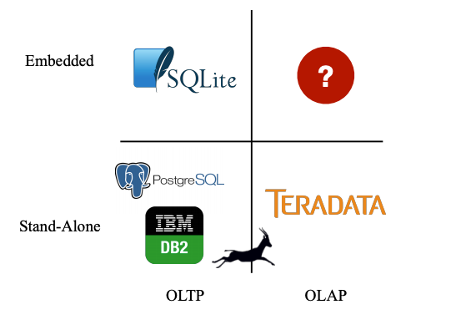
It’s nearly 2021 and never before have we been so spoiled with the number of different databases used for persisting, retrieval and analysis of all kinds of data. Last time I checked, DB-Engines ranking page listed 359 different commercial and open-source data stores across many different models e.g. relational, key-value, document, time-series etc. It certainly looks like every niche application is accounted for and one may think that there is no or very little room for new players to disrupt this space in a meaningful way. However, on close inspection, it appears that while the majority of use cases have been generously covered for many decades, one quadrant (see image below) has been under-represented. That’s until data science, IoT and edge computing started to become more pervasive and DuckDB was born.
It is no coincidence that demand for edge computing data storage and processing is soaring and many of the big vendors have recognized the unique requirements (and opportunities) this brings to the table e.g. only recently Microsoft announced the release of Azure SQL Edge – a small-footprint, edge-optimized SQL database engine with built-in AI. While Big Data technologies are becoming more pervasive and it’s never been easier to store and process terabytes of data, most business are still grappling with old problems for which throwing distributed cloud computing and storage model is not the panacea. Crunching and analyzing small but complex volumes of data has recently been dominated by Python rich libraries ecosystem, particularly the so-called Python Open Data Science Stack i.e. Pandas, NumPy, SciPy, and Scikit-learn. However, not everyone wants to give up SQL for Python and some of those technologies are not adequate when out-of-memory computation is required. When Hadoop started to gain popularity, many did not want to write Java or Scala jobs, so Cloudera, Hortonworks and other vendors started retrofitting their platforms with SQL interfaces to give end-users the level of abstraction they were comfortable with. This is where DuckDB, still in its infancy (in databases terms), could potentially become another valuable tool, helping analysts and data scientist in harnessing complex data locally with relative ease and speed.
DuckDB is designed to support analytical query workloads, also known as Online analytical processing (OLAP). These workloads are characterized by complex, relatively long-running queries that process significant portions of the stored dataset, for example aggregations over entire tables or joins between several large tables. Changes to the data are expected to be rather large-scale as well, with several rows being appended, or large portions of tables being changed or added at the same time.
To efficiently support this workload, it is critical to reduce the amount of CPU cycles that are expended per individual value. The state of the art in data management to achieve this are either vectorized or just-in-time query execution engines. DuckDB contains a columnar-vectorized query execution engine, where queries are still interpreted, but a large batch of values from a single (a ‘vector’) are processed in one operation. This greatly reduces overhead present in traditional systems such as PostgreSQL, MySQL or SQLite which process each row sequentially. Vectorized query execution leads to far better performance in OLAP queries.
Just like SQLite, DuckDB has no external dependencies, neither for compilation nor during run-time. For releases, the entire source tree of DuckDB is compiled into two files, a header and an implementation file, a so-called ‘amalgamation’. This greatly simplifies deployment and integration in other build processes. For building, all that is required to build DuckDB is a working C++11 compiler.
For DuckDB, there is no DBMS server software to install, update and maintain. DuckDB does not run as a separate process, but completely embedded within a host process. For the analytical use cases that DuckDB targets, this has the additional advantage of high-speed data transfer to and from the database. In some cases, DuckDB can process foreign data without copying. For example, the DuckDB Python package can run queries directly on Pandas data without ever importing or copying any data.
As far as I can tell, there is nothing like this on the market at the moment and DuckDB has found its unique niche i.e. dependency-free, embedded datastore for processing OLAP-style, relational data with speed and ease.
Also, if you’re interested in what motivated the founders of DuckDB to create it and a high-level system overview, there is a really good talk published by the CMU Database Group on YouTube (see video below).
Performance Analysis
If you follow database trends, ClickHouse is emerging as the go-to, open-source darling of on-prem and cloud OLAP-style data processing engine. I’m yet to get my hands on it and take it for a spin but I feel it would be unfair to compare it to DuckDB as they are intended for different crowd and applications. Both are open-source, column-oriented, OLAP databases but while Clickhouse is targeting distributed, enterprise-grade, big data workloads, DuckDB was developed primarely to bridge the gap between locally deployed databases and data science, dealing with small-to-medium data volumes. As such, in this post I will not compare individual RDBMSs and only outline how to load TPC-DS benchmark data and run SQL queries to look at DuckDB analytical workload performance.
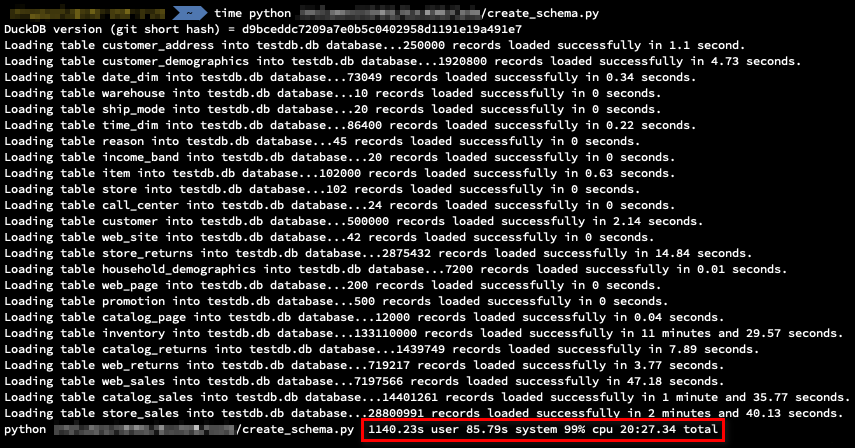
Firstly, let’s load some data. Flat files with test data were staged on a PCI-E SSD drive and all subsequent operations and queries were run on a Mac Pro 2012 with 112GB of memory and 2 x Intel Xeon X5690 CPUs. The following script creates an empty DuckDB database and schema. It also loads 10GB TPC-DS data, spread across 25 CSV files, using COPY command (for performance testing I also repeated this process for 20GB and 30GB data sets).
import duckdb
import sys
import os
from pathlib import PurePosixPath, Path
from timeit import default_timer as timer
from humanfriendly import format_timespan
sql_schema = PurePosixPath("/Path/Code/SQL/tpcds_ddls.sql")
tpc_ds_files_raw = r"/Path/Data/10GB/"
duckdb_location = PurePosixPath("/Path/DB/")
duckdb_filename = "testdb.db"
csv_file_delimiter = '|'
def get_sql(sql_schema):
table_name = []
query_sql = []
with open(sql_schema, "r") as f:
for i in f:
if i.startswith("----"):
i = i.replace("----", "")
table_name.append(i.rstrip("\n"))
temp_query_sql = []
with open(sql_schema, "r") as f:
for i in f:
temp_query_sql.append(i)
l = [i for i, s in enumerate(temp_query_sql) if "----" in s]
l.append((len(temp_query_sql)))
for first, second in zip(l, l[1:]):
query_sql.append("".join(temp_query_sql[first:second]))
sql = dict(zip(table_name, query_sql))
return sql
def BuildSchema(conn, tables, csv_file_delimiter, duckdb_location, duckdb_filename, sql, tpc_ds_files_raw):
sql = {x: sql[x] for x in sql if x in tables}
for k, v in sql.items():
try:
cursor = conn.cursor()
cursor.execute(v)
copysql = "COPY {table} FROM '{path}{table}.csv' (DELIMITER '{delimiter}')".format(
table=k, path=tpc_ds_files_raw, delimiter=csv_file_delimiter)
print('Loading table {table} into {dbname} database...'.format(dbname=duckdb_filename,
table=k), end="", flush=True)
table_load_start_time = timer()
cursor.execute(copysql)
table_load_end_time = timer()
table_load_duration = table_load_end_time - table_load_start_time
file_row_rounts = sum(
1
for line in open(
tpc_ds_files_raw+k+'.csv',
newline="",
)
)
cursor.execute(
"SELECT COUNT(1) FROM {table}".format(
table=k)
)
record = cursor.fetchone()
db_row_counts = record[0]
if file_row_rounts != db_row_counts:
raise Exception(
"Table {table} failed to load correctly as record counts do not match: flat file: {ff_ct} vs database: {db_ct}.\
Please troubleshoot!".format(
table=k,
ff_ct=file_row_rounts,
db_ct=db_row_counts,
)
)
else:
print('{records} records loaded successfully in {time}.'.format(
records=db_row_counts, time=format_timespan(table_load_duration)))
cursor.close()
except Exception as e:
print(e)
sys.exit(1)
if __name__ == "__main__":
if os.path.isfile(os.path.join(duckdb_location, duckdb_filename)):
os.remove(os.path.join(duckdb_location, duckdb_filename))
conn = duckdb.connect(os.path.join(duckdb_location, duckdb_filename))
ver = conn.execute("PRAGMA version;").fetchone()
print('DuckDB version (git short hash) =', ver[1])
sql_schema = get_sql(sql_schema)
tables = [q for q in sql_schema]
BuildSchema(conn, tables, csv_file_delimiter, duckdb_location,
duckdb_filename, sql_schema, tpc_ds_files_raw)
conn.close()
Looking at the execution times, the script run in just over 20 minutes. Largest table (size-wise), i.e. ‘store_sales’, containing over 28 million records took just under 3 minutes, whereas a table with the highest amount of records i.e. ‘inventory’ took over 11 minutes.
