combined_String =
COALESCE(@Combined_String + '' '', '''') + val
FROM cte
UPDATE ' + @Table_Name + '
SET feed = ltrim(rtrim(@Combined_String))
WHERE ' + @Table_Name + '.id = @z
SELECT @Combined_String = ''''
FETCH NEXT
FROM db_cursor INTO @z
END
CLOSE db_cursor
DEALLOCATE db_cursor'
--RESEED IDENTITY COLUMN & DELETE EMPTY RECORDS SQL
DECLARE @SQL_Reseed_Delete NVARCHAR(1000)
SET @SQL_Reseed_Delete =
'IF EXISTS (SELECT c.is_identity
FROM sys.tables t
JOIN sys.schemas s
ON t.schema_id = s.schema_id
JOIN sys.Columns c
ON c.object_id = t.object_id
JOIN sys.Types ty
ON ty.system_type_id = c.system_type_id
WHERE t.name = ''+ @Table_Name +''
AND s.Name = ''dbo''
AND c.is_identity=1)
SET IDENTITY_INSERT ' + @Table_Name + ' ON
DELETE FROM ' + @Table_Name + '
WHERE Feed IS NULL or Feed =''''
DBCC CHECKIDENT (' + @Table_Name + ', reseed, 1)
SET IDENTITY_INSERT ' + @Table_Name + ' OFF
ALTER INDEX IX_Feed_ID ON ' + @Table_Name + '
REORGANIZE'
EXECUTE sp_executesql @SQL_Drop_Index
EXECUTE sp_executesql @SQL_Remove_Chars
EXECUTE sp_executesql @SQL_Reseed_Delete
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION
END
DECLARE @ErrorMessage NVARCHAR(4000);
DECLARE @ErrorSeverity INT;
DECLARE @ErrorState INT;
SELECT @ErrorMessage = ERROR_MESSAGE(),
@ErrorSeverity = ERROR_SEVERITY(),
@ErrorState = ERROR_STATE();
RAISERROR (
@ErrorMessage
,-- Message text.
@ErrorSeverity
,-- Severity.
@ErrorState -- State.
);
END CATCH
IF @@TRANCOUNT > 0
BEGIN
COMMIT TRANSACTION
END
END
The package extracts Twitter feeds from each of the three CSV files (I downloaded them as XLSX and converted into CSV simply by opening them up in Excel and saving again as CSV as SSIS can be a bit temperamental using Excel as a data source), storing them in assigned tables and performing some data cleansing using the above SQL code.
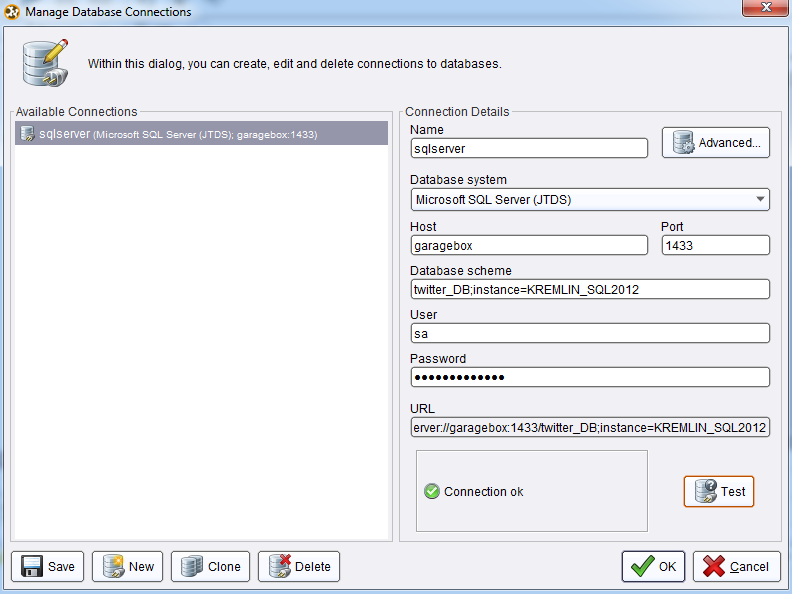
After both training data and new observations have been loaded into the database it is time to fire up RapidMiner. If you have any experience with ETL applications relying on drag-and-drop transformations functionally you should feel at home using RapidMiner. Using it is similar to building an SSIS routine on a development pane and linking individual transformations to create a logical data flow. To start, we need to create a database connection to read our tweets from SQL Server. There are numerous tutorials on the Internet and a few particularly useful ones on YouTube on how to install JTDE driver on the Windows box to read data from SQL Server instance so I won’t go into details on how to accomplish that. Below is a screen shot of the connection I set up in RapidMiner on my machine.
Finally, it is time to develop the model and the rest of the solution for Twitter data classification. As explaining it step by step with all supporting screen shots would require at least another post, I decided to provide this overview as a short footage hosted on YouTube – see below.
You can also download the original footage with all the complementary files e.g. SQL code, source data files etc. from HERE.
If you enjoyed this post please also check out my earlier version of Twitter sentiment analysis using pure SQL and SSIS which can be viewed from HERE. Finally, if you’re after a more adhoc/playful sentiment analysis tool for Twitter data and (optionally) have some basic knowledge of Python programming language, check out my post on using etcML web based tool under THIS link.
My name is Martin and this site is a random collection of recipes and reflections about various topics covering information management, data engineering, machine learning, business intelligence and visualisation plus everything else that I fancy to categorise under the 'analytics' umbrella. I'm a native of Poland but since my university days I have lived in Melbourne, Australia and worked as a DBA, developer, data architect, technical lead and team manager. My main interests lie in both, helping clients in technical aspects of information management e.g. data modelling, systems architecture, cloud deployments as well as business-oriented strategies e.g. enterprise data solutions project management, data governance and stewardship, data security and privacy or data monetisation. On the whole, I am very fond of anything closely or remotely related to data and as long as it can be represented as a string of ones and zeros and then analysed and visualised, you've got my attention!
Outside sporadic updates to this site I typically find myself fiddling with data, spending time with my kids or a good book, the gym or watching a good movie while eating Polish sausage with Zubrowka (best served on rocks with apple juice and a lime twist). Please read on and if you find these posts of any interests, don't hesitate to leave me a comment!





Never thought Polybase could be used in this capacity and don't think Microsoft advertised this feature (off-loading DB data as…