September 16th, 2013 / 12 Comments » / by admin
In this PREVIOUS POST I focused on the concepts of SSAS solution deployment and cube creation as well as went through some basic validation techniques to ensure that our data mart has correct data in it before it can be reported out of. This final post deals with reporting out of our data mart using SQL Server Reporting Services (SSRS) – another application being part of the comprehensive Microsoft BI stack (I have already covered SSIS and SSAS in previous posts).
There are many different ways to report on data stored in the data mart. For impromptu and ad hoc data analysis Excel cannot be beaten on user friendliness and ease of development. Having said that, I have seen many Excel reports which were more like stand-alone applications, with thousands of lines of VBA code mixed with SQL and MDX so given this tool’s flexibility, I would not dismiss it as lightweight and simple. Also, given that Excel seems to be getting all the attention as far as the direction Microsoft wants to take its reporting tools in, with many bells and whistles, particularly in version 2013, it is expected that Excel, not other applications will gain traction over the coming years. For more ‘pixel-perfect’ reports however, SSRS is still a great and powerful tool to use and it will be the focus of this post.
There are two applications that SSRS reports can build in: Report Builder and Visual Studio. Report Builder is designed to be user-friendly, and its GUI interface is designed to have the look and feel of Microsoft Office so that developers accustomed to building reports in either Microsoft Access or Excel will feel right at home. Unlike Visual Studio, Report Builder is not automatically installed when you install SQL Server 2012. It must be downloaded from the Internet and installed separately. Report Builder is designed for casual developers. It provides most, but not all, of the features that come with Visual Studio. For more feature-rich development, Visual Studio’s Reporting Services project provides full-featured development. With it you can accomplish everything that can be done in Report Builder, plus you have the ability to manage multiple files concurrently, work directly with source control, and include the Reporting Services project in the same solution as SSIS and SSAS projects.
There are many aspects of Reporting Services that an astute developer would have to get acquainted with e.g. SSRS administrative services, SSRS configuration manager, deployment and scheduling process etc. They won’t be covered here but there is copious amount of information on the internet relating to the management side of SSRS specifically. Without further ado, let’s jump into creating our first SSRS report based on the data in our data mart. Let’s open up Visual Studio and create a new project selecting Report Server Project from the options provided.
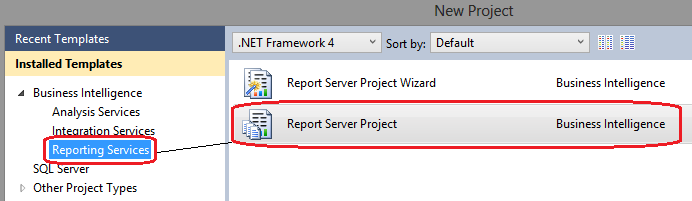
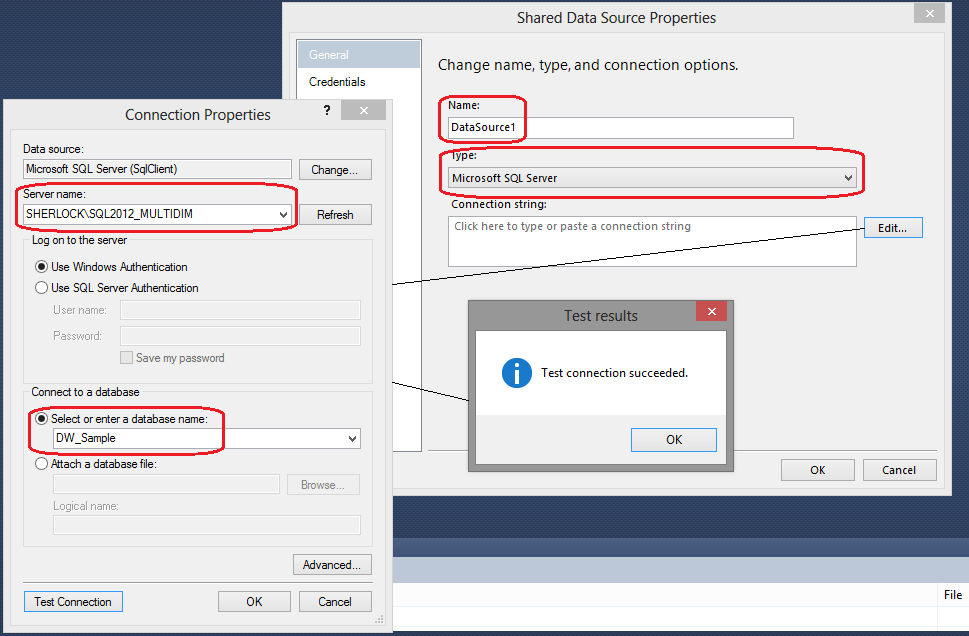
Once the project has been created, you can see it in Solution Explorer. Next, let’s create one or more data sources. Data sources provide the connection information for your reports. To create a shared data source, right-click the folder called Shared Data Sources and select the Add New Data Source option from the context menu. The Shared Data Source Properties dialog window will appear. In the Shared Data Source Properties dialog window, you enter a name for your new data source, select the type of connection to create, and provide a connection string as per image below.