These are not bad times, however, given that each one of the COPY statements was associate with the same database connection, on load completion all data was stored in the write-ahead log (WAL) file, as opposed to the database file. This creates a significant problem as check-pointing the WAL file does no occur until a new connection is instantiated. As such, any subsequent operation is bound to take a long time, waiting for WAL check-pointing as described in the following issue.
If I chose to initiate a new connection for each file loaded, the load time exploded to over 1 hour, most of it spent waiting for WAL file to transfer all the appended transactions into the database file. As DuckDB does not currently offer application-initiated WAL checkpointing and automated WAL truncation does not rely on the number of pages written or connection closing, I feel this may be a difficult teething issue to get around when using DuckDB for more production-grade applications.
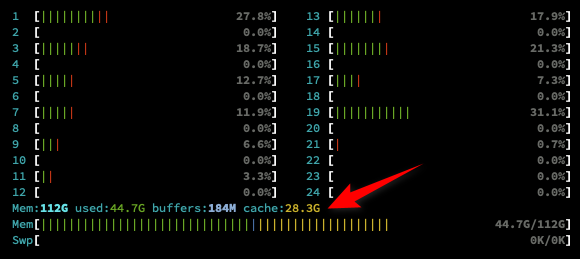
Another problem is memory usage. When loading 10GB of data, overall system memory usage exceed 40GB (quarter of it used by the system itself). Granted I had over 100GB of RAM available for testing on the target machine, this was not a problem, however, it seems to me that the issues many data scientist face when using Pandas for data analysis related to excessive memory usage may not be elevated with this tool. Below is a screenshot of some of the system stats with data temporarily paged in memory before being serialized for loading into the WAL file.
With data loaded into the target database, I scraped all of TPC-DS queries off the DuckDB website (link HERE) and run those across 10GB, 20GB and 30GB datasets to see how a typical OLAP-style analysis will perform. DuckDB TPC-DS benchmark coverage does not include queries 68, 76 and 89 but the tool is capable of executing all other SQL statements without any adjustments or modifications.
import duckdb
import sys
import os
import pandas as pd
from pathlib import PurePosixPath, Path
from timeit import default_timer as timer
from humanfriendly import format_timespan
sql_queries = PurePosixPath("/Path/Code/SQL/tpcds_sql_queries.sql")
execution_results = PurePosixPath("/Path/results.xlsx")
duckdb_location = PurePosixPath("/Path/DB/")
duckdb_filename = "testdb.db"
queries_skipped = ['Query68', 'Query76', 'Query89']
execution_rounds = 3
def get_sql(sql_queries):
query_number = []
query_sql = []
with open(sql_queries, "r") as f:
for i in f:
if i.startswith("----"):
i = i.replace("----", "")
query_number.append(i.rstrip("\n"))
temp_query_sql = []
with open(sql_queries, "r") as f:
for i in f:
temp_query_sql.append(i)
l = [i for i, s in enumerate(temp_query_sql) if "----" in s]
l.append((len(temp_query_sql)))
for first, second in zip(l, l[1:]):
query_sql.append("".join(temp_query_sql[first:second]))
sql = dict(zip(query_number, query_sql))
return sql
def run_sql(
query_sql, query_number, conn
):
try:
cursor = conn.cursor()
query_start_time = timer()
rows = cursor.execute(query_sql)
query_end_time = timer()
rows_count = sum(1 for row in rows)
query_duration = query_end_time - query_start_time
print(
"Query {q_number} executed in {time}...{ct} rows returned.".format(
q_number=query_number,
time=format_timespan(query_duration),
ct=rows_count,
)
)
except Exception as e:
print(e)
finally:
cursor.close()
def time_sql(index_count, pd_index, exec_round, conn, sql, duckdb_location, duckdb_filename):
exec_results = {}
for key, val in sql.items():
query_sql = val
query_number = key.replace("Query", "")
try:
cursor = conn.cursor()
query_start_time = timer()
cursor.execute(query_sql)
records = cursor.fetchall()
query_end_time = timer()
rows_count = sum(1 for row in records)
query_duration = query_end_time - query_start_time
exec_results.update({key: query_duration})
print(
"Query {q_number} executed in {time}...{ct} rows returned.".format(
q_number=query_number,
time=format_timespan(query_duration),
ct=rows_count,
)
)
cursor.close()
except Exception as e:
print(e)
df = pd.DataFrame(list(exec_results.items()), index=pd_index, columns=[
"Query_Number", "Execution_Time_"+str(exec_round)])
return(df)
def main(sql, duckdb_location, duckdb_filename):
index_count = len(sql.keys())
pd_index = range(0, index_count)
dfs = pd.DataFrame()
for exec_round in range(1, execution_rounds+1):
print('\nRunning Execution Round {r}'.format(r=exec_round))
conn = duckdb.connect(os.path.join(duckdb_location, duckdb_filename))
df = time_sql(index_count, pd_index, exec_round, conn,
sql, duckdb_location, duckdb_filename)
dfs = pd.concat([dfs, df], axis=1, sort=False)
dfs = dfs.loc[:, ~dfs.columns.duplicated()]
conn.close()
dfs['Mean_Execution_Time'] = round(dfs.mean(axis=1),2)
dfs.to_excel(execution_results,
sheet_name='TPC-DS_Exec_Times', index=False)
if __name__ == "__main__":
sql = get_sql(sql_queries)
if queries_skipped:
sql = {k: v for k, v in sql.items() if k not in queries_skipped}
main(sql, duckdb_location, duckdb_filename)
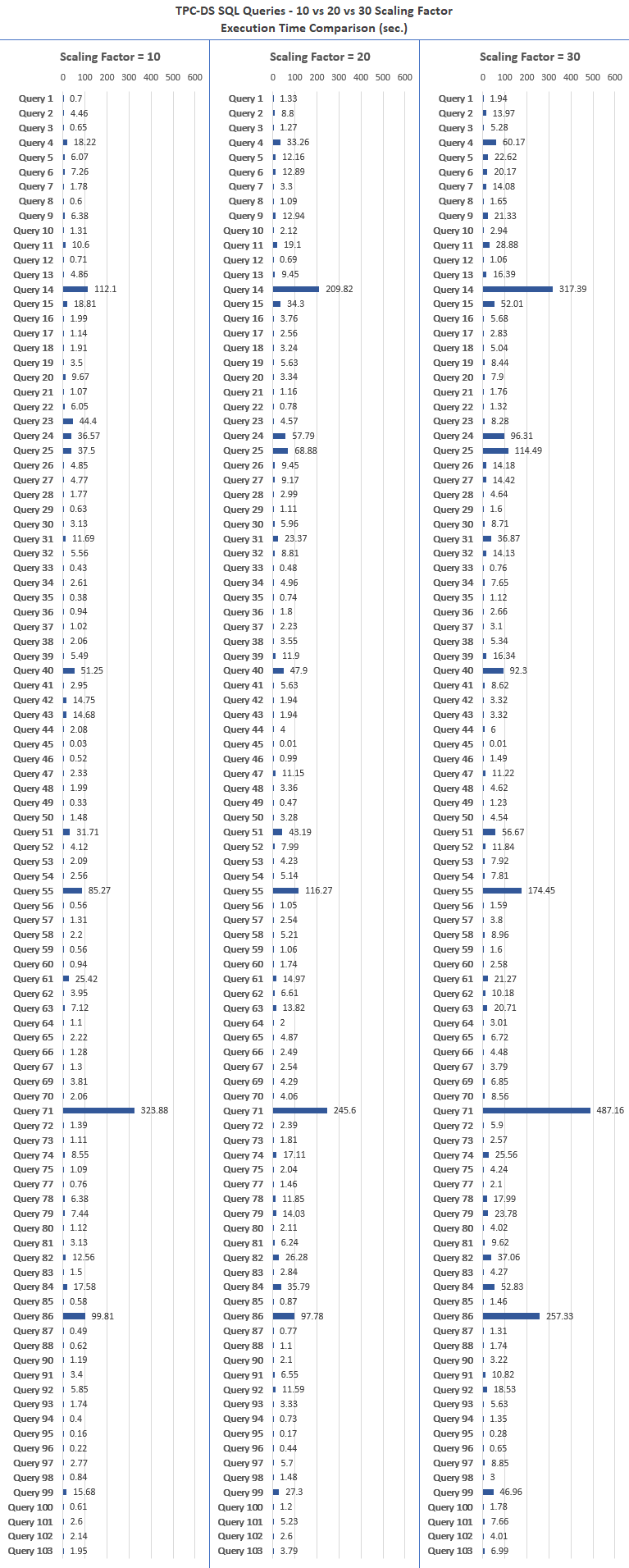
Each set of queries was run 3 times and final execution time calculated as the mean of those 3 iterations. The following table (click on image to enlarge) represents queries processing time for TPC-DS scaling factor 10, 20 and 30.
Looking at the results, most queries scale fairly linearly. Outside of a few exceptions, data processing time doubled every time its volume was doubled. There were a few outliers e.g. strangely Query 71 took longer when run against 10GB data set than when executed against 20GB size, however, for the most part it seems that the relationship between data size and query execution time is correlated.