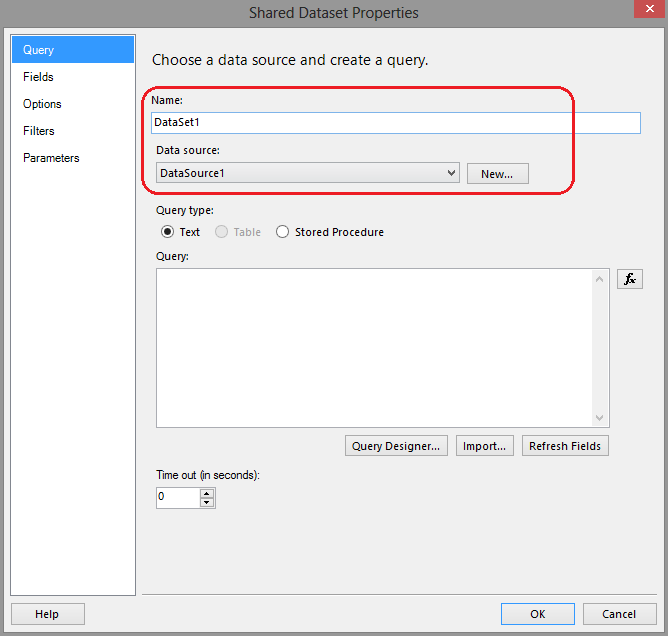
After we create our data sources, we then make one or more datasets. Datasets contain query string used to generate report data. The query string language is dependent on which type of connection is used. For example, if you are connecting to a SQL Server database, use the SQL language. If you are connecting to an Analysis Server database, use a language such as MDX. To create a shared dataset, right-click the Shared Datasets folder in Solution Explorer and choose Add New Dataset from the context menu. A Shared Dataset Properties dialog window appears where you can identify the name, data source, query type, and query for the dataset as per image below. Let’s not populate the query pane with any SQL just yet and leave it blank.
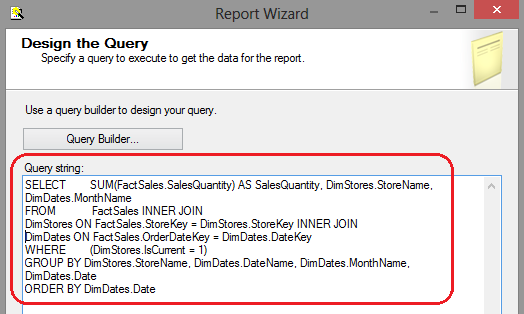
Once our data source and initial dataset have been defined, right-clicking the Reports folder in Solution Explorer and choosing Add New Report. This will trigger the wizard which we can use to define our report data source and the query which will drive the reports data. Next, on the Design the Query pane, enter the following SQL.
1 2 3 4 5 6 7 | SELECT SUM(FactSales.SalesQuantity) AS SalesQuantity, DimStores.StoreName, DimDates.DateName
FROM FactSales INNER JOIN
DimStores ON FactSales.StoreKey = DimStores.StoreKey INNER JOIN
DimDates ON FactSales.OrderDateKey = DimDates.DateKey
WHERE (DimStores.IsCurrent = 1)
GROUP BY DimStores.StoreName, DimDates.DateName, DimDates.Date
ORDER BY DimDates.Date
|
At this stage the wizard should look as per image blow.
When on Select the Report Type step, click on Matrix radio button. Click Next to proceed to Design the Matrix step and adjust the properties as per image below.
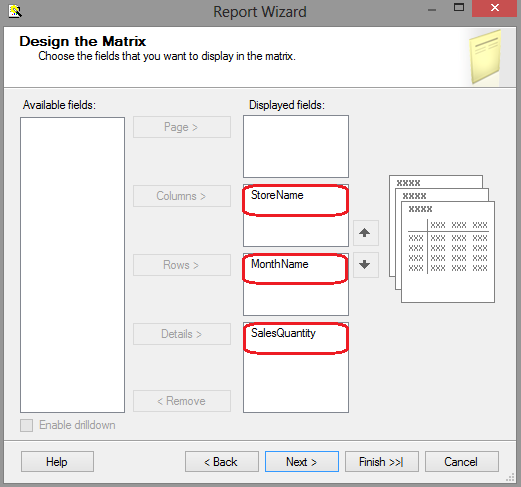
Continuing on, you can choose to finish the wizard or go to next step to adjust the theme you wish to apply and assign the report name. When completed, click on Finish to conclude the wizard. At this stage all we have is a very simple sales matrix with sales amount measures partitioned by store name and particular month. You can also see a tree-view of individual objects which make up this report on the left-hand side with data sources, data sets and individual attributes coming from data mart tables. We can run the report clicking on Preview button in the top left corner of the design pane.
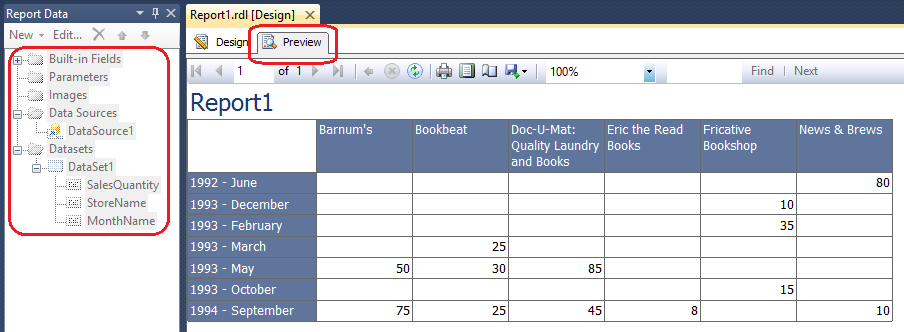
At this point the report looks quite simplistic and there is no level of interactivity. It may be OK for someone who would only run it to export the results to Excel and do further manipulation on the data or for someone who gets it emailed every day/month to casually look at the figures for any deviations from the norm. However, as it was the case with SSIS in POST 4, there is much more you can do in order to make it more functional, easy on the eye and interactive. SSRS allows the concept of parameters which you can use to slice/filter data before it gets outputted onto the report. There is a large number of components available (either default ones from the Visual Studio project toolbar or third party) which can really bring your reports to life so extensibility is not a problem. Below is a sample image of the same report with a few extra components added to make it look more dashboard-like (click on the image to enlarge it). This took only a few minutes to put together but the result is a report which is more visually appealing and a little bit more interactive (I included one parameter as a drop-down list with multiple values allowed to be selected in the top, left corner which permits end-users to filter the data based on the StoreName attribute).