Given that many of those queries are rather complex, I think that DuckDB performance was very good and that its columnar-vectorized query execution engine was up to the task. DuckDB claims that its vectorized query engine is superior to that of traditional RDBMS systems which crunch data tuple-at-a-time e.g. SQLite, MySQL or column-at-a-time e.g. Pandas due to the fact it’s optimized for CPU cache locality i.e. storing data in L1 and L2 cache, with very low latency. Based on the times recorded, I tend to agree and even though I have not run a comparison benchmark on other database engines, for an in-process (no server), single-file storage, no-dependencies software, I reckon DuckDB could outperform many commercial RDBMS systems on a similar hardware and volume of data in an OLAP-style scenarios.
Conclusion
From the short time I spent with DuckDB, I really like the idea of having a single-file, small and compact database at my disposal. Having the option to load text data into a SQLite-like database with relative ease and run analytics using plain, old vanilla SQL is both refreshing and practical. Whilst most times I would be inclined to use an established client-server RDBMS for all my data needs, DuckDB seems like it can comfortably occupy the unexplored niche – fast OLAP data storage and processing engine that one can use without worrying about complex deployment, set-up, configuration and tuning. It’s like a hummingbird of databases – small and fast – and while not (yet) as mature and full-featured as some of the stalwarts of the industry, it carries a lot of potential for workloads it’s designated to be used against.
Note: All artifacts used in this demo can be downloaded from my shared OneDrive folder HERE.
Introduction
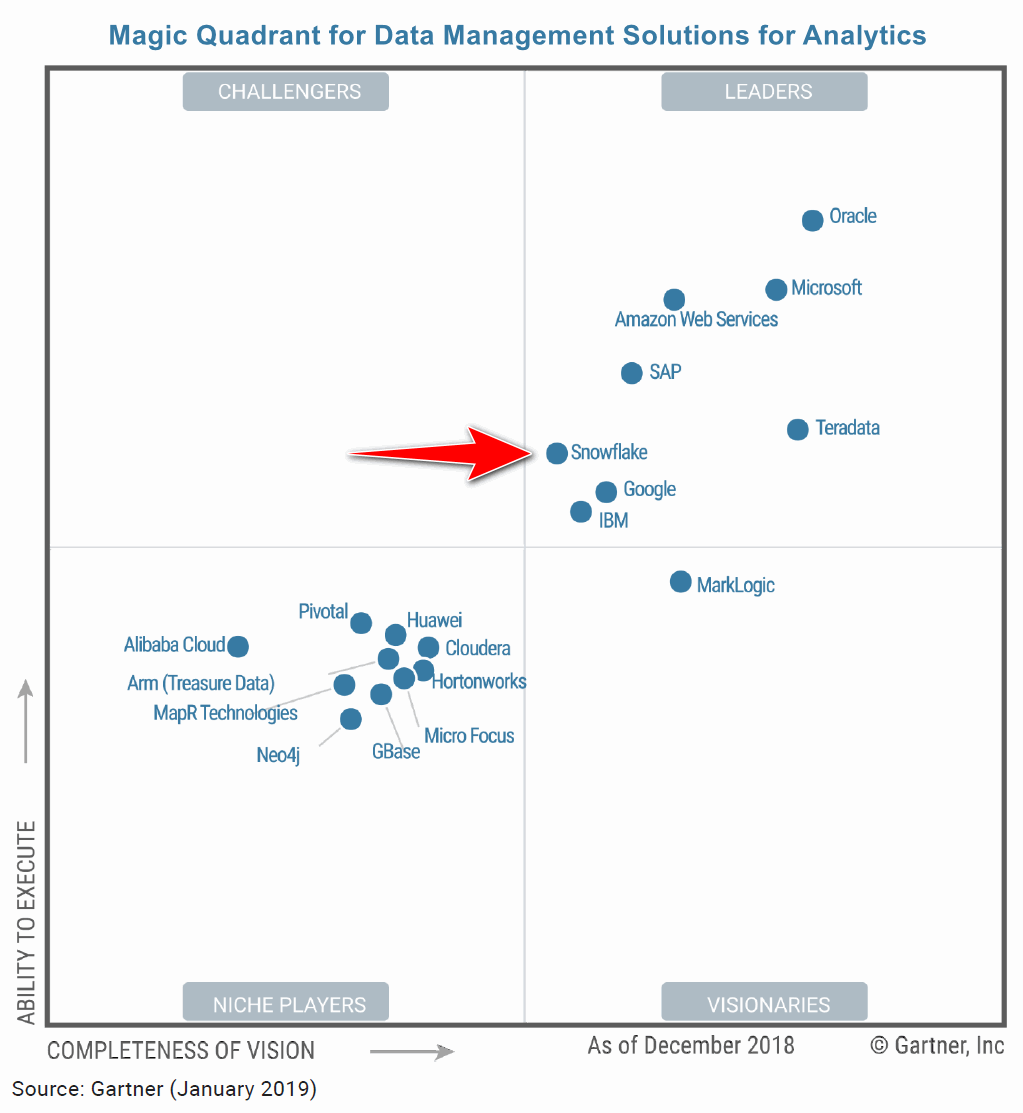
I have been working in the BI/Analytics field for a long time and have seen a lot of disruptive technologies in this space going through the hype cycle. Moving from SMP technologies to MPP databases, the era of Hadoop, the meteoric rise of Python and R for data science, serverless architectures and data lakes on cloud platforms etc. ensured that this industry stays more vibrant than ever. I see new frameworks, tools and paradigms raising to the surface almost daily and there are always new things to learn and explore. A few weeks ago, I had an interesting conversation with a recruiter about what’s trendy and interesting in the space of BI and Analytics and what the businesses she’s been helping with resourcing are looking for in terms of the IT talent pool. I was expecting to hear things like AI PaaS, Synthetic Data, Edge Analytics and all the interesting (and sometimes a bit over-hyped) stuff that the cool kids in Silicon Valley are getting into. Instead, she asserted that apart from public cloud platforms and all the run-of-the-mill BI tools like PowerBI and Looker, there is a growing demand for Snowflake projects. Mind you, this is an Australian market so chances are your neck of the woods may look completely different, but suffice to say, I didn’t expect a company not affiliated with a major public cloud provider to become so popular, particularly in this already congested market for cloud data warehousing solutions.
Snowflake, a direct competitor to Amazon’s Redshift, Microsoft’s Synapse and Google’s BigQuery, has been around for some time, but only recently I also started hearing more about it becoming the go-to technology for storing and processing large volumes of data in the cloud. I was also surprised to see Snowflake positioned in the ‘Leaders’ quadrant in the Data Management Solutions for Analytics chart, dethroning the well-known and respected industry stalwarts such as Vertica or Greenplum.
In this post, I want to look at Snowflake performance characteristics by creating a TPC-DS benchmark schema and executing a few analytical queries to see how it fares in comparison to some of the other MPP databases I worked with and/or tested. It’s not supposed to be an exhaustive overview or test and as such, these benchmark results should not be taken as Gospel. Having worked with databases all my career, I always look forward to exploring new technologies and even though I don’t expect to utilise Snowflake in my current project, it’s always exciting to kick the tires on a new platform or service.
OK, let’s dive in and see what’s in store!
Snowflake Architecture Primer
Snowflake claims to be built for cloud from the ground-up and does not offer on-premise deployment option, it’s purely a data warehouse as a service (DWaaS) offering. Everything – from database storage infrastructure to the compute resources used for analysis and optimisation of data – is handled by Snowflake. In this respect, Snowflake is not that much different from Google’s BigQuery although it’s difficult to contrast those two, mainly due to different pricing models (excluding storage cost) – BigQuery charges per volume of data scanned whereas Snowflake went with a more traditional model i.e. compute size and resource time allocation.
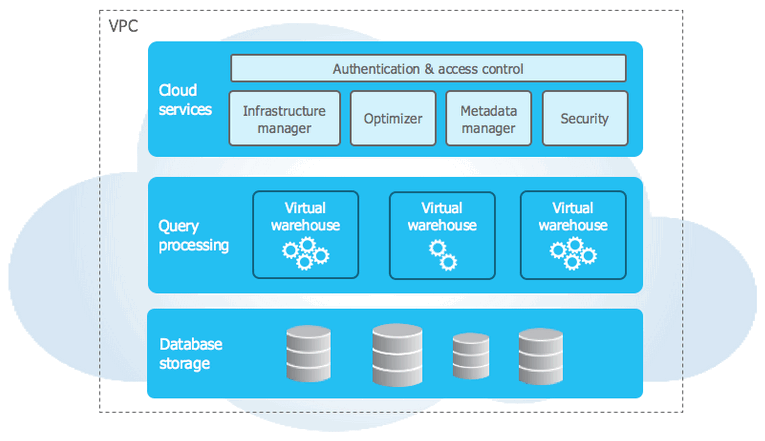
Snowflake’s architecture is a hybrid of traditional shared-disk database architectures and shared-nothing database architectures. Similar to shared-disk architectures, Snowflake uses a central data repository for persisted data that is accessible from all compute nodes in the data warehouse. But just like shared-nothing architectures, Snowflake processes queries using massively parallel processing compute clusters, where each node in the cluster stores a portion of the entire data set locally. This approach offers the data management simplicity of a shared-disk architecture, but with the performance and scale-out benefits of a shared-nothing architecture.