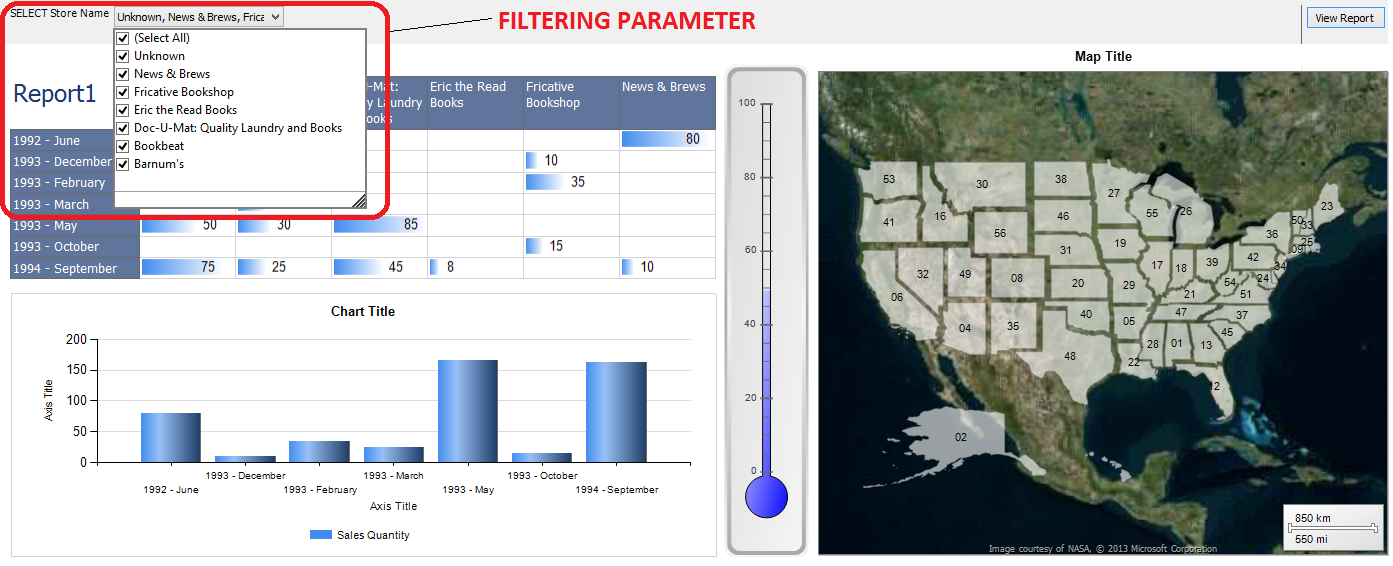
All additional components in this report are included in SSRS (2012 version) by default so you can really come a long way before running out of customisation options with just out-of-the-box functionality e.g. gauges, Bing maps, sparklines and of course .Net extensibility. If you want something more interactive e.g. more analytical reporting with real-time, dynamically driven interface, there is lots of options out there. Excel should not disappoint if you already have a solid investment in Microsoft stack. Version 2013, with the inclusion of PowerView, PowerPivot, PowerMap etc. is a terrific option for self-service, dynamic data analysis. This, coupled with SharePoint deployment and SQL Server database(s) should provide an enterprise ready solution for most of your needs. Otherwise, vendors such as Tableau, ClickView or SAP with its Lumira are pretty good but the price may prove to be prohibitive for many.
This concludes this post and this series (eight posts altogether). If you stumble upon this or any other post from the ‘How To Build A Data Mart’ collection on my blog don’t hesitate to leave me a comment – any feedback is appreciated, good or bad! As usual, solution files for this SSRS project as well as all other posts for this series can be found and downloaded from HERE.
Please also check other posts from this series:
Posted in: How To's, SQL, SSRS
Tags: SQL, SSRS
September 16th, 2013 / No Comments » / by admin
In the PREVIOUS POST I showed you how to refine our SSAS project and went over the concepts of dimension properties and hierarchies before cube creation and deployment process can be initiated. In this post I would like to focus on the concepts of SSAS solution deployment and cube creation as well as go through some basic validation techniques to ensure that our data mart has correct data in it before it can be reported out of.
Creating The SSAS Cube
Let’s continue on with the sample SSAS project which we polished up last time. All files relevant to further develop, deploy and test this solution as well as all the code used in previous posts to this series can be found HERE. In order to browse the dimensions we must first deploy them to our SSAS database. Visual Studio uses XML files for data sources, data source views, dimensions, and cubes, and there is a hidden master file that contains all of this code. The act of building of an SSAS project checks the validity of these files and combines them into this master file. The quickest way to deploy is to it from Visual Studio environment itself, however, we must first specify the SSAS instance we would like our database to be created on. To do this, right-click on root level of the project in Solution Explorer and select Properties as per image below (Alt + Enter should also work).
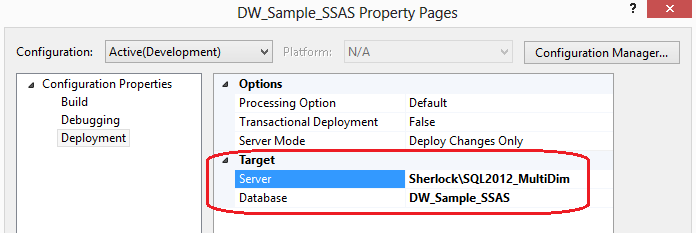
Next, select Deployment option from the Configuration Properties pane and populate the Target Server and Target Database as per below.
To process individual dimension we have meticulously created and deploy the data onto our SSAS server we can right-click on each dimension individually and select Process from the options provided. This should present us with another dialog window where providing we have done correct modelling decisions we can select Run to process our dimension. In case there are errors and you cannot deploy the data onto the specified SSAS server, go through the log to establish the cause for the issues which in most cases would pertain to the connection credentials or target deployment properties.
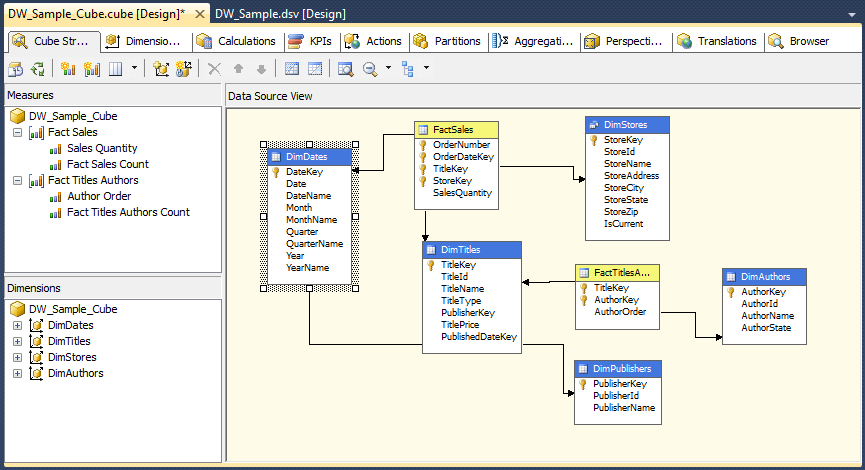
Finally, let’s look into how to create an SSAS cube. In order to start the cube wizard, right-click on the Cubes folder under solution explorer and select New Cube – this should start the wizard which will guide us through this process and is similar to the steps taken in order to create individual dimensions. After the welcome pane is displayed, click Next and on Select Creation Method click on Use Existing Tables from the options provided. Next step prompts us to select tables used for measure groups. This window allows you to choose which fact tables will be included in the cube. In our example, we have two fact tables: one that contains the measures and one that is used as a bridge between the Authors many-to-many dimension – let’s select them both and click next to continue with the wizard. In the next step, the wizard suggests columns and measures to use by comparing the columns’ data types. For example, Author Order is recommended as a measure because it is a fact table and it has a numeric value. This simple criteria is how the wizard decides what should and should not be included. You will also notice that Fact Sales Count and Fact Titles Authors Count have been added. The wizard suggests these additional measures to provide row counts for Fact Sales and Fact Titles Authors for your convenience, in case you need totals for each. The wizard labels these as Count measures for you, but you can change the names if you prefer. Following on, we select the four previously created dimensions and in the next step give our cube a meaningful name which should conclude the wizard. On completion Visual Studio displays cube designer window as per image below.
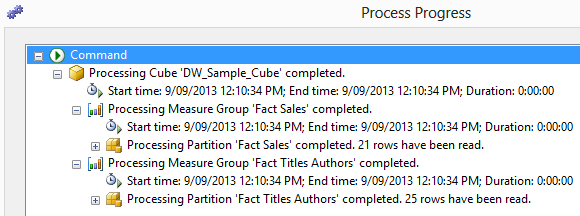
All there is left to do is to deploy the cube onto our server, configure it and test the data for any inconsistencies. The quickest way to deploy this is to right-click on the cube and select Process from the context menu provided. Once the process is completed, the following window should notify you of the process success/failure and the steps taken during cube processing and deployment.
There are other steps involved in further cube configuration which depends on the project requirements e.g. setting up translations, creating partitions, defining perspectives, adding custom calculations etc. however, given the intended purpose of this series I will not expand on those here. However, just like dimension, the cube also requires certain level of configuration input and validation so le’s run through those here.
Most of the cube configuration is done through adjusting the settings on the cube designer tabs. Each of those tabs is responsible for different cube properties. The image below shows the tabs selection for cube designer.