Snowflake’s unique architecture consists of three key layers:
Database Storage – When data is loaded into Snowflake, Snowflake reorganizes that data into its internaly optimized, compressed, columnar format. Snowflake stores this optimized data in cloud storage. Snowflake manages all aspects of how this data is stored — the organization, file size, structure, compression, metadata, statistics, and other aspects of data storage are handled by Snowflake. The data objects stored by Snowflake are not directly visible nor accessible by customers; they are only accessible through SQL query operations run using Snowflake
Query Processing – Query execution is performed in the processing layer. Snowflake processes queries using “virtual warehouses”. Each virtual warehouse is an MPP compute cluster composed of multiple compute nodes allocated by Snowflake from a cloud provider. Each virtual warehouse is an independent compute cluster that does not share compute resources with other virtual warehouses. As a result, each virtual warehouse has no impact on the performance of other virtual warehouses
Cloud Services – The cloud services layer is a collection of services that coordinate activities across Snowflake. These services tie together all of the different components of Snowflake in order to process user requests, from login to query dispatch. The cloud services layer also runs on compute instances provisioned by Snowflake from the cloud provider
Additionally, Snowflake can be hosted on any of the top three public cloud provides i.e. Azure, AWS and GCP across different regions, baring in mind that Snowflake accounts do not support multi-region deployments.
Loading TPC-DS Data
Data can be loaded into Snowflake is a number of ways, for example, using established ETL/ELT tools, using Snowpipe for continuous loading, WebUI or SnowSQL, and in a variety of formats e.g. JSON, AVRO, Parquet, CSV, Avro or XML. There are a few things to keep in mind when loading data into Snowflake which relate to file size, file splitting, file staging etc. The general recommendation is to produce files roughly 10MB to 100MB in size, compressed. Data loads of large Parquet files e.g. greater than 3GB could time out, therefore it is best practice to split those into smaller files to distribute the load among the servers in an active warehouse.
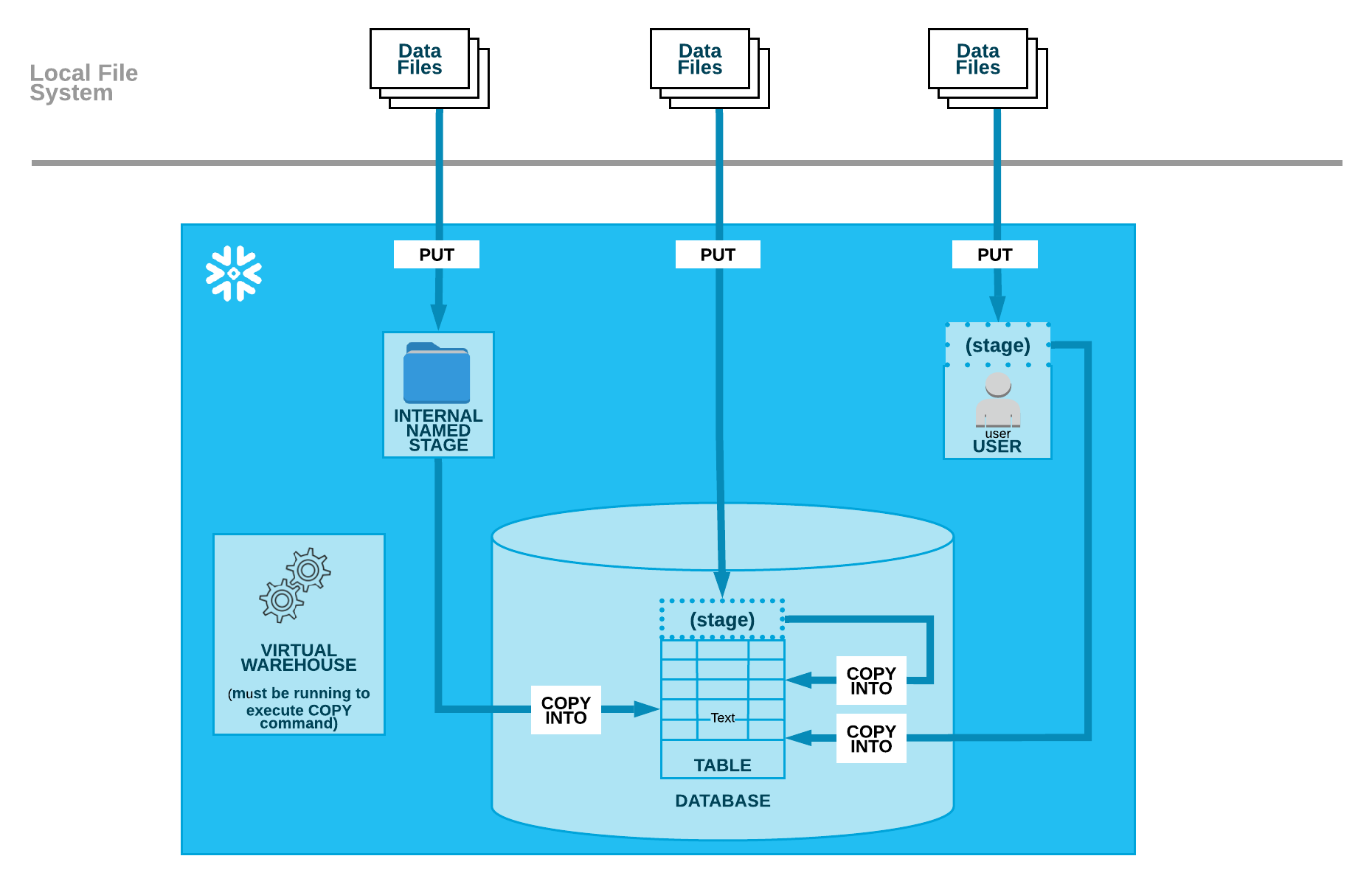
In order to run the TPC-DS queries on the Snowflake warehouse, I loaded the sample CSV-format data (scale factor of 100 and 300) from my local storage into the newly created schema using a small Python script. Snowflake also provides for staging files in public clouds object and blob storage e.g. AWS S3 but in this exercise, I transferred those from my local hard drive and staged them internally in Snowflake. As illustrated in the diagram below, loading data from a local file system is performed in two, separate steps:
Upload (i.e. stage) one or more data files to a Snowflake stage (named internal stage or table/user stage) using the PUT command
Use the COPY INTO command to load the contents of the staged file(s) into a Snowflake database table
As TPC-DS data does not conform to some of the requirements outlined above, the following script processed those files to ensure the format and size are consistent. The below script enables files format renaming (from DAT to CSV), breaking up larger files into smaller ones and removing trailing characters from line endings. It also creates the required TPC-DS schema and loads the pre-processed data into its objects.
#!/usr/bin/python
import snowflake.connector
from pathlib import PurePosixPath
import os
import re
import sys
from timeit import default_timer as timer, time
from humanfriendly import format_timespan
from csv import reader, writer
from multiprocessing import Pool, cpu_count
# define file storage locations variables
sql_schema = PurePosixPath("/Users/UserName/Location/SQL/tpc_ds_schema.sql")
tpc_ds_files_raw = PurePosixPath("/Volumes/VolumeName/Raw/")
tpc_ds_files_processed = PurePosixPath("/Volumes/VolumeName/Processed/")
# define other variables and their values
encoding = "iso-8859-1"
snow_conn_args = {
"user": "username",
"password": "password",
"account": "account_name_on_a_public_cloud",
}
warehouse_name = "TPCDS_WH"
db_name = "TPCDS_DB"
schema_name = "tpc_ds"
output_name_template = "_%s.csv"
file_split_row_limit = 10000000
def get_sql(sql_schema):
"""
Acquire sql ddl statements from a file stored in the sql_schema variable location
"""
table_name = []
query_sql = []
with open(sql_schema, "r") as f:
for i in f:
if i.startswith("----"):
i = i.replace("----", "")
table_name.append(i.rstrip("\n"))
temp_query_sql = []
with open(sql_schema, "r") as f:
for i in f:
temp_query_sql.append(i)
l = [i for i, s in enumerate(temp_query_sql) if "----" in s]
l.append((len(temp_query_sql)))
for first, second in zip(l, l[1:]):
query_sql.append("".join(temp_query_sql[first:second]))
sql = dict(zip(table_name, query_sql))
return sql
def process_files(
file,
tpc_ds_files_raw,
tpc_ds_files_processed,
output_name_template,
file_split_row_limit,
encoding,
):
"""
Clean up TPC-DS files (remove '|' row terminatinating characters)
and break them up into smaller chunks in parallel
"""
file_name = file[0]
line_numer = 100000
lines = []
with open(
os.path.join(tpc_ds_files_raw, file_name), "r", encoding=encoding
) as r, open(
os.path.join(tpc_ds_files_processed, file_name), "w", encoding=encoding
) as w:
for line in r:
if line.endswith("|\n"):
lines.append(line[:-2] + "\n")
if len(lines) == line_numer:
w.writelines(lines)
lines = []
w.writelines(lines)
row_count = file[1]
if row_count > file_split_row_limit:
keep_headers = False
delimiter = "|"
file_handler = open(
os.path.join(tpc_ds_files_processed, file_name), "r", encoding=encoding
)
csv_reader = reader(file_handler, delimiter=delimiter)
current_piece = 1
current_out_path = os.path.join(
tpc_ds_files_processed,
os.path.splitext(file_name)[0] +
output_name_template % current_piece,
)
current_out_writer = writer(
open(current_out_path, "w", encoding=encoding, newline=""),
delimiter=delimiter,
)
current_limit = file_split_row_limit
if keep_headers:
headers = next(csv_reader)
current_out_writer.writerow(headers)
for i, row in enumerate(csv_reader):
# pbar.update()
if i + 1 > current_limit:
current_piece += 1
current_limit = file_split_row_limit * current_piece
current_out_path = os.path.join(
tpc_ds_files_processed,
os.path.splitext(file_name)[0]
+ output_name_template % current_piece,
)
current_out_writer = writer(
open(current_out_path, "w", encoding=encoding, newline=""),
delimiter=delimiter,
)
if keep_headers:
current_out_writer.writerow(headers)
current_out_writer.writerow(row)
file_handler.close()
os.remove(os.path.join(tpc_ds_files_processed, file_name))
def build_schema(sql_schema, warehouse_name, db_name, schema_name, **snow_conn_args):
"""
Build TPC-DS database schema based on the ddl sql returned from get_sql() function
"""
with snowflake.connector.connect(**snow_conn_args) as conn:
cs = conn.cursor()
try:
cs.execute("SELECT current_version()")
one_row = cs.fetchone()
if one_row:
print("Building nominated warehouse, database and schema...")