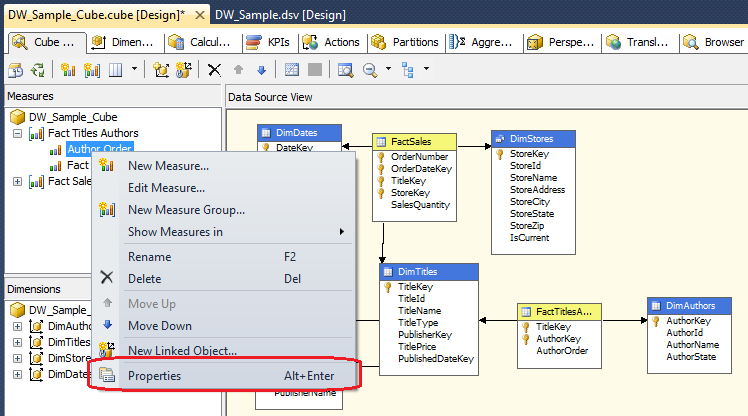
As far as configuring the properties of each measure and dimension which constitutes the cube content, these are usually accessed through the properties window on the Cube Structure tab. If you can’t see in it should be as easy as right-clicking on individual fact or dimension and selecting Properties from the context menu as per below.
To save space and leave the most procedural tasks out of this post I have put together a document which can be downloaded from HERE. It outlines the changes necessary to be made in order to configure the cube and its properties. Alternatively, you can view and download all the necessary files for this and other posts for this series from HERE.
Database vs. Cube Data Validation
Finally, let’s superficially validate the figures in the cube versus data warehouse objects to find out if what we have put together checks out and is a valid representation of our measures and dimensions. There are many very elaborate methods of validating the data between SSAS and database objects and in this post I will cover two ways of testing to highlight the potential discrepancies. The easiest way to compare the data between what’s in the cube and on the table level is to navigate to the Browser tab from the cube designer window (last tab) and drag desired measures and dimensions onto the query pane. This process is very much like building a pivot table in Excel and once the objects data is displayed and aggregated we can conveniently export the results into Excel straight from the SSAS project (version 2012 and up only) with a click of a button as per below.
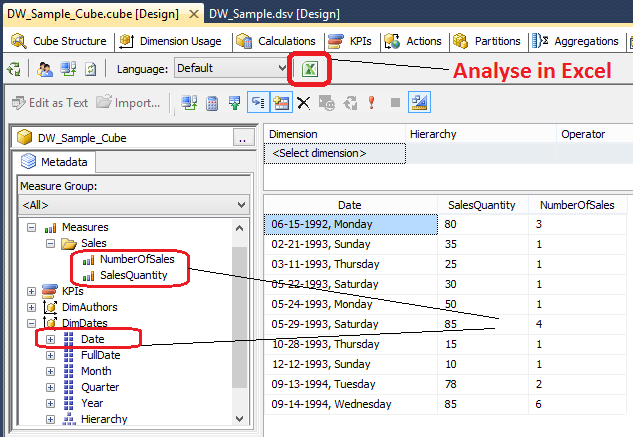
In the above image I dragged SalesQuantity and NumberOfSales measures as well as Date dimension onto the query pane and SSAS automatically aggregated the data for me. In order to validate that these figures are, in fact, what we store in the database let’s write a quick SQL and compare the output from both queries (even though the query can be composed by dragging and dropping measures/dimensions onto the query pane SSAS writes MDX code in the background).
1 2 3 4 5 6 7 | USE DW_Sample
SELECT
d.datename as Date,
SUM([SalesQuantity]) as SalesQuantity,
COUNT(*) as NumberOfSales
FROM [DW_Sample].[dbo].[FactSales] s join DimDates d ON s.orderdatekey = d.DateKey
GROUP BY d.datename
|
When executed, the figures from the database which feeds out SSAS project are identical to those stored in the cube as per image below.
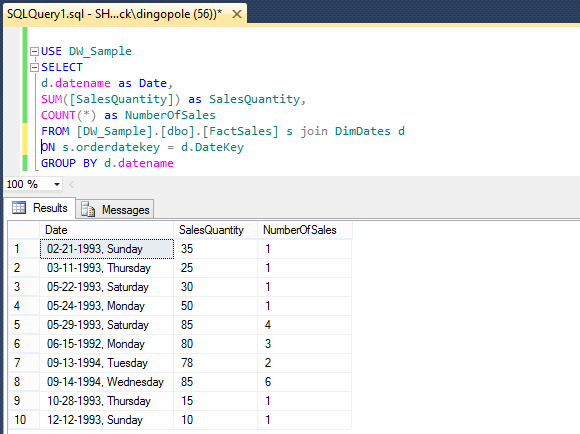
This method works well for small data sets but isn’t very effective with large volumes of data. Another, slightly more elaborate but also much more accurate and effective way is to create a linked server to our OLAP database and execute OPENQUERY SQL statement to extract the dimensional data in a tabular fashion for further comparison. First, let’s create a linked server executing the following SQL.