cs.execute("USE ROLE ACCOUNTADMIN;")
cs.execute(
"""CREATE OR REPLACE WAREHOUSE {wh} with WAREHOUSE_SIZE = SMALL
AUTO_SUSPEND = 300
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = FALSE;""".format(
wh=warehouse_name
)
)
cs.execute("USE WAREHOUSE {wh};".format(wh=warehouse_name))
cs.execute(
"CREATE OR REPLACE DATABASE {db};".format(db=db_name))
cs.execute("USE DATABASE {db};".format(db=db_name))
cs.execute(
"CREATE OR REPLACE SCHEMA {sch};".format(sch=schema_name))
sql = get_sql(sql_schema)
for k, v in sql.items():
try:
k = k.split()[-1]
cs.execute(
"drop table if exists {sch}.{tbl};".format(
sch=schema_name, tbl=k
)
)
cs.execute(v)
except Exception as e:
print(e)
print("Error while creating nominated database object", e)
sys.exit(1)
except (Exception, snowflake.connector.errors.ProgrammingError) as error:
print("Could not connect to the nominated snowflake warehouse.", error)
finally:
cs.close()
def load_data(encoding, schema_name, db_name, tpc_ds_files_processed, **snow_conn_args):
"""
Create internal Snowflake staging area and load csv files into Snowflake schema
"""
stage_name = "tpc_ds_stage"
paths = [f.path for f in os.scandir(tpc_ds_files_processed) if f.is_file()]
with snowflake.connector.connect(**snow_conn_args) as conn:
cs = conn.cursor()
cs.execute("USE ROLE ACCOUNTADMIN;")
cs.execute("USE WAREHOUSE {wh};".format(wh=warehouse_name))
cs.execute("USE DATABASE {db};".format(db=db_name))
cs.execute("USE SCHEMA {sch};".format(sch=schema_name))
cs.execute("drop stage if exists {st};".format(st=stage_name))
cs.execute(
"""create stage {st} file_format = (TYPE = "csv"
FIELD_DELIMITER = "|"
RECORD_DELIMITER = "\\n")
SKIP_HEADER = 0
FIELD_OPTIONALLY_ENCLOSED_BY = "NONE"
TRIM_SPACE = FALSE
ERROR_ON_COLUMN_COUNT_MISMATCH = TRUE
ESCAPE = "NONE"
ESCAPE_UNENCLOSED_FIELD = "\\134"
DATE_FORMAT = "AUTO"
TIMESTAMP_FORMAT = "AUTO"
NULL_IF = ("NULL")""".format(
st=stage_name
)
)
for path in paths:
try:
file_row_rounts = sum(
1
for line in open(
PurePosixPath(path), "r+", encoding="iso-8859-1", newline=""
)
)
file_name = os.path.basename(path)
# table_name = file_name[:-4]
table_name = re.sub(r"_\d+", "", file_name[:-4])
cs.execute(
"TRUNCATE TABLE IF EXISTS {tbl_name};".format(
tbl_name=table_name)
)
print(
"Loading {file_name} file...".format(file_name=file_name),
end="",
flush=True,
)
sql = (
"PUT file://"
+ path
+ " @{st} auto_compress=true".format(st=stage_name)
)
start = timer()
cs.execute(sql)
sql = (
'copy into {tbl_name} from @{st}/{f_name}.gz file_format = (ENCODING ="iso-8859-1" TYPE = "csv" FIELD_DELIMITER = "|")'
' ON_ERROR = "ABORT_STATEMENT" '.format(
tbl_name=table_name, st=stage_name, f_name=file_name
)
)
cs.execute(sql)
end = timer()
time = round(end - start, 1)
db_row_counts = cs.execute(
"""SELECT COUNT(1) FROM {tbl}""".format(tbl=table_name)
).fetchone()
except (Exception, snowflake.connector.errors.ProgrammingError) as error:
print(error)
sys.exit(1)
finally:
if file_row_rounts != db_row_counts[0]:
raise Exception(
"Table {tbl} failed to load correctly as record counts do not match: flat file: {ff_ct} vs database: {db_ct}.\
Please troubleshoot!".format(
tbl=table_name,
ff_ct=file_row_rounts,
db_ct=db_row_counts[0],
)
)
else:
print("OK...loaded in {t}.".format(
t=format_timespan(time)))
def main(
sql_schema,
warehouse_name,
db_name,
schema_name,
tpc_ds_files_raw,
tpc_ds_files_processed,
output_name_template,
file_split_row_limit,
encoding,
**snow_conn_args
):
"""
Rename TPC-DS files, do a row count for each file to determine the number of smaller files larger ones need to be split into
and kick off parallel files cleanup and split process. Finally, kick off schema built and data load into Snowflake
"""
for file in os.listdir(tpc_ds_files_raw):
if file.endswith(".dat"):
os.rename(
os.path.join(tpc_ds_files_raw, file),
os.path.join(tpc_ds_files_raw, file[:-4] + ".csv"),
)
fileRowCounts = []
for file in os.listdir(tpc_ds_files_raw):
if file.endswith(".csv"):
fileRowCounts.append(
[
file,
sum(
1
for line in open(
os.path.join(tpc_ds_files_raw, file),
encoding=encoding,
newline="",
)
),
]
)
p = Pool(processes=cpu_count())
for file in fileRowCounts:
p.apply_async(
process_files,
[
file,
tpc_ds_files_raw,
tpc_ds_files_processed,
output_name_template,
file_split_row_limit,
encoding,
],
)
p.close()
p.join()
build_schema(sql_schema, warehouse_name, db_name,
schema_name, **snow_conn_args)
load_data(encoding, schema_name, db_name,
tpc_ds_files_processed, **snow_conn_args)
if __name__ == "__main__":
main(
sql_schema,
warehouse_name,
db_name,
schema_name,
tpc_ds_files_raw,
tpc_ds_files_processed,
output_name_template,
file_split_row_limit,
encoding,
**snow_conn_args
)
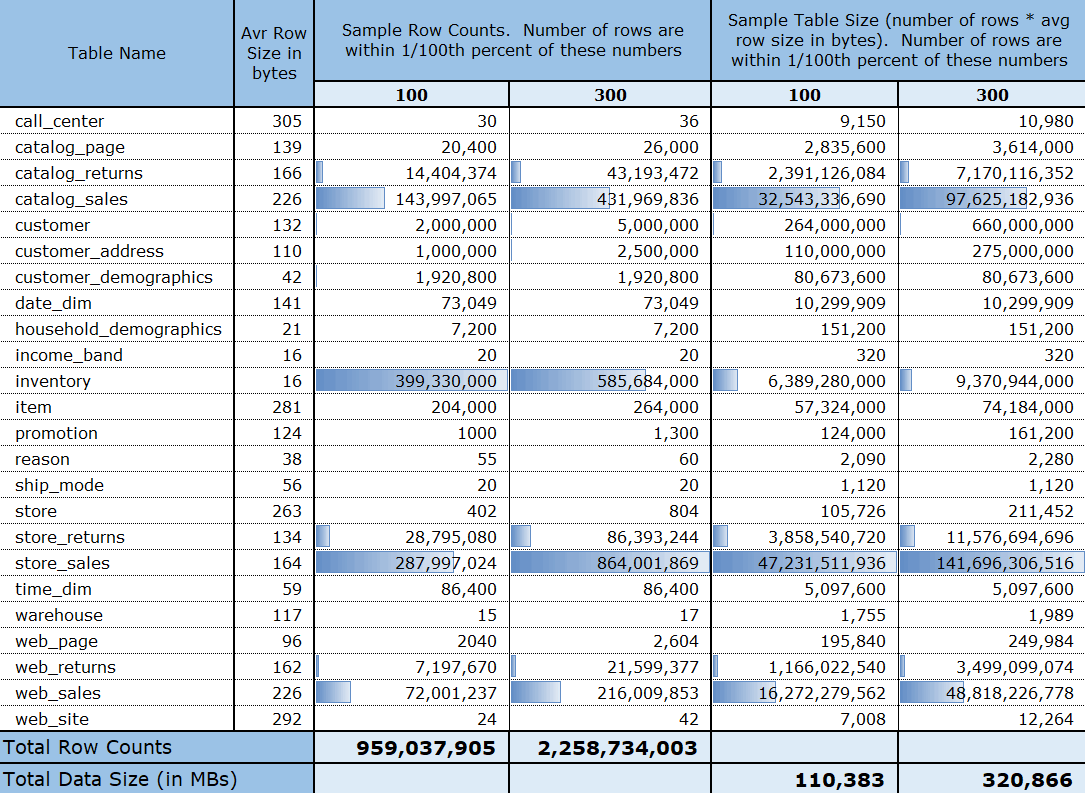
Once executed, the script produced 246 CSV files (up from 26 in the original data set) and on load completion, the following data volume (uncompressed) and row count metadata was created in Snowflake warehouse.
TPC-DS Benchmark Sample
Although Snowflake conveniently provides 10TB and 100TB versions of TPC-DS data, along with samples of all the benchmark’s 99 queries, I really wanted to go through the whole process myself to help me understand the service and tooling it provides in more details. In hindsight, it turned out to be an exercise in patience thanks to my ISP’s dismal upload speed so if you’re looking at kicking the tires and simply running a few queries yourself, it may be quicker to use Snowflake’s provided data sets.