1 2 3 4 5 6 | EXEC master.dbo.sp_addlinkedserver
@server = N'SQL2012_MultiDim',
@srvproduct = '',
@provider = N'MSOLAP',
@datasrc = N'Sherlock\sql2012_MultiDim',
@catalog = N'DW_Sample_SSAS'
|
As you remember, when visually building a result set in a Browser tab in Visual Studio, SSAS also creates MDX code in the background. To access we simply click on the Design Mode button to change the interface from visual to code. If you had the desired result set already created visually, the MDX code should look similar to the one below.
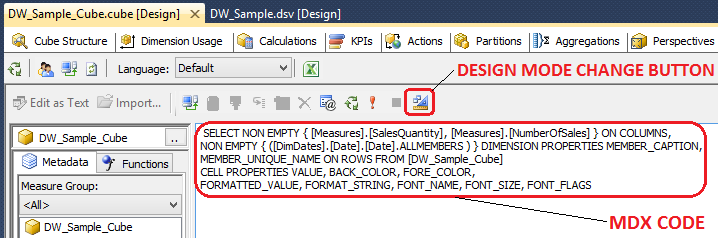
Let’s copy the code and wrapping it around with an OPENQUERY SQL statement let’s bring back the results in Microsoft SQL Server Management Studio as per below.
1 2 3 4 5 6 7 8 | SELECT *
FROM OPENQUERY
(SQL2012_MultiDim,
'SELECT NON EMPTY { [Measures].[SalesQuantity], [Measures].[NumberOfSales] } ON COLUMNS,
NON EMPTY { ([DimDates].[Date].[Date].ALLMEMBERS ) } DIMENSION PROPERTIES MEMBER_CAPTION,
MEMBER_UNIQUE_NAME ON ROWS FROM [DW_Sample_Cube]
CELL PROPERTIES VALUE, BACK_COLOR, FORE_COLOR,
FORMATTED_VALUE, FORMAT_STRING, FONT_NAME, FONT_SIZE, FONT_FLAGS')
|
Finally, after a little clean-up we can go ahead and compare the results between the cube and database using, for example, EXCEPT SQL statement as per the code snippet below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | SELECT
CAST("[DimDates].[Date].[Date].[Member_Caption]" AS nvarchar (50)) AS DateName,
CAST("[Measures].[SalesQuantity]" AS int) AS SalesQuantity,
CAST("[Measures].[NumberOfSales]" AS int) AS NumberOfSales
FROM OPENQUERY
(SQL2012_MultiDim,
'SELECT NON EMPTY { [Measures].[SalesQuantity], [Measures].[NumberOfSales] } ON COLUMNS,
NON EMPTY { ([DimDates].[Date].[Date].ALLMEMBERS ) } DIMENSION PROPERTIES MEMBER_CAPTION,
MEMBER_UNIQUE_NAME ON ROWS FROM [DW_Sample_Cube]
')
EXCEPT
SELECT
d.datename As DateName,
SUM([SalesQuantity]) as SalesQuantity,
COUNT(*) as SalesCount
FROM [DW_Sample].[dbo].[FactSales] s
join [DW_Sample].[dbo].[DimDates] d ON s.orderdatekey = d.DateKey
GROUP BY d.datename
|
If, after executing, the result brings back no values, this indicates data overlap and is symptomatic of that fact that there are no differences between the cube and the database. Similarly, you can try using INTERSECT SQL command in place if EXCEPT which should provide the opposite results i.e. only return the rows with identical data.
This concludes this post. As usual, the code used in this series as well as solution files for this SSAS project can be found and downloaded from HERE. In the NEXT ITERATION to the series I will be building a simple SSRS (SQL Server Reporting Services) report based on our data mart.
Please also check other posts from this series:
All SQL code and solution files can be found and downloaded from HERE.
Posted in: How To's, SQL, SSAS
Tags: Data Modelling, SSAS



Never thought Polybase could be used in this capacity and don't think Microsoft advertised this feature (off-loading DB data as…