It is worth mentioning that no performance optimisation was performed on the queries, data or system itself. Unlike other vendors which allows their administrators to fine-tune various aspects of its operation through mechanisms such as statistics update, table partitioning, creating query or workload-specific projections, tuning execution plans etc. Snowflake obfuscates a lot of those details away. Beyond elastically scaling compute down or up or defining cluster key to help with execution on very large tables, there is very little knobs and switches one can play with. That’s a good thing and unless you’re a consultant making money helping your clients with performance tuning, many engineers will be happy to jump on the bandwagon for this reason alone.
Also, data volumes analysed in this scenario do not follow the characteristics and requirements outline by the TPC organisation and under these circumstances would be considered an ‘unacceptable consideration’. For example, a typical benchmark submitted by a vendor needs to include a number of metrics beyond query throughput e.g. a price-performance ratio, data load times, the availability date of the complete configuration etc. The following is a sample of a compliant reporting of TPC-DS results: ‘At 10GB the RALF/3000 Server has a TPC-DS Query-per-Hour metric of 3010 when run against a 10GB database yielding a TPC-DS Price/Performance of $1,202 per query-per-hour and will be available 1-Apr-06’. As this demo and the results below go only skin-deep i.e. query execution times, the results are only indicative of the performance level in the context of the same data and configuration used.
OK, now with this little declaimer out of the way let’s look at how the 24 queries performed across the two distinct setups i.e. a Small warehouse and a Large warehouse across 100GB and 300GB datasets. I used the following Python script to return queries execution time.
#!/usr/bin/python
import configparser
import sys
from os import path, remove
from pathlib import PurePosixPath
import snowflake.connector
from timeit import default_timer as timer
from humanfriendly import format_timespan
db_name = "TPCDS_DB"
schema_name = "tpc_ds"
warehouse_name = "TPCDS_WH"
snow_conn_args = {
"user": "username",
"password": "password",
"account": "account_name_on_a_public_cloud",
}
sql_queries = PurePosixPath(
"/Users/UserName/Location/SQL/tpc_ds_sql_queries.sql"
)
def get_sql(sql_queries):
"""
Source operation types from the tpc_ds_sql_queries.sql SQL file.
Each operation is denoted by the use of four dash characters
and a corresponding query number and store them in a dictionary
(referenced in the main() function).
"""
query_number = []
query_sql = []
with open(sql_queries, "r") as f:
for i in f:
if i.startswith("----"):
i = i.replace("----", "")
query_number.append(i.rstrip("\n"))
temp_query_sql = []
with open(sql_queries, "r") as f:
for i in f:
temp_query_sql.append(i)
l = [i for i, s in enumerate(temp_query_sql) if "----" in s]
l.append((len(temp_query_sql)))
for first, second in zip(l, l[1:]):
query_sql.append("".join(temp_query_sql[first:second]))
sql = dict(zip(query_number, query_sql))
return sql
def run_sql(
query_sql, query_number, warehouse_name, db_name, schema_name
):
"""
Execute SQL query as per the SQL text stored in the tpc_ds_sql_queries.sql
file by it's number e.g. 10, 24 etc. and report returned row number and
query processing time
"""
with snowflake.connector.connect(**snow_conn_args) as conn:
try:
cs = conn.cursor()
cs.execute("USE ROLE ACCOUNTADMIN;")
cs.execute("USE WAREHOUSE {wh};".format(wh=warehouse_name))
cs.execute("USE DATABASE {db};".format(db=db_name))
cs.execute("USE SCHEMA {sch};".format(sch=schema_name))
query_start_time = timer()
rows = cs.execute(query_sql)
rows_count = sum(1 for row in rows)
query_end_time = timer()
query_duration = query_end_time - query_start_time
print(
"Query {q_number} executed in {time}...{ct} rows returned.".format(
q_number=query_number,
time=format_timespan(query_duration),
ct=rows_count,
)
)
except (Exception, snowflake.connector.errors.ProgrammingError) as error:
print(error)
finally:
cs.close()
def main(param, sql):
"""
Depending on the argv value i.e. query number or 'all' value, execute
sql queries by calling run_sql() function
"""
if param == "all":
for key, val in sql.items():
query_sql = val
query_number = key.replace("Query", "")
run_sql(
query_sql,
query_number,
warehouse_name,
db_name,
schema_name
)
else:
query_sql = sql.get("Query" + str(param))
query_number = param
run_sql(
query_sql,
query_number,
warehouse_name,
db_name,
schema_name
)
if __name__ == "__main__":
if len(sys.argv[1:]) == 1:
sql = get_sql(sql_queries)
param = sys.argv[1]
query_numbers = [q.replace("Query", "") for q in sql]
query_numbers.append("all")
if param not in query_numbers:
raise ValueError(
"Incorrect argument given. Looking for <all> or <query number>. Specify <all> argument or choose from the following numbers:\n {q}".format(
q=", ".join(query_numbers[:-1])
)
)
else:
param = sys.argv[1]
main(param, sql)
else:
raise ValueError(
"Too many arguments given. Looking for 'all' or <query number>."
)
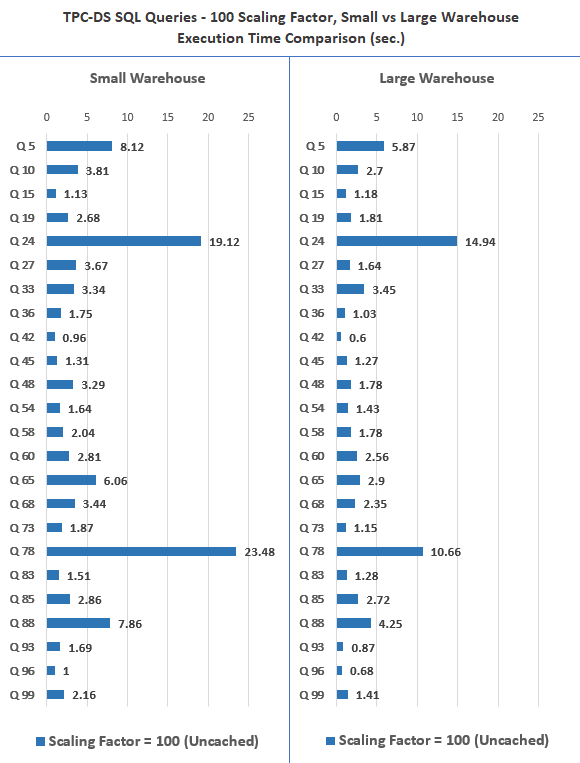
First up is the 100GB dataset, with queries running on empty cache (cached results were sub-second therefore I did not bother to graph those here), across Small and Large warehouses. When transitioning from the Small to the Large warehouse, I also dropped the existing warehouse (rather than resizing it), created a new one and re-populated it to ensure that not data is returned from cache.
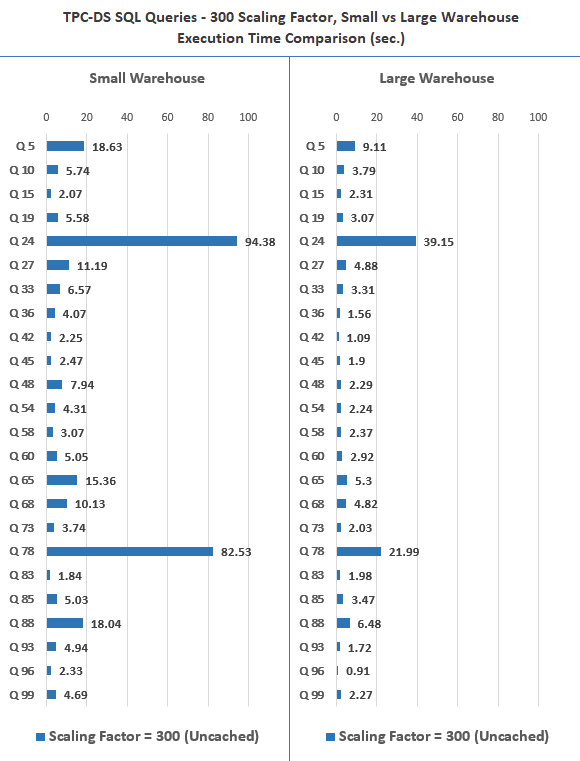
While these results and test cases are probably not truly representative of the ‘big data’ workloads, they provide a quick snapshot of how traditional analytical workloads would perform on the Snowflake platform. Scanning large tables with hundreds of millions of rows seemed to perform quite well, and, for the most part, performance differences were consistent with the increase in compute capacity. Cached queries run nearly instantaneously so looking at the execution pattern for cached vs non-cached results there was contest (and no point in comparing and graphing the results). Interestingly, I did a similar comparison for Google’s BigQuery platform (link HERE) and Snowflake seems to perform a lot better in this regard i.e. cached results are returned with low latency, usually in less than one second. Next up I graphed the 300GB scaling factor, again repeating the same queries across Small and Large warehouse size.
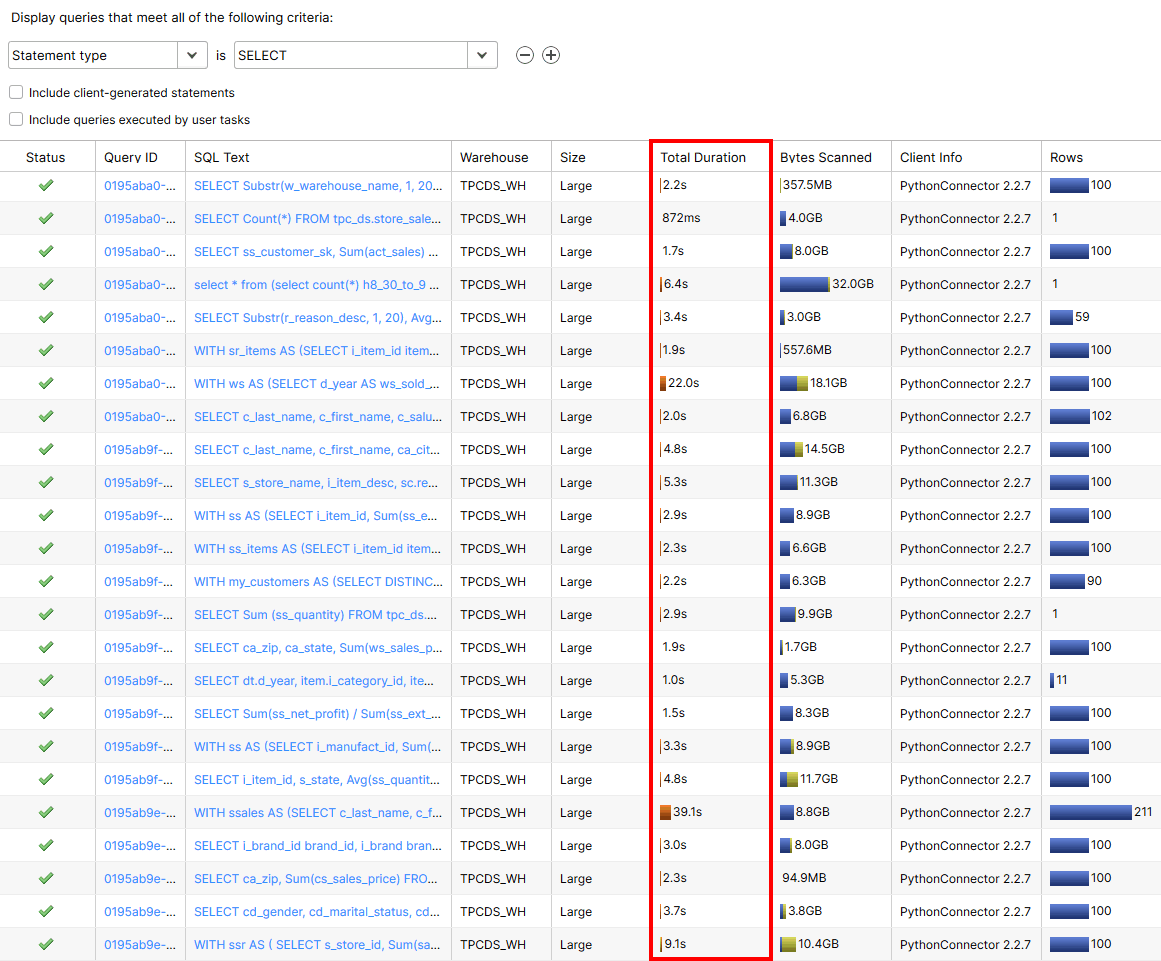
Snowflake’s performance on the 300GB dataset was very good and majority of the queries returned relatively fast. Side by side, it is easy to see the difference the larger compute allocation made to queries’ execution time, albeit at the cost of increased credits usage. Current pricing model dictates that Large warehouse is 4 times as expensive as a Small one. Given the price of a credit (standard, single-cluster warehouse) in AWS Sydney region is currently set to USD 2.75, 22 dollars per hour for the Large warehouse (not including storage and cloud services cost), it becomes a steep proposition at close to AUD 100K/year (assuming that only 12/24 hours will be charged and only during work days). Cost notwithstanding, Snowflake is a powerful platform and the ability to crunch a lot of data at this speed and on demand is commendable. Although a bit of an apples-to-oranges comparison, you can also view how BigQuery performed on exactly identical datasets in one of my previous posts HERE. Also, just for reference, I below is an image of metadata maintained by Snowflake itself on all activities across the warehouse, filtered to display only SELECT statements information (un-cached 300GB Large warehouse run in this case).
Snowflake Reference Architectures
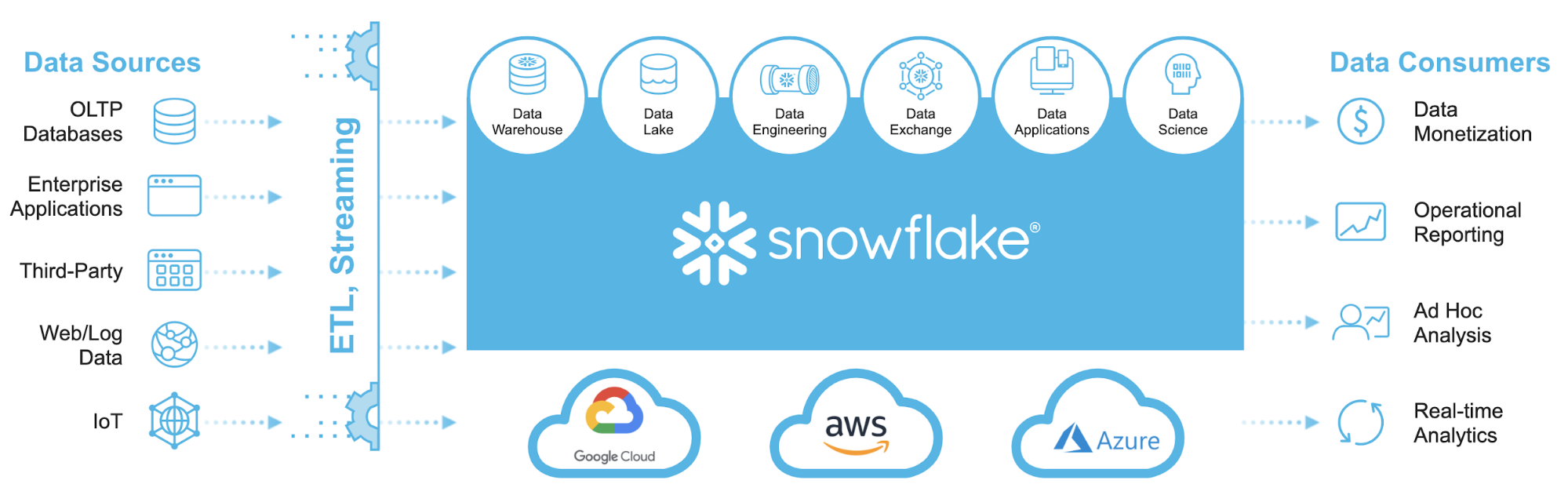
What I’m currently seeing in the industry from the big data architecture patterns point of view is that business tend to move towards deployments favored by either data engineering teams or BI/Analytics teams. The distinction across those two groups is heavily determined by the area of expertise and the tooling used, with DE shops more reliant on software engineering paradigms and BI folks skills skewed more towards SQL for most of their data processing needs. This allows teams not versed in software development to use vanilla SQL to provision and manage most of their data-related responsibilities and therefore Snowflake to effectively replace development-heavy tasks with the simplicity of its platform. Looking at what an junior analyst can achieve with just a few lines of SQL in Snowflake allows many businesses to drastically simplify and, at the same time, supercharge their analytical capability, all without the knowledge of programming in Scala or Python, distributed systems architecture, bespoke ETL frameworks or intricate cloud concepts knowledge. In the past, a plethora of tools and platforms would be required to shore up analytics pipelines and workloads. With Snowflake, many of those e.g. traditional, files-based data lakes, semi-structured data stores etc. can become redundant, with Snowflake becoming the linchpin of the enterprise information architecture.
The following are some examples of reference architectures used across several use cases e.g. IoT, streaming data stack, ML and data science, demonstrating Snowflake’s capabilities in supporting those varied scenarios with their platform.
Conclusion
Data warehousing realm has been dominated by a few formidable juggernauts of this industry and no business outside of few start-ups would be willing to bet their data on an up-and-coming entrant who is yet to prove itself. A few have tried but just as public cloud space is starting to consolidate and winners take it all, data warehousing domain has always been difficult to disrupt. In the ever-expanding era of cloud computing, many vendors are rushing to retool and retrofit their existing offering to take advantage of this new paradigm, but ultimately few offer innovative and fresh approaches. Starting from the ground-up and with no legacy and technical debt to worry about, Snowflake clearly is trying to reinvent the approach and I have to admit I was quite surprised by not only how well Snowflake performed in my small number of tests but also how coherent the vision is. They are not trying to position themselves as the one-stop-shop for ETL, visualisation and data warehousing. There is no mention of running their workloads on GPUs or FPGAs, no reference to Machine Learning or AI (not yet anyway) and on the face value, the product is just a reinvented data warehouse cloud appliance. Some may consider it a shortcoming as integration with other platforms, services and tools (something that Microsoft and AWS are doing so well) may be a paramount criterion. However, this focus on ensuring that the one domain they’re targeting gets the best engineering in its class is clearly evident. Being Jack of all trades and master of none may work for the Big Cheese so Snowflake is clearly trying to come up with a superior product in a single vertical and not devalue their value proposition – something that they have been able to excel at so far.
After nearly 15 years of working in the information management field and countless encounters with different vendors, RDBMSs, platforms etc. Snowflake seems like a breath of fresh air to me. It supports a raft of different connectors and drivers, speaks plain SQL, is multi-cloud, separates storage from compute, scales automatically, requires little to no tuning and performs well. It also comes with some great feature built-in, something that in case of other vendors may require a lot of configuration, expensive upgrades or even bespoke development e.g. time travel, zero-copy cloning, materialized views, data sharing or continuous data loading using Snowpipe. On the other hand, there are a few issues which may become a deal-breaker for some. A selection of features is only available in the higher (more expensive) tiers e.g. time travel or column-level security, there is no support for constraints and JavaScript-based UDFs/stored procedures are a pain to use. The Web UI is clean but a bit bare-bones and integration with some of the legacy tools may prove to be challenging. Additionally, the sheer fact that you’re not in control of the infrastructure and data (some industries are still limited to how and where their data is stored) may turn some interested parties away, especially that MPP engines like Greenplum, Vertica or ClickHouse can be deployed on both private and public clouds. Below is an excerpt from 2020 Gartner Magic Quadrant for Cloud Database Management Systems, outlining Snowflake’s core strengths and weaknesses.
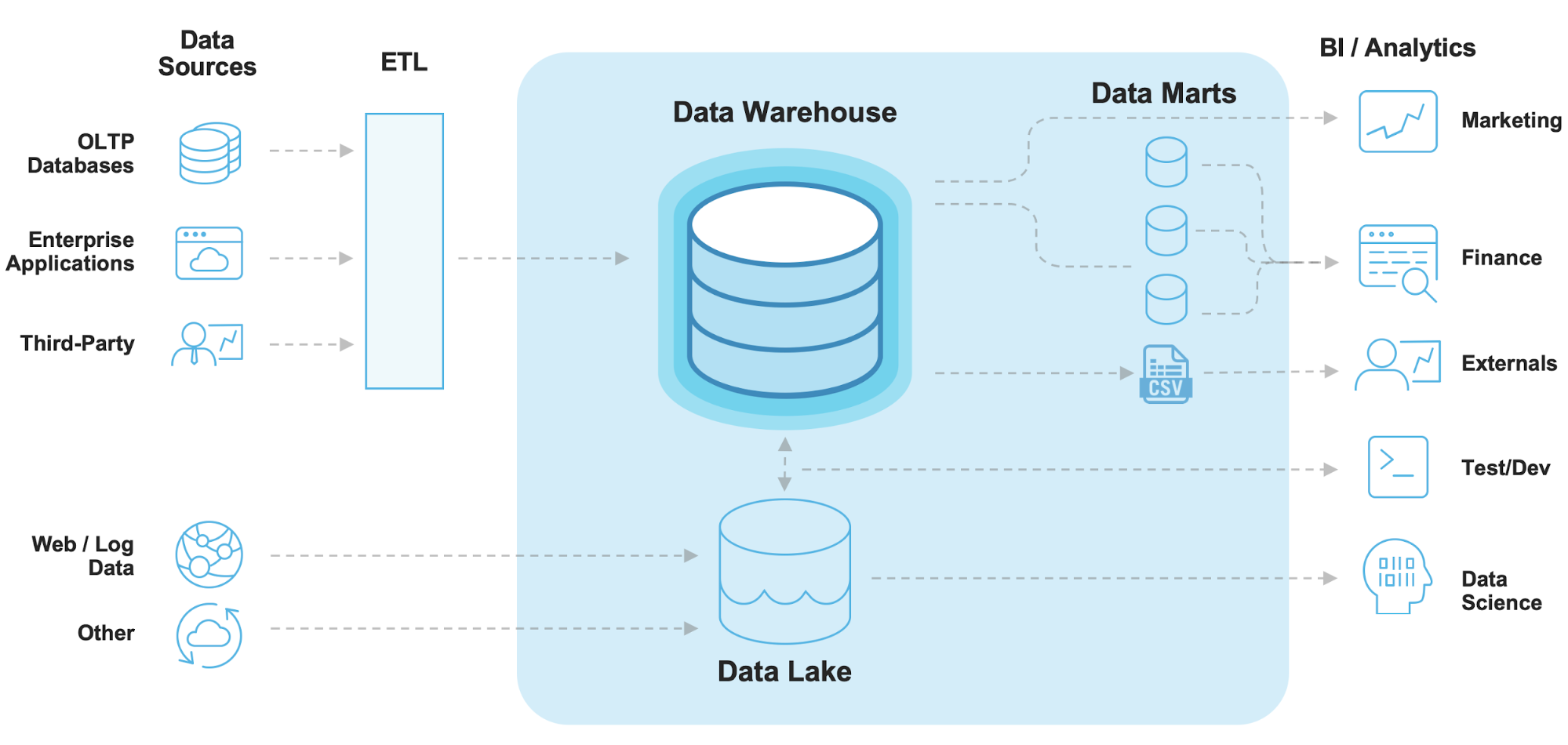
What I personally liked the most about this service is how familiar and simple it is, while providing all required features in a little to no-ops package. I liked the fact that in spite of all the novel architecture it’s built on, it feels just like another RDBMS. If I could compare it to a physical thing, it would be a (semi)autonomous electric car. Just like any automobile, EVs sport four wheels, lights, doors and everything else that unmistakably make them a vehicle. Likewise, Snowflake speaks SQL (a 40 years old language), has tables, views, UDFs and has all the features traditional databases have had for decades. However, just as the new breed of autonomous cars don’t come with a manual transmission, gas-powered engines, detailed mechanical service requirements or even a steering wheel, Snowflake looks to be built for the future, blending old-school familiarity and pioneering technology together. It is no-fuss, low-ops, security-built-in, cloud-only service which feels instantaneously recognizable and innovative at the same time. It’s not your grandpa’s data warehouse and, in my view, it has nearly all the features to rejuvenate and simplify a lot of the traditional BI architectures. The following is a comparison of a traditional vs contemporary data warehouse architectures, elevating Snowflake to the centerpiece of the data storage and processing platform.
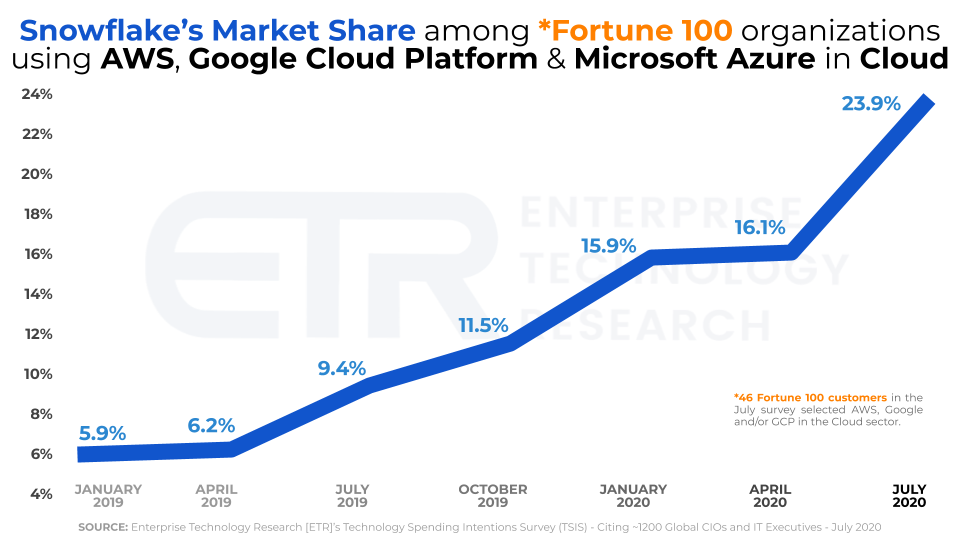
Many vendors are rushing to adapt and transform their on-premise-first data warehouse software with varied success. Oracle, IBM or Microsoft come to mind when looking at a popular RDBMSs engines running predominantly in customers’ data centers. All of those vendors are now pushing hard to customize their legacy products and ensure that the new iteration of their software is cloud-first but existing technical debt and the scope of investment already made may create unbreakable shackles, stifling innovation and compromising progress. Snowflake’s new approach to solving data management problems has gained quite a following and many companies are jumping on board in spite the fact that they are not affiliated with any of the major cloud vendors and the competition is rife – only last week Google announced BigQuery Omni. Looking at one of the most recent Data Warehouse market analysis (source HERE), Snowflake has been making some serious headway among Fortune 100 companies and is quickly capitalizing on its popularity and accelerating adoption rate. The chart below is a clear evidence of this and does not require any explanation – Snowflake is on a huge roll.
It’s still early days and time will tell if Snowflake can maintain the momentum but having spent a little time with it, I understand the appeal and why their service is gaining in popularity. If I was looking at storing and processing large volume of data and best of breed data warehousing capability, Snowflake would definitely be on my shopping list.
My name is Martin and this site is a random collection of recipes and reflections about various topics covering information management, data engineering, machine learning, business intelligence and visualisation plus everything else that I fancy to categorise under the 'analytics' umbrella. I'm a native of Poland but since my university days I have lived in Melbourne, Australia and worked as a DBA, developer, data architect, technical lead and team manager. My main interests lie in both, helping clients in technical aspects of information management e.g. data modelling, systems architecture, cloud deployments as well as business-oriented strategies e.g. enterprise data solutions project management, data governance and stewardship, data security and privacy or data monetisation. On the whole, I am very fond of anything closely or remotely related to data and as long as it can be represented as a string of ones and zeros and then analysed and visualised, you've got my attention!
Outside sporadic updates to this site I typically find myself fiddling with data, spending time with my kids or a good book, the gym or watching a good movie while eating Polish sausage with Zubrowka (best served on rocks with apple juice and a lime twist). Please read on and if you find these posts of any interests, don't hesitate to leave me a comment!